하이브리드 테이블 만들기¶
이 항목에서는 Snowflake에서 하이브리드 테이블 을 만드는 방법에 대한 개요를 제공합니다.
참고
하이브리드 테이블을 생성하려면 세션의 현재 웨어하우스로 지정된 실행 중인 웨어하우스가 있어야 합니다. 하이브리드 테이블을 생성할 때 실행 중인 웨어하우스를 지정하지 않으면 오류가 발생할 수 있습니다. 자세한 내용은 웨어하우스 관련 작업하기 를 참조하십시오.
CREATE HYBRID TABLE 옵션¶
다음 방법 중 하나를 사용하여 하이브리드 테이블을 생성할 수 있습니다.
CREATE HYBRID TABLE. 다음 예제에서는 PRIMARY KEY 제약 조건이 있는 하이브리드 테이블을 생성하고, 일부 행을 삽입하고, 행을 삭제하고, 테이블을 쿼리합니다.
CREATE HYBRID TABLE … AS SELECT(CTAS) 또는 CREATE HYBRID TABLE … LIKE. 예:
데이터 로딩하기¶
참고
하이브리드 테이블의 기본 저장소는 행 저장소이므로 하이브리드 테이블은 일반적으로 표준 테이블보다 저장 공간이 더 큽니다. 이러한 차이점의 주된 이유는 표준 테이블의 열 형식 데이터는 압축률이 더 높은 경우가 많기 때문입니다. 저장소 비용에 대한 자세한 내용은 하이브리드 테이블의 비용 평가 섹션을 참조하십시오.
대량 로딩 최적화¶
데이터 스테이지 또는 다른 테이블(CTAS, COPY INTO <테이블> 또는 INSERT INTO … SELECT 사용)에서 복사본을 복사하여 하이브리드 테이블에 데이터를 일괄 로드할 수 있습니다.
대량 로딩의 최적화는 테이블이 레코드가 로딩된 적이 없이 새로 생성되었는지, 아니면 CTAS 쿼리를 사용하여 생성되었는지에 따라 달라집니다.
하이브리드 테이블이 비어 있는 경우 3가지 로딩 방법(CTAS, COPY 및 INSERT INTO … SELECT)은 모두 최적화된 대량 로딩을 사용하여 로딩 프로세스의 속도를 높입니다. 테이블이 로딩되면 일반적인 INSERT 성능이 적용됩니다. COPY 및 INSERT INTO … SELECT 작업을 사용하여 증분 배치 로딩을 계속 실행할 수 있지만 일반적으로 효율성이 떨어집니다. 분당 약 100만 개의 레코드를 대량으로 로드하는 속도가 일반적이지만 테이블의 구조에 따라 크게 달라질 수 있습니다(예: 레코드가 클수록 로딩 속도가 느립니다). 최적화된 대량 로딩은 향후 릴리스에서 증분 배치 로딩을 지원하도록 확장될 예정입니다.
Snowsight 쿼리 프로필에서 Statistics 정보를 확인하여 대량 로딩 빠른 경로가 사용되었는지 확인할 수 있습니다. Number of rows inserted 빠른 경로가 사용되는 경우 Number of rows bulk loaded 로 참조됩니다. 예를 들어, 이 CTAS 작업은 200,000개의 행을 새 테이블에 대량으로 로딩했습니다.
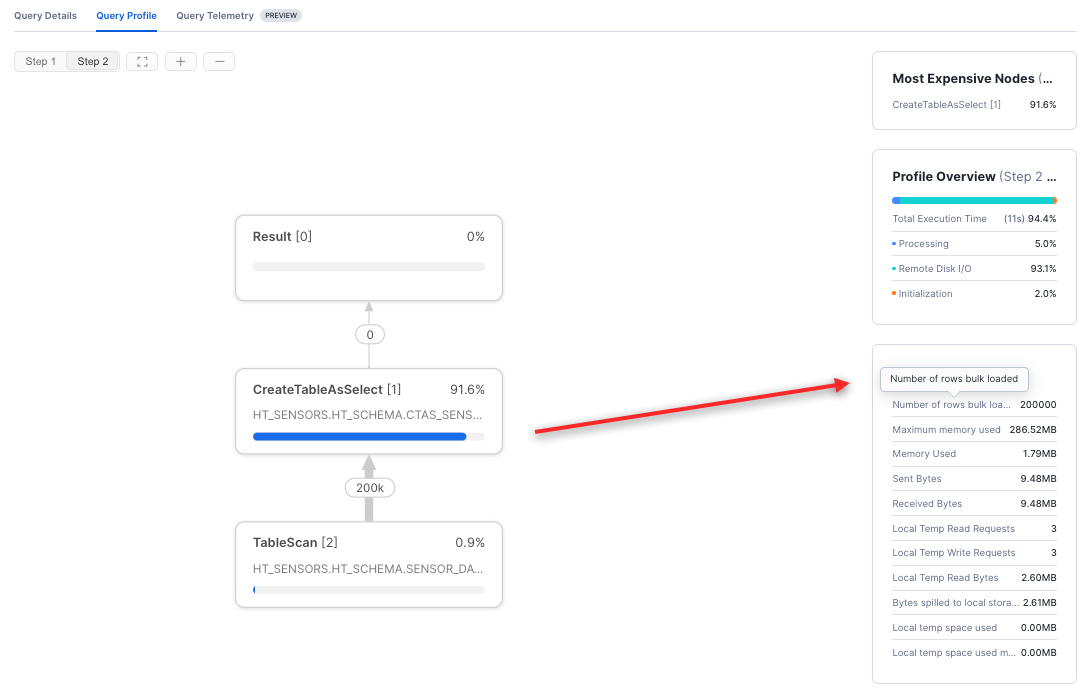
이후 동일한 테이블에 증분 배치 로딩을 하면 최적화된 대량 로딩이 사용되지 않습니다.
쿼리 프로필에 대한 자세한 내용은 하이브리드 테이블에 대한 쿼리 프로필 분석 및 쿼리 기록으로 쿼리 활동 모니터링하기 섹션을 참조하십시오.
주의
CTAS 명령은 FOREIGN KEY 제약 조건을 지원하지 않습니다. 하이브리드 테이블에 FOREIGN KEY 제약 조건이 필요한 경우 COPY 또는 INSERT INTO … SELECT 를 사용하여 테이블을 로드합니다.
참고
Snowflake 테이블에 데이터를 로드하는 다른 방법(예:Snowpipe)은 현재 지원되지 않습니다.
로딩 중 인덱스 작성 오류¶
인덱스 크기는 너비가 제한되어 있습니다. 하이브리드 테이블의 열, 특히 많은 수의 열에 인덱스가 구축된 경우 테이블을 로드하는 모든 명령(예: CTAS, COPY 또는 INSERT INTO … SELECT)은 다음과 같은 오류를 반환할 수 있습니다. 이 경우 테이블에는 IDX_HT100_COLS 라는 인덱스가 포함됩니다.
이 오류는 행 기반 저장소가 레코드당 저장할 수 있는 데이터(및 메타데이터)의 크기에 제한을 두기 때문에 발생합니다. 레코드 크기를 줄이려면 넓은 VARCHAR 열과 같이 더 큰 열을 인덱스 열로 지정하지 않고 테이블을 만듭니다. 더 적은 수의 열에 인덱스를 만들 수도 있습니다.
하이브리드 테이블 또는 하이브리드 테이블에 인덱스를 생성할 때 보조 인덱스의 INCLUDE 열을 사용할 수도 있습니다. 자세한 내용은 INCLUDE 열 섹션을 참조하십시오.