Micropartições e clustering de dados¶
Data warehouses tradicionais dependem do particionamento estático de grandes tabelas para alcançar um desempenho aceitável e permitir uma melhor escalabilidade. Nestes sistemas, uma partição é uma unidade de gerenciamento que é manipulada independentemente usando sintaxe e DDL especializados; no entanto, o particionamento estático tem uma série de limitações bem conhecidas, tais como despesas de manutenção e distorção de dados, que podem resultar em partições de tamanho desproporcional.
Em contraste com um data warehouse, a plataforma de dados Snowflake implementa uma forma poderosa e única de particionamento, chamada microparticionamento, que oferece todas as vantagens do particionamento estático sem as limitações conhecidas, além de proporcionar benefícios adicionais significativos.
Atenção
Tabelas híbridas são baseados em uma arquitetura que não oferece suporte a alguns dos recursos disponíveis nas tabelas Snowflake padrão, como chaves de clustering.
O que são micropartições?¶
Todos os dados nas tabelas Snowflake são automaticamente divididos em micropartições, que são unidades de armazenamento contíguas. Cada micropartição contém entre 50 MB e 500 MB de dados não comprimidos (note que o tamanho real no Snowflake é menor porque os dados são sempre armazenados comprimidos). Grupos de linhas em tabelas são mapeados em micropartições individuais, organizadas de forma colunar. Este tamanho e estrutura permitem a remoção extremamente granular em tabelas muito grandes, que podem ser compostas de milhões, ou mesmo centenas de milhões, de micropartições.
O Snowflake armazena metadados sobre todas as linhas armazenadas em uma micropartição, inclusive:
O intervalo de valores para cada uma das colunas na micropartição.
O número de valores distintos.
Propriedades adicionais utilizadas tanto para otimização quanto para o processamento eficiente de consultas.
Nota
O microparticionamento é realizado automaticamente em todas as tabelas Snowflake. As tabelas são particionadas de forma transparente usando a ordenação dos dados à medida que são inseridos/carregados.
Benefícios do microparticionamento¶
Os benefícios da abordagem do Snowflake ao particionamento de dados de tabela incluem:
Em contraste com o particionamento estático tradicional, as micropartições do Snowflake são derivadas automaticamente; elas não precisam ser definidas explicitamente de forma antecipada ou mantidas pelos usuários.
Como o nome sugere, as micropartições são pequenas em tamanho (50 a 500 MB, antes da compressão), o que permite uma remoção refinada e DML extremamente eficiente para consultas mais rápidas.
As micropartições podem se sobrepor em seu intervalo de valores, o que, combinado com seu tamanho uniformemente pequeno, ajuda a evitar distorções.
As colunas são armazenadas de forma independente dentro de micropartições, o que muitas vezes é chamado de armazenamento colunar. Isto permite uma verificação eficiente das colunas individuais; apenas as colunas referenciadas por uma consulta são verificadas.
As colunas também são comprimidas individualmente dentro de micropartições. O Snowflake determina automaticamente o algoritmo de compressão mais eficiente para as colunas em cada micropartição.
Você pode ativar o clustering em tabelas específicas especificando uma chave de clustering para cada uma dessas tabelas. Para obter mais informações sobre como especificar uma chave de clustering, consulte:
Para obter mais informações adicionais sobre clustering, incluindo estratégias para a escolha das tabelas a serem clusterizadas, consulte:
Impacto das micropartições¶
DML¶
Todas as operações DML (por exemplo, DELETE, UPDATE, MERGE) aproveitam os metadados das micropartições subjacentes para facilitar e simplificar a manutenção das tabelas. Por exemplo, algumas operações, como a exclusão de todas as linhas de uma tabela, são operações somente de metadados.
Descarte de uma coluna em uma tabela¶
Quando uma coluna em uma tabela é descartada, as micropartições que contêm os dados da coluna descartada não são reescritas quando a instrução drop é executada. Os dados na coluna eliminada permanecem armazenados. Para obter mais informações, consulte as Notas de uso para ALTER TABLE.
Remoção em consultas¶
Os metadados das micropartições mantidas pelo Snowflake permitem a remoção precisa em colunas de micropartições no tempo de execução da consulta, incluindo colunas contendo dados semiestruturados. Em outras palavras, uma consulta que especifica um filtro baseado em um intervalo de valores que acessa 10% dos valores do intervalo deveria idealmente verificar apenas 10% das micropartições.
Por exemplo, suponha que uma tabela grande contenha um ano de dados históricos com colunas de data e hora. Considerando uma distribuição uniforme dos dados, uma consulta visando uma hora específica idealmente verificaria 1/8760 das micropartições da tabela e depois apenas verificaria a parte das micropartições que contém os dados para a coluna de hora; o Snowflake usa a verificação colunar das partições para que uma partição inteira não seja verificada se uma consulta filtrar apenas por uma coluna.
Em outras palavras, quanto mais próxima a proporção entre micropartições verificadas e dados colunares estiver da proporção dos dados reais selecionados, mais eficiente será a remoção realizada na tabela.
Para dados de série temporal, este nível de remoção potencialmente habilita tempos de resposta de subsegundos para consultas dentro de intervalos (ou seja, “fatias”) tão refinados quanto uma hora ou até menos.
Nem todas as expressões de predicado podem ser usadas para remoção. Por exemplo, o Snowflake não remove em micropartições com base em um predicado com uma subconsulta, mesmo que a subconsulta resulte em uma constante.
O que é clustering de dados?¶
Normalmente, os dados armazenados em tabelas são classificados/ordenados segundo dimensões naturais (por exemplo, data e/ou regiões geográficas). Este “clustering” é um fator-chave nas consultas porque dados de tabela que não estão classificados ou estão apenas parcialmente classificados podem impactar o desempenho da consulta, particularmente em tabelas muito grandes.
No Snowflake, conforme os dados são inseridos/carregados em uma tabela, metadados de clustering são coletados e registrados para cada micropartição criada durante o processo. O Snowflake então aproveita estas informações de clustering para evitar a verificação desnecessária de micropartições durante consultas, acelerando significativamente o desempenho das consultas que fazem referência a estas colunas.
O diagrama a seguir ilustra uma tabela de Snowflake, t1, com quatro colunas classificadas por data:
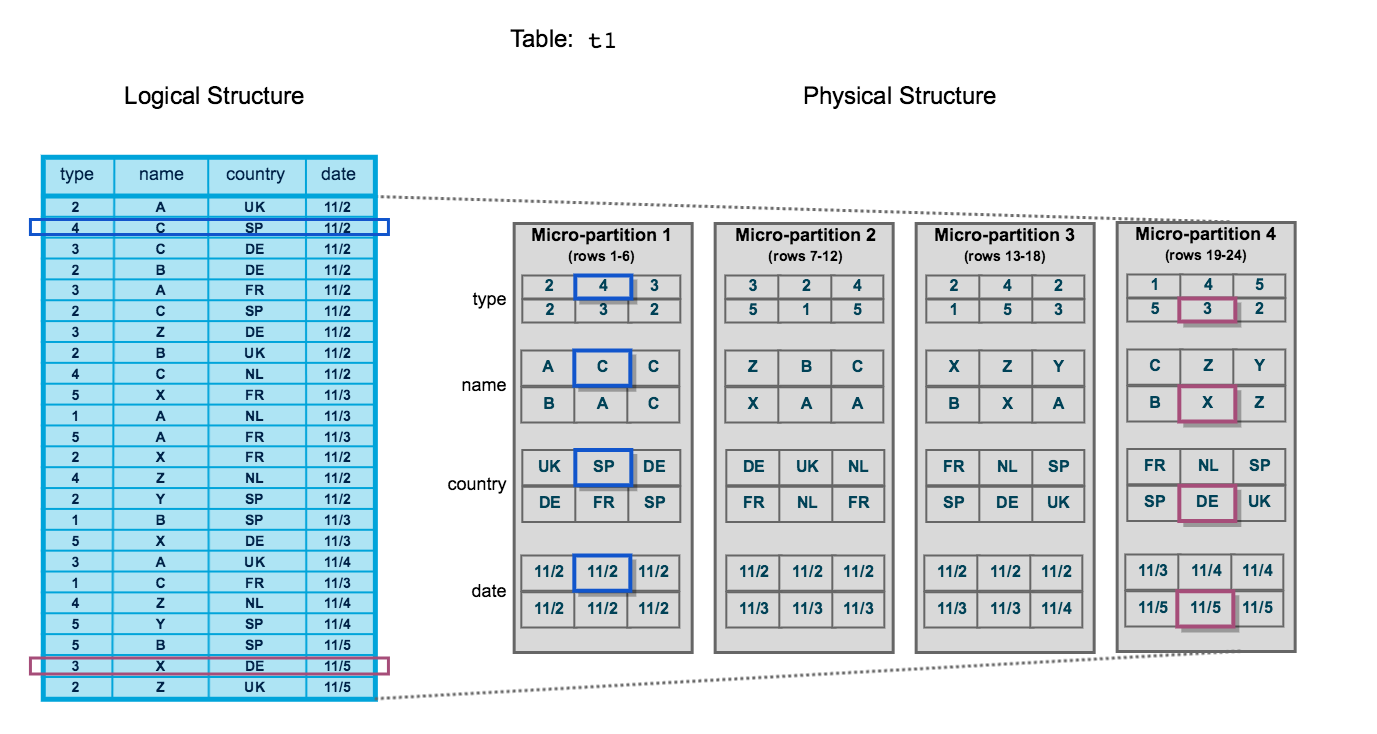
A tabela consiste em 24 linhas armazenadas em 4 micropartições, com as linhas divididas igualmente entre cada micropartição. Dentro de cada micropartição, os dados são classificados e armazenados por coluna, o que permite ao Snowflake realizar as seguintes ações para consultas na tabela:
Primeiro, fazer remoções em micropartições que não são necessárias para a consulta.
Em seguida, fazer remoções por coluna dentro das micropartições restantes.
Note que este diagrama pretende ser apenas uma representação conceitual em pequena escala do clustering de dados que o Snowflake utiliza em micropartições. Uma tabela do Snowflake típica pode consistir em milhares, até mesmo milhões, de micropartições.
Informações de clustering mantidas para micropartições¶
O Snowflake mantém metadados de clustering para as micropartições em uma tabela, inclusive:
O número total de micropartições que compõem a tabela.
O número de micropartições contendo valores que se sobrepõem (em um subconjunto especificado de colunas de tabela).
A profundidade das micropartições sobrepostas.
Profundidade de clustering¶
A profundidade de clustering para uma tabela preenchida mede a profundidade média (1 ou maior) das micropartições sobrepostas para colunas especificadas em uma tabela. Quanto menor a profundidade média, mais bem clusterizada é a tabela em relação às colunas especificadas.
A profundidade de clustering pode ser usada para uma variedade de propósitos, inclusive:
Monitorar a integridade de clustering de uma tabela grande, particularmente ao longo do tempo conforme o DML é realizado na tabela.
Determinar se uma tabela grande se beneficiaria da definição explícita de uma chave de clustering.
Uma tabela sem micropartições (ou seja, uma tabela não preenchida/vazia) tem uma profundidade de clustering de 0.
Nota
A profundidade de clustering para uma tabela não é uma medida absoluta ou precisa para o clustering adequado da tabela. Em última análise, o desempenho da consulta é o melhor indicador de quão bem clusterizada uma tabela está:
Se as consultas em uma tabela estiverem funcionando conforme necessário ou esperado, a tabela provavelmente está bem clusterizada.
Se o desempenho da consulta se degradar com o tempo, é provável que a tabela não esteja mais bem clusterizada e possa se beneficiar do clustering.
Ilustração da profundidade de clustering¶
O diagrama a seguir fornece um exemplo conceitual de uma tabela que consiste em cinco micropartições com valores que variam de A a Z, e ilustra como a sobreposição afeta a profundidade de clustering:
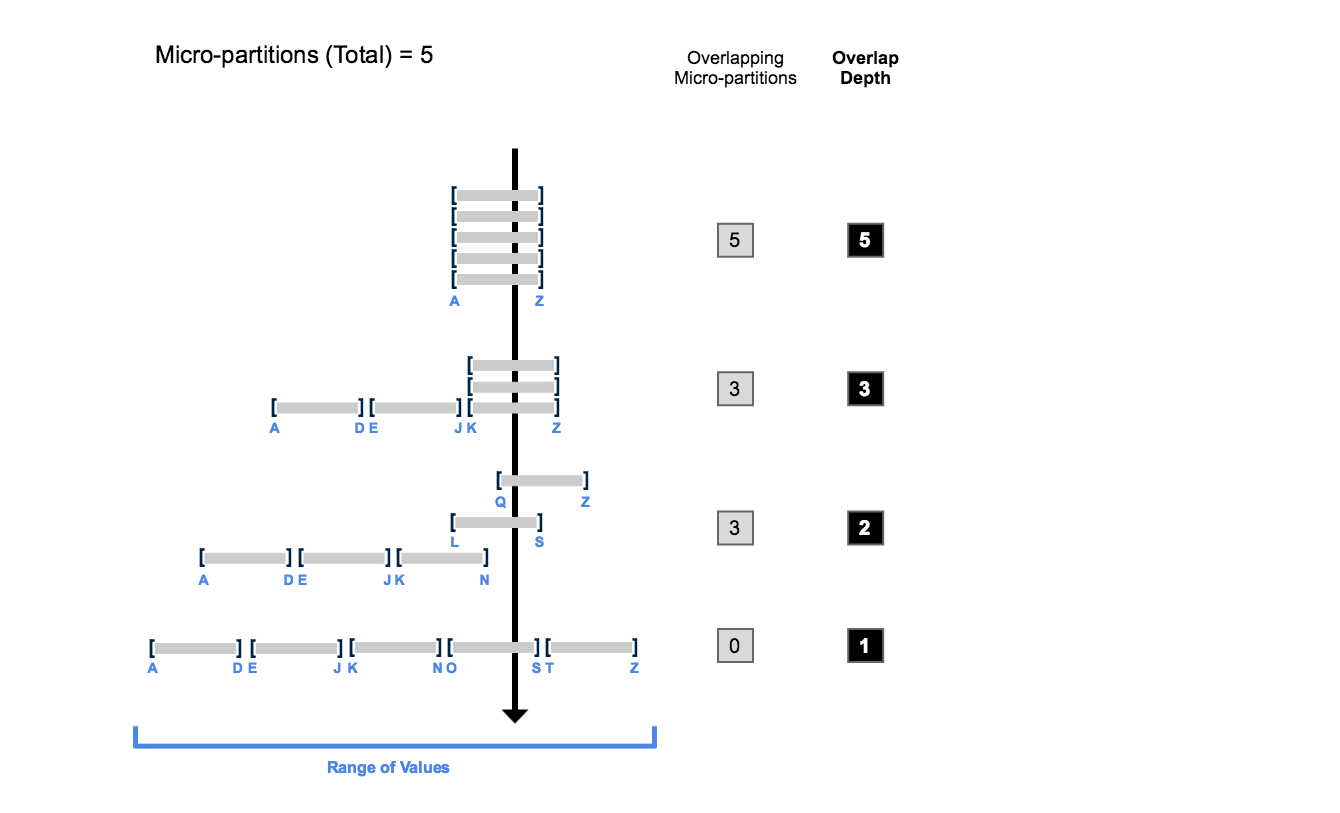
Este diagrama ilustra:
No início, o intervalo de valores em todas as micropartições se sobrepõe.
Conforme o número de micropartições sobrepostas diminui, a profundidade de sobreposição diminui.
Quando não há sobreposição no intervalo de valores em todas as micropartições, as micropartições são consideradas em um estado constante (ou seja, elas não podem ser melhoradas por clustering).
O diagrama não tem a intenção de representar uma tabela real. Em uma tabela real, com dados contidos em um grande número de micropartições, não é provável nem necessário atingir um estado constante em todas as micropartições para melhorar o desempenho da consulta.
Monitoramento de informações de clustering de tabelas¶
Para visualizar/monitorar os metadados de clustering para uma tabela, o Snowflake fornece as seguintes funções do sistema:
SYSTEM$CLUSTERING_INFORMATION (incluindo profundidade de clustering)
Para obter mais detalhes sobre como estas funções utilizam metadados de clustering, consulte Ilustração da profundidade de clustering (neste tópico).