Amazon S3에서 대량 로드¶
이미 Amazon Web Services(AWS) 계정이 있고 S3 버킷을 사용하여 데이터 파일을 저장 및 관리하는 경우 Snowflake로 대량 로드하기 위해 기존 버킷과 폴더 경로를 사용할 수 있습니다. 이 항목 세트는 S3 버킷에서 테이블로 대량 로드하는 COPY 명령에 대한 사용 방법을 설명합니다.
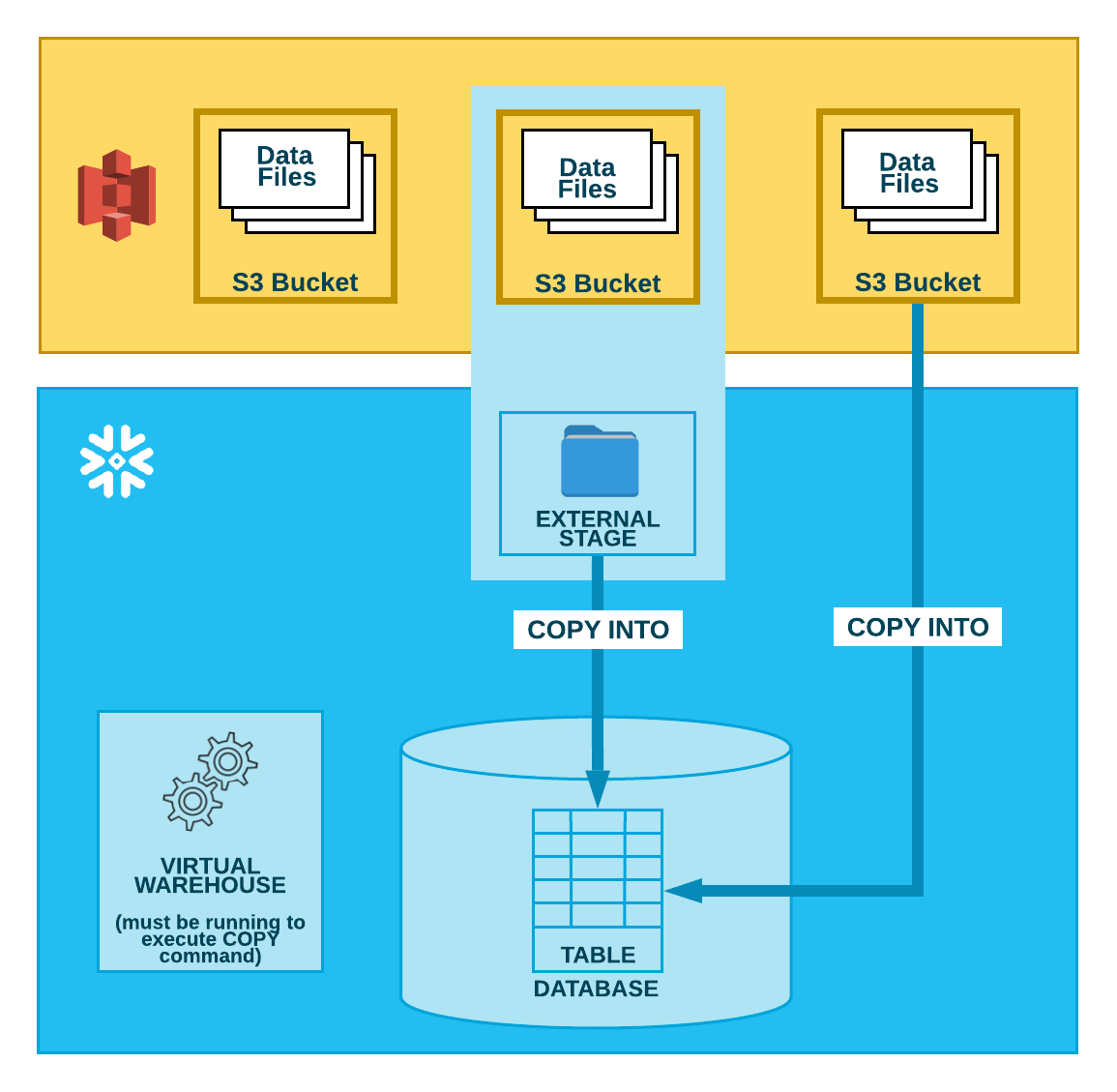
아래 다이어그램과 같이, S3 버킷에서 데이터를 로드하는 작업은 다음의 두 단계로 수행됩니다.
- 1단계:
Snowflake는 데이터 파일이 이미 S3 버킷에서 스테이징된 것으로 가정합니다. 아직 스테이징 되지 않은 경우 AWS에서 제공하는 업로드 인터페이스/유틸리티를 사용하여 파일을 스테이징합니다.
- 2단계:
COPY INTO <테이블> 명령을 사용하여 스테이징된 파일의 내용을 Snowflake 데이터베이스 테이블에 로드합니다. 버킷에서 직접 로드할 수 있지만, Snowflake는 버킷을 참조하는 외부 스테이지를 생성하고 외부 스테이지를 대신 사용하는 것을 권장합니다.
사용하는 방법에 관계없이, 이 명령을 수동으로 실행하거나 스크립트 내에서 실행할 경우 이 단계에서는 세션에 대해 실행 중인 현재 가상 웨어하우스가 필요합니다. 웨어하우스는 테이블에 행을 실제로 삽입하기 위한 컴퓨팅 리소스를 제공합니다.
참고
Snowflake는 각 Amazon Virtual Private Cloud의 Amazon S3 게이트웨이 엔드포인트를 사용합니다.
Snowflake 계정이 AWS에 호스팅되는 한, 네트워크 트래픽은 공용 인터넷을 통과하지 않습니다. 이는 S3 버킷이 위치한 리전에 관계없이 적용됩니다.
팁
이 항목 세트의 지침에서는 데이터 로드 준비하기 를 읽고 원하는 경우 명명된 파일 형식을 생성한 것으로 가정합니다.
시작하기 전에 데이터 로딩 고려 사항 에서 모범 사례, 팁 및 기타 지침을 확인할 수도 있습니다.
다음 항목:
구성 작업(필요한 경우 완료):
데이터 로딩 작업(로드하는 각 파일 세트에 대해 완료):