쿼리 기록으로 쿼리 활동 모니터링하기¶
계정의 쿼리 활동을 모니터링하려면 다음을 사용할 수 있습니다.
Snowsight 의 Query History 및 Grouped Query History 페이지.
SNOWFLAKE 데이터베이스의 ACCOUNT_USAGE 스키마에서 QUERY_HISTORY 뷰 및 AGGREGATE_QUERY_HISTORY 뷰 .
INFORMATION_SCHEMA 에 있는 테이블 함수의 QUERY_HISTORY 패밀리.
Snowsight 의 Query History 페이지에서 다음을 수행할 수 있습니다.
계정에서 사용자가 실행하는 개별 또는 그룹 쿼리를 모니터링하십시오.
성능 데이터를 포함하여 쿼리에 대한 세부 정보를 볼 수 있습니다. 경우에 따라서는 쿼리 세부 정보가 제공되지 않습니다.
쿼리 프로필에서 실행된 쿼리의 각 단계를 탐색할 수 있습니다.
쿼리 기록 페이지에서는 지난 14일 동안 Snowflake 계정에서 실행된 쿼리를 탐색할 수 있습니다.
워크시트 내에서 해당 워크시트에서 실행된 쿼리에 대한 쿼리 기록을 볼 수 있습니다. 쿼리 기록 보기 섹션을 참조하십시오.
Snowsight에서 쿼리 기록 검토하기¶
Snowsight 의 Query History 페이지에 액세스하려면 다음을 수행하십시오.
Snowsight 에 로그인합니다.
탐색 메뉴에서 Monitoring » Query History 를 선택합니다.
Individual Queries 또는 Grouped Queries 로 이동합니다. 그룹화된 쿼리에 대한 자세한 내용은 Snowsight에서 그룹화된 쿼리 기록 뷰 사용 섹션을 참조하십시오.
Individual Queries, 의 경우 가장 관련성 높고 정확한 결과를 보려면 뷰를 필터링하십시오.
목록 상단에 Load More 버튼이 표시되면 로딩할 수 있는 가용성 있는 결과가 더 있다는 뜻입니다. Load More 를 선택하거나 목록 하단으로 스크롤하여 다음 결과 세트를 가져올 수 있습니다.
쿼리 기록을 보기 위해 필요한 권한¶
실행한 쿼리의 기록을 언제든지 볼 수 있습니다.
다른 쿼리 기록을 보려면 활성 역할이 Query History 에서 볼 수 있는 다른 항목에 영향을 미칩니다.
활성 역할이 ACCOUNTADMIN 역할인 경우 계정에 대한 모든 쿼리 기록을 볼 수 있습니다.
활성 역할에 웨어하우스에 대해 부여된 MONITOR 또는 OPERATE 권한이 있는 경우 해당 웨어하우스를 사용하는 다른 사용자가 실행한 쿼리를 볼 수 있습니다.
활성 역할이 SNOWFLAKE 데이터베이스에 대한 GOVERNANCE_VIEWER 데이터베이스 역할을 부여받은 경우 SQL를 사용하여 ACCOUNT_USAGE 뷰를 직접 쿼리할 수 있으며, 쿼리 기록의 :ui:`Grouped Queries`를 볼 수도 있습니다. 그러나 이 역할만으로는 Snowsight 의 다른 사용자가 :ui:`Individual Queries`를 볼 수 있는 권한을 부여하지 않습니다. 모든 사용자 쿼리(그룹화 및 개별 쿼리 모두)를 보려면 역할이 ACCOUNTADMIN이거나 SNOWFLAKE 데이터베이스에 대한 IMPORTED PRIVILEGES 권한을 부여받아야 합니다. 또는 다음 두 권한으로 IMPORTED PRIVILEGES를 대체할 수 있습니다.
활성 역할에 SNOWFLAKE 데이터베이스에 대한 READER_USAGE_VIEWER 데이터베이스 역할이 부여된 경우 계정과 연결된 독자 계정의 모든 사용자에 대한 쿼리 기록을 볼 수 있습니다. SNOWFLAKE 데이터베이스 역할 섹션을 참조하십시오.
쿼리 기록 사용 시 고려 사항¶
계정의 Query History 를 검토할 때 다음 사항을 고려하십시오.
세션 의 데이터 보존 정책으로 인해 7일 이상 전에 실행된 쿼리에 대한 세부 정보에는 User 정보가 포함되지 않습니다. 사용자 필터를 사용하여 개별 사용자가 실행한 쿼리를 검색할 수 있습니다. 쿼리 기록 필터링하기 섹션을 참조하십시오.
구문 또는 구문 분석 오류로 인해 실패한 쿼리의 경우 실행된 SQL 문 대신
<redacted>가 표시됩니다. 적절한 권한이 있는 역할을 부여받은 경우 ENABLE_UNREDACTED_QUERY_SYNTAX_ERROR 매개 변수를 설정하여 전체 쿼리 텍스트를 볼 수 있습니다.필터와 Started 및 End Time 열은 현재 타임존을 사용합니다. 이 설정은 변경할 수 없습니다. 세션에 대한 TIMEZONE 매개 변수를 설정해도 사용되는 타임존은 변경되지 않습니다.
쿼리 기록 필터링하기¶
쿼리 기록 목록은 다음과 같이 필터링할 수 있습니다.
예를 들어 장기 실행 쿼리, 실패한 쿼리, 대기 중인 쿼리를 식별하기 위한 쿼리 상태입니다.
다음을 포함하여 쿼리를 수행한 사용자:
쿼리 기록을 볼 수 있는 액세스 권한이 있는 모든 사용자를 확인할 수 있는 All.
자신이 로그인한 사용자(기본값)
다른 사용자의 쿼리 기록을 볼 수 있는 역할을 가진 우 계정의 개별 Snowflake 사용자.
쿼리가 실행된 기간(최대 14일).
다음을 포함한 기타 필터:
SQL Text. GROUP BY와 같은 특정 문을 사용하는 쿼리를 볼 수 있습니다.
Query ID. 특정 쿼리에 대한 세부 정보를 볼 수 있습니다.
Warehouse. 특정 웨어하우스를 사용하여 실행된 쿼리를 볼 수 있습니다.
Statement Type. DELETE, UPDATE, INSERT 또는 SELECT와 같은 특정 유형의 문을 사용한 쿼리를 볼 수 있습니다.
Duration. 예를 들어 특히 장기 실행 쿼리를 식별할 수 있습니다.
Session ID. 특정 Snowflake 세션 중에 실행되는 쿼리를 볼 수 있습니다.
Query Tag. QUERY_TAG 세션 매개 변수를 통해 설정된 특정 쿼리 태그가 있는 쿼리를 볼 수 있습니다.
Parameterized Query Hash 를 클릭하여 필터에 지정된 매개 변수화된 쿼리 해시 ID 에 따라 그룹화된 쿼리를 표시합니다. 자세한 내용은 매개 변수가 있는 쿼리의 해시(query_parameterized_hash) 사용하기 섹션을 참조하십시오.
Client generated statements. 웹 인터페이스를 포함하여 클라이언트, 드라이버 또는 라이브러리에서 실행되는 내부 쿼리를 볼 수 있습니다. 예를 들어, 사용자가 Snowsight 의 Warehouses 페이지로 이동할 때마다 Snowflake는 백그라운드에서 SHOW WAREHOUSES 문을 실행합니다. 이 필터가 활성화되면 해당 문이 표시됩니다. 클라이언트가 생성한 문에 대해서는 계정에 비용이 청구되지 않습니다.
Queries executed by user tasks. 실행된 SQL 문이나 사용자 작업으로 호출된 저장 프로시저를 볼 수 있습니다.
Show replication refresh history, 원격 리전과 계정에 대한 복제 새로 고침 작업을 수행하는 데 사용되는 쿼리를 볼 수 있습니다.
거의 실시간 결과를 보려면 Auto Refresh 를 활성화하십시오. Auto Refresh 가 활성화되면 테이블이 10초마다 새로 고쳐집니다.
기본적으로 Queries 테이블에서 다음 열을 볼 수 있습니다.
SQL Text. 실행된 문의 텍스트입니다(항상 표시됨).
Query ID. 쿼리의 ID입니다(항상 표시됨).
Status, 실행된 문의 상태입니다(항상 표시됨).
User. 문을 실행한 사용자 이름을 확인합니다.
Warehouse. 문을 실행하는 데 사용된 웨어하우스를 확인합니다.
Duration. 문을 실행하는 데 걸린 시간을 확인합니다.
Started. 문 실행이 시작된 시간을 확인합니다.
결과가 더 많으면 테이블을 정렬할 수 없습니다. 테이블을 정렬한 후 목록 맨 위에 있는 Load More 를 선택하면 새 결과가 데이터 끝에 추가되고 정렬 순서가 더 이상 적용되지 않습니다.
보다 구체적인 정보를 보려면 Columns 를 선택하여 테이블에서 다음과 같은 열을 추가하거나 제거할 수 있습니다.
All. 모든 열을 표시합니다.
User 를 클릭하여 문을 실행한 사용자를 표시합니다.
Warehouse 를 클릭하여 문을 실행하는 데 사용된 웨어하우스의 이름을 표시합니다.
Warehouse Size. 문을 실행하는 데 사용된 웨어하우스의 크기를 표시합니다.
Duration 을 클릭하여 문이 실행되는 데 걸린 시간을 표시합니다.
Started 를 클릭하여 문의 시작 시간을 표시합니다.
End Time. 문의 종료 시간을 표시합니다.
Session ID. 문을 실행한 세션의 ID를 표시합니다.
Client Driver. 문을 실행하는 데 사용된 클라이언트, 드라이버 또는 라이브러리의 이름과 버전을 표시합니다. 문은 Snowsight 디스플레이
Go 1.1.5에서 실행됩니다.Bytes Scanned. 쿼리 처리 중에 스캔된 바이트 수를 표시합니다.
Rows. 문에서 반환된 행 수를 표시합니다.
Query Tag. 쿼리에 설정된 쿼리 태그를 표시합니다.
Parameterized Query Hash 를 입력하여 필터에 지정된 매개 변수화된 쿼리 해시 ID 에 따라 그룹화된 쿼리를 표시합니다. 자세한 내용은 매개 변수가 있는 쿼리의 해시(query_parameterized_hash) 사용하기 섹션을 참조하십시오.
Incident. 문제 해결 또는 디버깅 목적으로 사용되는 인시던트의 실행 상태의 문에 대한 세부 정보를 표시합니다.
쿼리에 대한 추가 세부 정보를 보려면 테이블에서 쿼리를 선택하여 Query Details 를 여십시오.
Snowsight에서 그룹화된 쿼리 기록 뷰 사용¶
Snowsight 에서 Grouped Query History 뷰를 사용하여 중요하고 자주 실행되는 쿼리의 사용량과 성능을 모니터링할 수 있습니다. 이 그래픽 뷰는 AGGREGATE_QUERY_HISTORY 뷰 에 기록된 정보를 기반으로 합니다. 실행된 쿼리는 매개 변수화된 쿼리 해시 ID 로 그룹화됩니다. 시간 경과에 따른 주요 통계를 모니터링하고 각 그룹에 속한 개별 쿼리로 드릴다운할 수 있습니다.
이 뷰에는 Snowflake에 대한 모든 쿼리가 포함되지만, 특히 높은 처리량으로 소수의 고유 문을 반복적으로 실행하는 Unistore 워크로드 를 모니터링하고 분석하는 데 유용합니다. 하이브리드 테이블 을 포함하는 워크로드의 경우 개별 쿼리를 살펴보는 방식으로 성능을 모니터링하기는 어렵습니다.
예를 들어, 워크로드가 사용자에 따라 ID, 매우 빠르게 실행되며 개별 분석이 불가능할 정도로 빠른 속도로 반복되는 매우 유사한 수천 개의 포인트 조회 쿼리와 삽입으로 구성되어 있을 수 있습니다. 이와 같은 질문에 답하려면 이러한 작업에 대한 집계된 뷰가 필수적입니다.
내 계정 또는 워크로드에서 어떤 그룹화된 쿼리(또는 매개 변수화된 쿼리)가 총 시간 또는 리소스를 가장 많이 소비하고 있나요?
매개 변수화된 쿼리의 성능이 시간이 지남에 따라 크게 변경되었나요?
매개 변수화된 쿼리에는 어떤 종류의 문제가 발생하나요? 잠겼나요? 큐에 추가되었나요? 편집 시간이 오래 걸리나요?
매개 변수화된 쿼리는 얼마나 자주 성공하거나 실패하나요? 1% 미만인가요, 아니면 그보다 더 자주 발생하나요?
그룹화된 쿼리 기록 사용 방법¶
Snowsight 에서 Grouped Query History 에 액세스하려면 다음을 수행합니다.
Snowsight 에 로그인합니다.
탐색 메뉴에서 Monitoring » Query History » :ui:`Grouped Queries`를 선택합니다. 이 페이지에는 공통된 :doc:`매개 변수화된 쿼리 해시ID </user-guide/query-hash>`를 기준으로 그룹화된 쿼리가 표시됩니다.
참고
개별 쿼리는 Grouped Queries 목록에 즉시 표시되지 않습니다. AGGREGATE_QUERY_HISTORY 뷰의 기록에서 목록을 업데이트하는 데 걸리는 대기 시간은 최대 180분(3시간)이지만 목록이 훨씬 빠르게 채워지는 경우가 많습니다.
그룹화된 쿼리를 선택하면 해당 매개 변수화된 쿼리 해시에 대한 성능 통계를 볼 수 있습니다. Snowsight 는 실행된 총 쿼리 수, 실패한 쿼리 수, 지연 시간(p50, p90, p99) 및 분당 실행 횟수를 표시합니다. 페이지 하단 섹션에는 해당 해시의 일부로 실행된 샘플 개별 쿼리가 표시되며, 각 쿼리를 선택하여 구체적인 세부 정보를 확인할 수 있습니다.
예를 들어, 지난 하루 동안 이 그룹에서 약 540개의 쿼리가 실행되었으며, 총 지속 시간은 3시간이었습니다.
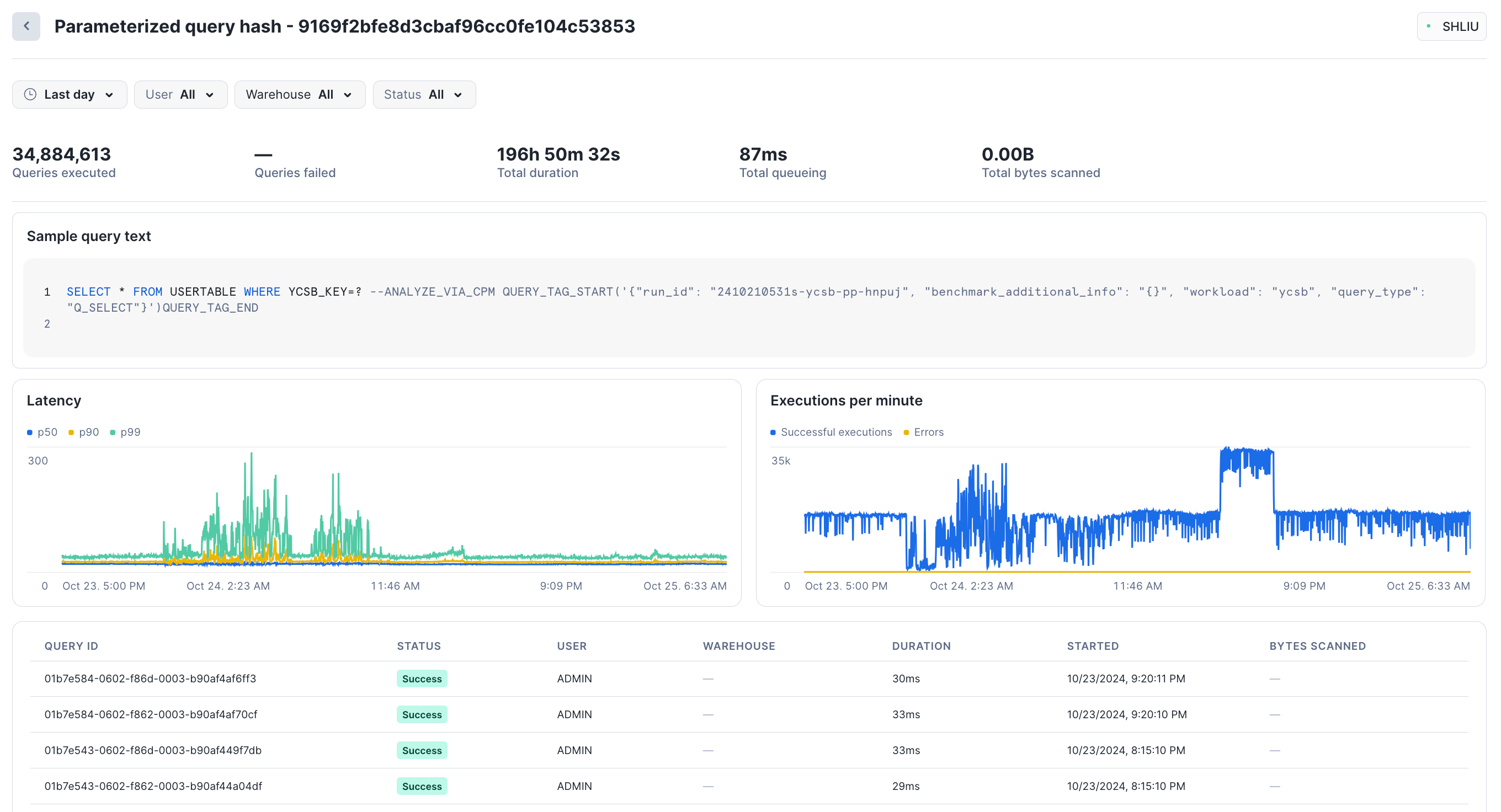
Parameterized query hash 뷰에서 Failed 또는 ``Successful``와 같은 상태별로 쿼리를 필터링할 수 있습니다. Grouped Queries 뷰 및 Parameterized query hash 뷰 모두에서 날짜 범위별, 사용자별, 웨어하우스별로 필터링할 수 있습니다. 날짜 범위는 그룹화된 쿼리 기록의 최대 최근 14일로 제한됩니다. 14일 전에 실행된 쿼리에 대한 정보는 검색할 수 없습니다.
일부 웨어하우스는 Snowflake에서 관리하는 내부 웨어하우스이며, 해당 웨어하우스는 Warehouse 필터에 표시되지 않습니다. 마찬가지로, SYSTEM 사용자는 :ui:`User`에 표시되지 않습니다.
필터를 사용하는 대신 필터링된 결과를 반환하는 집계 쿼리를 실행할 수 있습니다. AGGREGATE_QUERY_HISTORY 뷰 섹션을 참조하세요.
개별 쿼리 목록¶
또는 Individual Queries`에서 확인할 수 있습니다. 이 뷰는 하이브리드 테이블에 대해 생성될 수 있는 쿼리의 양이 매우 많기 때문에 Unistore 워크로드에서 실행되는 모든 쿼리를 반영하지는 않습니다. 이 동작에 대한 자세한 내용은 :ref:`label-query_history_usage_notes_acct_usage`의 하이브리드 테이블 섹션을 참조하세요. Snowflake는 Unistore 워크로드를 사용하는 모든 사용자가 :ui:`Grouped Queries 뷰에서 모니터링하는 것으로 시작할 것을 권장합니다.
그룹화된 쿼리 기록을 보는 데 필요한 권한¶
사용자는 언제든지 실행한 쿼리의 기록을 볼 수 있습니다. 사용자의 활동 역할은 표시되는 다른 쿼리에 영향을 줍니다. 다음 중 하나에 해당하는 경우 Grouped Queries 및 Individual Queries 가 모두 표시됩니다.
귀하의 활동 역할은 ACCOUNTADMIN 입니다.
SNOWFLAKE 데이터베이스에서 IMPORTED PRIVILEGES 활동 역할이 부여되었습니다(SNOWFLAKE 데이터베이스의 스키마를 사용할 다른 역할 활성화 참조).
GOVERNANCE_VIEWER 데이터베이스 역할 이 있습니다.
이러한 역할이나 권한이 없는 경우 Individual Queries 만 볼 수 있습니다. 액세스 권한에 대한 자세한 내용은 쿼리 기록으로 쿼리 활동 모니터링하기 섹션을 참조하십시오.
특정 쿼리의 세부 정보 및 프로필 검토하기¶
Query History 에서 쿼리를 선택하면 해당 쿼리의 세부 정보와 프로필을 검토할 수 있습니다.
Snowflake Native App 에서 수정된 쿼리 프로필 데이터¶
Snowflake Native App Framework 는 다음과 같은 컨텍스트에서 쿼리 프로필 의 정보를 수정합니다.
앱이 설치되거나 업그레이드될 때 실행되는 쿼리입니다.
앱이 소유한 저장 프로시저에서 발생하는 쿼리입니다.
앱이 소유한 안전하지 않은 뷰 또는 함수가 포함된 쿼리입니다.
이러한 각 유형의 쿼리에 대해 Snowsight 는 전체 쿼리 프로필 트리를 표시하는 대신 쿼리 프로필 데이터를 비어 있는 단일 노드로 축소합니다.
쿼리 세부 정보 검토하기¶
특정 쿼리의 세부 정보를 검토하고 성공적인 쿼리 결과를 보려면 쿼리에 대한 Query Details 를 여십시오.
다음을 포함하여 쿼리 실행에 대한 정보를 보려면 Details 를 검토할 수 있습니다.
쿼리의 상태.
쿼리가 시작된 시간(사용자의 현지 타임존).
쿼리가 종료된 시간(사용자의 현지 타임존).
쿼리를 실행하는 데 사용된 웨어하우스의 크기.
쿼리 기간.
쿼리 ID.
쿼리의 쿼리 태그(존재하는 경우).
드라이버 상태. 자세한 내용은 View the Snowflake client version 섹션을 참조하십시오.
쿼리를 제출하는 데 사용된 클라이언트, 드라이버 또는 라이브러리의 이름과 버전. 예를 들어 Snowsight 를 사용하여 실행되는 쿼리의 경우
Go 1.1.5입니다.세션 ID.
Query Details 탭 위에 나열된 쿼리를 실행한 사용자와 쿼리를 실행하는 데 사용된 웨어하우스를 볼 수 있습니다.
SQL Text 섹션에서 쿼리의 실제 텍스트를 검토합니다. SQL 텍스트를 마우스로 가리켜 워크시트에서 문을 열거나 문을 복사할 수 있습니다. 쿼리가 실패한 경우 오류 세부 정보를 검토할 수 있습니다.
Results 섹션에는 쿼리의 결과가 표시됩니다. 결과의 처음 10,000행만 볼 수 있으며 쿼리를 실행한 사용자만 결과를 볼 수 있습니다. 전체 결과 세트를 CSV 형식의 파일로 내보내려면 Export Results 를 선택하십시오.
쿼리 프로필 검토하기¶
Query Profile 탭을 통해 쿼리 실행 계획을 탐색하고 각 실행 단계에 대해 세분화된 정보를 파악할 수 있습니다.
쿼리 프로필은 쿼리의 역학을 이해할 수 있는 강력한 도구입니다. 특정 쿼리의 성능이나 동작에 대해 자세히 확인해야 할 때마다 사용할 수 있으며, 잠재적인 성능 병목 현상 및 향상 기회를 식별하기 위해 SQL 쿼리식에서 일반적인 실수를 확인할 수 있도록 설계되었습니다.
이 섹션에서는 쿼리 프로필을 탐색하고 사용하는 방법에 대한 간략한 개요를 제공합니다.
인터페이스 |
설명 |
|---|---|
쿼리 실행 계획 |
쿼리 실행 계획은 쿼리 프로필 중앙에 표시됩니다. 쿼리 실행 계획은 행 세트 연산자를 나타내는 연산자 노드로 구성됩니다. 연산자 노드 사이의 화살표는 한 연산자에서 다른 연산자로 이동하는 행 세트를 나타냅니다. |
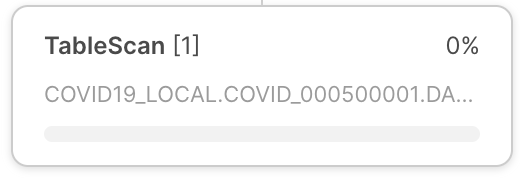
연산자 노드 |
각 연산자 노드는 다음을 포함합니다.
|

쿼리 프로필 탐색 |
쿼리 프로필의 왼쪽 위 모서리에서 이 버튼을 사용해 다음 작업을 수행할 수 있습니다.
참고 단계는 쿼리가 단계적으로 실행되는 경우에만 나타납니다. |

정보 창 |
쿼리 프로필에서는 다양한 정보 창을 제공합니다. 이러한 창은 쿼리 실행 계획에 나타납니다. 나타나는 창은 쿼리 실행 계획의 포커스에 따라 다릅니다. 쿼리 프로필은 다음 정보 창을 포함합니다.
창에서 제공하는 정보에 대한 자세한 내용은 쿼리 프로필 참조 섹션을 참조하십시오. |
Snowflake Native App 에서 수정된 기록 데이터 쿼리¶
Snowflake Native App 과 관련된 쿼리의 경우 query_text 및 error_message 필드는 다음 컨텍스트의 쿼리 기록 에서 수정됩니다.
앱이 설치되거나 업그레이드될 때 실행되는 쿼리.
앱이 소유한 저장 프로시저의 하위 작업에서 발생하는 쿼리.
이러한 각 상황에서 Snowsight 의 쿼리 기록 셀은 공백으로 나타납니다.
쿼리 프로필 참조¶
이 섹션에서는 각 정보 창에 나타날 수 있는 모든 항목에 대해 설명합니다. 정보 창의 정확한 내용은 쿼리 실행 계획의 컨텍스트에 따라 다릅니다.
프로필 개요¶
이 창에서는 쿼리 시간을 사용한 처리 작업에 대한 정보를 제공합니다. 실행 시간은 쿼리를 처리하는 동안 “시간이 사용된 위치”에 대한 정보를 제공합니다. 사용한 시간은 다음의 카테고리로 분류할 수 있습니다.
Processing — CPU에서 데이터를 처리하기 위해 사용된 시간입니다.
Local Disk IO — 로컬 디스크 액세스에 의해 처리가 차단된 시간입니다.
Remote Disk IO — 원격 디스크 액세스에 의해 처리가 차단된 시간입니다.
Network Communication — 처리에서 네트워크 데이터 전송을 대기 중이었던 시간입니다.
Synchronization — 참여 프로세스 사이에서의 다양한 동기화 활동입니다.
Initialization — 쿼리 처리를 설정하기 위해 사용된 시간입니다.
Hybrid Table Requests Throttling — 하이브리드 테이블에 저장된 데이터 읽기 및 쓰기 요청을 스로틀링 하는 데 소요되는 시간입니다.
쿼리 인사이트¶
쿼리 실행 성능에 영향을 미치는 조건이 있는 경우 이 창은 해당 조건에 대한 인사이트를 제공합니다. 각 인사이트에는 쿼리 성능이 어떻게 영향을 받을 수 있는지에 대한 설명과 다음 단계에 대한 일반적인 권장 사항이 포함된 메시지가 제공됩니다.
자세한 내용은 쿼리 인사이트를 사용하여 성능 개선하기 섹션을 참조하십시오.
참고
:doc:`/sql-reference/account-usage/query_insights`를 쿼리하여 이러한 인사이트를 얻을 수도 있습니다.
통계¶
세부 정보 창에서 제공되는 주요 정보 소스는 다양한 통계이며, 이는 다음 섹션으로 그룹화됩니다.
IO — 쿼리 중에 수행된 입출력 작업에 대한 정보:
스캔 진행률 — 해당 테이블에서 현재 스캔한 데이터의 백분율입니다.
스캔된 바이트 수 — 현재까지 스캔한 바이트 수입니다.
캐시에서 스캔된 백분율 — 로컬 디스크 캐시에서 스캔한 데이터의 백분율입니다.
작성된 바이트 수 — 기록된 바이트 수(예: 테이블에 로드할 때)입니다.
결과에 작성된 바이트 수 — 결과 오브젝트에 기록된 바이트 수입니다. 예를 들어,
select * from . . .은 선택 항목에 있는 각 필드를 나타내는 표 형식의 결과 세트를 생성합니다. 일반적으로, 결과의 결과로 생성된 모든 것을 나타내고 결과에 작성된 바이트 수 는 반환된 결과의 크기를 나타냅니다.결과에서 읽은 바이트 수 — 결과 오브젝트에서 읽은 바이트 수입니다.
스캔된 외부 바이트 수 — 외부 오브젝트(예: 스테이지)에서 읽은 바이트 수입니다.
DML — 데이터 조작 언어(DML) 쿼리에 대한 통계:
삽입된 행 수 — 테이블 1개(또는 테이블 여러 개)에 삽입된 행 수입니다.
업데이트된 행 수 — 테이블에서 업데이트된 행 수입니다.
삭제된 행 수 — 테이블에서 삭제된 행 수입니다.
언로드된 행 수 — 데이터 내보내기 중 언로드된 행 수입니다.
Pruning — 테이블 정리의 효과에 대한 정보:
스캔된 파티션 — 현재까지 스캔한 파티션의 수입니다.
파티션 총계 — 지정된 테이블의 총 파티션 수입니다.
Spilling — 임시 결과가 메모리에 적합하지 않는 작업에 대한 디스크 사용량 정보:
로컬 저장소로 분산된 바이트 수 —로컬 디스크에 분산된 데이터 볼륨입니다.
원격 저장소로 분산된 바이트 수 —원격 디스크에 분산된 데이터 볼륨입니다.
Network — 네트워크 통신:
네트워크를 통해 전송된 바이트 수 — 네트워크를 통해 전송된 데이터의 양입니다.
External Functions — 외부 함수 호출에 대한 정보:
SQL 문에 의해 호출되는 각 외부 함수와 관련하여 다음과 같은 통계가 표시됩니다. 동일한 SQL 문에서 동일한 함수가 두 번 이상 호출되면 통계가 집계됩니다.
총 호출 수 — 외부 함수가 호출된 횟수입니다. (행을 나누는 일괄 처리의 수, 재시도 횟수(일시적인 네트워크 장애가 있는 경우) 등으로 인해 SQL 문의 텍스트에 표시된 외부 함수 호출 횟수와 다를 수 있음)
전송된 행 수 — 외부 함수로 전송된 행의 개수입니다.
수신된 행 수 — 외부 함수로부터 수신된 행의 개수입니다.
전송된 바이트 수(x-리전) — 외부 함수로 전송된 행의 개수입니다. 레이블에 “(x-리전)”이 포함된 경우, 데이터가 여러 리전으로 전송되었습니다(청구에 영향을 줄 수 있음).
수신된 바이트 수(x-리전) — 외부 함수로부터 수신된 행의 개수입니다. 레이블에 “(x-리전)”이 포함된 경우, 데이터가 여러 리전으로 전송되었습니다(청구에 영향을 줄 수 있음).
일시적인 오류로 인한 재시도 — 일시적인 오류로 인한 재시도 횟수입니다.
호출당 평균 지연 시간 — Snowflake가 데이터를 전송한 후 반환된 데이터를 수신한 시간 사이의 호출당 평균 시간입니다.
HTTP 4xx 오류 — 4xx 상태 코드를 반환한 총 HTTP 요청 수입니다.
HTTP 5xx 오류 — 5xx 상태 코드를 반환한 총 HTTP 요청 수입니다.
성공한 호출당 대기 시간(평균) — 성공적인 HTTP 요청의 평균 대기 시간입니다.
평균 제한 대기 시간 오버헤드 — 제한에 따른 속도 저하로 인한 성공적인 요청당 평균 오버헤드입니다(HTTP 429).
제한으로 인해 재시도된 배치 — HTTP 429 오류로 인해 재시도된 배치 수입니다.
성공한 호출당 대기 시간(P50) — 성공적인 HTTP 요청의 50번째 백분위수 대기 시간입니다. 성공적인 모든 요청의 50%가 완료하는 데 이 시간보다 짧게 걸렸습니다.
성공한 호출당 대기 시간(P90) — 성공적인 HTTP 요청의 90번째 백분위수 대기 시간입니다. 성공적인 모든 요청의 90%가 완료하는 데 이 시간보다 짧게 걸렸습니다.
성공한 호출당 대기 시간(P95) — 성공적인 HTTP 요청의 95번째 백분위수 대기 시간입니다. 성공적인 모든 요청의 95%가 완료하는 데 이 시간보다 짧게 걸렸습니다.
성공한 호출당 대기 시간(P99) — 성공적인 HTTP 요청의 99번째 백분위수 대기 시간입니다. 성공적인 모든 요청의 99%가 완료하는 데 이 시간보다 짧게 걸렸습니다.
Extension Functions — 확장 함수 호출에 대한 정보:
Java UDF handler load time — 로드할 Java UDF 처리기를 위한 시간입니다.
Total Java UDF handler invocations — Java UDF 처리기가 호출되는 횟수입니다.
Max Java UDF handler execution time — 실행할 Java UDF 처리기의 최대 시간입니다.
Avg Java UDF handler execution time — Java UDF 처리기를 실행할 평균 시간입니다.
Java UDTF process() invocations — Java UDTF 프로세스 메서드 가 호출된 횟수입니다.
Java UDTF process() execution time — Java UDTF 프로세스 실행에 걸리는 시간입니다.
Avg Java UDTF process() execution time — Java UDTF 프로세스 실행에 걸린 평균 시간입니다.
Java UDTF’s constructor invocations — Java UDTF 생성자 가 호출된 횟수입니다.
Java UDTF’s constructor execution time — Java UDTF 생성자 실행에 걸리는 시간입니다.
Avg Java UDTF’s constructor execution time — Java UDTF 생성자 실행에 걸리는 평균 시간입니다.
Java UDTF endPartition() invocations — Java UDTF endPartition 메서드 가 호출된 횟수입니다.
Java UDTF endPartition() execution time — Java UDTF endPartition 메서드 실행에 걸리는 시간입니다.
Avg Java UDTF endPartition() execution time — Java UDTF endPartition 메서드 실행에 걸리는 평균 시간입니다.
Max Java UDF dependency download time — Java UDF 종속 항목 다운로드에 걸리는 최대 시간입니다.
Max JVM memory usage — JVM에서 보고한 최대 메모리 사용량입니다.
Java UDF inline code compile time in ms — Java UDF 인라인 코드의 컴파일 시간입니다.
Total Python UDF handler invocations — Python UDF 처리기가 호출된 횟수입니다.
Total Python UDF handler execution time — Python UDF 처리기의 총 실행 시간입니다.
Avg Python UDF handler execution time — Python UDF 처리기 실행에 걸리는 평균 시간입니다.
Python sandbox max memory usage — Python 샌드박스 환경의 최대 메모리 사용량입니다.
Avg Python env creation time: Download and install packages — 패키지 다운로드와 설치를 포함하여 Python 환경을 만드는 데 걸리는 평균 시간입니다.
Conda solver time — Python 패키지를 해결하기 위해 Conda 솔버를 실행하는 데 걸리는 시간입니다.
Conda env creation time — Python 환경을 만드는 데 걸리는 시간입니다.
Python UDF initialization time — Python UDF를 초기화하는 데 걸리는 시간입니다.
Number of external file bytes read for UDFs — UDF에 대해 읽은 외부 파일 바이트 수입니다.
Number of external files accessed for UDFs — UDF에 대해 액세스한 외부 파일 수입니다.
필드 값(예: “일시적인 오류로 인한 재시도”)이 0이면 필드가 표시되지 않습니다.
가장 비용이 큰 노드¶
이 창에는 쿼리의 총 실행 시간(또는 쿼리가 여러 처리 단계에서 실행되는 경우 표시된 쿼리 단계의 실행 시간) 중 1% 이상 동안 유지된 모든 노드가 나열됩니다. 그리고 실행 시간별로 노드가 내림차순으로 나열되어 사용자가 실행 시간의 측면에서 가장 비용이 많이 소요되는 연산자 노드를 빠르게 찾을 수 있습니다.
속성¶
다음 섹션에서는 가장 일반적인 연산자 타입의 목록 및 속성을 제공합니다.
데이터 액세스 및 생성 연산자¶
- TableScan:
단일 테이블에 대한 액세스를 나타냅니다. 속성:
전체 테이블 이름 — 스캔된 테이블의 정규화된 이름
테이블 별칭 — 사용된 테이블 별칭, 있는 경우
열 — 스캔된 열 목록
추출된 베리언트 경로 — VARIANT 열에서 추출된 경로의 목록
스캔 모드 — ROW_BASED 또는 COLUMN_BASED(하이브리드 테이블의 스캔 에만 표시)
액세스 조건 — 테이블 스캔 중에 적용되는 쿼리의 조건
- IndexScan:
하이브리드 테이블의 보조 인덱스 에 대한 액세스를 나타냅니다. 속성:
전체 테이블 이름 — 인덱스를 포함하는 스캔된 테이블의 정규화된 이름
열 — 스캔된 인덱스 열 목록
스캔 모드 — ROW_BASED 또는 COLUMN_BASED
액세스 조건 — 인덱스 스캔 중에 적용되는 쿼리의 조건
전체 인덱스 이름 — 스캔된 인덱스의 정규화된 이름
- ValuesClause:
VALUES 절과 함께 제공되는 값 목록입니다. 속성:
값의 개수 — 생성된 값의 개수입니다.
값 — 생성된 값의 목록입니다.
- 생성기:
TABLE(GENERATOR(...))구문을 사용하여 레코드를 생성합니다. 속성:rowCount — 제공된 rowCount 매개 변수입니다.
timeLimit — 제공된 timeLimit 매개 변수입니다.
- ExternalScan:
스테이지 오브젝트에 저장된 데이터에 대한 액세스를 나타냅니다. 스테이지에서 데이터를 직접 스캔하는 쿼리의 일부일 수 있지만, 데이터 로딩 작업(즉, COPY 문)에도 사용할 수 있습니다.
속성:
스테이지 이름 — 데이터를 읽는 스테이지의 이름입니다.
스테이지 타입 — 스테이지의 타입(예: TABLE STAGE)입니다.
- InternalObject:
내부 데이터 오브젝트(예: Information Schema 테이블 또는 이전 쿼리 결과)에 대한 액세스를 나타냅니다. 속성:
오브젝트 이름 — 액세스한 오브젝트의 이름 또는 타입입니다.
데이터 처리 연산자¶
- 필터:
레코드를 필터링하는 작업을 나타냅니다. 속성:
필터 조건 - 필터링을 수행하기 위해 사용되는 조건입니다.
- 조인:
지정된 조건에서 두 입력을 결합합니다. 속성:
조인 타입 — 조인 타입(예: INNER, LEFT OUTER 등)입니다.
같음 조인 조건 — 같음 기반 조건을 사용하는 조인의 경우 요소를 조인하기 위해 사용되는 식을 나열합니다.
추가 조인 조건 — 일부 조인은 같음이 아닌 조건자를 포함하는 조건을 사용합니다. 그러한 경우 여기에 나열됩니다.
참고
같음이 아닌 조인 조건자는 처리 속도가 상당히 느려질 수 있으므로 가능하면 사용하지 말아야 합니다.
- 집계:
입력을 그룹화하고 집계 함수를 계산합니다. GROUP BY 및 SELECT DISTINCT와 같은 SQL 구문을 나타낼 수 있습니다. 속성:
그룹화 키 — GROUP BY를 사용하면 그룹화 기준으로 사용된 식이 나열됩니다.
집계 함수 — 각 집계 그룹에 대해 계산된 함수(예: SUM)의 목록입니다.
- GroupingSets:
GROUPING SETS, ROLLUP 및 CUBE 등의 구문을 나타냅니다. 속성:
그룹화 키 세트 — 그룹화 세트의 목록
집계 함수 — 각 그룹에 대해 계산된 함수(예: SUM)의 목록입니다.
- WindowFunction:
윈도우 함수를 계산합니다. 속성:
윈도우 함수 — 계산된 윈도우 함수의 목록입니다.
- 정렬:
지정된 식에서 입력을 정렬합니다. 속성:
정렬 키 — 정렬 순서를 정의하는 식입니다.
- SortWithLimit:
일반적으로 SQL에서
ORDER BY ... LIMIT ... OFFSET ...구문의 결과인 정렬 후 입력 시퀀스의 일부를 생성합니다.속성:
정렬 키 — 정렬 순서를 정의하는 식입니다.
행 개수 — 생성된 행의 개수입니다.
오프셋 — 생성된 튜플이 출력되는 순서가 지정된 시퀀스의 위치입니다.
- 데이터 스큐:
VARIANT 레코드를 처리하여 지정된 경로에서 평면화할 수 있습니다. 속성:
입력 — 데이터를 평면화하기 위해 사용되는 입력 식입니다.
- JoinFilter:
쿼리 계획에서 더 이상 조인 조건과 일치하지 않는 것으로 식별될 수 있는 튜플을 제거하는 특수 필터링 작업입니다. 속성:
원래 조인 ID — 필터링할 수 있는 튜플을 식별하기 위해 사용되는 조인입니다.
- UnionAll:
두 입력을 연결합니다. 속성: 없음
- ExternalFunction:
외부 함수에 의한 처리를 나타냅니다.
DML 연산자¶
- 삽입:
INSERT 또는 COPY 작업을 통해 테이블에 레코드를 추가합니다. 속성:
입력 식 — 식이 삽입됩니다.
테이블 이름 — 레코드가 추가되는 테이블의 이름입니다.
- 삭제:
테이블에서 레코드를 제거합니다. 속성:
테이블 이름 — 레코드가 삭제되는 테이블의 이름입니다.
- 업데이트:
테이블에서 레코드를 업데이트합니다. 속성:
테이블 이름 — 업데이트된 테이블의 이름입니다.
- 병합:
테이블에 대한 MERGE 연산을 수행합니다. 속성:
전체 테이블 이름 — 업데이트된 테이블의 이름입니다.
- 언로드:
테이블의 데이터를 스테이지의 파일로 내보내는 COPY 작업을 나타냅니다. 속성:
위치 - 데이터가 저장되는 스테이지의 이름입니다.
메타데이터 연산자¶
일부 쿼리에는 데이터 처리 작업이 아닌 순수한 메타데이터/카탈로그 작업에 해당하는 단계가 포함됩니다. 이러한 단계는 단일 연산자로 구성됩니다. 몇 가지 예는 다음과 같습니다.
- DDL 및 트랜잭션 명령:
오브젝트, 세션, 트랜잭션 등을 생성 또는 수정하기 위해 사용됩니다. 일반적으로 이러한 쿼리는 가상 웨어하우스에 의해 처리되지 않으며 결과적으로 일치하는 SQL 문에 해당하는 단일 단계 프로필이 됩니다. 예:
CREATE DATABASE | SCHEMA | …
ALTER DATABASE | SCHEMA | TABLE | SESSION | …
DROP DATABASE | SCHEMA | TABLE | …
COMMIT
- 테이블 만들기 명령:
테이블을 만들기 위한 DDL 명령입니다. 예:
CREATE TABLE
다른 DDL 명령과 유사하게, 이러한 쿼리에서는 단일 단계 프로필이 생성되지만, CTAS 문에서 사용되는 경우와 같이 다단계 프로필의 일부일 수도 있습니다. 예:
CREATE TABLE … AS SELECT …
- 쿼리 결과 재사용:
이전 쿼리의 결과를 재사용하는 쿼리입니다.
- 메타데이터 기반 결과:
데이터에 액세스하지 않고 메타데이터만을 기반으로 하여 결과가 계산되는 쿼리입니다. 이러한 쿼리는 가상 웨어하우스에 의해 처리되지 않습니다. 예:
SELECT COUNT(*) FROM …
SELECT CURRENT_DATABASE()
기타 연산자¶
- 결과:
쿼리 결과를 반환합니다. 속성:
식 목록 - 생성된 식입니다.
쿼리 프로필을 통해 확인된 일반 쿼리 문제¶
이 섹션에서는 쿼리 프로필을 사용하여 식별 및 해결이 가능한 몇 가지 문제에 대해 설명합니다.
“급증하는” 조인¶
SQL 사용자가 저지르는 일반적인 실수 중 하나는 조인 조건을 제공하지 않고 테이블을 조인하거나(그로 인해 “데카르트 곱”이 수행됨) 한 테이블의 레코드가 다른 테이블의 여러 레코드와 일치하는 조건을 제공하는 것입니다. 이러한 쿼리의 경우 Join 연산자에서는 사용량보다 훨씬 더 많은 튜플을 생성(크기 기준)합니다.
이는 Join 연산자가 생성한 레코드의 수를 통해 확인할 수 있으며, 일반적으로 Join 연산자에서 오랜 시간이 걸리는 원인이 됩니다.
ALL을 제외한 UNION¶
SQL에서는 UNION 또는 UNION ALL 구문으로 두 데이터 세트를 결합할 수 있습니다. 차이점은 UNION ALL는 단순히 입력을 연결하는 반면 UNION은 동일하게 연결하지만 중복 제거를 수행한다는 점입니다.
일반적인 실수는 UNION ALL 의미 체계로 충분한 상황에서 UNION를 사용하는 것입니다. 이러한 쿼리는 쿼리 프로필에 UnionAll 연산자로 표시되며 맨 위에는 추가 Aggregate 연산자(중복 제거 수행)가 표시됩니다.
너무 커서 메모리에 적합하지 않은 쿼리¶
일부 작업(예: 방대한 데이터 세트에 대한 중복 제거)의 경우 작업을 실행하기 위해 사용되는 서버의 가용 메모리가 임시 결과를 유지하기에 충분하지 않을 수 있습니다. 결과적으로 쿼리 처리 엔진은 데이터를 로컬 디스크로 유출 하기 시작합니다. 로컬 디스크 공간이 충분하지 않으면 유출된 데이터가 원격 디스크에 저장됩니다.
이러한 유출은 쿼리 성능에 커다란 영향을 미칠 수 있습니다(특히 유출에서 원격 디스크가 사용되는 경우). 이를 완화하기 위한 권장 사항은 다음과 같습니다.
더 큰 크기의 웨어하우스 사용(사실상 작업에서 사용할 수 있는 메모리/로컬 디스크 공간을 증가) 및/또는
크기가 더 작은 일괄 처리로 데이터 처리.
비효율적인 정리¶
Snowflake는 데이터에 대한 풍부한 통계를 수집하여 쿼리 필터를 기반으로 테이블의 불필요한 부분을 읽을 필요가 없습니다. 그러나 이를 위해서는 데이터 저장소 순서가 쿼리 필터 속성과 관련이 있어야 합니다.
정리의 효율성은 TableScan 연산자에서 스캔된 파티션 및 전체 파티션 통계를 비교하여 확인할 수 있습니다. 전자가 후자에 비해 일부에 불과하면 정리가 효율적인 것입니다. 그렇지 않으면, 정리가 효과가 없는 것입니다.
물론, 정리는 실제로 상당한 양의 데이터를 필터링하는 쿼리에만 유용할 수 있습니다. 정리 통계에는 데이터 감소가 표시되지 않지만, 대량의 레코드를 필터링하는 TableScan 상단에 Filter 연산자가 있는 경우 다른 데이터 구성이 이 쿼리에 유용하다는 신호가 될 수 있습니다.
정리에 대한 자세한 내용은 Snowflake 테이블 구조 이해하기 을 참조하십시오.