Sparkコネクターの概要¶
Spark用のSnowflakeコネクターは、他のデータソース(PostgreSQL、HDFS、S3など)と同様に、SnowflakeをApache Sparkデータソースとして使用できるようにします。
注釈
As an alternative to using Spark, consider writing your code to use Snowpark API instead. Snowpark allows you to perform all of your work within Snowflake (rather than in a separate Spark compute cluster). Snowpark also supports pushdown of all operations, including Snowflake UDFs. However, when you want to enforce row and column policies on Iceberg tables, use the Snowflake Spark Connector. For more information, see Apache Spark™から Apache Iceberg™ テーブルをクエリするときにデータ保護ポリシーを適用する.
SnowflakeとSparkの相互作用¶
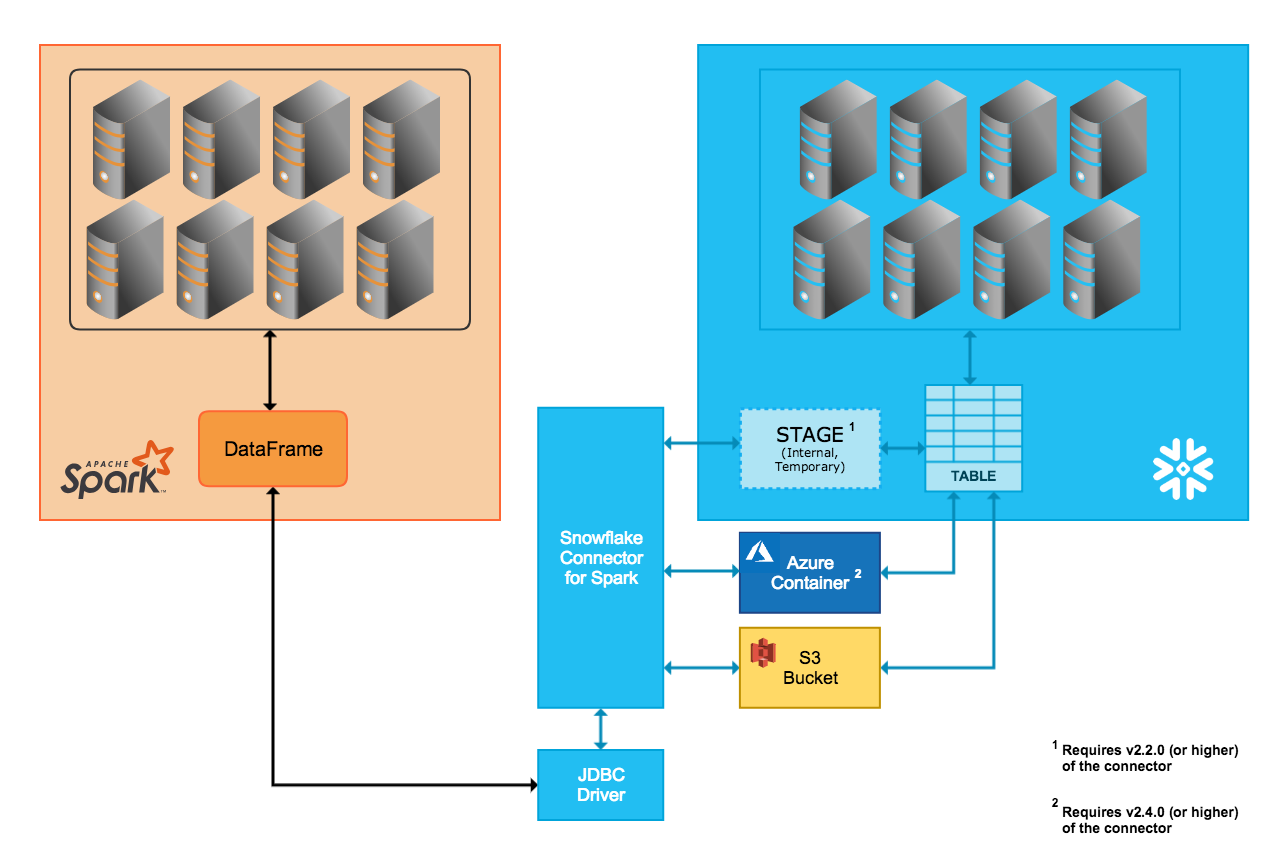
コネクターは、SnowflakeクラスターとSparkクラスター間の双方向のデータ移動をサポートします。Sparkクラスターは自己ホストするか、Qubole、AWS EMR、またはDatabricksなどの別のサービスを介してアクセスできます。
コネクターを使用して、次の操作を実行できます。
Snowflakeのテーブル(またはクエリ)からSpark DataFrame を作成します。
Spark DataFrame のコンテンツをSnowflakeのテーブルに書き込みます。
コネクタはScala 2.12.xまたは2.13.xを使用してこれらの操作を実行し、Snowflake JDBC ドライバーを使用してSnowflakeと通信します。
注釈
SnowflakeとApache Sparkを接続するために、Spark用のSnowflakeコネクターは厳密には必要ありません。他のサードパーティの JDBC ドライバーを使用できます。ただし、Snowflake JDBC ドライバーと組み合わせたコネクターは2つのシステム間で大量のデータを転送するために最適化されているため、Spark用のSnowflakeコネクターを使用することをお勧めします。また、SparkからSnowflakeへのクエリプッシュダウンをサポートすることにより、パフォーマンスが向上します。
データ転送¶
SnowflakeのSparkコネクターは、2つの転送モードをサポートしています。
内部転送では、Snowflakeによって内部/透過的に作成および管理される一時的な場所を使用します。
外部転送では、ユーザーが作成および管理する通常は一時的な保管場所を使用します。
Tip
次のいずれかに該当する場合は、外部データ転送を使用します。
バージョン2.1.x以下のSparkコネクターを使用している場合(内部転送をサポートしていません)。
転送に36時間以上かかる可能性がある場合(内部転送では、36時間後に期限が切れる一時的な認証情報が使用されます)。
それ以外の場合は、内部データ転送の使用を お勧めします。
内部データ転送¶
コネクターが自動的に作成および管理するSnowflake内部ステージを介して、2つのシステム間のデータ転送が容易化されます。
Snowflakeに接続し、Snowflakeでセッションを初期化すると、コネクターは内部ステージを作成します。
Snowflakeセッションの期間中、コネクターはステージを使用してデータを格納し、そのデータを宛先に転送します。
Snowflakeセッションの最後に、コネクターはステージをドロップし、それによりステージ内のすべての一時データを削除します。
内部転送のサポートには、Snowflakeアカウントのクラウドプラットフォームに基づいて、特定のバージョン(またはそれ以降)のコネクターが必要です。
- AWS:
内部データ転送モードは、コネクターのバージョン2.2.0(およびそれ以降)でのみサポートされています。
- Azure:
内部データ転送モードは、コネクタのバージョン2.4.0(およびそれ以上)でのみサポートされています。
- GCP:
内部データ転送モードは、コネクタのバージョン2.7.0(およびそれ以降)でのみサポートされています。
外部データ転送¶
2つのシステム間でのデータの転送は、ユーザーが指定した保存場所と、コネクターによって自動的に作成されたファイルによって容易化されます。
- AWS:
転送データファイルが作成され、S3バケットに格納されます。
- Azure:
転送データファイルが作成され、Blobストレージコンテナに格納されます。Azureを介した外部転送は、コネクタのバージョン2.4.0(およびそれ以上)でのみサポートされています。
ストレージの場所を指定するパラメーターは、 コネクタの構成オプションの設定 に記載されています。
注釈
外部データ転送の場合は、Sparkコネクタのインストール/構成の一部として、保存場所を作成および構成する必要があります。
また、外部転送中にコネクターによって作成されたファイルは一時的なものであることが意図されていますが、コネクターによって保存場所からファイルは自動的に削除されません。ファイルを削除するには、次のいずれかの方法を使用します。
それらを手動で削除します。
コネクターの
purgeパラメーターを設定します。このパラメーターの詳細については、 コネクタの構成オプションの設定 をご参照ください。Amazon S3ライフサイクルポリシーパラメーターなどのストレージシステムパラメーターを設定して、転送完了後にファイルをクリーンアップします。
列マッピング¶
SparkテーブルからSnowflakeテーブルにデータをコピーするときに列名が一致しない場合は、 コネクタの構成オプションの設定 に記載されている columnmapping パラメーターを使用して、SparkからSnowflakeに列名をマッピングします。
注釈
列マッピングは、内部データ転送でのみサポートされます。
クエリプッシュダウン¶
最適なパフォーマンスを得るには、大量データを読み取ったり、システム間で大きな中間結果を転送したりしないでください。理想的には、ほとんどの処理はデータが格納されている場所の近くで行われ、参加するストアの機能を活用して、不要なデータを動的に排除する必要があります。
クエリプッシュダウンは、大規模で複雑なSpark論理プラン(全体または一部)をSnowflakeで処理できるようにすることで、これらのパフォーマンス効率を活用します。
クエリプッシュダウンは、Spark用Snowflakeコネクタのバージョン2.1.0(またはそれ以上)でサポートされています。
プッシュダウンはすべての状況で可能というわけではありません。たとえば、Spark UDFs はSnowflakeにプッシュダウンできません。プッシュダウンでサポートされる操作のリストについては、 プッシュダウン をご参照ください。
注釈
すべての操作でプッシュダウンが必要な場合は、代わりに Snowpark API を使用するようにコードを作成することを検討してください。Snowparkは、Snowflake UDFs のプッシュダウンもサポートしています。
Databricksの統合¶
Databricksは、SparkとSnowflake間のネイティブ接続を提供するために、Spark用のSnowflakeコネクターをDatabricks Unified Analytics Platformに統合しました。
ScalaとPythonを使用したコード例を含む詳細については、 データソース--- Snowflake (Databricksドキュメント)または DatabricksでのSpark用Snowflakeの構成 をご参照ください。
Quboleの統合¶
Quboleは、SparkとSnowflake間のネイティブ接続を提供するために、Spark用のSnowflakeコネクターをQubole Data Service(QDS)エコシステムに統合しました。この統合により、SnowflakeをSparkデータストアとしてQuboleに直接追加できます。
SnowflakeがSparkデータストアとして追加されると、データエンジニアとデータサイエンティストはSparkとQDS UI、API、およびノートブックを次の目的で使用できます。
外部データソースを準備してSnowflakeに統合したり、Snowflakeデータを改良して変換したりするなど、高度なデータ変換を実行します。
Snowflakeに既に存在するデータを使用して、Sparkで機械学習および AI モデルを構築、トレーニング、および実行します。
詳細については、 Qubole-Snowflake統合ガイド (Quboleドキュメント)または QuboleでのSpark用Snowflakeの構成 をご参照ください。