Introduction to streams¶
ストリーム・オブジェクトは、データ操作言語 (DML) によるテーブルへの挿入 (COPY INTOを含む) 、更新、削除などの変更と、各変更に関するメタデータを記録し、変更されたデータを使用してアクションを実行できるようにします。このプロセスは、変更データキャプチャ(CDC)と呼ばれます。このトピックでは、ストリームを使用した変更データキャプチャの重要な概念を紹介します。
個々のテーブルストリームは、 ソーステーブル の行に加えられた変更を追跡します。テーブルストリーム(単に「ストリーム」とも呼ばれます)は、テーブル内の2つのトランザクションポイント間で行レベルで変更された内容の「変更テーブル」を利用可能にします。これにより、トランザクション形式で一連の変更記録をクエリおよび使用できます。
ストリームを作成して、次のオブジェクトの変更データをクエリできます。
共有テーブルを含む標準テーブル。
ビュー(セキュアビューを含む)
制限事項 による Apache Iceberg™テーブル。
Offset storage¶
ストリームは、作成されると、特定の時点(呼称: オフセット)をオブジェクトの現在のトランザクションバージョンとして初期化することにより、ソースオブジェクト(例: テーブル、外部テーブル、またはビューの基になるテーブル)内にあるすべての行の初期スナップショットを論理的に取得します。ストリームで使用される変更追跡システムは、このスナップショットの取得後にコミットされた DML 変更に関する情報を記録します。変更レコードは、変更前後の行の状態を提供します。変更情報は、追跡されるソースオブジェクトの列構造を反映し、各変更イベントを説明する追加のメタデータ列を含みます。
ストリームは現在のテーブルスキーマを使用します。しかし、ストリームは削除されたデータを読み取り、経時変化を追跡することがあるため、オフセットとアドバンスの間でスキーマに互換性のない変更があると、クエリに失敗することがあります。
ストリーム自体には、テーブルデータが 含まれない ことに注意してください。ストリームは、ソースオブジェクトのオフセットのみを保存し、ソースオブジェクトのバージョン管理履歴を活用して CDC 記録を返します。テーブルの最初のストリームが作成されると、いくつかの非表示の列がソーステーブルに追加され、変更追跡メタデータの保存が開始されます。これらの列は少量のストレージを消費します。ストリームのクエリ時に返される CDC レコードは、ストリームに保存されている オフセット と、テーブルに保存されている 変更追跡メタデータ の組み合わせに依存します。Streams on Viewsの場合、これらのテーブルに非表示の列を追加するには、ビューと基になるテーブルに対して変更追跡を明示的に有効にする必要があることに注意してください。
ストリームをブックマークと考えると便利な場合があります。ブックマークは、ブックのページ(つまり、ソースオブジェクト)の特定の時点を示します。ブックマークは破棄でき、他のブックマークをブックのさまざまな場所に挿入できます。同様に、ストリームはドロップして、同じまたは異なる時点に作成された他のストリームにより(異なる時間に連続してストリームを作成するか、 Time Travel を使用)、同じまたは異なるオフセットでオブジェクトのために変更記録を消費することができます。
CDC 記録のコンシューマーの一例は、データパイプラインです。このパイプラインでは、最後の抽出以降に変更されたステージングテーブルのデータのみが変換され、他のテーブルにコピーされます。
Table versioning¶
1つ以上の DML ステートメントを含むトランザクションがテーブルにコミットされるたびに、新しいテーブルバージョンが作成されます。これは、次のテーブルタイプに適用されます。
標準テーブル
ディレクトリテーブル
動的テーブル
外部テーブル
Apache Iceberg™ テーブル
ビューの基になるテーブル
テーブルのトランザクション履歴では、ストリームオフセットは2つのテーブルバージョンの間にあります。ストリームをクエリすると、オフセット後および現在の時刻以前にコミットされたトランザクションによって発生した変更が返されます。
次の例は、タイムラインに10のコミットされたバージョンを持つソーステーブルを示しています。ストリーム s1 のオフセットは、現在、テーブルバージョン v3 と v4 の間です。ストリームがクエリ(または消費)されると、返されるレコードには、テーブルタイムラインのストリームオフセットの直後のバージョンであるテーブルバージョン v4 から、タイムラインの最新のコミット済みテーブルバージョンである v10 までのすべてのトランザクションが含まれます。
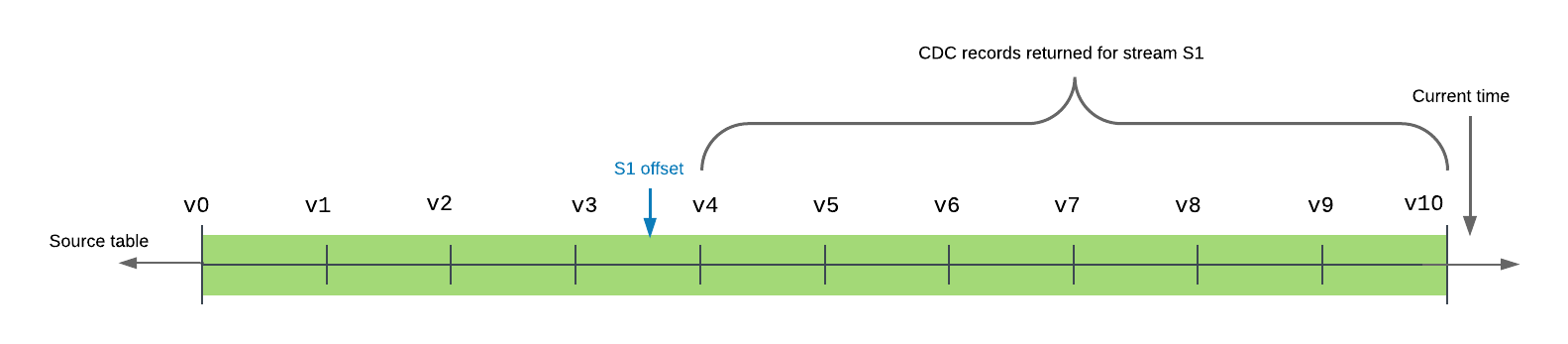
ストリームは、現在のオフセットから現在のバージョンのテーブルへの最小限の変更セットを提供します。
複数のクエリは、オフセットを変更することなく、ストリームから同じ変更データを独立して使用できます。ストリームは、DML トランザクションで使用される場合に のみ オフセットを進めます。これには、Create Table As Select(CTAS)トランザクションや COPY INTO ロケーショントランザクションが含まれ、この動作は明示的トランザクションと 自動コミット トランザクションの両方に適用されます。(デフォルトでは、DML ステートメントが実行されると、自動コミットトランザクションが暗黙的に開始され、ステートメントの完了時にトランザクションがコミットされます。この動作は AUTOCOMMIT パラメーターで制御されます)。明示的なトランザクション内であっても、ストリームをクエリするだけではオフセットは進みません。ストリームの内容は、 DML ステートメント内で消費する必要があります。
注釈
DML 操作内で変更データを消費せずに、ストリームのオフセットを現在のテーブルバージョンに進めるには、次のいずれかのアクションを実行します。
ストリームを再作成します(CREATE OR REPLACE STREAM 構文を使用)。
現在の変更データを仮テーブルに挿入します。INSERT ステートメントでストリームをクエリしますが、すべての変更データ(例:
WHERE 0 = 1)を除外する WHERE 句を含めます。
SQL ステートメントが明示的なトランザクション内でストリームをクエリすると、ストリームはステートメントが実行されたときではなく、トランザクションが開始されたときのストリームアドバンスポイント(つまり、タイムスタンプ)でクエリされます。この動作は、DML ステートメントと、既存のストリームの行を新しいテーブルに取り込む CREATE TABLE ... AS SELECT (CTAS)ステートメントの両方に関係します。
ストリームから選択する DML ステートメントは、トランザクションが正常にコミットされる限り、ストリーム内のすべての変更データを消費します。複数のステートメントがストリーム内の同じ変更レコードにアクセスするようにするには、それらを明示的なトランザクションステートメント(BEGIN .. COMMIT)で囲みます。これにより、ストリームがロックされます。DML は並列トランザクションでのソースオブジェクトの更新は、変更追跡システムによって追跡されますが、明示的なトランザクションステートメントがコミットされ、既存の変更データが消費されるまでストリームを更新しません。
Repeatable read isolation¶
ストリームは反復可能な読み取り分離をサポートします。反復可能読み取りモードでは、トランザクション内の複数の SQL ステートメントがストリーム内の同じレコードセットを参照します。これは、テーブルでサポートされている読み取りコミットモードとは異なります。このモードでは、ステートメントは同じトランザクション内で実行された以前のステートメントによって行われた変更を、これらの変更がまだコミットされていない場合でも、確認します。
トランザクションでストリームによって返されるデルタレコードは、ストリームの現在位置からトランザクション開始時間までの範囲です。トランザクションがコミットされると、ストリーム位置はトランザクション開始時間まで進みます。それ以外の場合は、同じ位置に留まります。
次の例を考えてみましょう:
時間 |
トランザクション1 |
トランザクション2 |
|---|---|---|
1 |
トランザクションを開始します。 |
|
2 |
テーブル |
|
3 |
テーブル |
|
4 |
クエリストリーム |
|
5 |
トランザクションをコミットします。 ストリームがトランザクション内の DML ステートメントで消費された場合、ストリーム位置はトランザクション開始時間まで進みます。 |
|
6 |
トランザクションを開始します。 |
|
7 |
クエリストリーム |
トランザクション1内で、ストリーム s1 へのすべてのクエリは同じレコードセットを参照します。テーブル t1 へのDML 変更は、トランザクションがコミットされたときにのみストリームに記録されます。
トランザクション2で、ストリームへのクエリは、トランザクション1でテーブルに記録された変更を確認します。トランザクション1がコミットされる 前 にトランザクション2が開始した場合、ストリームへのクエリは、ストリームの位置からトランザクション2の開始時刻までのストリームのスナップショットを返します。トランザクション1によってコミットされた変更は表示されません。
Stream columns¶
ストリームには、実際のテーブルの列やデータではなく、ソースオブジェクトのオフセットが保存されます。クエリを実行すると、ストリームは履歴データにアクセスし、ソースオブジェクトと同じ形状(つまり、同じ列名と順序)で履歴データを返しますが、次の追加の列があります。
- METADATA$ACTION:
記録された DML 操作(INSERT、 DELETE)を示します。
- METADATA$ISUPDATE:
操作が UPDATE ステートメントの一部であったかどうかを示します。ソースオブジェクトの行の更新は、ストリーム内の DELETE および INSERT 記録のペアとして表され、メタデータ列の METADATA$ISUPDATE 値は TRUE に設定されます。
ストリームは2つのオフセットの違いを記録することに注意してください。行が追加され、現在のオフセットで更新された場合、デルタの変更は新しい行になります。METADATA$ISUPDATE 行には FALSE 値が記録されます。
- METADATA$ROW_ID:
時間の経過に伴う変更を追跡するための、一意で不変の行 ID を指定します。ストリームのソース・オブジェクトで CHANGE_TRACKING を無効にしてから再度有効にすると、行 ID が変更される可能性があります。
Snowflakeは METADATA$ROW_ID に関して次の保証を提供しています。
METADATA$ROW_ID はストリームのソースオブジェクトに依存します。
例えば、テーブル
table1上のストリームstream1とテーブルtable1上のストリームstream2は、同じ行に対して同じ METADATA$ROW_ID を生成しますが、ビューview1上のストリームstream_viewは、viewがステートメントCREATE VIEW view AS SELECT * FROM table1を使用して定義されていても、stream1と同じ METADATA$ROW_ID を生成することは保証されません。ソースオブジェクト上のストリームとソースオブジェクトのクローン上のストリームは、クローン作成時に存在する行に対して同じ METADATA$ROW_ID を生成します。
ソースオブジェクト上のストリームとソースオブジェクトのレプリカ上のストリームは、複製された行に対して同じ METADATA$ROW_ID を生成します。
Types of streams¶
次のストリーム型は、それぞれによって記録されたメタデータに基づいて使用できます。
- 標準:
標準テーブル、動的テーブル、Snowflake管理Apache Iceberg™テーブル、ディレクトリテーブル、またはビューのストリームをサポートします。 標準(つまりデルタ)ストリームは、挿入、更新、削除(テーブルの切り捨てを含む)を含む、ソースオブジェクトに対するすべての DML の変更を追跡します。このストリーム型は、変更セットで挿入および削除された行で結合を実行して、行レベルのデルタを提供します。たとえば、実質的な効果として、テーブル内の2つのトランザクションポイントの間に挿入されてから削除された行は、デルタで削除されます(つまり、ストリームのクエリ時に返されない)。
注釈
標準ストリームは、地理空間データの変更データを取得できません。地理空間データを含むオブジェクトに追加専用ストリームを作成することをお勧めします。
- 追加のみ:
標準テーブル、動的テーブル、Snowflake管理Apache Iceberg™テーブル、またはビューのストリームでサポートされます。 追加専用ストリームは行の挿入のみを追跡します。更新、削除、および切り捨て操作は、追加専用ストリームではキャプチャされません。例えば、最初に10行がテーブルに挿入され、追加専用ストリームのオフセットを進める前にそのうちの5行が削除された場合、ストリームは10行の挿入行のみを記録することになります。
追加専用ストリームは、追加された行だけを返します。そのため、抽出、ロード、変換(ELT)の標準ストリームや、行の挿入のみに依存する類似のシナリオよりも、パフォーマンスが大幅に向上します。たとえば、追加専用ストリームの行が消費された直後にソーステーブルを切り捨てることができ、記録の削除は、次にストリームがクエリまたは消費されるときにオーバーヘッドに寄与しません。
セカンダリオブジェクトをソースとして使用して、ターゲットアカウントに追加専用ストリームを作成することはサポートされていません。
- 挿入のみ:
外部管理のApache Iceberg™または外部テーブル上のストリームでサポートされています。`挿入専用ストリームは、行の挿入のみを追跡します。挿入されたセットから行を削除する削除操作は記録されません(つまり、操作なし)。たとえば、任意の2つのオフセットの間で、外部テーブルによって参照されるクラウドストレージの場所から ``File1` が削除され、
File2が追加された場合、ストリームはFile1が要求された変更間隔の前またはその期間中に追加されたかどうかに関係なく、File2内の行の記録のみを返します。標準テーブルの CDC データを追跡する場合とは異なり、クラウドストレージ内のファイルの履歴記録へのアクセスは、Snowflake によって管理または保証されません。上書きまたは追加されたファイルは、基本的に新しいファイルとして処理されます。古いバージョンのファイルはクラウドストレージから削除されますが、挿入専用ストリームは削除操作を記録しません。ファイルの新しいバージョンがクラウドストレージに追加され、挿入専用ストリームは行を挿入として記録します。ストリームは、古いファイルバージョンと新しいファイルバージョンの差分を記録しません。Azure AppendBlobs を使用している場合など、追加によって外部テーブルメタデータの自動更新がトリガーされない場合があることに注意してください。
Data flow¶
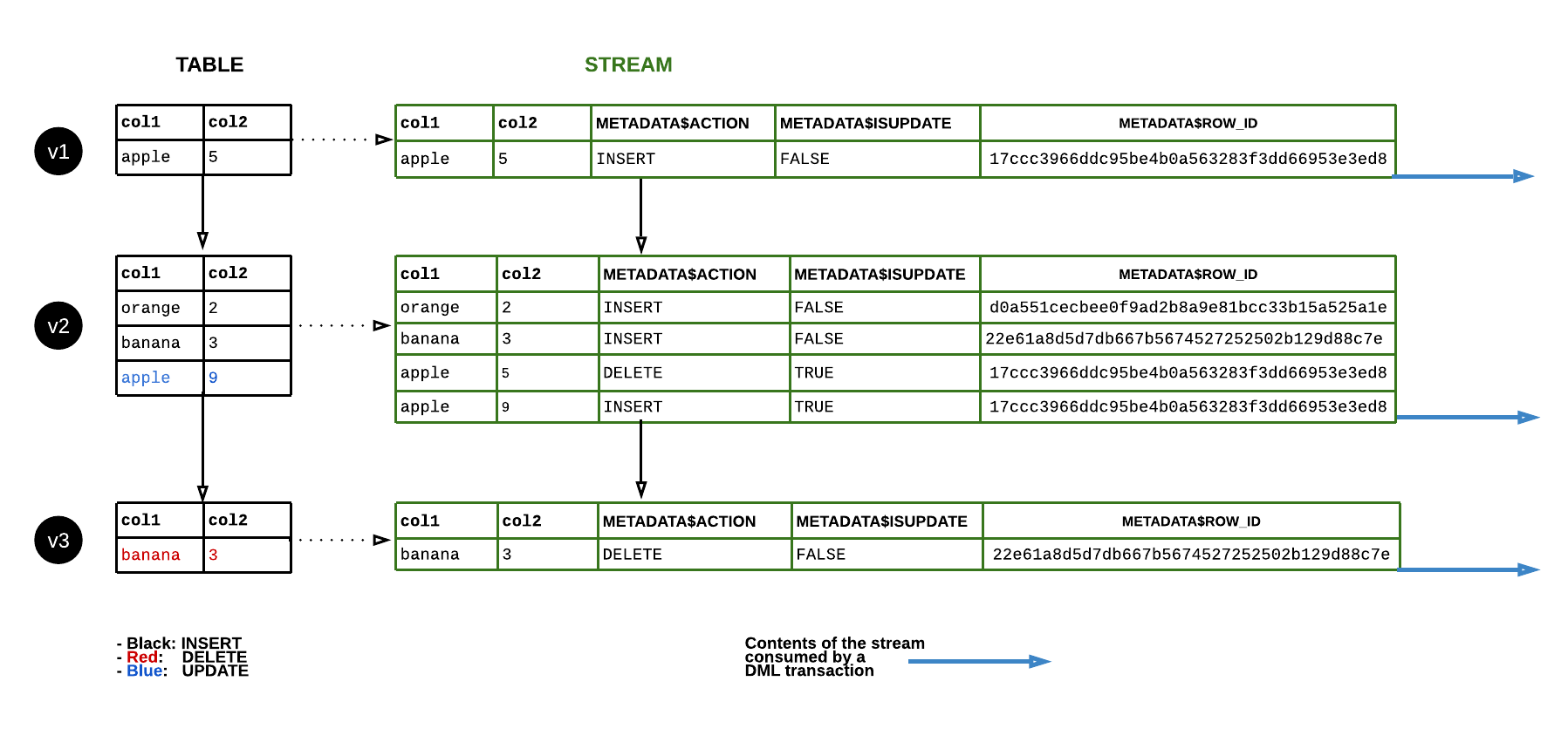
次の図は、ソーステーブルの行が更新されるときに標準ストリームの内容がどのように変化するかを示しています。DML ステートメントがストリームコンテンツを消費するたびに、ストリーム位置が進み、テーブルに対する次の DML の変更(つまり、 テーブルバージョン の変更)を追跡します。
Data retention period and staleness¶
ストリームのオフセットが、ソーステーブル(またはソースビューの基になるテーブル)のデータ保持期間の外にある場合、ストリームは古くなります。古い状態では、ソーステーブルの履歴データと未消費の変更記録にはアクセスできなくなります。新しい変更記録の追跡を継続するには、 CREATE STREAM コマンドを使用してストリームを再作成する必要があります。
ストリームが古くなるのを防ぐには、テーブルの保持期間内に DML ステートメント内でストリーム記録を消費し、 STALE_AFTER タイムスタンプの前(つまり、ソースオブジェクトの拡張データ保持期間内)に変更データを定期的に消費します。さらに、ストリーム上で SYSTEM$STREAM_HAS_DATA を呼び出すと、ストリームが空で、 SYSTEM$STREAM_HAS_DATA 関数が FALSE を返す場合に限り、ストリームが古くなるのを防ぐことができます。
データ保持期間の詳細については、 Time Travelの理解と使用 を参照してください。
注釈
共有テーブルやビュー上のストリームは、それぞれテーブルや基礎となるテーブルのデータ保持期間を延長しません。詳細については、 共有オブジェクトのストリーム をご参照ください。
テーブルのデータ保持期間が14日未満であり、ストリームが消費されていない場合、Snowflakeはこの期間を一時的に延長して、ストリームが古くならないようにします。保持期間は、 Snowflake Edition に関係なく、ストリームのオフセットまで延長され、デフォルトで最大14日間です。Snowflakeがデータ保持期間を延長できる最大日数は、 MAX_DATA_EXTENSION_TIME_IN_DAYS パラメータ値によって決定されます。ストリームが消費されると、拡張データ保持期間はテーブルのデフォルトに戻ります。
以下のテーブルは、 DATA_RETENTION_TIME_IN_DAYS と MAX_DATA_EXTENSION_TIME_IN_DAYS の値の例を示しています。これは、ストリームコンテンツが古くならないように消費されるべき頻度を示しています。
DATA_RETENTION_TIME_IN_DAYS |
MAX_DATA_EXTENSION_TIME_IN_DAYS |
X日でストリームを消費する |
|---|---|---|
14 |
0 |
14 |
1 |
14 |
14 |
0 |
90 |
90 |
ストリームの陳腐化ステータスを確認するには、 DESCRIBE STREAM または SHOW STREAMS コマンドを使用します。STALE_AFTER 列のタイムスタンプは、ソースオブジェクトの拡張データ保持期間です。これは、ストリームがいつ古くなると予測されるか、またはタイムスタンプが過去の場合はいつ古くなったかを示します。このタイムスタンプは、ソースオブジェクトの DATA_RETENTION_TIME_IN_DAYS または MAX_DATA_EXTENSION_TIME_IN_DAYS パラメータ設定の大きい方の値をストリームの最後の消費時間に加算することによって計算されます。
注釈
ソーステーブルのデータ保持期間がスキーマまたはデータベースのレベルで設定されている場合、現在のロールには、 STALE_AFTER 値を計算するためにスキーマまたはデータベースへのアクセス権が必要です。
ストリームの変更データを消費すると、 STALE_AFTER のタイムスタンプが更新されます。STALE_AFTER のタイムスタンプからしばらくの間、ストリームからの読み出しは成功するかもしれませんが、ストリームはいつ古くなってもおかしくありません。STALE 列は、ストリームが古くなっていると予想されるかどうかを示しますが、まだ古くなっていない場合もあります。
ストリームが古くなるのを防ぐには、 STALE_AFTER のタイムスタンプより前(つまり、ソースオブジェクトの拡張データ保持期間内)に、変更データを定期的に消費します。STREAM_HAS_DATA 関数が予期せぬ結果を返す可能性があるため、 STALE_AFTER 期間経過後のストリームからの結果に依存しないでください。
STALE_AFTER のタイムスタンプが過ぎると、たとえ未消費の記録がなくても、ストリームはいつでも古くなる可能性があります。ソースオブジェクトの変更データがある場合でも、ストリームをクエリすると0個の記録が返される場合があります。例えば、追加専用ストリームは行の挿入のみを追跡しますが、更新や削除もソースオブジェクトに変更記録を書き込みます。さらに、再クラスタリングのように、変更データを生成しないテーブル書き込みもあります。ストリームの変化データを消費すると、間に変更データがあるかどうかにかかわらず、そのオフセットは現在に進みます。
重要
オブジェクトを再作成すると(CREATE OR REPLACE TABLE 構文を使用)、その履歴はドロップされ、テーブルまたはビューのストリームも古くなります。さらに、ビューの基になるテーブルを再作成またはドロップすると、ビューのストリームが古くなります。
現在、ストリームとそのソーステーブル(またはソースビューの基になるテーブル)を含むデータベースまたはスキーマのクローンが作成されると、ストリームクローン内の未消費の記録にアクセスできなくなります。この動作は、テーブルの Time Travel と一致しています。テーブルのクローンが作成される場合、テーブルクローンの履歴データは、クローンが作成された時間/時点で開始されます。
ソースオブジェクトの名前を変更しても、ストリームが壊れたり、古くなったりすることはありません。さらに、ソースオブジェクトがドロップされ、同じ名前で新しいオブジェクトが作成される場合、元のオブジェクトにリンクされているストリームは、新しいオブジェクトにリンク されません。
Multiple consumers of streams¶
ユーザーには、オブジェクトの変更記録のコンシューマーごとに個別のストリームを作成することをお勧めします。「コンシューマー」とは、 DML トランザクションを使用してオブジェクトの変更記録を消費するタスク、スクリプト、またはその他のメカニズムを指します。このトピックで前述したように、ストリームがオフセットを進めるのは、 DML トランザクションで使用される場合のみです。これには、Create Table As Select(CTAS)トランザクションや COPY INTO ロケーショントランザクションが含まれます。
Time Travelが使用されていない限り、単一ストリーム内の変更データのさまざまなコンシューマーはさまざまなデルタを取得します。DML トランザクションを使用して、ストリーム内の最新のオフセットからキャプチャされた変更データが使用されると、ストリームはオフセットを進めます。次のコンシューマーは、変更データを使用できなくなります。オブジェクトの 同じ 変更データを使用するには、オブジェクトに複数のストリームを作成します。ストリームはソースオブジェクトのオフセットのみを保存し、実際のテーブル列のデータは保存 しません。したがって、大きなコストをかけずに、オブジェクトに対する任意の数のストリームを作成できます。
Streams on views¶
Streams on Viewsは、ローカルビューと、セキュアビューを含む、Snowflake Secure Data Sharingを使用して共有されるビューの両方をサポートします。現在、ストリームはマテリアライズドビューの変更を追跡できません。
ストリームは、次の要件を満たすビューに制限されます。
- 基になるテーブル:
基になるテーブルは、すべてネイティブテーブルである必要があります。
ビューは以下の演算子のみ適用できます。
Projections
Filters
内部結合またはクロス結合
UNION ALL
完全に展開されたクエリがこの要件表の他の要件を満たす限り、 FROM 句の入れ子ビューおよびサブクエリはサポートされます。
- クエリを表示する:
一般的な要件:
クエリは任意の数の列を選択できます。
クエリには、任意の数の WHERE 述語を含めることができます。
次の操作を含むビューはまだサポートされていません。
GROUP BY 句
QUALIFY 句
FROM 句にないサブクエリ
相関サブクエリ
LIMIT 句
DISTINCT 句
関数:
選択リストの関数は、システム定義のスカラー関数である必要があります。
- 変更追跡:
基になるテーブルで変更追跡を有効にする必要があります。
ビューにストリームを作成する前に、ビューの基になるテーブルの変更追跡を有効にする必要があります。手順については、 Enabling change tracking on views and underlying tables をご参照ください。
Join results behavior¶
結合を含むビューへの変更を追跡するストリームの結果を調べる場合、どのデータが結合されているかを理解することが重要です。ストリームオフセットが右側のテーブルと結合されているために左側のテーブルで発生した変更、ストリームオフセットが左側のテーブルと結合されているために右側のテーブルで発生した変更、およびストリームオフセットが左右両方のテーブルで結合されているために両方のテーブルで発生した変更などです。
次の例を考えてみましょう:
次の2つのテーブルが作成されます。
id で2つのテーブルを結合するビューが作成されます。各テーブルには、他と結合する単一の行があります。
ビューへの変更を追跡するストリームが作成されます。
ビューにはエントリが1つあり、ストリームにはエントリがありません。これは、ストリームの現在のオフセット以降、テーブルに変更が加えられていないためです。
基になるテーブルが更新された後に ordersByCustomerStream を選択すると、 orders x Δ customers + Δ orders x customers + Δ orders x Δ customers の記録が生成されます。
Δ
ordersおよび Δcustomersは、ストリームオフセット以降に各テーブルに発生した変更です。ordersとcustomersは、現在のストリームオフセットにおけるテーブルのコンテンツの合計です。
Snowflakeでの最適化により、この式を計算するコストは、入力のサイズに線形的に比例するとは限らないことに注意してください。
別の結合行が orders に挿入されると、 ordersByCustomer に新しい行が追加されます。
ordersByCustomersStream から選択すると1つの行が生成されます。Δ orders x customers には新しい挿入が含まれ、 orders x Δ customers + Δ orders x Δ customers は空であるためです。
別の結合行が customers に挿入された場合、 ordersByCustomer には合計3つの 新しい 行が含まれます。
ordersByCustomersStream から選択すると3行が生成されます。Δ orders x customers、 orders x Δ customers、および Δ orders x Δ customers はそれぞれ1行を生成するためです。
追加専用のストリームの場合、 Δ orders と Δ customers には行の挿入のみが含まれ、 orders と customers にはストリームオフセットの前に発生した更新を含むテーブルの完全な内容が含まれることに注意してください。
CHANGES clause: Read-only alternative to streams¶
ストリームの代わりに、Snowflakeは SELECT ステートメントの CHANGES 句を使用して、テーブルまたはビューの変更追跡メタデータのクエリをサポートします。CHANGES 句を使用すると、明示的なトランザクションオフセットを使用してストリームを作成しなくても、2つの時点間で変更追跡メタデータをクエリできます。CHANGES 句を使用しても、オフセットは前倒し されません (つまり、レコードを使用)。複数のクエリにより、異なるトランザクションの開始と終了の間で変更追跡メタデータを取得できます。このオプションでは、 AT | BEFORE 句を使用してメタデータのトランザクションの開始点を指定する必要があります。変更追跡間隔のエンドポイントは、オプションの END 句を使用して設定できます。
ストリームは、現在のトランザクション テーブルバージョン を保存し、ほとんどのシナリオで CDC 記録の適切なソースです。任意の期間のオフセットを管理する必要があるまれなシナリオでは、 CHANGES 句を使用できます。
現在、変更追跡メタデータが記録される前に、次がtrueである必要があります。
- テーブル:
テーブルで変更追跡を有効にする(ALTER TABLE ... CHANGE_TRACKING = TRUE を使用)か、テーブルでストリームを作成します(CREATE STREAM を使用)。
- ビュー:
ビューとその基になるテーブルで変更の追跡を有効にします。手順については、 Enabling change tracking on views and underlying tables をご参照ください。
変更追跡を有効にすると、いくつかの非表示の列がテーブルに追加され、変更追跡メタデータの保存が開始されます。これら非表示の CDC データ列の値は、ストリーム メタデータ列 への入力を提供します。列は少量のストレージを消費します。
これらの条件のいずれかが満たされる前の期間では、オブジェクトの変更追跡メタデータは使用できません。
Required access privileges¶
ストリームのクエリには、少なくとも次のロール権限を持つロールが必要です。
オブジェクト |
権限 |
注意 |
|---|---|---|
データベース |
USAGE |
|
スキーマ |
USAGE |
|
ストリーム |
SELECT |
|
テーブル |
SELECT |
テーブルのみのストリーム。 |
ビュー |
SELECT |
ビューのみのストリーム。 |
外部ステージ |
USAGE |
ディレクトリテーブル(外部ステージ上)のみのストリーム |
内部ステージ |
READ |
ディレクトリテーブル(内部ステージ)のみのストリーム |
Billing for streams¶
このトピックの データ保持期間と陳腐化 で説明したように、ストリームが定期的に消費されない場合、Snowflakeは、ソーステーブルまたはソースビューの基になるテーブルのデータ保持期間を 一時的に 延長します。テーブルのデータ保持期間が14日未満の場合、アカウントの Snowflakeエディション に関係なく、期間はストリームトランザクションオフセット より短く 、または14日(テーブルのデータ保持期間が14日未満の場合)に、バックグラウンドで延長されます。
拡張データ保持期間には追加のストレージが必要であり、これは毎月のストレージ料金に反映されます。
ストリームに関連する主なコストは、仮想ウェアハウスがストリームをクエリするために使用する処理時間です。これらの料金は、なじみのあるSnowflakeクレジットとして請求書に表示されます。
制限事項¶
ストリームには以下の制限事項が適用されます。
外部カタログを使用する Apache Iceberg™ テーブルでは、標準ストリームまたは追加専用ストリームを使用できません。(挿入のみのストリームはサポートされています。)
GROUP BY 句を持つビューの変更を追跡することはできません。
NOT NULL にする列を追加または変更した後、ストリームに対するクエリは、ストリームが許されない NULL 値を持つ行を出力すると失敗する可能性があります。これは、ストリームのスキーマが現在の NOT NULL 制約を強制しており、ストリームが返す履歴データと一致しないために起こります。
Streams on Views によって タスクがトリガーされる と、クエリ内の結合、集約、フィルターに関係なく、Streams on Views クエリによって参照されるテーブルへの変更もタスクのトリガーとなります。
ストリームは、パーティション分割された外部テーブルまたは外部カタログによって管理されるパーティション分割された Apache Iceberg™ テーブルではサポートされません。