Übersicht zum Spark-Konnektor¶
Der Snowflake-Konnektor für Spark ermöglicht die Verwendung von Snowflake als Apache-Spark-Datenquelle ähnlich wie andere Datenquellen (PostgreSQL, HDFS, S3 usw.).
Bemerkung
As an alternative to using Spark, consider writing your code to use Snowpark API instead. Snowpark allows you to perform all of your work within Snowflake (rather than in a separate Spark compute cluster). Snowpark also supports pushdown of all operations, including Snowflake UDFs. However, when you want to enforce row and column policies on Iceberg tables, use the Snowflake Spark Connector. For more information, see Durchsetzen von Datenschutzrichtlinien bei der Abfrage von Apache Iceberg™-Tabellen von Apache Spark™.
Interaktion zwischen Snowflake und Spark¶
Der Konnektor unterstützt die bidirektionale Datenbewegung zwischen einem Snowflake-Cluster und einem Spark-Cluster. Der Spark-Cluster kann selbst gehostet oder über einen anderen Service wie Qubole, AWS EMR oder Databricks aufgerufen werden.
Mit dem Konnektor können Sie die folgenden Operationen ausführen:
Auffüllen eines Spark-DataFrame mit Inhalten einer Tabelle (oder Abfrage) aus Snowflake.
Schreiben des Inhalts eines Spark-DataFrame in eine Tabelle in Snowflake.
Der Konnektor verwendet Scala 2.12.x oder 2.13.x, um diese Operationen auszuführen, und verwendet den Snowflake-JDBC-Treiber, um mit Snowflake zu kommunizieren.
Bemerkung
Der Snowflake-Konnektor für Spark ist nicht unbedingt erforderlich, um Snowflake und Apache Spark zu verbinden. Es können auch andere JDBC-Treiber von Drittanbietern verwendet werden. Wir empfehlen jedoch die Verwendung des Snowflake-Konnektors für Spark, da der Konnektor in Verbindung mit dem Snowflake-JDBC-Treiber für die Übertragung großer Datenmengen zwischen beiden Systemen optimiert wurde. Er bietet auch eine verbesserte Leistung durch die Unterstützung der Abfrageverschiebung von Spark nach Snowflake.
Datenübertragung¶
Der Snowflake-Konnektor für Spark unterstützt zwei Übertragungsmodi:
Für die interne Übertragung wird ein temporärer Speicherort verwendet, der intern/transparent von Snowflake erstellt und verwaltet wird.
Bei der externen Übertragung wird ein Speicherort verwendet, der in der Regel temporär ist und vom Benutzer erstellt und verwaltet wird.
Tipp
Verwenden Sie die externe Datenübertragung, wenn eine der folgenden Voraussetzungen erfüllt ist:
Sie verwenden die Version 2.1.x oder niedriger des Spark-Konnektors (der keine interne Übertragung unterstützt).
Ihre Übertragung dauert wahrscheinlich 36 Stunden oder länger (interne Übertragung verwendet temporäre Anmeldeinformationen, die nach 36 Stunden ablaufen).
Ansonsten empfehlen wir die Verwendung der internen Datenübertragung.
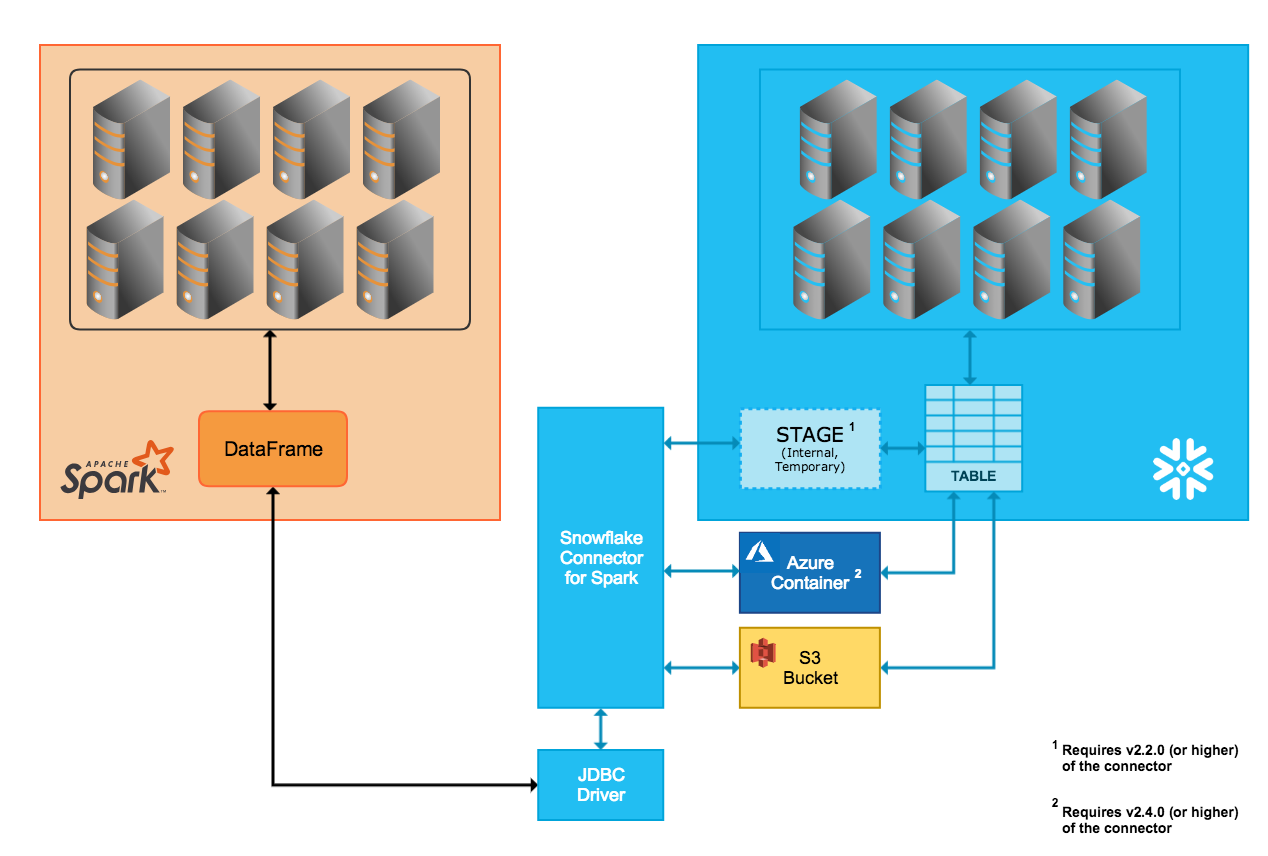
Interne Datenübertragung¶
Die Datenübertragung zwischen den beiden Systemen wird durch eine internen Stagingbereich von Snowflake erleichtert, der vom Konnektor automatisch erstellt und verwaltet wird:
Nach dem Verbinden mit Snowflake und dem Initialisieren einer Sitzung in Snowflake erstellt der Konnektor den internen Stagingbereich.
Während der gesamten Dauer der Snowflake-Sitzung verwendet der Konnektor den Stagingbereich, um Daten zu speichern und sie an ihr Ziel zu übertragen.
Am Ende der Snowflake-Sitzung löscht der Konnektor den Stagingbereich und entfernt damit alle darin enthaltenen temporären Daten.
Beachten Sie, dass die Unterstützung für die interne Übertragung eine bestimmte Version (oder höher) des Konnektors erfordert, die auf der Cloudplattform für Ihr Snowflake-Konto basiert:
- AWS:
Der interne Datenübertragungsmodus wird nur in der Version 2.2.0 (und höher) des Konnektors unterstützt.
- Azure:
Der interne Datenübertragungsmodus wird nur in der Version 2.4.0 (und höher) des Konnektors unterstützt.
- GCP:
Der interne Datenübertragungsmodus wird nur in der Version 2.7.0 (und höher) des Konnektors unterstützt.
Externe Datenübertragung¶
Die Datenübertragung zwischen den beiden Systemen wird durch einen Speicherort erleichtert, den der Benutzer festlegt, und durch Dateien, die automatisch vom Konnektor erstellt werden:
- AWS:
Die Datendateien für die Übertragung werden in einem S3-Bucket erstellt und gespeichert.
- Azure:
Die Datendateien für die Übertragung werden in einem Blob-Speichercontainer erstellt und gespeichert. Die externe Übertragung über Azure wird nur in der Version 2.4.0 (und höher) des Konnektors unterstützt.
Die Parameter, die den Speicherort angeben, sind in Einstellen der Konfigurationsoptionen für den Konnektor dokumentiert:
Bemerkung
Für die externe Datenübertragung muss der Speicherort im Rahmen der Installation/Konfiguration des Spark-Konnektors erstellt und konfiguriert werden.
Außerdem sind die vom Konnektor während der externen Übertragung erstellten Dateien als temporär gedacht, aber der Konnektor löscht die Dateien nicht automatisch vom Speicherort. Um die Dateien zu löschen, verwenden Sie eine der folgenden Methoden:
Löschen Sie die Dateien manuell.
Stellen Sie den Parameter
purgefür den Konnektor ein. Weitere Informationen zu diesem Parameter finden Sie unter Einstellen der Konfigurationsoptionen für den Konnektor.Legen Sie einen Parameter für das Speichersystem fest, wie beispielsweise den Amazon S3-Lebenszyklusrichtlinien-Parameter, um die Dateien nach der Übertragung zu bereinigen.
Spaltenzuordnung¶
Wenn Sie Daten aus einer Spark-Tabelle in eine Snowflake-Tabelle kopieren und die Spaltennamen nicht übereinstimmen, können Sie die Spaltennamen von Spark zu Snowflake mit dem Parameter columnmapping zuordnen, der in Einstellen der Konfigurationsoptionen für den Konnektor dokumentiert ist.
Bemerkung
Die Spaltenzuordnung wird nur für die interne Datenübertragung unterstützt.
Abfrageverschiebung (Pushdown)¶
Für eine optimale Performance sollten Sie in der Regel vermeiden, viele Daten zu lesen oder umfangreiche Zwischenergebnisse zwischen Systemen zu übertragen. Im Idealfall sollte der größte Teil der Verarbeitung nahe des Speicherorts erfolgen, um die Möglichkeiten der teilnehmenden Speicher zu nutzen, damit nicht mehr benötigte Daten dynamisch eliminiert werden.
Mit Abfrage-Pushdown werden diese Leistungskapazitäten genutzt, indem große und komplexe logische Pläne von Spark (ganz oder teilweise) an Snowflake übergeben werden, sodass Snowflake den größten Teil der eigentlichen Arbeit erledigt.
Der Pushdown von Abfragen wird ab Version 2.1.0 des Snowflake-Konnektors für Spark unterstützt.
Pushdown ist nicht in allen Situationen möglich. Beispielsweise kann kein Pushdown von Spark-UDFs in Snowflake ausgeführt werden. Eine Liste der für Pushdown unterstützten Operationen finden Sie unter Pushdown.
Bemerkung
Wenn Sie Pushdown für alle Operationen benötigen, sollten Sie Ihren Code so schreiben, dass dieser stattdessen Snowpark API verwendet. Snowpark unterstützt auch den Pushdown von Snowflake-UDFs.
Integration von Databricks¶
Databricks hat den Snowflake-Konnektor für Spark in die Databricks Unified Analytics Platform integriert, um eine native Konnektivität zwischen Spark und Snowflake zu ermöglichen.
Weitere Details, einschließlich Codebeispiele mit Scala und Python, finden Sie unter Datenquellen – Snowflake (in der Databricks-Dokumentation) oder unter Konfigurieren von Snowflake für Spark in Databricks.
Integration von Qubole¶
Qubole hat den Snowflake-Konnektor für Spark in das Qubole Data Service (QDS)-Ökosystem integriert, um eine native Konnektivität zwischen Spark und Snowflake zu ermöglichen. Durch diese Integration kann Snowflake als Spark-Datenspeicher direkt in Qubole hinzugefügt werden.
Sobald Snowflake als Spark-Datenspeicher hinzugefügt wurde, können Dateningenieure und Datenwissenschaftler Spark und die QDS-UI, -API und -Notebooks für Folgendes verwenden:
Durchführen von erweiterten Datentransformationen, wie z. B. die Vorbereitung und Konsolidierung externer Datenquellen in Snowflake oder die Verfeinerung und Transformation von Snowflake-Daten.
Erstellen, Trainieren und Ausführen von maschinellem Lernen und von AI-Modellen in Spark unter Verwendung der Daten, die bereits in Snowflake vorhanden sind.
Weitere Details dazu finden Sie im Qubole-Snowflake-Integrationshandbuch (in der Qubole-Dokumentation) oder unter Konfigurieren von Snowflake für Spark in Qubole.