Python 사용자 정의 집계 함수¶
사용자 정의 집계 함수(UDAFs)는 하나 이상의 행을 입력으로 받아 단일 행의 출력을 생성합니다. UDAF는 여러 행의 값을 연산하여 합계, 평균, 계산, 최소값 또는 최대값 찾기, 표준 편차, 추정과 같은 수학적 계산과 일부 비수학적 연산을 수행합니다.
Python UDAFs는 Snowflake 시스템 정의 SQL 집계 함수 와 유사한 자체 집계 함수를 작성할 수 있는 방법을 제공합니다.
Python에서 DataFrames용 사용자 정의 함수(UDAFs) 만들기 에 설명된 대로 Snowpark APIs를 사용하여 자체 UDAFs를 생성할 수도 있습니다.
제한 사항¶
집계 함수 핸들러를 위한 인터페이스¶
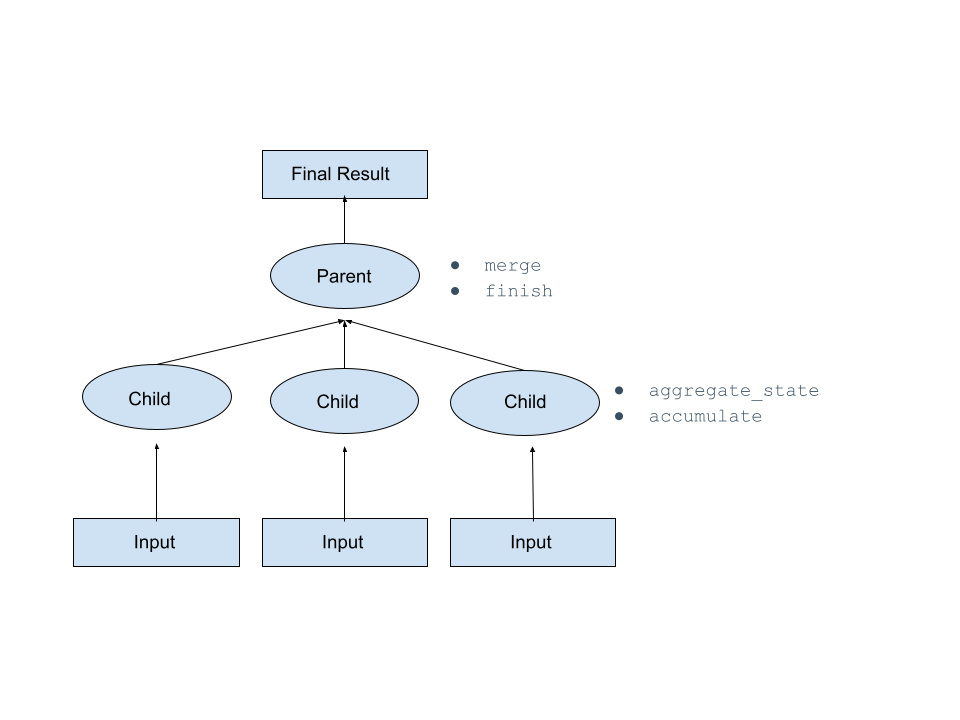
집계 함수는 하위 노드의 상태를 집계한 다음, 이 집계 상태를 직렬화하여 상위 노드로 전송하고, 상위 노드에서 병합하여 최종 결과를 계산합니다.
집계 함수를 정의하려면 Snowflake가 런타임에 호출하는 메서드를 포함하는 Python 클래스(함수의 핸들러)를 정의해야 합니다. 이러한 메서드는 아래 테이블에 설명되어 있습니다. 이 항목의 다른 곳에 있는 예제를 참조하십시오.
메서드 |
요구 사항 |
설명 |
|---|---|---|
|
필수 |
집계의 내부 상태를 초기화합니다. |
|
필수 |
집계의 현재 상태를 반환합니다.
|
|
필수 |
새로운 입력 행을 기준으로 집계 상태를 누적합니다. |
|
필수 |
두 개의 중간 집계 상태를 결합합니다. |
|
필수 |
집계된 상태를 기반으로 최종 결과를 생성합니다. |
예: 합계 계산¶
다음 예제의 코드는 숫자 값의 합계를 반환하는 python_sum 사용자 정의 집계 함수(UDAF)를 정의합니다.
UDAF를 만듭니다.
테스트 데이터 테이블을 만듭니다.
python_sumUDAF를 호출합니다.결과를 Snowflake 시스템 정의 SQL 함수인 SUM 의 출력과 비교하여 결과가 동일한지 확인합니다.
판매 테이블에서 품목 유형별 합계 값으로 그룹화합니다.
예: 평균 계산¶
다음 예제의 코드는 숫자 값의 평균을 반환하는 python_avg 사용자 정의 집계 함수를 정의합니다.
함수를 만듭니다.
테스트 데이터 테이블을 만듭니다.
python_avg사용자 정의 함수를 호출합니다.결과를 Snowflake 시스템 정의 SQL 함수인 AVG 의 출력과 비교하여 결과가 동일한지 확인합니다.
판매 테이블에서 품목 유형별로 평균값을 그룹화합니다.
예: 고유 값만 반환¶
다음 예제의 코드는 배열을 받아서 고유 값만 포함된 배열을 반환합니다.
예: 문자열 개수 반환¶
다음 예제의 코드는 오브젝트에서 문자열의 모든 인스턴스 수를 반환합니다.
예: 상위 k개의 가장 큰 값 반환¶
다음 예제의 코드는 k 에 대해 가장 큰 값의 목록을 반환합니다. 이 코드는 최소 힙에 음수 입력값을 누적한 다음 가장 큰 값의 상위 k 를 반환합니다.