Bulk loading from Amazon S3¶
If you already have an Amazon Web Services (AWS) account and use S3 buckets for storing and managing your data files, you can make use of your existing buckets and folder paths for bulk loading into Snowflake. This set of topics describes how to use the COPY command to bulk load from an S3 bucket into tables.
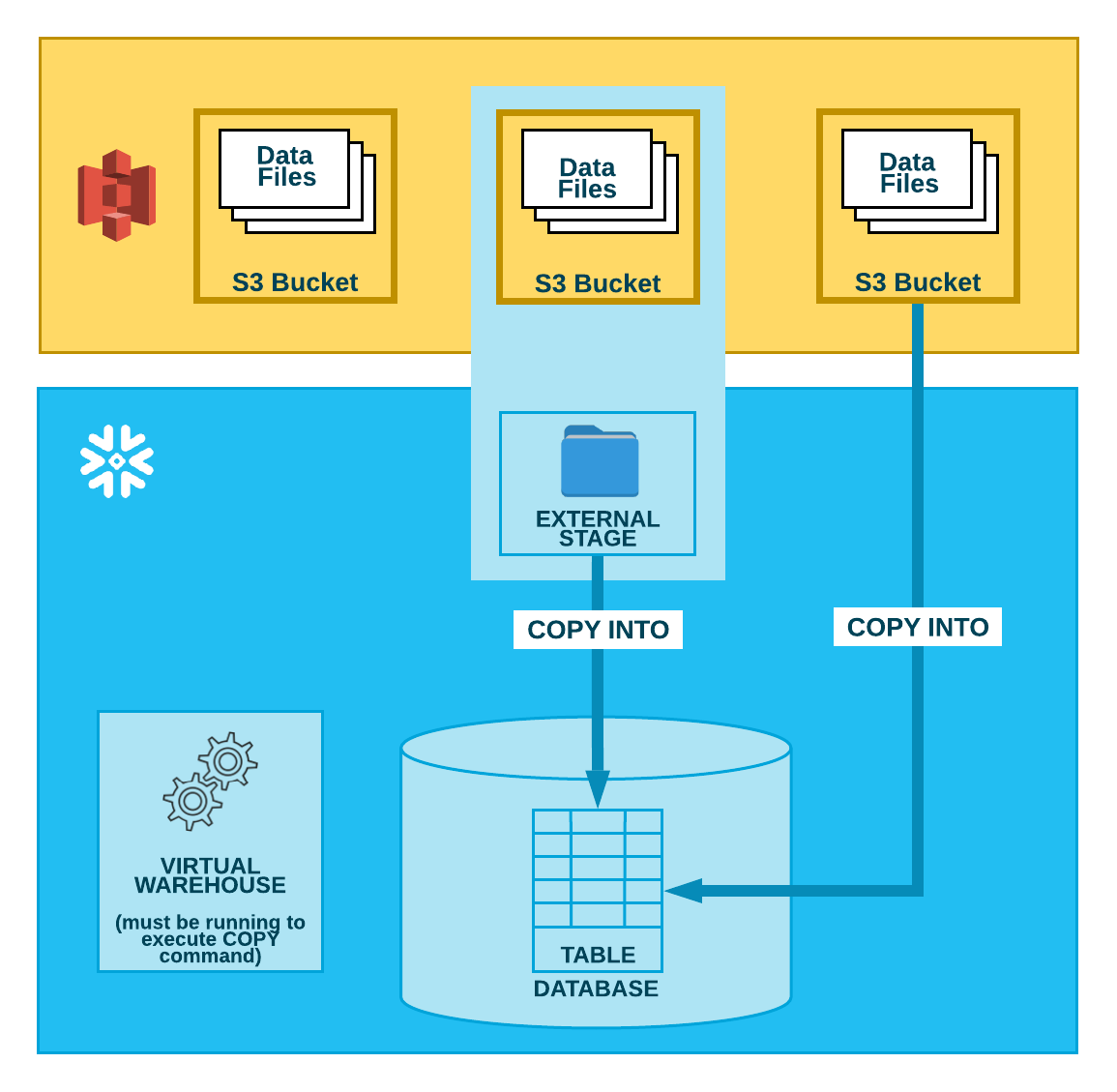
As illustrated in the diagram below, loading data from an S3 bucket is performed in two steps:
- Step 1:
Snowflake assumes the data files have already been staged in an S3 bucket. If they haven’t been staged yet, use the upload interfaces/utilities provided by AWS to stage the files.
- Step 2:
Use the COPY INTO <table> command to load the contents of the staged file(s) into a Snowflake database table. You can load directly from the bucket, but Snowflake recommends creating an external stage that references the bucket and using the external stage instead.
Regardless of the method you use, this step requires a running, current virtual warehouse for the session if you execute the command manually or within a script. The warehouse provides the compute resources to perform the actual insertion of rows into the table.
Note
Snowflake uses Amazon S3 gateway endpoints in each of its Amazon Virtual Private Clouds.
As long as your Snowflake account is hosted on AWS, your network traffic does not traverse the public internet. This is true regardless of the region that your S3 bucket is in.
Tip
The instructions in this set of topics assume you have read Preparing to load data and have created a named file format, if desired.
Before you begin, you may also want to read Data loading considerations for best practices, tips, and other guidance.
Next Topics:
-
Configuration tasks (complete as needed):
-
Data loading tasks (complete for each set of files you load):