하이브리드 테이블이 포함된 데이터베이스를 복제본으로 생성할 수 있는 목적은 크게 두 가지입니다.
특정 시점 복원 작업을 실행하기 위해. 복제본은 기본적으로 암시적 연속 백업을 생성하는 Time Travel 과 함께 작동합니다. 데이터 보존 기간을 설정 한 후 Time Travel 기록의 어느 시점에서든 데이터베이스를 복제하여 데이터베이스를 정상 상태로 복원할 수 있습니다(충돌이 발생한 경우). 복원이 필요한 경우를 제외하고는 복제본을 생성할 필요가 없습니다.
프로덕션 환경에서 개발 또는 테스트 환경으로 데이터베이스를 복제하는 등 소스 환경에서 다른 환경으로 하이드레이션할 수 있습니다.
하이브리드 테이블이 포함된 복제본 데이터베이스를 생성할려고 시도하기 전에 다음 섹션의 특정 요구 사항과 제한 사항을 읽고 이해해야 합니다.
스키마 수준이나 테이블 수준에서는 하이브리드 테이블을 복제본으로 생성할 수 없습니다. 하이브리드 테이블 또는 표준 테이블을 복제하여 새 하이브리드 테이블을 생성할려고 하면 명령이 오류와 함께 실패합니다. 예:
CREATEHYBRIDTABLEclone_ht1CLONEht1;
391411 (0A000): This feature is not supported for hybrid tables: 'CLONE'.
다른 스키마를 복제본으로 생성해 스키마를 생성할려고 하는데 소스 스키마에 1개 이상의 하이브리드 테이블이 있는 경우 명령이 실패합니다. 그러나 IGNORE HYBRID TABLES 매개 변수를 사용하여 스키마에서 하이브리드 테이블을 명시적으로 건너뛰는 방식으로 스키마를 복제할 수 있습니다. 이 매개 변수는 데이터베이스 복제본 생성에도 사용할 수 있습니다. 예:
AT BEFORE, OFFSET 또는 STATEMENT (쿼리 UUID) 매개 변수를 사용하여 하이브리드 테이블을 포함하는 복제본을 생성할 수 없습니다. 매개 변수를 전혀 지정하지 않거나 TIMESTAMP 값을 명시적으로 형 변환하여 AT TIMESTAMP 를 지정해야 합니다.
표준 테이블의 동작과 마찬가지로 복제본에 원본 테이블의 기록은 복제본 자체에 유지되지 않습니다. 복제본 테이블은 소스 테이블의 모든 이전 기록을 잃게 되므로, 복제된 후에는 Time Travel을 사용하여 과거 상태를 볼 수 없습니다. Time Travel을 사용하면 복제본 작업 후 발생하는 테이블의 새로운 기록을 볼 수 있습니다.
하이브리드 테이블 복제는 데이터 크기 작업인 반면, 표준 테이블 복제는 메타데이터 전용 작업입니다. 이 차이는 컴퓨팅 비용, 저장소 비용, 성능에 영향을 미칩니다.
데이터베이스에 하이브리드 테이블이 포함된 경우 데이터베이스 복제본 작업 자체에 컴퓨팅 비용이 발생합니다.
하이브리드 테이블을 복제하면 데이터가 행 저장소에 물리적으로 복사본으로 저장되므로, 큰 테이블의 경우 복제 작업에 오랜 시간이 걸릴 수 있으며 비용은 데이터의 크기에 따라 선형적으로 증가합니다.
복제 성능은 CREATE TABLE AS SELECT 를 통한 최적화된 직접 대량 로딩과 유사합니다. 데이터 로딩하기 섹션을 참조하십시오.
CREATE DATABASE … CLONE 명령을 사용하여 하이브리드 테이블이 포함된 데이터베이스를 복제본으로 생성할 수 있습니다. 이 명령은 기존 소스 데이터베이스의 이름과 새 대상 데이터베이스의 이름을 지정합니다. 복제본 데이터베이스는 지정한 AT TIMESTAMP 값 또는 타임스탬프를 지정하지 않은 경우 현재 시점으로 생성됩니다. 새 데이터베이스는 표준 또는 하이브리드 테이블 유형에 관계없이 해당 시점에 소스에 존재했던 스키마 및 테이블의 복사본입니다(표준 또는 하이브리드 테이블 유형에 관계 없음).
다음 예제는 1개 이상의 하이브리드 테이블이 포함된 데이터베이스를 복제할 때 예상되는 동작을 보여줍니다. 첫 번째 명령은 testdb 데이터베이스의 testdata 스키마에 존재하는 2개의 테이블을 표시합니다. ht1 테이블은 하이브리드 테이블이고 st1 테이블은 표준 테이블입니다.
적절한 타임스탬프가 있는 testdb (이 경우 restore_testdb)의 복제본을 생성해 세 개의 테이블이 포함된 “정상”상태로 데이터베이스를 복원할 수 있습니다. 여기에 지정된 타임스탬프는 테이블이 생성된 시점(그리고 삭제되기 전)과 매우 가까운 시점입니다. 실제로는 테이블에 데이터가 로딩되거나 다른 업데이트가 적용된 시점에 따라 타임스탬프를 신중하게 선택해야 합니다. 이 예제의 주요 목표는 테이블을 삭제하기 직전의 상태를 캡처하는 것입니다.
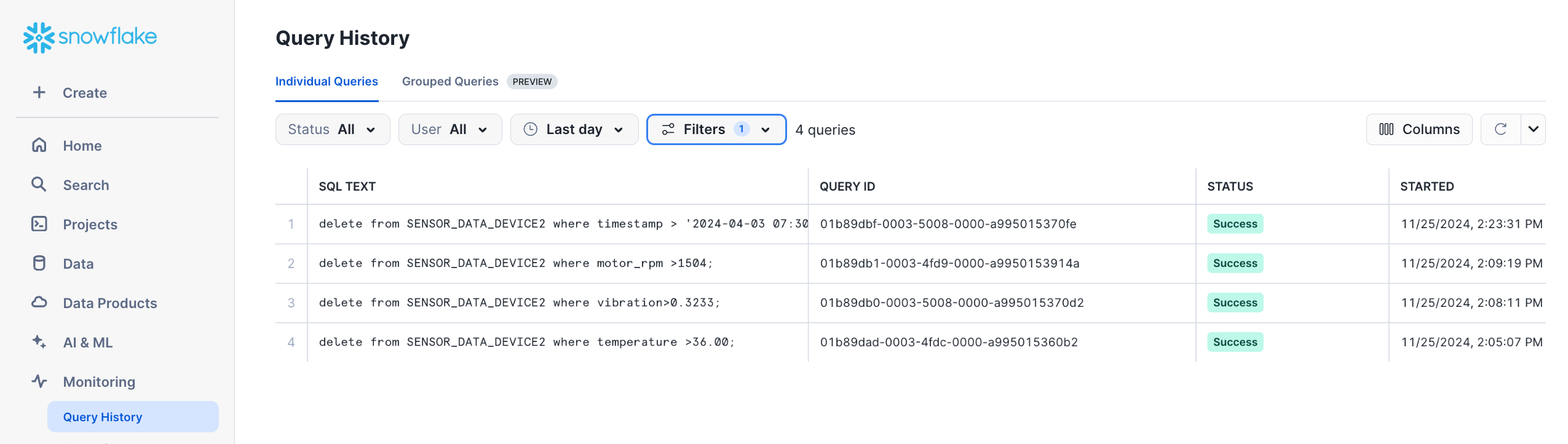
이름이 ht_sensors``인데이터베이스에이름이``sensor_data_device2``인테이블이포함된``ht_schema 스키마가 있습니다. 11월 25일에 이 테이블에서 일련의 DELETE 작업이 실행되었다고 가정해 보겠습니다. Snowsight 의 탐색 메뉴에서 Monitoring»Query History`를 선택하여 이러한 DELETE 작업에 대한 정보를 확인할 수 있습니다. (이 예제에서는 이 작업을 격리하기 위해 :ui:`SQL Text 필터가 ``DELETE``로 설정되어 있습니다.)
목록의 두 번째 DELETE 작업이 실수로 실행된 경우(motor_rpm 값이 1504보다 큰 행이 삭제된 경우) 데이터베이스를 복제본으로 만들어 해당 작업이 커밋되기 직전의 상태로 복원할 수 있습니다. (이 예제에서는 단순화를 위해 이 기간 동안 해당 테이블이나 데이터베이스의 다른 테이블에 업데이트 또는 삽입과 같은 다른 변경 사항이 적용되지 않았다고 가정하겠습니다.)
데이터베이스를 복제하기 전에 간단한 쿼리를 통해 Time Travel 결과를 확인할 수 있습니다. 이렇게 하면 비용이 많이 드는 복원 작업을 실행하기 전에 복제본이 예상한 데이터를 캡처하는지 확인할 수 있습니다.
예를 들어, 1분 간격의 다음 2개의 Time Travel 쿼리 결과를 비교해 보겠습니다.
SELECTCOUNT(*)FROMsensor_data_service2AT(TIMESTAMP=>'Mon, 25 Nov 2024 14:09:00'::TIMESTAMP_LTZ)WHEREMOTOR_RPM>1504;
결과는 예상했던 차이를 확인시켜 줍니다. 이제 첫 번째 쿼리와 동일한 타임스탬프를 사용하여 데이터베이스를 복제본으로 생성할 수 있습니다.
USEDATABASEht_sensors;USESCHEMAht_schema;CREATEORREPLACEDATABASErestore_ht_sensorsCLONEht_sensorsAT(TIMESTAMP=>'Mon, 25 Nov 2024 14:09:00'::TIMESTAMP_LTZ);
+---------------------------------------------------+| status ||---------------------------------------------------|| Database RESTORE_HT_SENSORS successfully created. |+---------------------------------------------------+
이제 복제본 데이터베이스의 상태를 확인합니다. 테이블(sensor_data_device2)의 복제본 버전에는 Time Travel 데이터가 없다는 점에 유의하십시오.
SELECTCOUNT(*)FROMSENSOR_DATA_DEVICE2AT(TIMESTAMP=>'Mon, 25 Nov 2024 14:09:00'::TIMESTAMP_LTZ)WHEREMOTOR_RPM>1504;
000707 (02000): Time travel data is not available for table SENSOR_DATA_DEVICE2. The requested time is eitherbeyond the allowed time travel period or before the object creation time.
마지막으로, 복제본 테이블이 timestamp 열이 2024-04-0307:30:00.000 보다 큰 행을 유지했기 때문에 쿼리 기록에서 가장 최근 DELETE 작업을 다시 적용해야 할 수 있습니다.