Introduction to streams¶
Um objeto de fluxo registra as alterações feitas na linguagem de manipulação de dados (DML) nas tabelas, incluindo inserções (inclusive COPY INTO), atualizações e exclusões, bem como metadados sobre cada alteração, para que as ações possam ser executadas usando os dados alterados. Esse processo é chamado de captura de dados de alteração (CDC). Este tópico introduz conceitos-chave para a captura de alterações de dados usando fluxos.
Um fluxo de tabela individual rastreia as alterações feitas nas linhas em uma tabela de origem. Um fluxo de tabela (também chamado simplesmente de «fluxo») disponibiliza uma «tabela de alterações» com o que mudou, no nível da linha, entre dois pontos de tempo transacionais em uma tabela. Isso permite consultar e consumir uma sequência de registros de alterações de forma transacional.
É possível criar fluxos para consultar dados de alteração sobre os seguintes objetos:
Tabelas padrão, incluindo tabelas compartilhadas.
Exibições, incluindo exibições seguras
Offset storage¶
Quando criado, um fluxo tira logicamente um instantâneo inicial de cada linha do objeto de origem (por exemplo, tabela, tabela externa ou as tabelas subjacentes para uma exibição) inicializando um ponto no tempo (chamado offset) como a versão transacional atual do objeto. O sistema de rastreamento de alterações utilizado pelo fluxo então registra informações sobre as alterações do DML após esse instantâneo ter sido tirado. Os registros de alterações fornecem o estado de uma linha antes e depois da alteração. As informações de alteração espelham a estrutura da coluna do objeto de origem rastreado e incluem colunas adicionais de metadados que descrevem cada evento de alteração.
Os fluxos usam o esquema de tabela atual. No entanto, como os fluxos podem ler dados excluídos para rastrear as alterações ao longo do tempo, qualquer alteração de esquema incompatível entre o deslocamento e o avanço pode causar falhas na consulta.
Note que um fluxo em si não contém quaisquer dados de tabela. Um fluxo só armazena um offset para o objeto de origem e retorna registros CDC aproveitando o histórico de versões para o objeto de origem. Quando o primeiro fluxo para uma tabela é criado, várias colunas ocultas são adicionadas à tabela de origem e começam a armazenar metadados de rastreamento de alterações. Estas colunas consomem uma pequena quantidade de armazenamento. Os registros CDC retornados ao consultar um fluxo dependem de uma combinação do offset armazenado no fluxo e dos metadados de rastreamento de alterações armazenados na tabela. Observe que para Streams on Views, o rastreamento de alterações deve ser habilitado explicitamente para a exibição e tabelas subjacentes para adicionar as colunas ocultas a estas tabelas.
Pode ser útil pensar em um fluxo como um marcador, que indica um ponto no tempo nas páginas de um livro (ou seja, o objeto de origem). Um marcador pode ser descartado e outros marcadores podem ser inseridos em lugares diferentes em um livro. Da mesma forma, um fluxo pode ser descartado e outros fluxos podem ser criados no mesmo momento ou em momentos diferentes (seja criando os fluxos consecutivamente em momentos diferentes ou usando o Time Travel) para consumir os registros de alterações de um objeto no mesmo offset ou em offsets diferentes.
Um exemplo de um consumidor de registros CDC é um pipeline de dados, no qual apenas os dados em tabelas de preparação que mudaram desde a última extração são transformados e copiados para outras tabelas.
Table versioning¶
Uma nova versão da tabela é criada sempre que uma transação que inclui uma ou mais instruções DML é confirmada na tabela. Isto se aplica aos seguintes tipos de tabela:
Tabelas padrão
Tabelas de diretório
Tabelas dinâmicas
Tabelas externas
Tabelas Apache Iceberg™
Tabelas subjacentes para uma exibição
No histórico de transações de uma tabela, um offset de fluxo está localizado entre duas versões de tabela. A consulta de um fluxo retorna as alterações causadas por transações confirmadas após o offset e na hora atual ou antes dela.
O exemplo a seguir mostra uma tabela de origem com 10 versões confirmadas na linha do tempo. O offset do fluxo s1 está entre as versões de tabela v3 e v4. Quando o fluxo é consultado (ou consumido), os registros retornados incluem todas as transações entre a versão de tabela v4, a versão imediatamente após o offset do fluxo na linha de tempo da tabela, e v10, a versão de tabela mais recente confirmada na linha de tempo, inclusive.
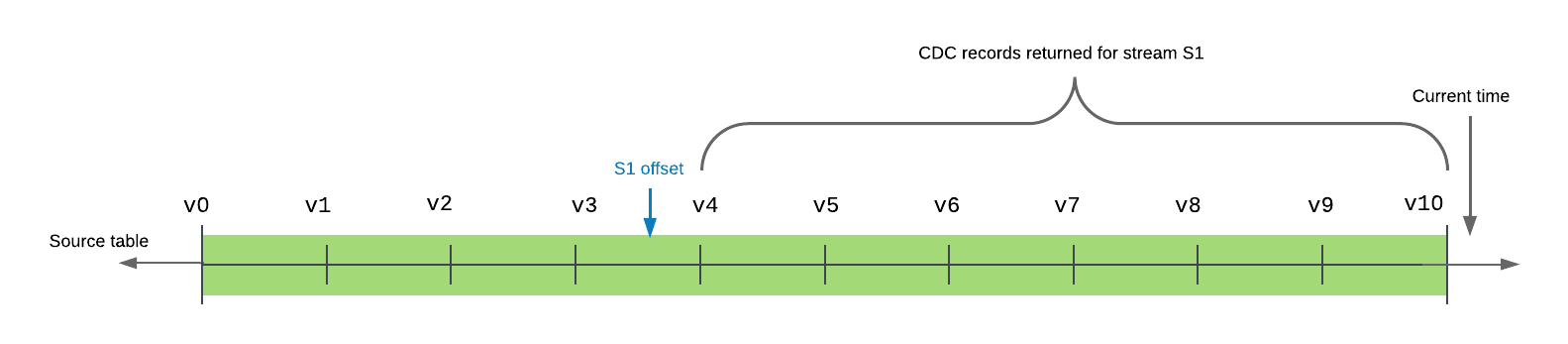
Um fluxo fornece o conjunto mínimo de alterações desde o offset atual até a versão atual da tabela.
Múltiplas consultas podem consumir independentemente os mesmos dados de alteração de um fluxo sem alterar o offset. Um fluxo avança segundo o offset somente quando é usado em uma transação DML. Isso inclui uma transação Create Table As Select (CTAS) ou uma transação de local COPY INTO e esse comportamento se aplica a transações explícitas e de autocommit. (Por padrão, quando uma instrução DML é executada, uma transação de confirmação automática é implicitamente iniciada e a transação é confirmada na conclusão da instrução. Este comportamento é controlado com o parâmetro AUTOCOMMIT). Apenas consultar um fluxo não avança seu offset, mesmo dentro de uma transação explícita; o conteúdo do fluxo precisa ser consumido em uma instrução DML.
Nota
Para avançar o offset de um fluxo para a versão de tabela atual sem consumir os dados de alteração em uma operação DML, complete uma das seguintes ações:
Recrie o fluxo (usando a sintaxe CREATE OR REPLACE STREAM).
Insira os dados de alteração atuais em uma tabela temporária. Na instrução INSERT, consulte o fluxo mas inclua uma cláusula WHERE que filtra todos os dados de alteração (por exemplo,
WHERE 0 = 1).
Quando uma instrução SQL consulta um fluxo dentro de uma transação explícita, o fluxo é consultado no ponto de avanço do fluxo (ou seja, o carimbo de data/hora) quando a transação começou, e não quando a instrução foi executada. Este comportamento diz respeito tanto a instruções DML como instruções CREATE TABLE … AS SELECT (CTAS) que preenchem uma nova tabela com linhas de um fluxo existente.
Uma instrução DML que seleciona de um fluxo consome todos os dados de alteração no fluxo, desde que a transação seja confirmada com sucesso. Para garantir que múltiplas instruções acessem os mesmos registros de alterações no fluxo, cerque-as com uma instrução de transação explícita (BEGIN … COMMIT). Isto bloqueia o fluxo. Atualizações DML do objeto de origem em transações paralelas são rastreadas pelo sistema de rastreamento de modificações, mas não atualizam o fluxo até que a instrução da transação explícita seja confirmada e os dados de alteração existentes sejam consumidos.
Repeatable read isolation¶
Os fluxos suportam o isolamento de leitura repetível. No modo de leitura repetível, múltiplas instruções SQL dentro de uma transação veem o mesmo conjunto de registros em um fluxo. Isto difere do modo de leitura confirmada com suporte por tabelas, no qual as instruções veem quaisquer alterações feitas por instruções anteriores executadas dentro da mesma transação, mesmo que essas alterações ainda não estejam confirmadas.
Os registros delta retornados pelos fluxos em uma transação são o intervalo desde a posição atual do fluxo até a hora de início da transação. A posição do fluxo avança para a hora de início da transação se a transação for confirmada; caso contrário, ela permanece na mesma posição.
Considere o seguinte exemplo:
Hora |
Transação 1 |
Transação 2 |
|---|---|---|
1 |
Inicie a transação. |
|
2 |
Consulte o fluxo |
|
3 |
Atualize as linhas na tabela |
|
4 |
Consulte o fluxo |
|
5 |
Confirme a transação. Se o fluxo foi consumido em instruções DML dentro da transação, a posição do fluxo avança para a hora de início da transação. |
|
6 |
Inicie a transação. |
|
7 |
Consulte o fluxo |
Dentro da Transação 1, todas as consultas do fluxo s1 veem o mesmo conjunto de registros. Alterações de DML na tabela t1 são registradas apenas no fluxo quando a transação é confirmada.
Na Transação 2, consultas ao fluxo veem as alterações registradas na tabela na Transação 1. Observe que se a Transação 2 tivesse começado antes da Transação 1 ter sido confirmada, consultas ao fluxo teriam retornado um instantâneo do fluxo desde a posição do fluxo até a hora de início da Transação 2 e não veriam nenhuma alteração confirmada pela Transação 1.
Stream columns¶
Um fluxo armazena um offset para o objeto de origem, e não quaisquer colunas ou dados reais da tabela. Quando consultado, um fluxo acessa e retorna os dados históricos na mesma forma que o objeto de origem (ou seja, os mesmos nomes de coluna e ordenação) com as seguintes colunas adicionais:
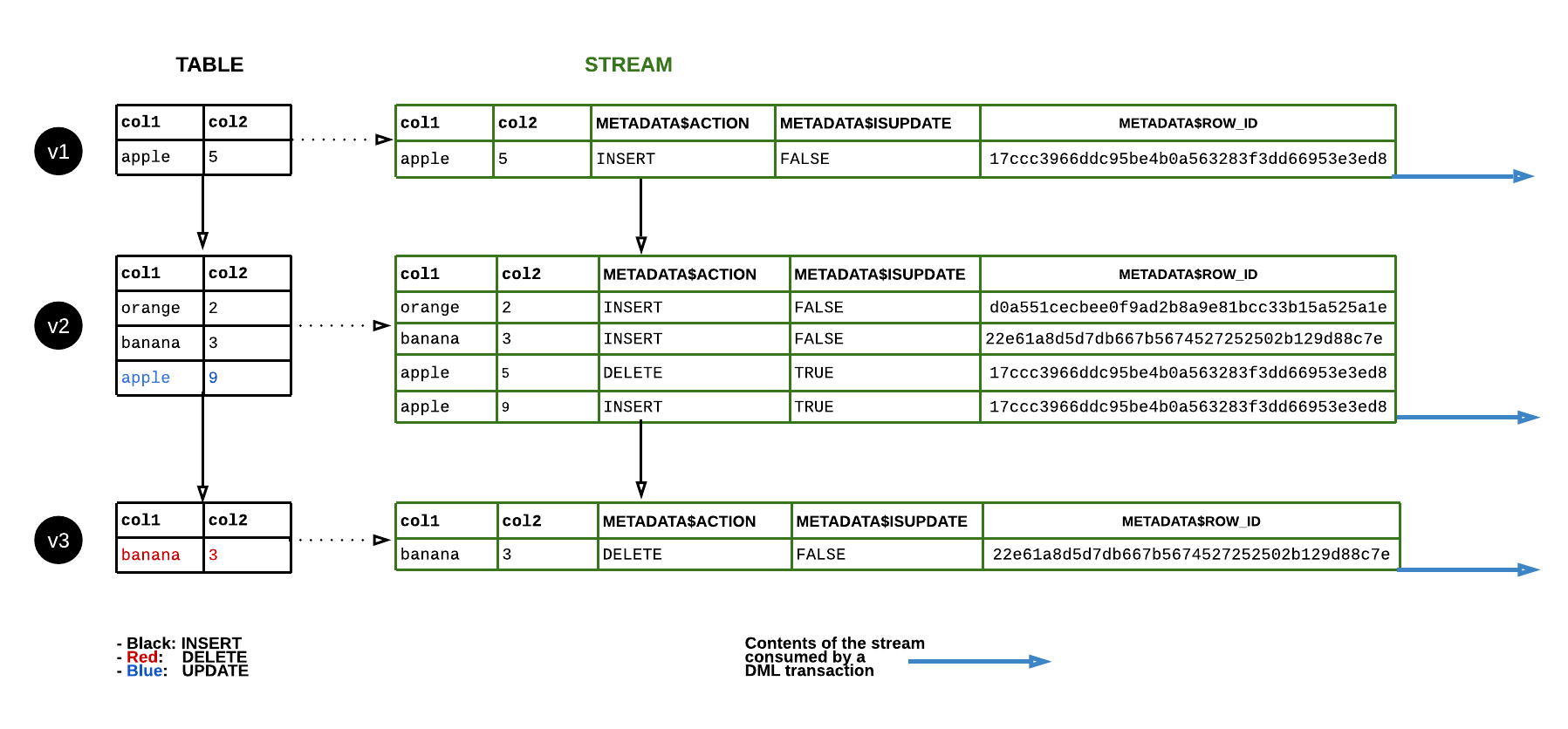
- METADATA$ACTION:
Indica a operação DML (INSERT, DELETE) registrada.
- METADATA$ISUPDATE:
Indica se a operação fazia parte de uma instrução UPDATE. As atualizações das linhas no objeto de origem são representadas como um par de registros DELETE e INSERT no fluxo com valores das coluna de metadados METADATA$ISUPDATE definidos como TRUE.
Observe que os fluxos registram as diferenças entre dois offsets. Se uma linha for adicionada e depois atualizada no offset atual, a alteração do delta é uma nova linha. A linha METADATA$ISUPDATE registra um valor FALSE.
- METADATA$ROW_ID:
Especifica um ID de linha exclusiva e imutável para rastrear alterações ao longo do tempo. Se CHANGE_TRACKING for desativado e posteriormente reativado no objeto de origem do fluxo, o ID de linha poderá ser alterado.
Snowflake oferece as seguintes garantias em relação a METADATA$ROW_ID:
O METADATA$ROW_ID depende do objeto de origem do fluxo.
Por exemplo, um fluxo
stream1na tabelatable1e um fluxostream2na tabelatable1produzem os mesmos METADATA$ROW_IDs para as mesmas linhas, mas um fluxostream_viewna exibiçãoview1não é garantido que produza os mesmos METADATA$ROW_IDs questream1, mesmo queviewseja definido usando a instruçãoCREATE VIEW view AS SELECT * FROM table1.Um fluxo em um objeto de origem e um fluxo no clone do objeto de origem produzem os mesmos METADATA$ROW_IDs para as linhas que existem no momento da clonagem.
Um fluxo em um objeto de origem e um fluxo na réplica do objeto de origem produzem os mesmos METADATA$ROW_IDs para as linhas que foram replicadas.
Types of streams¶
Os seguintes tipos de fluxo estão disponíveis com base nos metadados registrados por cada um:
- Padrão:
Compatível com fluxos em tabelas padrão, tabelas dinâmicas, tabelas Apache Iceberg™ gerenciadas pelo Snowflake, tabelas de diretório ou exibições. Um fluxo padrão (ou seja, delta) rastreia todas as alterações de DML no objeto de origem, inclusive inserções, atualizações e exclusões (inclusive truncamentos de tabela). Este tipo de fluxo realiza uma junção nas linhas inseridas e excluídas no conjunto de alterações para fornecer o delta de nível de linha. Como efeito líquido, por exemplo, uma linha que é inserida e depois excluída entre dois pontos de tempo transacionais em uma tabela é removida no delta (ou seja, não é retornada quando o fluxo é consultado).
Nota
Fluxos padrão não podem recuperar dados geoespaciais de alteração. Recomendamos a criação de fluxos apenas para anexação em objetos que contenham dados geoespaciais.
- Apenas para anexação:
Compatível com fluxos em tabelas padrão, tabelas dinâmicas, tabelas Apache Iceberg™ gerenciadas pelo Snowflake ou exibições. Um fluxo somente de acréscimo rastreia exclusivamente as inserções de linha. As operações de atualização, exclusão e truncamento não são capturadas por fluxos apenas para anexação. Por exemplo, se 10 linhas forem inicialmente inseridas em uma tabela e, em seguida, 5 dessas linhas forem excluídas antes de avançar o deslocamento para um fluxo somente para anexação, o fluxo registrará apenas as 10 linhas inseridas.
Um fluxo somente para anexação retorna especificamente as linhas anexadas, tornando-o notavelmente mais eficiente do que um fluxo padrão para extração, carregamento e transformação (ELT) e cenários semelhantes que dependem exclusivamente de inserções de linha. Por exemplo, uma tabela de origem pode ser truncada imediatamente depois que as linhas de um fluxo apenas para anexação são consumidas, e as exclusões de registros não contribuirão para sobrecarga na próxima vez em que o fluxo for consultado ou consumido.
Não há suporte para a criação de fluxos somente para anexação em uma conta de destino usando um objeto secundário como origem.
- Apenas para inserção:
Compatível com fluxos no Apache Iceberg™ gerenciado externamente ou em tabelas externas. Um fluxo somente de inserção rastreia apenas inserções de linhas; ele não registra operações de exclusão que removem linhas de um conjunto inserido (ou seja, sem operação). Por exemplo, entre quaisquer dois deslocamentos, se
File1for removido do local de armazenamento em nuvem referenciado pela tabela externa eFile2for adicionado, o fluxo retornará registros apenas para as linhas emFile2, independentemente deFile1ter sido adicionado antes ou dentro do intervalo de alteração solicitado. Diferentemente do rastreamento de dados do CDC para tabelas padrão, o acesso aos registros históricos de arquivos no armazenamento em nuvem não é regido pelo Snowflake nem garantido por ele.Os arquivos sobrescritos ou anexados são essencialmente tratados como novos arquivos: a versão antiga do arquivo é removida do armazenamento em nuvem, mas o fluxo apenas para inserção não registra a operação de exclusão. A nova versão do arquivo é adicionada ao armazenamento em nuvem, e o fluxo apenas para inserção registra as linhas como inserções. O fluxo não registra a diferença entre as versões antiga e nova do arquivo. Observe que os anexos podem não acionar uma atualização automática dos metadados de tabela externa, como quando se usa Azure AppendBlobs.
Data flow¶
O diagrama a seguir mostra como o conteúdo de um fluxo padrão muda conforme as linhas na tabela de origem são atualizadas. Sempre que uma instrução DML consome o conteúdo do fluxo, a posição do fluxo avança para acompanhar o próximo conjunto de alterações DML na tabela (ou seja, as alterações em uma versão da tabela):
Data retention period and staleness¶
Um fluxo torna-se desatualizado quando seu offset está fora do período de retenção de dados para sua tabela de origem (ou para as tabelas subjacentes para uma exibição de origem). Em um estado desatualizado, os dados históricos e quaisquer registros de alterações não consumidos da tabela de origem não estarão mais acessíveis. Para continuar rastreando novos registros de alterações, você deve recriar o fluxo usando o comando CREATE STREAM.
Para evitar que um fluxo fique desatualizado, consuma os registros de fluxo dentro de uma instrução DML durante o período de retenção da tabela e consuma regularmente seus dados de alteração antes do carimbo de data/hora STALE_AFTER (ou seja, dentro do período de retenção de dados estendido para o objeto de origem). Além disso, chamar SYSTEM$STREAM_HAS_DATA no fluxo evita que ele fique desatualizado, desde que o fluxo esteja vazio e a função SYSTEM$STREAM_HAS_DATA retorne FALSE.
Para obter mais informações sobre os períodos de retenção de dados, consulte Compreensão e uso do Time Travel.
Nota
Os fluxos em tabelas ou exibições compartilhadas não estendem o período de retenção de dados da tabela ou das tabelas subjacentes, respectivamente. Para obter mais informações, consulte Fluxos em objetos compartilhados.
Se o período de retenção de dados para uma tabela for inferior a 14 dias, e se um fluxo não tiver sido consumido, o Snowflake estende temporariamente este período para evitar que o fluxo se torne desatualizado. O período de retenção é estendido para o offset do fluxo, até um máximo de 14 dias, por padrão, independentemente da edição do Snowflake. O número máximo de dias para os quais o Snowflake pode estender o período de retenção de dados é determinado pelo valor do parâmetro MAX_DATA_EXTENSION_TIME_IN_DAYS. Depois que o fluxo é consumido, o período de retenção de dados estendido retorna ao padrão da tabela.
A tabela a seguir mostra exemplos de valores DATA_RETENTION_TIME_IN_DAYS e MAX_DATA_EXTENSION_TIME_IN_DAYS, indicando com que frequência o conteúdo do fluxo deve ser consumido para evitar a desatualização:
DATA_RETENTION_TIME_IN_DAYS |
MAX_DATA_EXTENSION_TIME_IN_DAYS |
Consumo de fluxos em X dias |
|---|---|---|
14 |
0 |
14 |
1 |
14 |
14 |
0 |
90 |
90 |
Para verificar o status de desatualização de um fluxo, use o comando DESCRIBE STREAM ou SHOW STREAMS. O carimbo de data/hora da coluna STALE_AFTER é o período de retenção de dados estendido para o objeto de origem. Ele mostra quando o fluxo está previsto para ficar desatualizado ou quando ele ficou desatualizado, caso o carimbo de data/hora esteja no passado. Este carimbo de data/hora é calculado adicionando o maior valor da configuração dos parâmetros DATA_RETENTION_TIME_IN_DAYS ou MAX_DATA_EXTENSION_TIME_IN_DAYS para o objeto de origem ao último horário de consumo do fluxo.
Nota
Se o período de retenção de dados da tabela de origem for definido no nível do esquema ou do banco de dados, a função atual deverá ter acesso ao esquema ou ao banco de dados para calcular o valor STALE_AFTER.
Consumir dados de alteração para um fluxo atualiza o carimbo de data/hora STALE_AFTER. Embora a leitura do fluxo possa ser bem-sucedida por algum tempo após o carimbo de data/hora STALE_AFTER, o fluxo pode ficar desatualizado a qualquer momento. A coluna STALE indica se é esperado que o fluxo fique desatualizado, embora possa não estar ainda.
Para evitar que um fluxo fique desatualizado, consuma regularmente seus dados de alteração antes do carimbo de data/hora STALE_AFTER (ou seja, dentro do período de retenção de dados estendido para o objeto de origem). Não confie nos resultados de um fluxo após o período STALE_AFTER ter decorrido, pois a função STREAM_HAS_DATA pode retornar resultados inesperados.
Depois que o carimbo de data/hora STALE_AFTER tiver passado, o fluxo pode se tornar desatualizado a qualquer momento, mesmo que não haja registros não consumidos. Consultar um fluxo pode retornar 0 registros, mesmo se houver dados de alteração para o objeto de origem. Por exemplo, um fluxo de dados apenas para anexação rastreia apenas inserções de linha, mas atualiza e exclui, bem como grava registros de alteração em um objeto de origem. Além disso, algumas gravações de tabela, como o reclustering, não produzem dados de alteração. O consumo dos dados de alteração para um fluxo avança seu offset para o presente, independentemente de haver dados de alteração intervenientes.
Importante
Recriar um objeto (usando a sintaxe CREATE OR REPLACE TABLE) descarta seu histórico, o que também faz com que qualquer fluxo na tabela ou exibição fique desatualizado. Além disso, recriar ou descartar qualquer uma das tabelas subjacentes para uma exibição faz com que qualquer fluxo na exibição se torne desatualizado.
Atualmente, quando um banco de dados ou esquema que contém um fluxo e sua tabela de origem (ou as tabelas subjacentes para uma exibição de origem) é clonado, quaisquer registros não consumidos no clone do fluxo ficam inacessíveis. Este comportamento é consistente com o Time Travel para tabelas. Se uma tabela for clonada, os dados históricos para o clone da tabela começam no momento/ponto em que o clone foi criado.
Renomear um objeto de origem não quebra um fluxo ou faz com que ele se torne desatualizado. Além disso, se um objeto de origem é abandonado e um novo objeto é criado com o mesmo nome, quaisquer fluxos ligados ao objeto original não são vinculados ao novo objeto.
Multiple consumers of streams¶
Recomendamos que os usuários criem um fluxo separado para cada consumidor de registros de alterações para um objeto. “Consumidor” refere-se a uma tarefa, script ou outro mecanismo que consome os registros de alteração para um objeto usando uma transação DML. Conforme declarado anteriormente neste tópico, um fluxo avança seu deslocamento somente quando é usado em uma transação DML. Isso inclui uma transação Create Table As Select (CTAS) ou uma transação de local COPY INTO.
Consumidores diferentes de dados de alteração em um único fluxo recuperam deltas diferentes, a menos que o Time Travel seja usado. Quando os dados de alteração capturados do último offset em um fluxo são consumidos usando uma transação DML, o fluxo avança segundo o offset. Os dados de alteração não estão mais disponíveis para o próximo consumidor. Para consumir os mesmos dados de alteração de um objeto, crie múltiplos fluxos para o objeto. Um fluxo armazena apenas um offset para o objeto de origem e não quaisquer dados reais da coluna da tabela; portanto, você pode criar qualquer número de fluxos para um objeto sem incorrer em custos significativos.
Streams on views¶
Streams on Views oferecem suporte tanto a exibições locais quanto exibições compartilhadas usando o Snowflake Secure Data Sharing, incluindo exibições seguras. Atualmente, os fluxos não podem rastrear alterações em exibições materializadas.
Os fluxos são limitados a exibições que satisfazem os seguintes requisitos:
- Tabelas subjacentes:
Todas as tabelas subjacentes devem ser tabelas nativas.
A exibição pode aplicar apenas as seguintes operações:
Projeções
Filtros
Junções internas ou cruzadas
UNION ALL
Exibições aninhadas e subconsultas na cláusula FROM são compatíveis, desde que a consulta totalmente expandida atenda aos outros requisitos desta tabela de requisitos.
- Consulta de exibição:
Requisitos gerais:
A consulta pode selecionar qualquer número de colunas.
A consulta pode conter qualquer número de predicados WHERE.
Exibições com as seguintes operações ainda não têm suporte:
Cláusulas GROUP BY
Cláusulas QUALIFY
Subconsultas não incluídas na cláusula FROM.
Subconsultas correlacionadas
Cláusulas LIMIT
Cláusulas DISTINCT
Funções:
As funções na lista de seleção devem ser funções escalares definidas pelo sistema.
- Rastreamento de alterações:
O rastreamento de alterações deve estar habilitado nas tabelas subjacentes.
Antes de criar um fluxo em uma exibição, você deve ativar o controle de alterações nas tabelas subjacentes da exibição. Para obter instruções, consulte Enabling change tracking on views and underlying tables.
Join results behavior¶
Ao examinar os resultados de um fluxo que rastreia as mudanças para uma exibição que contém uma junção, é importante entender quais dados estão sendo unidos. Mudanças que ocorreram na tabela da esquerda desde que o offset do fluxo está sendo unido com a tabela da direita, mudanças na tabela da direita desde que o offset do fluxo está sendo unido com a tabela da esquerda, e mudanças em ambas as tabelas desde que o offset do fluxo está sendo unido um com o outro.
Considere o seguinte exemplo:
Duas tabelas são criadas:
Uma exibição é criada para unir as duas tabelas em id. Cada tabela tem uma única linha que se une à outra:
É criado um fluxo que rastreia as mudanças na exibição:
A exibição tem uma entrada e o fluxo não tem nenhuma desde que não houve mudanças nas tabelas desde o offset atual do fluxo:
Uma vez feitas as atualizações nas tabelas subjacentes, selecionando ordersByCustomerStream, serão produzidos registros de orders x Δ customers + Δ orders x customers + Δ orders x Δ customers onde:
Δ
orderse Δcustomerssão as mudanças que ocorreram em cada tabela desde o offset do fluxo.ordens e clientes são o conteúdo total das tabelas no offset de fluxo atual.
Note que, devido às otimizações no Snowflake, o custo de computação desta expressão nem sempre é linearmente proporcional ao tamanho das entradas.
Se outra linha de junção for inserida em orders então ordersByCustomer terá uma nova linha:
A seleção de ordersByCustomersStream produz uma linha porque Δ orders x customers contém a nova inserção e orders x Δ customers + Δ orders x Δ customers está vazio:
Se outra linha de junção for então inserida em customers, então ordersByCustomer terá um total de três novas linhas:
A seleção de ordersByCustomersStream produz três linhas porque Δ orders x customers, orders x Δ customers e Δ orders x Δ customers cada uma produzirá uma linha:
Observe que para os fluxos apenas para anexação, Δ orders e Δ customers conterão apenas inserções de linha, enquanto orders e customers conterão o conteúdo completo das tabelas, incluindo quaisquer atualizações que tenham ocorrido antes do offset de fluxo.
CHANGES clause: Read-only alternative to streams¶
Como alternativa aos fluxos, o Snowflake suporta a consulta de metadados de rastreamento de alterações para tabelas ou exibições, usando a cláusula CHANGES para instruções SELECT. A cláusula CHANGES permite consultar os metadados de rastreamento de alterações entre dois pontos no tempo sem ter que criar um fluxo com um offset transacional explícito. Usar a cláusula CHANGES não avança o offset (ou seja, consome os registros). Consultas múltiplas podem recuperar os metadados de rastreamento de alterações entre diferentes pontos de extremidade iniciais e finais transacionais. Esta opção requer a especificação de um ponto inicial transacional para os metadados usando uma cláusula AT | BEFORE; o ponto final para o intervalo de rastreamento de alterações pode ser definido usando a cláusula opcional END.
Um fluxo armazena a versão de tabela transacional atual e é a origem apropriada de registros CDC na maioria dos cenários. Para cenários pouco frequentes que requerem o gerenciamento do offset por períodos de tempo arbitrários, a cláusula CHANGES está disponível para seu uso.
Atualmente, o seguinte deve ser verdadeiro para que os metadados de rastreamento de alterações sejam registrados:
- Tabelas:
Habilite o rastreamento de alterações na tabela (usando ALTER TABLE … CHANGE_TRACKING = TRUE), ou crie um fluxo na tabela (usando CREATE STREAM).
- Exibições:
Habilite o rastreamento de alterações na exibição e em suas tabelas subjacentes. Para obter instruções, consulte Enabling change tracking on views and underlying tables.
O rastreamento de alterações adiciona várias colunas ocultas à tabela e começa a armazenar metadados de rastreamento de alterações. Os valores nestas colunas de dados CDC ocultos fornecem a entrada para as colunas de metadados do fluxo. As colunas consomem uma pequena quantidade de armazenamento.
Não há metadados de rastreamento de alterações para o objeto durante o período anterior ao cumprimento de uma dessas condições.
Required access privileges¶
A consulta de um fluxo requer uma função com um mínimo das seguintes permissões de função:
Objeto |
Privilégio |
Notas |
|---|---|---|
Banco de dados |
USAGE |
|
Esquema |
USAGE |
|
Fluxo |
SELECT |
|
Tabela |
SELECT |
Fluxos apenas em tabelas. |
Exibição |
SELECT |
Somente Streams on Views |
Estágio externo |
USAGE |
Fluxos apenas em tabelas de diretório (em estágios externos) |
Estágio interno |
READ |
Fluxos apenas em tabelas de diretório (em estágios internos) |
Billing for streams¶
Como descrito em Período de retenção de dados e desatualização (neste tópico), quando um fluxo não é consumido regularmente, o Snowflake temporariamente estende o período de retenção de dados para a tabela de origem ou as tabelas subjacentes na exibição de origem. Se o período de retenção de dados para a tabela for inferior a 14 dias, então, nos bastidores, o período é estendido para o menor valor do offset do fluxo transacional offset ou 14 dias (se o período de retenção de dados para a tabela for inferior a 14 dias) independentemente da edição do Snowflake para sua conta.
A prorrogação do período de retenção de dados requer armazenamento adicional que será refletido em suas taxas mensais de armazenamento.
O principal custo associado a um fluxo é o tempo de processamento utilizado por um warehouse virtual para consultar o fluxo. Essas taxas aparecem em sua conta como créditos do Snowflake conhecidos.
Limitações¶
As seguintes limitações se aplicam aos fluxos:
Você não pode usar fluxos padrão ou apenas de anexação em tabelas Apache Iceberg™ que usam um catálogo externo. (Fluxos apenas de inserção são aceitos.)
Não é possível rastrear alterações em uma exibição com cláusulas GROUP BY.
Após adicionar ou modificar uma coluna para ser NOT NULL, as consultas em fluxos podem falhar se o fluxo gerar linhas com valores NULL não permitidos. Isso acontece porque o esquema do fluxo impõe a restrição NOT NULL atual, que não corresponde aos dados históricos retornados pelo fluxo.
Quando uma tarefa é acionada por fluxos on exibições, qualquer alteração nas tabelas referenciadas pela consulta de fluxos on exibições também acionará a tarefa, independentemente de quaisquer junções, agregações ou filtros na consulta.
Não há suporte para fluxos em tabelas externas particionadas ou tabelas Apache Iceberg™ particionadas gerenciadas por um catálogo externo.