Monitoramento da atividade de consulta com o Histórico de consultas¶
Para monitorar a atividade de consulta em sua conta, você pode usar:
As páginas Query History e Grouped Query History no Snowsight.
Exibição QUERY_HISTORY e Exibição AGGREGATE_QUERY_HISTORY no esquema ACCOUNT_USAGE do banco de dados SNOWFLAKE.
A família QUERY_HISTORY de funções de tabela em INFORMATION_SCHEMA.
Na página Snowsight em Query History, você pode fazer o seguinte:
Monitore consultas individuais ou agrupadas que são executadas por usuários em sua conta.
Veja detalhes sobre consultas, incluindo dados de desempenho. Em alguns casos, os detalhes da consulta não estão disponíveis.
Explore cada etapa de uma consulta executada no perfil da consulta.
A página Histórico de consultas permite explorar as consultas executadas na sua conta Snowflake nos últimos 14 dias.
Em uma planilha, você pode ver o histórico de consultas que foram executadas nessa planilha. Consulte Visualização do histórico de consultas.
Revisão do histórico de consultas no Snowsight¶
Para acessar a página Query History em Snowsight, faça o seguinte:
Faça login na Snowsight.
No menu de navegação, selecione Monitoring » Query History.
Acesse Individual Queries ou Grouped Queries. Para obter mais informações sobre consultas agrupadas, consulte Como usar a exibição Histórico de consultas agrupadas no Snowsight.
Para Individual Queries, filtre sua exibição para ver os resultados mais relevantes e precisos.
Se um botão Load More aparecer na parte superior da lista, isso significa que há mais resultados disponíveis a serem carregados. É possível buscar o próximo conjunto de resultados selecionando Load More ou rolando até o final da lista.
Privilégios necessários para visualizar o histórico de consultas¶
Você sempre pode visualizar o histórico das consultas executadas.
Para visualizar o histórico de outras consultas, sua função ativa afeta o que mais você pode ver em Query History:
Se sua função ativa for a função ACCOUNTADMIN, você poderá visualizar todo o histórico de consultas da conta.
Se sua função ativa tiver o privilégio MONITOR ou OPERATE concedido em um warehouse, você poderá visualizar consultas executadas por outros usuários que usam esse warehouse.
Se sua função ativa receber a função de banco de dados GOVERNANCE_VIEWER para o banco de dados SNOWFLAKE, é suficiente para consultar as exibições ACCOUNT_USAGE diretamente com SQL, e também permite que você visualize Grouped Queries no Histórico de consultas. No entanto, essa função por si só não concede a capacidade de visualizar Individual Queries por outros usuários no Snowsight. Para visualizar todas as consultas do usuário (tanto agrupadas quanto individuais), sua função deve ser ACCOUNTADMIN ou ter a concessão de IMPORTED PRIVILEGES no banco de dados SNOWFLAKE. Como alternativa, os dois privilégios a seguir podem substituir o IMPORTED PRIVILEGES:
Se a função de banco de dados READER_USAGE_VIEWER for concedida à sua função ativa para o banco de dados SNOWFLAKE, você poderá visualizar o histórico de consultas de todos os usuários nas contas de leitor associadas à sua conta. Consulte Funções de banco de dados SNOWFLAKE.
Considerações sobre o uso do histórico de consultas¶
Ao analisar o Query History da sua conta, considere o seguinte:
Os detalhes das consultas executadas há mais de sete dias não incluem as informações de User devido à política de retenção de dados das sessões. Você pode usar o filtro de usuário para recuperar consultas executadas por usuários individuais. Consulte Filtro do histórico de consultas.
Para consultas que falharam devido a erros de sintaxe ou de análise, você verá
<redigido>em vez da instrução SQL que foi executada. Se você receber uma função com privilégios apropriados, poderá definir o parâmetro ENABLE_UNREDACTED_QUERY_SYNTAX_ERROR para visualizar o texto completo da consulta.Os filtros e as colunas Started e End Time usam seu fuso horário atual. Você não pode alterar essa configuração. Definir o parâmetro TIMEZONE para a sessão não altera o fuso horário usado.
Filtro do histórico de consultas¶
É possível filtrar a lista Histórico de consultas da seguinte forma:
Status da consulta, por exemplo, para identificar consultas de longa duração, consultas com falha e consultas em fila.
Usuário que realizou a consulta, incluindo:
All, para ver todos os usuários aos quais você tem acesso para visualizar o histórico de consultas.
O usuário que você usou para entrar (padrão)
Usuários individuais do Snowflake em sua conta, se sua função puder visualizar o histórico de consultas de outros usuários.
Período durante o qual a consulta foi executada, até 14 dias.
Outros filtros, incluindo os seguintes:
SQL Text, por exemplo, para visualizar consultas que usam instruções específicas, como GROUP BY.
Query ID, para visualizar detalhes de uma consulta específica.
Warehouse, para visualizar consultas que foram executadas usando um warehouse específico.
Statement Type, para visualizar consultas que usaram um tipo específico de instrução, como DELETE, UPDATE, INSERT ou SELECT.
Duration, por exemplo, para identificar consultas especialmente de longa duração.
Session ID, para visualizar consultas executadas durante uma sessão específica do Snowflake.
Query Tag, para visualizar consultas com uma tag de consulta específica definida por meio do parâmetro de sessão QUERY_TAG.
Parameterized Query Hash, para exibir as consultas agrupadas de acordo com o ID de hash de consulta parametrizada especificado no filtro. Para obter mais informações, consulte Uso do hash da consulta parametrizada (query_parameterized_hash).
Client generated statements, para visualizar consultas internas executadas por um cliente, driver ou biblioteca, incluindo a interface da web. Por exemplo, sempre que um usuário navega para a página Warehouses no Snowsight, o Snowflake executa uma instrução SHOW WAREHOUSES em segundo plano. Essa instrução ficaria visível quando este filtro estivesse habilitado. Sua conta não é cobrada por instruções geradas pelo cliente.
Queries executed by user tasks, para visualizar instruções SQL executadas ou procedimentos armazenados chamados pelas tarefas do usuário.
Show replication refresh history, para visualizar consultas usadas para executar tarefas de atualização de replicação em regiões e contas remotas.
Se quiser ver resultados quase em tempo real, ative Auto Refresh. Quando Auto Refresh está ativado, a tabela é atualizada a cada dez segundos.
Você pode ver as seguintes colunas na tabela Queries por padrão:
SQL Text, o texto da instrução executada (sempre mostrado).
Query ID, a ID da consulta (sempre mostrado).
Status, o status da instrução executada (sempre mostrado).
User, para ver o nome de usuário que executou uma instrução.
Warehouse, para ver o warehouse usado para executar uma instrução.
Duration, para ver quanto tempo levou para executar uma instrução.
Started, para ver a hora em que uma instrução começou a ser executada.
Se você tiver mais resultados, não poderá classificar a tabela. Se você selecionar Load More no topo da lista após classificar a tabela, os novos resultados serão anexados ao final dos dados e a ordem de classificação não será mais aplicada.
Para visualizar informações mais específicas, você pode selecionar Columns para adicionar ou remover colunas da tabela, como:
All para exibir todas as colunas.
User para exibir o usuário que executou a instrução.
Warehouse para exibir o nome do warehouse usado para executar a instrução.
Warehouse Size para exibir o tamanho do warehouse usado para executar a instrução.
Duration para exibir o tempo necessário para a execução da instrução.
Started para exibir a hora de início da instrução.
End Time para exibir a hora de término da instrução.
Session ID para exibir a ID da sessão que executou a instrução.
Client Driver para exibir o nome e a versão do cliente, driver ou biblioteca usada para executar a instrução. As instruções executadas em Snowsight mostram
Go 1.1.5.Bytes Scanned para exibir o número de bytes verificados durante o processamento da consulta.
Rows para exibir o número de linhas retornadas por uma instrução.
Query Tag para exibir a tag de consulta definida para uma consulta.
Parameterized Query Hash para exibir consultas agrupadas de acordo com o ID de hash de consulta parametrizada especificado no filtro. Para obter mais informações, consulte Uso do hash da consulta parametrizada (query_parameterized_hash).
Incident para exibir detalhes de instruções com status de execução de incidente, usadas para fins de solução de problemas ou depuração.
Para visualizar detalhes adicionais sobre uma consulta, selecione uma consulta na tabela para abrir o Query Details.
Como usar a exibição Histórico de consultas agrupadas no Snowsight¶
É possível usar a exibição Grouped Query History no Snowsight para monitorar o uso e o desempenho de consultas críticas e frequentemente executadas. Essa exibição gráfica é baseada nas informações registradas em Exibição AGGREGATE_QUERY_HISTORY. As consultas executadas são agrupadas por um ID de hash de consulta parametrizado. É possível monitorar as principais estatísticas ao longo do tempo e detalhar as consultas individuais que pertencem a cada grupo.
Embora essa exibição inclua todas as consultas no Snowflake, ela é particularmente útil para monitorar e analisar as cargas de trabalho do Unistore que executam um pequeno número de instruções distintas repetidamente com alta taxa de transferência. Para cargas de trabalho envolvendo tabelas híbridas, é um desafio monitorar o desempenho analisando consultas individuais.
Por exemplo, sua carga de trabalho pode consistir em milhares de consultas e inserções de pesquisa de pontos muito semelhantes que variam apenas de acordo com o ID de usuário, são executadas com extrema rapidez e repetidas a uma taxa que torna impossível analisá-las individualmente. Uma exibição agregada dessas operações é essencial quando você deseja responder a perguntas como essas:
Quais consultas agrupadas (ou consultas parametrizadas) estão consumindo a maior parte do tempo total ou dos recursos em minha conta ou carga de trabalho?
O desempenho de uma consulta parametrizada mudou substancialmente ao longo do tempo?
Quais são os tipos de problemas que uma consulta parametrizada enfrenta? Bloqueio? Fila de espera? Tempos de compilação longos?
Com que frequência uma consulta parametrizada é bem-sucedida ou falha? Menos de um por cento das vezes, ou mais frequentemente do que isso?
Como usar o Histórico de consultas agrupadas¶
Para acessar Grouped Query History no Snowsight, faça o seguinte:
Faça login na Snowsight.
No menu de navegação, selecione Monitoring » Query History » Grouped Queries. A página mostra as consultas agrupadas por seu ID de hash de consulta parametrizada comum.
Nota
As consultas individuais não aparecem imediatamente na lista Grouped Queries. A latência para atualizar a lista a partir dos registros na exibição AGGREGATE_QUERY_HISTORY pode ser de até 180 minutos (3 horas), mas a lista geralmente é preenchida muito mais rapidamente.
Selecione qualquer consulta agrupada para ver as estatísticas de desempenho desse hash de consulta parametrizado. O Snowsight exibe o número total de consultas executadas, o número de consultas que falharam, a latência (p50, p90, p99) e as execuções por minuto. A seção inferior da página mostra alguns exemplos de consultas individuais executadas como parte desse hash; é possível selecionar cada consulta para ver seus detalhes específicos.
Por exemplo, durante o último dia, cerca de 540 consultas foram executadas neste grupo, com uma duração total de cerca de 3 horas:
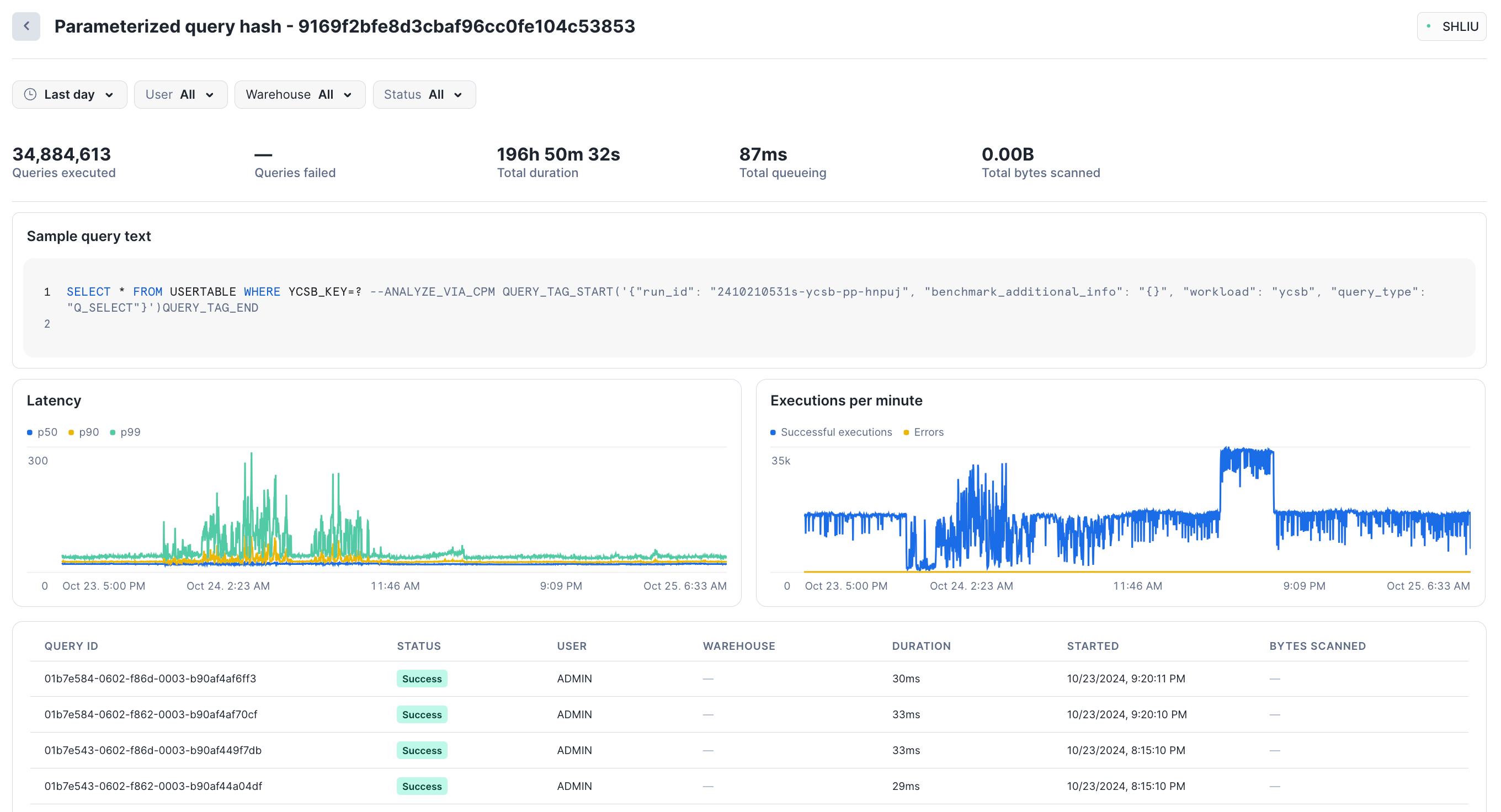
Na visualização Parameterized query hash, você pode filtrar consultas por status, como Failed ou Successful. Tanto na visualização Grouped Queries quanto na Parameterized query hash, é possível filtrar por um intervalo de datas, por usuário e por warehouse. O intervalo de datas é limitado a um máximo dos últimos 14 dias do histórico de consultas agrupadas. Você não pode recuperar informações sobre consultas que foram executadas há mais de 14 dias.
Observe que alguns warehouses são warehouses internos gerenciados pelo Snowflake, e esses warehouses não aparecem no filtro Warehouse. Da mesma forma, o usuário SYSTEM não aparece no filtro User.
Como alternativa ao uso de filtros, você pode executar consultas agregadas que retornam resultados filtrados. Consulte também o Exibição AGGREGATE_QUERY_HISTORY.
Lista de consultas individuais¶
Como alternativa, você pode consultar Individual Queries. Essa exibição não reflete todas as consultas executadas pelas cargas de trabalho do Unistore, dado o grande volume de consultas que podem ser criadas em tabelas híbridas. Para obter mais informações sobre esse comportamento, consulte a seção de tabelas híbridas do Notas de uso. A Snowflake recomenda que todos os usuários com cargas de trabalho do Unistore comecem monitorando a visualização Grouped Queries.
Privilégios necessários para visualizar o Histórico de consultas agrupadas¶
Os usuários sempre podem visualizar o histórico das consultas que executaram. A função ativa de um usuário afeta quais outras consultas são visíveis. É possível visualizar Grouped Queries e Individual Queries se uma das opções a seguir for verdadeira:
Sua função ativa é ACCOUNTADMIN.
Sua função ativa recebeu IMPORTED PRIVILEGES no banco de dados SNOWFLAKE (consulte Habilitando outras funções para usar esquemas no banco de dados SNOWFLAKE).
Você tem a função de banco de dados GOVERNANCE_VIEWER.
Se você não tiver nenhuma dessas funções ou privilégios, só poderá ver Individual Queries. Para obter mais informações sobre privilégios de acesso, consulte Monitoramento da atividade de consulta com o Histórico de consultas.
Revisão dos detalhes e do perfil de uma consulta específica¶
Ao selecionar uma consulta em Query History, você pode revisar os detalhes e o perfil da consulta.
Consulta de dados do perfil censurados de um Snowflake Native App¶
O Snowflake Native App Framework censura as informações do perfil de consulta nos seguintes contextos:
Consultas executadas quando o aplicativo é instalado ou atualizado.
Consultas originadas de um procedimento armazenado de propriedade do aplicativo.
Consultas contendo uma exibição ou função não segura de propriedade do aplicativo.
Para cada um desses tipos de consultas, Snowsight recolhe os dados do perfil de consulta em um único nó vazio em vez de exibir a árvore completa do perfil de consulta.
Revisão dos detalhes da consulta¶
Para revisar os detalhes de uma consulta específica e visualizar os resultados de uma consulta bem-sucedida, abra o Query Details de uma consulta.
Você pode revisar Details para obter informações sobre a execução da consulta, incluindo:
O status da consulta.
Quando a consulta foi iniciada, no fuso horário local do usuário.
Quando a consulta terminou, no fuso horário local do usuário.
O tamanho do warehouse usado para executar a consulta.
A duração da consulta.
A ID da consulta.
A tag de consulta da consulta, se existir.
O status do driver. Para obter mais detalhes, consulte View the Snowflake client version.
O nome e a versão do cliente, driver ou biblioteca usada para enviar a consulta. Por exemplo,
Go 1.1.5para consultas executadas usando Snowsight.A ID da sessão.
Você pode ver o warehouse usado para executar a consulta e o usuário que executou a consulta listados acima da guia Query Details.
Revise a seção SQL Text para obter o texto real da consulta. Você pode passar o mouse sobre o texto SQL para abrir a instrução em uma planilha ou copiar a instrução. Se a consulta falhar, você poderá revisar os detalhes do erro.
A seção Results mostra os resultados da consulta. Você só pode visualizar as primeiras 10.000 linhas de resultados, e somente o usuário que executou a consulta pode visualizar os resultados. Selecione Export Results para exportar o conjunto completo de resultados como um arquivo formatado em CSV.
Revisão do perfil de consulta¶
A guia Query Profile permite explorar o plano de execução da consulta e compreender detalhes granulares sobre cada etapa de execução.
O perfil da consulta é uma ferramenta poderosa para compreender a mecânica das consultas. Pode ser usado sempre que você precisar saber mais sobre o desempenho ou comportamento de uma determinada consulta. É projetado para ajudar a detectar erros típicos em expressões de consulta SQL para identificar possíveis gargalos de desempenho e oportunidades de melhoria.
Esta seção fornece uma breve visão geral de como navegar e usar o perfil de consulta.
Interface |
Descrição |
|---|---|
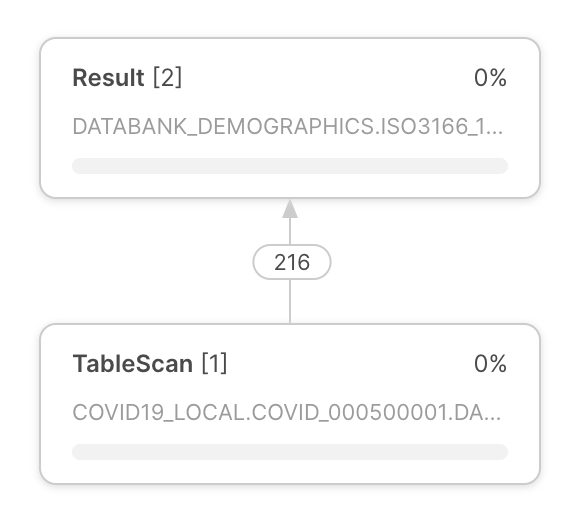
Plano de execução da consulta |
O plano de execução da consulta aparece no centro do perfil da consulta. O plano de execução da consulta é composto por nós de operador, que representam operadores de conjunto de linhas. As setas entre os nós do operador indicam os conjuntos de linhas que fluem de um operador para outro. |
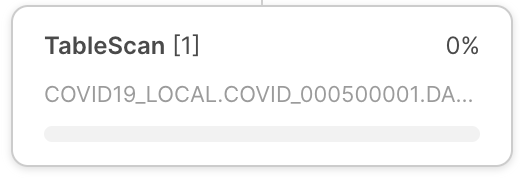
Nó do operador |
Cada nó de operador inclui o seguinte:
|

Navegação no perfil de consulta |
No canto superior esquerdo do perfil de consulta, use os botões para:
Nota As etapas só aparecem se a consulta foi executada em etapas. |

Painéis informativos |
O perfil de consulta fornece vários painéis de informação. Os painéis aparecem no plano de execução da consulta. Os painéis que aparecem dependem do foco do plano de execução da consulta. O perfil de consulta inclui os seguintes painéis de informação:
Para saber mais sobre as informações fornecidas pelos painéis, consulte Referência do perfil de consulta. |
Consulta de dados do histórico censurados de um Snowflake Native App¶
Para consultas relacionadas a Snowflake Native App, os campos query_text e error_message são censurados do histórico de consultas nos seguintes contextos:
As consultas são executadas quando o aplicativo é instalado ou atualizado.
Consultas originadas de um trabalho filho de um procedimento armazenado de propriedade do aplicativo.
Em cada uma dessas situações, a célula do histórico de consultas em Snowsight aparece em branco.
Referência do perfil de consulta¶
Esta seção descreve todos os itens que podem aparecer em cada painel de informação. O conteúdo exato dos painéis de informação depende do contexto do plano de execução da consulta.
Visão geral do perfil¶
O painel fornece informações sobre quais tarefas de processamento consumiram tempo de consulta. O tempo de execução fornece informações sobre “onde o tempo foi gasto” durante o processamento de uma consulta. O tempo gasto pode ser dividido nas seguintes categorias:
Processing — tempo gasto no processamento de dados pela CPU.
Local Disk IO — hora em que o processamento foi bloqueado pelo acesso a disco local.
Remote Disk IO — hora em que o processamento foi bloqueado pelo acesso a disco remoto.
Network Communication — tempo em que o processamento aguardava a transferência dos dados da rede.
Synchronization — diversas atividades de sincronização entre os processos participantes.
Initialization — tempo gasto na preparação do processamento da consulta.
Hybrid Table Requests Throttling — tempo gasto limitando solicitações de leitura e gravação de dados armazenados em tabelas híbridas.
Insights de consulta¶
Se houver condições que afetem o desempenho da execução da consulta, este painel fornecerá informações sobre essas condições. Cada insight inclui uma mensagem que explica como o desempenho da consulta pode ser afetado e fornece uma recomendação geral para as próximas etapas.
Para obter mais informações, consulte Uso de insights de consulta para melhorar o desempenho.
Nota
Você pode acessar esses insights consultando a exibição Exibição QUERY_INSIGHTS.
Estatísticas¶
Uma das principais fontes de informações fornecidas no painel de detalhes são as diversas estatísticas, agrupadas nas seções seguintes:
IO — informações sobre as operações de entrada-saída realizadas durante a consulta:
Scan progress — a porcentagem de dados verificados para uma determinada tabela até o momento.
Bytes scanned — o número de bytes verificados até o momento.
Percentage scanned from cache — a porcentagem de dados verificados a partir do cache do disco local.
Bytes written — bytes gravados (por exemplo, ao carregar em uma tabela).
Bytes written to result — bytes gravados no objeto de resultado. Por exemplo,
select * from . . .produziria um conjunto de resultados em formato tabular representando cada campo na seleção. Em geral, o objeto de resultado representa tudo o que é produzido como resultado da consulta, e Bytes gravados no resultado representa o tamanho do resultado retornado.Bytes read from result — bytes lidos do objeto de resultado.
External bytes scanned — bytes lidos a partir de um objeto externo, por exemplo, um estágio.
DML — estatísticas para consultas de linguagem de manipulação de dados (DML):
Number of rows inserted — número de linhas inseridas em uma tabela (ou tabelas).
Number of rows updated — número de linhas atualizadas em uma tabela.
Number of rows deleted — número de linhas excluídas de uma tabela.
Number of rows unloaded — número de linhas descarregadas durante a exportação de dados.
Pruning — informações sobre os efeitos da remoção realizada na tabela:
Partitions scanned — número de partições verificadas até o momento.
Partitions total — número total de partições em uma determinada tabela.
Spilling — informações sobre o uso do disco para operações onde os resultados intermediários não cabem na memória:
Bytes spilled to local storage — volume de dados despejados para o disco local.
Bytes spilled to remote storage — volume de dados despejados no disco remoto.
Network — comunicação em rede:
Bytes sent over the network — quantidade de dados enviados pela rede.
External Functions — informações sobre chamadas para funções externas:
As seguintes estatísticas são mostradas para cada função externa chamada pela instrução SQL. Se a mesma função foi chamada mais de uma vez a partir da mesma instrução SQL, então as estatísticas são agregadas.
Total invocations — número de vezes que uma função externa foi chamada. (Isto pode ser diferente do número de chamadas de funções externas no texto da instrução SQL devido ao número de lotes em que as linhas estão divididas, o número de novas tentativas (se houver problemas transitórios na rede), etc.)
Rows sent — número de linhas enviadas para funções externas.
Rows received — número de linhas recebidas de volta das funções externas.
Bytes sent (x-region) — número de bytes enviados para funções externas. Se o rótulo incluir “(x-region)”, os dados foram enviados através de regiões (o que pode ter impacto no faturamento).
Bytes received (x-region) — número de bytes recebidos de funções externas. Se o rótulo incluir “(x-region)”, os dados foram enviados através de regiões (o que pode ter impacto no faturamento).
Retries due to transient errors — número de tentativas de repetição devido a erros transitórios.
Average latency per call — média de tempo por invocação (chamada) entre o momento em que Snowflake enviou os dados e o recebimento dos dados devolvidos.
HTTP 4xx erros — número total de solicitações de HTTP que retornaram um código de status 4xx.
HTTP 5xx erros — número total de solicitações de HTTP que retornaram um código de status 5xx.
Latency per successful call (avg) — latência média para solicitações de HTTP bem-sucedidas.
Avg throttle latency overhead — sobretaxa média por solicitação bem-sucedida devido a uma desaceleração causada pela limitação (HTTP 429).
Batches retried due to throttling — número de lotes que foram repetidos devido a erros HTTP 429.
Latency per successful call (P50) — latência de percentil 50 para solicitações de HTTP bem-sucedidas. 50 por cento de todas as solicitações bem-sucedidas levaram menos do que esse tempo para serem concluídas.
Latency per successful call (P90) — latência de percentil 90 para solicitações de HTTP bem-sucedidas. 90 por cento de todas as solicitações bem-sucedidas levaram menos do que esse tempo para serem concluídas.
Latency per successful call (P95) — latência de percentil 95 para solicitações de HTTP bem-sucedidas. 95 por cento de todas as solicitações bem-sucedidas levaram menos do que esse tempo para serem concluídas.
Latency per successful call (P99) — latência de percentil 99 para solicitações de HTTP bem-sucedidas. 99 por cento de todas as solicitações bem-sucedidas levaram menos do que esse tempo para serem concluídas.
Extension Functions — informações sobre chamadas para funções de extensão:
Java UDF handler load time – quantidade de tempo para o manipulador da UDF de Java carregar.
Total de invocações do manipulador da UDF de Java — número de vezes que o manipulador da UDF de Java é invocado.
Max Java UDF handler execution time — quantidade de tempo máxima para que o manipulador da UDF de Java seja executado.
Avg Java UDF handler execution time — quantidade média de tempo para executar o manipulador da UDF de Java.
Java UDTF process() invocations — número de vezes que o método de processo da UDTF foi invocado.
Java UDTF process() execution time — quantidade de tempo para executar o processo da UDTF de Java.
Avg Java UDTF process() execution time — quantidade média de tempo para executar o processo da UDTF de Java.
Java UDTF’s constructor invocations — número de vezes que o construtor da UDTF foi invocado.
Java UDTF’s constructor execution time — quantidade de tempo para executar o construtor da UDTF de Java.
Avg Java UDTF’s constructor execution time — quantidade média de tempo para executar o construtor da UDTF de Java.
Java UDTF endPartition() invocations — número de vezes que o método endPartition da UDTF foi invocado.
Java UDTF endPartition() execution time — quantidade de tempo para executar o método endPartition da UDTF de Java.
Avg Java UDTF endPartition() execution time — quantidade média de tempo para executar o método endPartition da UDTF de Java.
Max Java UDF dependency download time — quantidade máxima de tempo para baixar as dependências da UDF de Java.
Max JVM memory usage — pico de uso de memória conforme relatado pelo JVM.
Java UDF inline code compile time in ms — tempo de compilação para o código inline da UDF de Java.
Python total UDF invocações do manipulador — número de vezes que o manipulador da UDF de Python foi invocado.
Total Python UDF handler execution time — tempo total de execução do manipulador da UDF de Python.
Avg Python UDF handler execution time — quantidade média de tempo para executar o manipulador da UDF de Python.
Python sandbox max memory usage — pico de uso de memória pelo ambiente sandbox do Python.
Avg Python env creation time: Download and install packages — quantidade média de tempo para criar o ambiente Python, incluindo download e instalação de pacotes.
Conda solver time — quantidade de tempo para executar o solucionador Conda para resolver pacotes Python.
Conda env creation time — quantidade de tempo para criar o ambiente Python.
Python UDF initialization time — quantidade de tempo para inicializar a UDF de Python.
Number of external file bytes read for UDFs — número de bytes de arquivos externos lidos para UDFs.
Number of external files accessed for UDFs — número de arquivos externos acessados para UDFs.
Se o valor de um campo, por exemplo “Retries due to transient errors”, for zero, então o campo não é exibido.
Nós mais caros¶
O painel lista todos os nós que duraram 1% ou mais do tempo total de execução da consulta (ou o tempo de execução da etapa de consulta exibida, se a consulta foi executada em várias etapas de processamento). O painel lista os nós por tempo de execução em ordem decrescente, permitindo aos usuários localizar rapidamente os nós mais custosos em termos de tempo de execução.
Atributos¶
As seções seguintes fornecem uma lista dos tipos de operadores mais comuns e seus atributos:
Operadores de geração e acesso a dados¶
- TableScan:
Representa o acesso a uma única tabela. Atributos:
Nome completo da tabela — o nome totalmente qualificado da tabela verificada
Table alias — usado, se presente
Columns — lista de colunas verificadas
Caminhos variantes extraídos — lista de caminhos extraídos das colunas VARIANT
Modo de verificação — ROW_BASED ou COLUMN_BASED (mostrado apenas para verificações de tabelas híbridas)
Predicados de acesso — condições da consulta que são aplicadas durante a verificação da tabela
- IndexScan:
Representa o acesso a índices secundários em tabelas híbridas Atributos:
Nome completo da tabela — o nome totalmente qualificado da tabela verificada que contém o índice
Colunas — lista de colunas de índice verificadas
Modo de verificação — ROW_BASED ou COLUMN_BASED
Predicados de acesso — condições da consulta que são aplicadas durante a verificação do índice
Nome completo do índice — o nome totalmente qualificado do índice verificado
- ValuesClause:
Lista de valores fornecidos com a cláusula VALUES. Atributos:
Number of values — o número de valores produzidos.
Values — a lista de valores produzidos.
- Gerador:
Gera registros usando o constructo
TABLE(GENERATOR(...)). Atributos:rowCount — parâmetro rowCount fornecido.
timeLimit — parâmetro timeLimit fornecido.
- ExternalScan:
Representa o acesso a dados armazenados em objetos de preparação. Pode ser uma parte das consultas que verificam dados diretamente dos estágios, mas também para operações de carregamento de dados (ou seja, instruções COPY).
Atributos:
Stage name — o nome do estágio de onde os dados são lidos.
Stage type — o tipo do estágio (por exemplo, TABLE STAGE).
- InternalObject:
Representa o acesso a um objeto de dados interno (por exemplo, uma tabela de Information Schema ou o resultado de uma consulta anterior). Atributos:
Object Name — o nome ou tipo do objeto acessado.
Operadores de processamento de dados¶
- Filter:
Representa uma operação que filtra os registros. Atributos:
Filter condition - a condição utilizada para realizar a filtragem.
- Join:
Combina duas entradas em uma determinada condição. Atributos:
Join Type — Tipo de junção (por exemplo, INNER, LEFT OUTER, etc.).
Equality Join Condition — para as junções que utilizam condições baseadas na igualdade, lista as expressões utilizadas para unir elementos.
Additional Join Condition — algumas condições de junção contêm predicados baseadas em desigualdade. Elas estão listadas aqui.
Nota
Predicados de junção de desigualdade podem resultar em velocidades de processamento significativamente mais lentas e devem ser evitados, se possível.
- Agregação:
Agrupa entradas e computa funções agregadas. Pode representar constructos SQL como GROUP BY, assim como SELECT DISTINCT. Atributos:
Grouping Keys — se GROUP BY for usado, lista as expressões pelas quais agrupamos.
Aggregate Functions — lista de funções computadas para cada grupo agregado, por exemplo SUM.
- GroupingSets:
Representa construtos como GROUPING SETS, ROLLUP e CUBE. Atributos:
Grouping Key Sets — lista de conjuntos de agrupamento
Aggregate Functions — lista de funções computadas para cada grupo, por exemplo SUM.
- WindowFunction:
Computa funções de janela. Atributos:
Window Functions — lista de funções de janela computadas.
- Sort:
Ordena a entrada em uma determinada expressão. Atributos:
Sort Keys — expressão que define a classificação.
- SortWithLimit:
Produz uma parte da sequência de entrada após a classificação, normalmente um resultado de um constructo
ORDER BY ... LIMIT ... OFFSET ...em SQL.Atributos:
Sort Keys — expressão que define a classificação.
Number of rows — número de linhas produzidas.
Offset — posição na sequência ordenada a partir da qual as tuplas produzidas são emitidas.
- Flatten:
Processa registros VARIANT, possivelmente nivelando-os em um caminho especificado. Atributos:
input — a expressão de entrada usada para nivelar os dados.
- JoinFilter:
Operação de filtragem especial que remove tuplas que podem ser identificadas como possivelmente não correspondendo à condição de um Join mais além no plano da consulta. Atributos:
Original join ID — a junção usada para identificar tuplas que podem ser filtradas.
- UnionAll:
Concatena duas entradas. Atributos: nenhum.
- ExternalFunction:
Representa o processamento por uma função externa.
Operadores DML¶
- Insert:
Adiciona registros a uma tabela através de uma operação INSERT ou COPY. Atributos:
Input expressions — quais expressões são inseridas.
Table names — nomes de tabelas que são adicionadas aos registros.
- Delete:
Remove registros de uma tabela. Atributos:
Table name — o nome da tabela da qual os registros são excluídos.
- Update:
Atualiza os registros em uma tabela. Atributos:
Table name — o nome da tabela atualizada.
- Merge:
Realiza uma operação MERGE em uma tabela. Atributos:
Full table name — o nome da tabela atualizada.
- Unload:
Representa uma operação COPY que exporta dados de uma tabela para um arquivo em um estágio. Atributos:
Location - o nome do estágio onde os dados são salvos.
Operadores de metadados¶
Algumas consultas incluem etapas que são puras operações de metadados/catálogos em vez de operações de processamento de dados. Estas etapas consistem em um único operador. Alguns exemplos incluem:
- Comandos DDL e de transação:
Usados para criar ou modificar objetos, sessões, transações, etc. Normalmente, estas consultas não são processadas por um warehouse virtual e resultam em um perfil de etapa única que corresponde à instrução SQL correspondente. Por exemplo:
CREATE DATABASE | SCHEMA | …
ALTER DATABASE | SCHEMA | TABLE | SESSION | …
DROP DATABASE | SCHEMA | TABLE | …
COMMIT
- Comando de criação de tabelas:
Comando DDL para a criação de uma tabela. Por exemplo:
CREATE TABLE
Similar a outros comandos DDL, estas consultas resultam em um perfil de etapa única; no entanto, também podem fazer parte de um perfil de múltiplas etapas, como quando usadas em uma instrução CTAS. Por exemplo:
CREATE TABLE … AS SELECT …
- Reutilização do resultado da consulta:
Uma consulta que reutiliza o resultado de uma consulta anterior.
- Resultado baseado em metadados:
Uma consulta cujo resultado é computado puramente com base em metadados, sem acessar nenhum dado. Estas consultas não são processadas por um warehouse virtual. Por exemplo:
SELECT COUNT(*) FROM …
SELECT CURRENT_DATABASE()
Operadores diversos¶
- Resultado:
Retorna o resultado da consulta. Atributos:
List of expressions - as expressões produzidas.
Problemas comuns de consulta identificados pelo perfil de consulta¶
Esta seção descreve alguns dos problemas que você pode identificar e solucionar usando o perfil de consulta.
“Explosão” de junções¶
Um dos erros comuns dos usuários de SQL é unir tabelas sem fornecer uma condição de junção (resultando em um “produto cartesiano”), ou fornecer uma condição em que os registros de uma tabela correspondem a vários registros de outra tabela. Para tais consultas, o operador Join produz significativamente (muitas vezes por ordem de magnitude) mais tuplas do que consome.
Isto pode ser observado verificando o número de registros produzidos por um operador Join, e normalmente também se reflete em um operador Join que consome muito tempo.
UNION sem ALL¶
Em SQL, é possível combinar dois conjuntos de dados com constructos UNION ou UNION ALL. A diferença entre eles é que UNION ALL simplesmente concatena as entradas, enquanto UNION faz o mesmo, mas também realiza a eliminação de duplicatas.
Um erro comum é usar UNION quando a semântica UNION ALL é suficiente. Estas consultas aparecem no perfil de consulta como um operador UnionAll com um operador extra Aggregate por cima (que realiza a eliminação de duplicatas).
Consultas grandes demais para caber na memória¶
Para algumas operações (por exemplo, eliminação de duplicatas para um conjunto de dados grande), a quantidade de memória disponível para os servidores usados para executar a operação pode não ser suficiente para armazenar resultados intermediários. Como resultado, o mecanismo de processamento de consultas começará a despejar os dados no disco local. Se o espaço em disco local não for suficiente, os dados despejados são salvos em discos remotos.
Este despejo pode ter um efeito profundo no desempenho da consulta (especialmente se for utilizado disco remoto para despejo). Para sanar isso, recomendamos:
Usar um warehouse maior (aumentando efetivamente a memória disponível/espaço em disco local para a operação), e/ou
Processar dados em lotes menores.
Remoção ineficiente¶
O Snowflake coleta estatísticas ricas em dados, permitindo não ler partes desnecessárias de uma tabela com base nos filtros de consulta. Entretanto, para que isso tenha efeito, a ordem do armazenamento de dados precisa ser correlacionada com os atributos do filtro de consulta.
A eficiência da remoção pode ser observada comparando as estatísticas de partições verificadas e partições totais nos operadores TableScan. Se a primeira for uma pequena fração da segunda, a remoção foi eficiente. Caso contrário, não teve efeito.
Naturalmente, a remoção só pode ajudar para consultas que realmente filtram uma quantidade significativa de dados. Se as estatísticas de remoção não mostram redução de dados, mas há um operador Filter acima de TableScan que filtra uma série de registros, isto pode sinalizar que uma organização de dados diferente pode ser benéfica para esta consulta.
Para obter mais informações sobre remoção, consulte Explicação das estruturas de tabela do Snowflake.