Spark 커넥터 개요¶
Spark용 Snowflake Connector를 사용하면 Snowflake를 기타 데이터 소스(PostgreSQL, HDFS, S3 등)와 유사한 Apache Spark 데이터 소스로 사용할 수 있습니다.
참고
As an alternative to using Spark, consider writing your code to use Snowpark API instead. Snowpark allows you to perform all of your work within Snowflake (rather than in a separate Spark compute cluster). Snowpark also supports pushdown of all operations, including Snowflake UDFs. However, when you want to enforce row and column policies on Iceberg tables, use the Snowflake Spark Connector. For more information, see Apache Spark™에서 Apache Iceberg™ 테이블 쿼리 시 데이터 보호 정책 적용.
Snowflake와 Spark 간의 상호 작용¶
커넥터는 Snowflake 클러스터와 Spark 클러스터 사이에서의 양방향 데이터 이동을 지원합니다. Spark 클러스터는 자체 호스팅되거나 Qubole, AWS EMR 또는 Databricks 등의 기타 서비스를 통해 액세스할 수 있습니다.
커넥터를 사용하면 다음 작업을 수행할 수 있습니다.
Snowflake의 테이블(또는 쿼리)에서 Spark DataFrame을 채웁니다.
Spark DataFrame의 내용을 Snowflake의 테이블에 작성합니다.
커넥터는 Scala 2.12.x 또는 2.13.x를 사용하여 이러한 작업을 수행하고 Snowflake JDBC 드라이버를 사용하여 Snowflake와 통신합니다.
참고
Spark용 Snowflake Connector는 Snowflake와 Apache Spark를 연결하기 위한 필수 요소가 아니며, 기타 서드 파티 JDBC 드라이버를 사용할 수 있습니다. 그러나 Snowflake JDBC 드라이버와 함께 커넥터는 두 시스템 사이에서의 대용량 데이터 전송에 최적화되어 있으므로 Spark용 Snowflake Connector를 사용하는 것이 좋습니다. 또한, Spark에서 Snowflake로의 쿼리 푸시다운을 지원하여 성능도 향상됩니다.
데이터 전송¶
Snowflake Spark Connector는 다음의 2가지 전송 모드를 지원합니다.
내부 전송에서는 Snowflake에서 내부적인/투명한 생성 및 관리를 위한 임시 위치를 사용합니다.
외부 전송에서는 일반적으로 사용자가 생성 및 관리하는 임시 저장 위치를 사용합니다.
팁
다음 중 1개에 해당하는 경우 외부 데이터 전송을 사용합니다.
Spark Connector의 버전 2.1.x 이하(내부 전송을 지원하지 않음)를 사용하는 중입니다.
전송에 36시간 이상이 걸릴 수 있습니다(내부 전송에서는 36시간 후에 만료되는 임시 자격 증명이 사용됨).
이외의 경우에는, 내부 데이터 전송을 사용하는 것이 좋습니다.
내부 데이터 전송¶
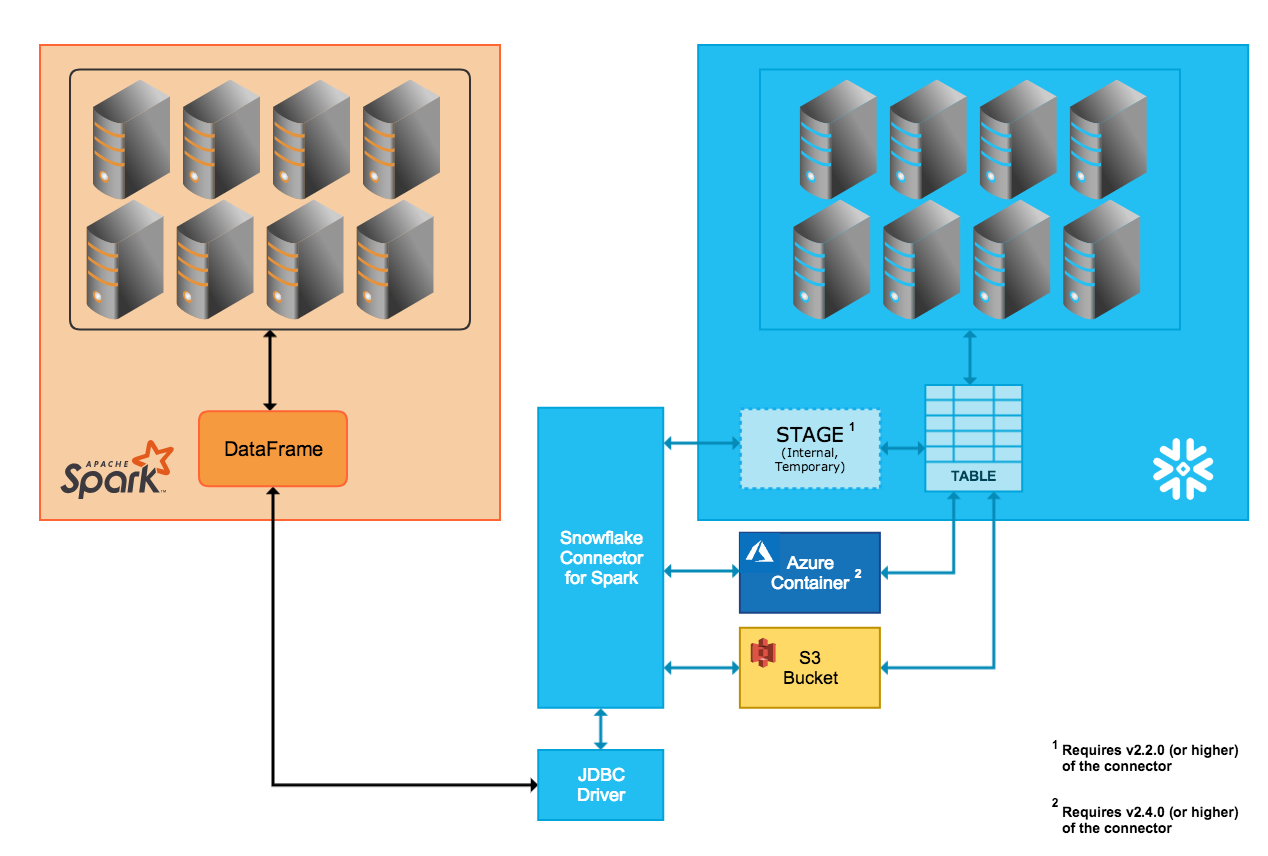
두 시스템 사이에서의 데이터 전송은 커넥터가 자동으로 생성 및 관리하는 Snowflake 내부 스테이지를 통해 원활하게 수행될 수 있습니다.
Snowflake에 연결하고 Snowflake에서 세션을 초기화할 때, 커넥터가 내부 스테이지를 생성합니다.
Snowflake 전체 세션 기간 동안 커넥터는 스테이지를 사용하여 데이터를 저장하는 동시에 데이터를 대상으로 전송합니다.
Snowflake 세션이 종료되면 커넥터는 스테이지를 삭제하여 스테이지의 모든 임시 데이터를 제거합니다.
내부 전송을 지원하려면 Snowflake 계정의 클라우드 플랫폼에 따라 특정 버전 이상의 커넥터가 필요하다는 점에 유의하십시오.
- AWS:
내부 데이터 전송 모드는 커넥터 버전 2.2.0 이상에서만 지원됩니다.
- Azure:
내부 데이터 전송 모드는 커넥터 버전 2.4.0 이상에서만 지원됩니다.
- GCP:
내부 데이터 전송 모드는 커넥터 버전 2.7.0 이상에서만 지원됩니다.
외부 데이터 전송¶
두 시스템 사이에서의 데이터 전송은 사용자가 지정하는 저장 위치와 커넥터에 의해 자동으로 생성되는 파일을 통해 원활하게 수행될 수 있습니다.
- AWS:
전송 데이터 파일이 생성되어 S3 버킷에 저장됩니다.
- Azure:
전송 데이터 파일이 생성되어 Blob 저장소 컨테이너에 저장됩니다. Azure를 통한 외부 전송은 커넥터 버전 2.4.0 이상에서만 지원됩니다.
저장 위치를 지정하는 매개 변수에 대한 설명은 커넥터에 대한 구성 옵션 설정하기 에서 제공됩니다.
참고
외부 데이터 전송의 경우 Spark 커넥터를 설치/구성하는 작업의 일부로 저장소 위치를 생성 및 구성해야 합니다.
또한, 외부 전송 시 커넥터에서 생성되는 파일은 임시로 생성되지만 커넥터가 저장 위치에서 자동으로 파일을 삭제하지 않습니다. 이러한 파일을 삭제하려면 다음 방법 중 1개를 수행합니다.
수동으로 삭제합니다.
커넥터에
purge매개 변수를 설정합니다. 이 매개 변수에 대한 자세한 내용은 커넥터에 대한 구성 옵션 설정하기 를 참조하십시오.Amazon S3 수명 주기 정책 매개 변수와 같은 저장소 시스템 매개 변수를 설정하여 전송이 완료된 후 파일을 정리합니다.
열 매핑¶
Spark 테이블에서 Snowflake 테이블로 데이터를 복사할 때 열 이름이 일치하지 않으면 커넥터에 대한 구성 옵션 설정하기 에서 설명된 columnmapping 매개 변수를 사용하여 Spark에서 Snowflake로 열 이름을 매핑할 수 있습니다.
참고
열 매핑은 내부 데이터 전송에서만 지원됩니다.
쿼리 푸시다운¶
최적의 성능을 위해서는 일반적으로는 대량 데이터 읽기 또는 시스템 사이에서의 대규모 임시 결과 전송을 방지해야 합니다. 이상적으로는 참여 저장소의 기능을 활용할 수 있도록 데이터가 저장된 위치 근처에서 대부분의 처리가 수행되어 필요하지 않은 데이터를 동적으로 제거해야 합니다.
쿼리 푸시다운은 크고 복잡한 Spark 논리 계획(전체 또는 일부)을 Snowflake에서 처리할 수 있도록 하여 Snowflake를 통해 대부분의 실제 작업을 수행함으로써 이러한 성능 효율성을 활용합니다.
쿼리 푸시다운은 Spark용 Snowflake 커넥터 버전 2.1.0 이상에서 지원됩니다.
일부 상황에서는 푸시다운을 사용할 수 없습니다. 예를 들어 Spark UDFs는 Snowflake로 푸시다운할 수 없습니다. 푸시다운을 위해 지원되는 작업의 목록은 푸시다운 섹션을 참조하십시오.
참고
모든 작업에 대해 푸시다운이 필요한 경우 대신 Snowpark API 를 사용하는 코드를 작성해 보십시오. Snowpark는 Snowflake UDF의 푸시다운도 지원합니다.
Databricks 통합¶
Databricks는 Spark용 Snowflake Connector를 Databricks 통합 분석 플랫폼에 통합하여 Spark와 Snowflake 사이의 기본 연결을 제공합니다.
Scala 및 Python을 사용하는 코드 예제 등 자세한 내용은 데이터 소스 — Snowflake (Databricks 설명서) 또는 Databricks에서 Spark용 Snowflake 구성하기 를 참조하십시오.
Qubole 통합¶
Qubole은 Spark용 Snowflake Connector를 Qubole Data Service(QDS) 에코시스템에 통합하여 Spark와 Snowflake 사이의 기본 연결을 제공합니다. 이 통합을 통해 Qubole에서 직접 Spark 데이터 저장소로 Snowflake를 추가할 수 있습니다.
Snowflake가 Spark 데이터 저장소로 추가되면 데이터 엔지니어 및 데이터 과학자는 Spark와 QDS UI, API 및 노트북을 사용하여:
외부 데이터 소스를 Snowflake로 준비 및 통합하거나 Snowflake 데이터를 세분화 및 변환하는 등의 고급 데이터 변환을 수행합니다.
Snowflake에 이미 있는 데이터를 사용하여 Spark에서 머신 러닝 및 AI 모델을 구축, 학습 및 실행합니다.
자세한 내용은 Qubole-Snowflake 통합 가이드 (Qubole 설명서) 또는 Qubole에서 Spark용 Snowflake 구성하기 를 참조하십시오.