Model Serving no Snowpark Container Services¶
Nota
Este recurso está disponível nas regiões comerciais da AWS, do Azure e do Google Cloud. Ele não está disponível em regiões governamentais ou governamentais comerciais.
Nota
A capacidade de executar modelos no Snowpark Container Services (SPCS) descrita neste tópico está disponível no snowflake-ml-python versão 1.8.0 e posteriores.
O Snowflake Model Registry permite que você execute modelos em um warehouse (o padrão) ou em um pool de computação do Snowpark Container Services (SPCS) por meio do Model Serving. A execução de modelos em um warehouse impõe algumas limitações quanto ao tamanho e aos tipos de modelos que você pode usar (especificamente, modelos de tamanho pequeno a médio que utilizam apenas CPU e cujas dependências podem ser satisfeitas por pacotes disponíveis no canal conda do Snowflake).
A execução de modelos no Snowpark Container Services (SPCS) facilita essas restrições ou as elimina completamente. É possível usar qualquer pacote que desejar, incluindo aqueles do Python Package Index (PyPI) ou de outras fontes. Modelos Large podem ser executados em clusters distribuídos de GPUs. E você não precisa saber nada sobre tecnologias de contêiner, como Docker ou Kubernetes. O Snowflake Model Serving cuida de todos os detalhes.
Principais conceitos¶
Uma visão geral simplificada de alto nível da arquitetura de inferência do Snowflake Model Serving é mostrada abaixo.
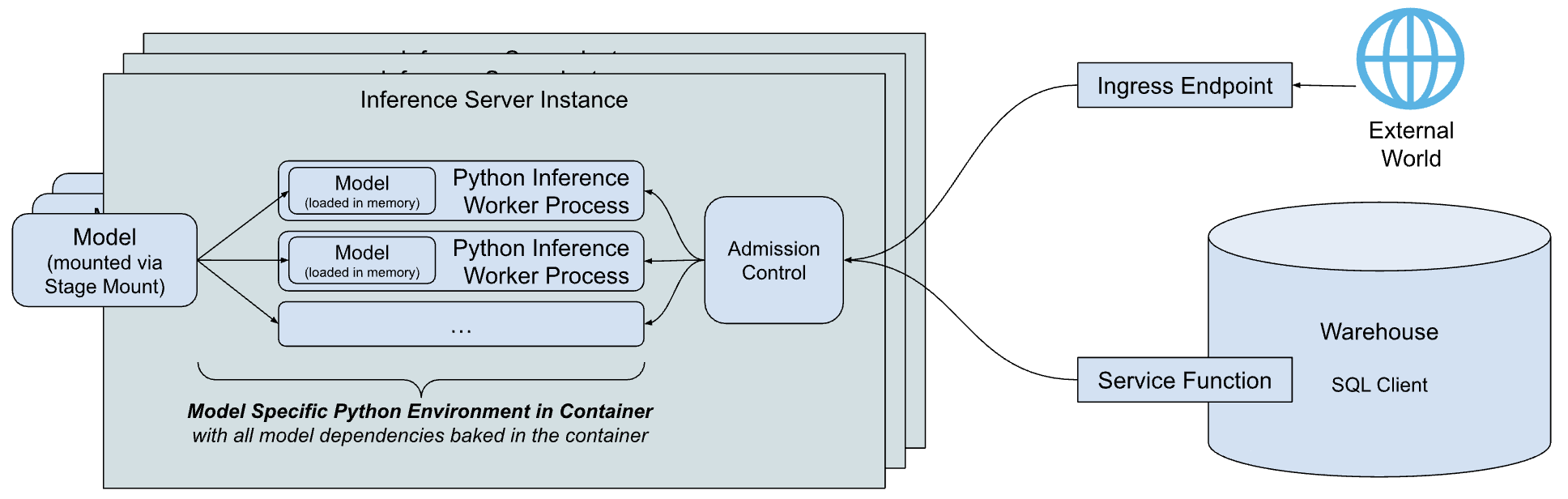
Os principais componentes da arquitetura são:
servidor de inferência: O servidor que executa o modelo e fornece previsões. O servidor de inferência pode usar vários processos de inferência para utilizar totalmente os recursos do nó. As solicitações ao modelo são despachadas pelo controle de admissão, que gerencia a fila de solicitação de entrada para evitar condições de falta de memória, rejeitando clientes quando o servidor está sobrecarregado. Hoje, a Snowflake fornece um servidor de inferência simples e flexível baseado em Python que pode executar inferência para todos os tipos de modelos. Com o tempo, a Snowflake planeja oferecer servidores de inferência otimizados para tipos de modelo específicos.
Ambiente Python específico do modelo: para reduzir a latência da inicialização de um modelo, que inclui o tempo necessário para baixar as dependências e carregar o modelo, o Snowflake cria um contêiner que encapsula as dependências do modelo específico.
Funções de serviço: Para se comunicar com o servidor de inferência a partir do código em execução em um warehouse, o Snowflake Model Serving cria funções que têm a mesma assinatura do modelo, mas que, em vez disso, chamam o servidor de inferência por meio do protocolo de função externa.
Ponto de extremidade de entrada: Para permitir que aplicativos fora do Snowflake chamem o modelo, o Snowflake Model Serving pode provisionar um ponto de extremidade HTTP opcional, acessível à Internet pública.
Como funciona?¶
O diagrama a seguir mostra como o Snowflake Model Serving implementa e veicula modelos em um warehouse ou no SPCS.
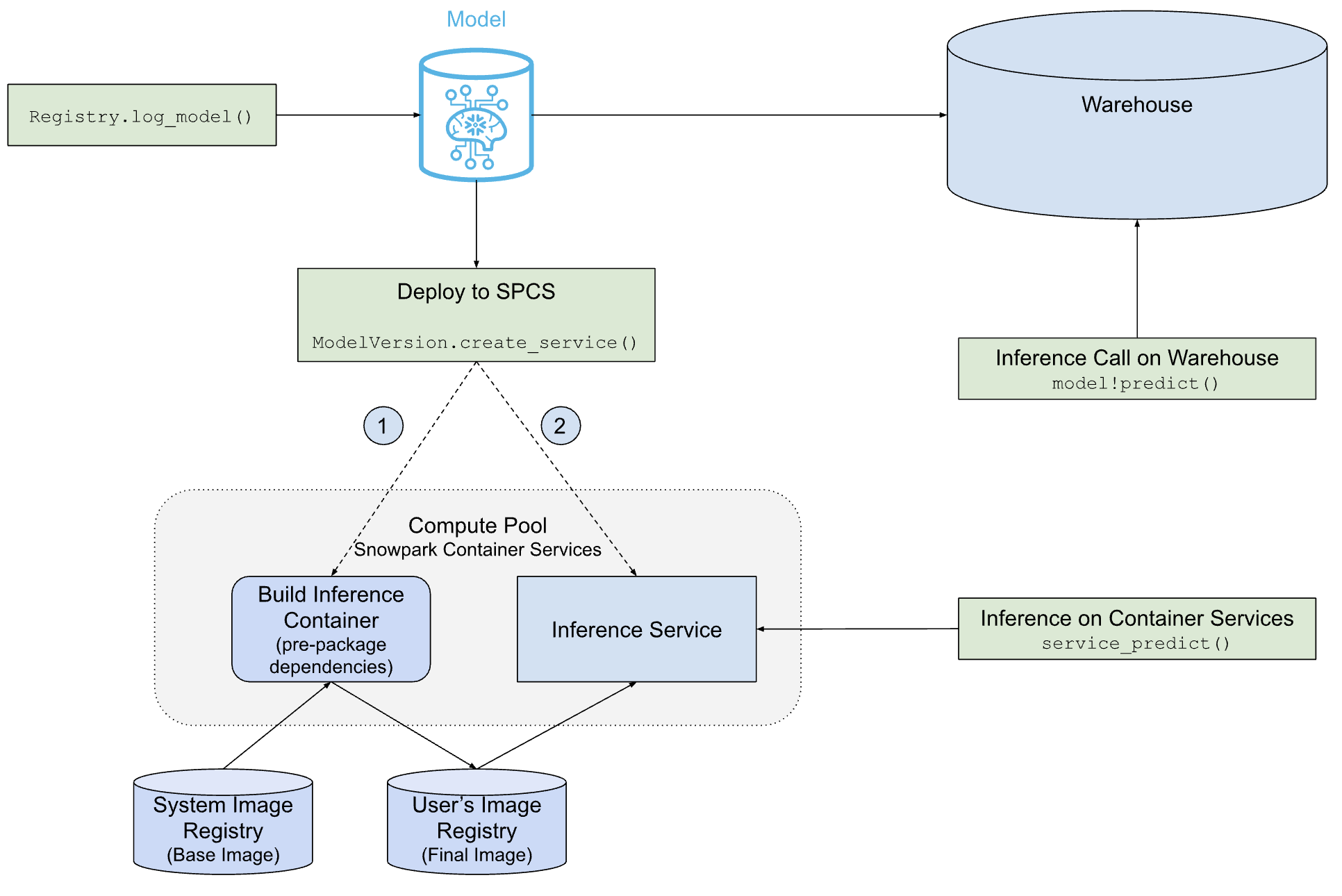
Como você pode ver, o caminho para a implementação do SPCS é mais complexo do que o caminho para a implementação do warehouse, mas o Snowflake Model Serving faz todo o trabalho para você, incluindo a criação da imagem do contêiner que contém o modelo e suas dependências, e a criação do servidor de inferência que executa o modelo.
Pré-requisitos¶
Antes de começar, certifique-se de ter o seguinte:
Uma conta Snowflake em qualquer região comercial da AWS, do Azure ou do Google Cloud. As regiões governamentais não são compatíveis.
Versão 1.6.4 ou posterior do pacote Python
snowflake-ml-python.Um modelo que você deseja executar no Snowpark Container Services.
Familiaridade com o Snowflake Model Registry.
Familiaridade com o Snowpark Container Services. Em particular, você deve entender sobre pools de computação, repositórios de imagens e privilégios relacionados.
Criação de um pool de computação¶
O Snowpark Container Services (SPCS) executa imagens de contêiner em pools de computação. Se você ainda não tiver um pool de computação adequado, crie um da seguinte forma:
CREATE COMPUTE POOL IF NOT EXISTS mypool
MIN_NODES = 2
MAX_NODES = 4
INSTANCE_FAMILY = 'CPU_X64_M'
AUTO_RESUME = TRUE;
Consulte a tabela de nomes de família para obter uma lista de famílias de instâncias válidas.
Certifique-se de que a função que executará o modelo seja a proprietário do pool de computação ou tenha o privilégio USAGE ou OPERATE no pool.
Privilégios obrigatórios¶
O Model Serving funciona com o Snowpark Container Services. Para usar o Model Serving, o usuário precisa dos seguintes privilégios:
USAGE ou OWNERSHIP em um pool de computação onde o serviço será executado.
Se for desejado um ponto de extremidade de entrada no Model Serving, o usuário deve ter o privilégio BIND SERVICE ENDPOINT na conta.
Proprietários ou usuários de modelos com o privilégio READ no modelo pode implantar o modelo no Serving. Para permitir que outra função acesse a inferência, os proprietários de serviço podem conceder a função de serviço
INFERENCE_SERVICE_FUNCTION_USAGEpara compartilhar funções de serviço e concederALL_ENDPOINTS_USAGEpara compartilhar pontos de extremidade de entrada.
Limitações¶
Aplicam-se as seguintes limitações ao Model Serving no Snowpark Container Services.
Somente o proprietário de um modelo ou funções com o privilégio READ no modelo pode implantá-lo no Snowpark Container Services.
A criação de imagem falha se demorar mais de uma hora.
Funções de tabela não são compatíveis. Modelos sem função de tabela não podem ser implantados no Snowpark Container Services no momento.
Implementação de um modelo para o SPCS¶
Registre em log uma nova versão do modelo (usando reg.log_model) ou obtenha uma referência a uma versão do modelo existente (reg.get_model(...).version(...)). Em qualquer situação, você acaba com uma referência a um objeto ModelVersion.
Dependências e elegibilidade do modelo¶
As dependências de um modelo determinam se ele pode ser executado em um warehouse, em um serviço SPCS ou em ambos. É possível, se necessário, especificar dependências intencionalmente para tornar um modelo inelegível para execução em um desses ambientes.
O canal conda do Snowflake está disponível apenas em warehouses e é a única fonte de dependências de warehouse. Por padrão, as dependências do conda para modelos SPCS obtêm suas dependências do conda-forge.
Quando você registra em log uma versão do modelo, as dependências do conda do modelo são validadas em relação ao canal conda do Snowflake. Se todas as dependências do conda do modelo estiverem disponíveis, o modelo será considerado elegível para ser executado em um warehouse. Ele também pode ser elegível para executar em um serviço SPCS se todas as dependências estiverem disponíveis no conda-forge, embora isso não seja verificado até que você crie um serviço.
Modelos registrados em log com dependências PyPI devem ser executados no SPCS. Especificar pelo menos uma dependência PyPI é uma maneira de tornar um modelo inelegível para execução em um warehouse. Se seu modelo tiver apenas dependências conda, especifique pelo menos uma com um canal explícito (mesmo conda-forge), conforme mostrado no exemplo a seguir.
# reg is a snowflake.ml.registry.Registry object
reg.log_model(
model_name="my_model",
version_name="v1",
model=model,
conda_dependencies=["conda-forge::scikit-learn"])
Para modelos implementados no SPCS, as dependências do conda, se houver, são instaladas primeiro e, em seguida, todas as dependências PyPI são instaladas no ambiente conda usando pip.
Criação de um serviço¶
Para criar um serviço SPCS e implementar o modelo nele, chame o método create_service da versão do modelo, conforme mostrado no exemplo a seguir.
# mv is a snowflake.ml.model.ModelVersion object
mv.create_service(service_name="myservice",
service_compute_pool="my_compute_pool",
ingress_enabled=True,
gpu_requests=None)
A seguir estão os argumentos necessários para create_service:
service_name: o nome do serviço a ser criado. Este nome deve ser único dentro da conta.service_compute_pool: o nome do pool de computação a ser usado para executar o modelo. O pool de computação já deve existir.ingress_enabled: se True, o serviço se torna acessível por meio de um ponto de extremidade HTTP. Para criar o ponto de extremidade, o usuário deve ter o privilégio BIND SERVICE ENDPOINT.gpu_requests: uma cadeia de caracteres que especifica o número de GPUs. Para um modelo que pode ser executado em CPU ou GPU, este argumento determina se o modelo será executado em CPU ou em GPUs. Se o modelo for de um tipo conhecido que só pode ser executado em CPU (por exemplo, modelos scikit-learn), a criação da imagem falhará se GPUs forem solicitadas.
Se você estiver implantando um novo modelo, pode levar até 5 minutos para criar o serviço para modelos baseados em CPU e 10 minutos para modelos baseados em GPU. Se o pool de computação estiver ocioso ou exigir redimensionamento, poderá demorar mais para criar o serviço.
Este exemplo mostra apenas os argumentos necessários e mais comumente usados. Consulte a referência da API ModelVersion para ver a lista completa de argumentos.
Configuração de serviço padrão¶
O servidor de inferência usa padrões fáceis de usar que funcionam para a maioria dos casos de uso. Essas configurações são:
Número de threads de trabalho: para um modelo alimentado por CPU, o servidor usa o dobro do número de CPUs de processos de trabalho mais um. Modelos alimentados por GPU usam um processo de trabalho. Você pode substituir isso usando o argumento
num_workersna chamadacreate_service.Segurança do thread: alguns modelos não são thread-safe. Portanto, o serviço carrega uma cópia separada do modelo para cada processo de trabalho. Isso pode resultar no esgotamento de recurso para modelos grandes.
Utilização do nó: por padrão, uma instância do servidor de inferência solicita o nó inteiro, solicitando todo o CPU e a memória do nó em que é executado. Para personalizar a alocação de recursos por instância, use argumentos como
cpu_requests,memory_requestsegpu_requests.Ponto de extremidade: o ponto de extremidade de inferência é denominado
inferênciae usa a porta 5000. Eles não podem ser personalizados.
Comportamento de criação de imagem de contêiner¶
Por padrão, o Snowflake Model Serving cria a imagem do contêiner usando o mesmo pool de computação que será usado para executar o modelo. Este pool de computação de inferência provavelmente é muito poderoso para esta tarefa (por exemplo, GPUs não são usadas na criação de imagens de contêiner). Na maioria dos casos, isso não terá um impacto significativo nos custos de computação, mas se for uma preocupação, você pode escolher um pool de computação menos potente para criar imagens especificando o argumento image_build_compute_pool.
é uma função idempotente create_service. Chamá-la várias vezes não aciona a criação da imagem a cada vez. No entanto, as imagens de contêiner podem ser reconstruídas com base em atualizações no serviço de inferência, incluindo correções de vulnerabilidades em pacotes dependentes. Quando isso acontece, create_service aciona automaticamente a reconstrução da imagem
Nota
Os modelos desenvolvidos usando classes de modelagem do Snowpark ML não podem ser implantados em ambientes que tenham um GPU. Como solução alternativa, você pode extrair o modelo nativo e implementá-lo. Por exemplo:
# Train a model using Snowpark ML from snowflake.ml.modeling.xgboost import XGBRegressor regressor = XGBRegressor(...) regressor.fit(training_df) # Extract the native model xgb_model = regressor.to_xgboost() # Test the model with pandas dataframe pandas_test_df = test_df.select(['FEATURE1', 'FEATURE2', ...]).to_pandas() xgb_model.predict(pandas_test_df) # Log the model in Snowflake Model Registry mv = reg.log_model(xgb_model, model_name="my_native_xgb_model", sample_input_data=pandas_test_df, comment = 'A native XGB model trained from Snowflake Modeling API', ) # Now we should be able to deploy to a GPU compute pool on SPCS mv.create_service( service_name="my_service_gpu", service_compute_pool="my_gpu_pool", image_repo="my_repo", max_instances=1, gpu_requests="1", )
Interface de usuário¶
Você pode gerenciar os modelos implantados na Model Registry Snowsight UI. Para obter mais informações, consulte Serviços de inferência de modelos.
Como usar um modelo implementado em SPCS¶
É possível chamar os métodos de um modelo usando SQL, Python ou um ponto de extremidade HTTP.
SQL¶
O Snowflake Model Serving cria funções de serviço ao implementar um modelo no SPCS. Essas funções servem como uma ponte de SQL para o modelo em execução no pool de computação do SPCS. Uma função de serviço é criada para cada método do modelo, e elas são nomeadas como service_name!method_name. Por exemplo, se o modelo tiver dois métodos nomeados PREDICT e EXPLAIN e estiver sendo implementado em um serviço nomeado MY_SERVICE, as funções de serviço resultantes serão MY_SERVICE!PREDICT e MY_SERVICE!EXPLAIN.
Nota
As funções de serviço estão contidas no serviço. Por esse motivo, elas têm apenas um único ponto de controle de acesso, o serviço. Você não pode ter diferentes privilégios de controle de acesso para diferentes funções em um único serviço.
A chamada das funções de serviço de modelo em SQL é feita usando um código como o seguinte:
-- See signature of the inference function in SQL.
SHOW FUNCTIONS IN SERVICE MY_SERVICE;
-- Call the inference function in SQL following the same signature (from `arguments` column of the above query)
SELECT MY_SERVICE!PREDICT(feature1, feature2, ...) FROM input_data_table;
Python¶
Chame os métodos de um serviço usando o método run de um objeto de versão do modelo, incluindo o argumento service_name para especificar o serviço onde o método será executado. Por exemplo:
# Get signature of the inference function in Python
# mv: snowflake.ml.model.ModelVersion
mv.show_functions()
# Call the function in Python
service_prediction = mv.run(
test_df,
function_name="predict",
service_name="my_service")
Se você não incluir o argumento service_name, o modelo será executado em um warehouse.
Pontos de extremidade HTTP¶
Cada serviço vem com o respectivo nome DNS interno. A implantação de um serviço com ingress_enabled também cria um ponto de extremidade HTTP público disponível fora do Snowflake. Qualquer um dos pontos de extremidade pode ser usado para chamar um serviço.
Nomes de pontos de extremidade¶
Você encontra o ponto de extremidade HTTP público de um serviço com entrada habilitada usando o comando SHOW ENDPOINTS ou o método list_services() de um objeto de versão de modelo.
# mv: snowflake.ml.model.ModelVersion
mv.list_services()
A saída de ambos contém uma coluna ingress_url, que tem uma entrada do formato unique-service-id-account-id.snowflakecomputing.app. Trata-se do ponto de extremidade HTTP em disponibilidade pública para o seu serviço. As limitações de nome DNS a serem aplicadas. Em um URL, sublinhados (_) no nome do método são substituídos por traços (-) no URL. Por exemplo, o nome do serviço predict_probability é alterado para predict-probability no URL.
Para obter o nome DNS interno no Snowflake, use o comando DESCRIBE SERVICE. A coluna de saída dns_name desse comando contém o nome DNS interno do serviço. Para encontrar a porta do seu serviço, use o comando SHOW ENDPOINTS IN SERVICE. A coluna port ou port_range contém a porta usada por um serviço. É possível fazer chamadas internas para seu serviço usando URL https://dns_name:port/<method_name>.
Corpo da solicitação¶
Todas as solicitações de inferência devem usar o método POST HTTP com um cabeçalho Content-Type: application/json, e o corpo da mensagem segue o formato de dados descrito em Formatos de dados de entrada e saída de serviços remotos.
A primeira coluna da entrada é um número INTEGER que representa o número da linha no lote, e as colunas restantes devem corresponder à assinatura do seu serviço. O corpo da solicitação a seguir é um exemplo de modelo com a assinatura predict(INTEGER, VARCHAR, TIMESTAMP):
{
"data": [
[0, 10, "Alex", "2014-01-01 16:00:00"],
[1, 20, "Steve", "2015-01-01 16:00:00"],
[2, 30, "Alice", "2016-01-01 16:00:00"],
[3, 40, "Adrian", "2017-01-01 16:00:00"]
]
}
Chamada de serviço¶
Os usuários podem chamar um serviço usando o ponto de extremidade público programaticamente das seguintes maneiras:
Com um token de acesso programático (Programmatic Access Token, PAT), autenticação baseada em um token que você gerou no Snowflake. Para obter informações sobre como configurar um PAT para usar com os serviços do Snowflake, consulte Uso de tokens de acesso programático para autenticação. Para usar um PAT ao chamar um serviço, inclua o token no cabeçalho
Authorizationda solicitação:Authorization: Snowflake Token="<your_token>"
Por exemplo, com um PAT armazenado na variável de ambiente
SNOWFLAKE_SERVICE_PATe a assinatura da funçãopredict(INTEGER, VARCHAR, TIMESTAMP)usada nos exemplos anteriores, você pode fazer uma solicitação para o ponto de extremidaderandom-id.myaccount.snowflakecomputing.app/predictcom o seguinte comandocurl:curl \ -X POST \ -H "Content-Type: application/json" \ -H "Authorization: Snowflake Token=\"$SNOWFLAKE_SERVICE_PAT\"" \ -d '{ "data": [ [0, 10, "Alex", "2014-01-01 16:00:00"], [1, 20, "Steve", "2015-01-01 16:00:00"], [2, 30, "Alice", "2016-01-01 16:00:00"], [3, 40, "Adrian", "2017-01-01 16:00:00"] ] }' \ random-id.myaccount.snowflakecomputing.app/predict/predict
Com um JSON Web Token (JWT), gerado após autenticação do par de chaves. Seu aplicativo autentica as solicitações para o ponto de extremidade público gerando um JWT do seu par de chaves, trocando-o com o Snowflake por um token OAuth e, depois disso, esse token OAuth é usado para autenticação direta com o ponto de extremidade público.
Para conferir um exemplo de uso do JWT para autenticação com um ponto de extremidade público, consulte Tutorial do Snowpark Container Services – Acesse o ponto de extremidade público programaticamente.
Para obter mais informações sobre autenticação de par de chaves no Snowflake, consulte Autenticação de pares de chaves e rotação de pares de chaves.
Nota
Não há efeitos colaterais ao chamar o serviço por HTTP. Todas as falhas de autorização, como um token incorreto ou a falta de rota de rede para o serviço, resultam no erro 404. O serviço pode retornar os erros 400 ou 429 quando o corpo da solicitação é inválido ou o serviço está ocupado.
Consulte Como implementar um transformador de frases Hugging Face para inferência com base em GPU para um exemplo de uso de um ponto de extremidade HTTP do servidor modelo.
Considerações sobre latência¶
Você pode usar as seguintes opções para executar a inferência enquanto hospeda um modelo no Snowpark Container Services. Elas têm vantagens e desvantagens distintas com relação à expectativa de latência e aos casos de uso.
Pontos de extremidade HTTP
Os pontos de extremidade HTTP são melhores para inferência online ou em tempo real e oferecem a menor latência dentre as suas opções. O tráfego não passa por um warehouse ou por serviços globais do Snowflake, e os dados de entrada são enviados diretamente para o servidor após a autenticação.
SQL
Os comandos SQL são melhores para inferência em lote. Os dados de entrada são enviados de um warehouse para o servidor, sendo que o warehouse compila e executa a consulta. Os dados de resposta são gravados em um cache no warehouse antes de serem devolvidos ao servidor. Transferências, compilação e execução do warehouse incorrem em latência. A latência de execução é sempre menor quando um resultado em cache é usado.
APIs Snowpark Python
As APIs Python contam com os comandos SQL executados no Snowflake e são ideais para as mesmas finalidades que o SQL direto. No entanto, a latência é afetada pelo tipo de
DataFrameusado como entrada. Os DataFrames Snowpark usam dados já disponíveis no Snowflake e podem operar da mesma maneira que o SQL direto. Os DataFrames pandas carregam os dados na memória para uma tabela do Snowflake temporária, o que incorre em latência de transferência.Para a menor latência ao usar as APIs Python, prepare os DataFrames pandas como DataFrames Snowpark antes de hospedar seu modelo.
Nota
As avaliações de desempenho que você realiza localmente usando um DataFrame pandas apresentarão um desempenho diferente com o mesmo DataFrame pandas que está em execução no Snowpark Container Services, devido à latência da criação de tabela temporária. Para uma avaliação de desempenho precisa do seu modelo, use um DataFrame Snowpark como entrada.
Gerenciamento de serviços¶
O Snowpark Container Services oferece uma interface SQL para gerenciamento de serviços. É possível usar os comandos DESCRIBE SERVICE e ALTER SERVICE com serviços SPCS criados pelo Snowflake Model Serving da mesma forma que faria para gerenciar qualquer outro serviço SPCS. Por exemplo, você pode:
Alteração de MIN_INSTANCES e outras propriedades de um serviço
Descarte (exclusão) de um serviço
Compartilhamento de um serviço com outra conta
Alteração da propriedade de um serviço (o novo proprietário deve ter acesso READ ao modelo)
Nota
Se o proprietário de um serviço perder o acesso ao modelo subjacente por qualquer motivo, o serviço deixará de funcionar após a reinicialização. Ele continuará funcionando até ser reiniciado.
Para garantir a reprodutibilidade e depurabilidade, você não pode alterar a especificação de um serviço de inferência existente. No entanto, você pode copiar a especificação, personalizá-la e usá-la para criar seu próprio serviço para hospedar o modelo. No entanto, esse método não protege o modelo subjacente de ser excluído. Além disso, ele não rastreia a linhagem. É melhor permitir que o Snowflake Model Serving crie serviços.
Dimensionamento de serviços¶
A partir do snowflake-ml-python 1.25.0, você pode definir os limites de dimensionamento para seu serviço de inferência definindo min_instances e max_instances no método create_service.
Como funciona o dimensionamento automático¶
O serviço é inicializado com o número de nós especificado em min_instances e é dinamicamente dimensionado dentro do intervalo definido com base no volume de tráfego em tempo real e na utilização de hardware.
Dimensionamento como zero (suspensão automática): se min_instances estiver definido como 0 (padrão), o serviço será suspenso automaticamente se nenhum tráfego for detectado por 30 minutos.
Latência de dimensionamento: os acionadores de dimensionamento normalmente são ativados após um minuto de cumprimento da condição necessária. Observe que o tempo total de ativação inclui esse período do acionador mais o tempo necessário para provisionar e inicializar novas instâncias de serviço.
Práticas recomendadas: a Snowflake recomenda a seguinte estratégia de configuração:
min_instances: defina esse valor como um que atenda aos seus requisitos de desempenho de linha de base para cargas de trabalho típicas. Isso garante a disponibilidade imediata e evita atrasos na inicialização a frio.max_instances: defina esse valor para acomodar suas demandas de pico de carga de trabalho, mantendo um limite máximo no consumo de recursos.
Suspensão de serviços¶
A configuração padrão min_instances=0 permite que o serviço seja suspenso automaticamente após 30 minutos de inatividade. As solicitações recebidas acionarão uma retomada, com o atraso total determinado pela disponibilidade do pool de computação e pelo tempo de carregamento do modelo (atraso na inicialização).
Para suspender ou retomar manualmente um serviço, use o comando ALTER SERVICE.
ALTER SERVICE my_service [ SUSPEND | RESUME ];
Exclusão de modelos¶
É possível gerenciar modelos e versões de modelo normalmente com a interface SQL ou a API Python, com a restrição de que um modelo ou versão de modelo que esteja sendo usado por um serviço (esteja em execução ou suspenso) não pode ser descartado (excluído). Para descartar um modelo ou versão de modelo, descarte o serviço primeiro.
Exemplos¶
Esses exemplos pressupõem que você já criou um pool de computação, um repositório de imagens e concedeu privilégios conforme necessário. Consulte Pré-requisitos para obter mais detalhes.
Como implementar um modelo XGBoost para inferência com base em CPU¶
O código a seguir ilustra as principais etapas na implantação de um modelo XGBoost odelo para inferência em SPCS, depois usando o modelo implementado para inferência. Um notebook para este exemplo está disponível.
from snowflake.ml.registry import registry
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session
from xgboost import XGBRegressor
# your model training code here output of which is a trained xgb_model
# Open model registry
reg = registry.Registry(session=session, database_name='my_registry_db', schema_name='my_registry_schema')
# Log the model in Snowflake Model Registry
model_ref = reg.log_model(
model_name="my_xgb_forecasting_model",
version_name="v1",
model=xgb_model,
conda_dependencies=["scikit-learn","xgboost"],
sample_input_data=pandas_test_df,
comment="XGBoost model for forecasting customer demand"
)
# Deploy the model to SPCS
model_ref.create_service(
service_name="forecast_model_service",
service_compute_pool="my_cpu_pool",
ingress_enabled=True)
# See all services running a model
model_ref.list_services()
# Run on SPCS
model_ref.run(pandas_test_df, function_name="predict", service_name="forecast_model_service")
# Delete the service
model_ref.delete_service("forecast_model_service")
Como esse modelo tem a entrada habilitada, é possível chamar o ponto de extremidade HTTP público dele. O exemplo a seguir usa um PAT armazenado na variável de ambiente PAT_TOKEN para autenticação com um ponto de extremidade público do Snowflake:
import os
import json
import numpy as np
from pprint import pprint
import requests
def get_headers(pat_token):
headers = {'Authorization': f'Snowflake Token="{pat_token}"'}
return headers
headers = get_headers(os.getenv("PAT_TOKEN"))
# Put the endpoint url with method name `predict`
# The endpoint url can be found with `show endpoints in service <service_name>`.
URL = 'https://<random_str>-<organization>-<account>.snowflakecomputing.app/predict'
# Prepare data to be sent
data = {"data": np.column_stack([range(pandas_test_df.shape[0]), pandas_test_df.values]).tolist()}
# Send over HTTP
def send_request(data: dict):
output = requests.post(URL, json=data, headers=headers)
assert (output.status_code == 200), f"Failed to get response from the service. Status code: {output.status_code}"
return output.content
# Test
results = send_request(data=data)
print(json.loads(results))
Como implementar um transformador de frases Hugging Face para inferência com base em GPU¶
O código a seguir treina e implementa um transformador de frase Hugging Face, incluindo um ponto de extremidade HTTP.
Esse exemplo requer o pacote sentence-transformers, um pool de computação de GPU e um repositório de imagens.
from snowflake.ml.registry import registry
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session
from sentence_transformers import SentenceTransformer
session = Session.builder.configs(SnowflakeLoginOptions("connection_name")).create()
reg = registry.Registry(session=session, database_name='my_registry_db', schema_name='my_registry_schema')
# Take an example sentence transformer from HF
embed_model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Have some sample input data
input_data = [
"This is the first sentence.",
"Here's another sentence for testing.",
"The quick brown fox jumps over the lazy dog.",
"I love coding and programming.",
"Machine learning is an exciting field.",
"Python is a popular programming language.",
"I enjoy working with data.",
"Deep learning models are powerful.",
"Natural language processing is fascinating.",
"I want to improve my NLP skills.",
]
# Log the model with pip dependencies
pip_model = reg.log_model(
embed_model,
model_name="sentence_transformer_minilm",
version_name="pip",
sample_input_data=input_data, # Needed for determining signature of the model
pip_requirements=["sentence-transformers", "torch", "transformers"], # If you want to run this model in the Warehouse, you can use conda_dependencies instead
)
# Force Snowflake to not try to check warehouse
conda_forge_model = reg.log_model(
embed_model,
model_name="sentence_transformer_minilm",
version_name="conda_forge_force",
sample_input_data=input_data,
# setting any package from conda-forge is sufficient to know that it can't be run in warehouse
conda_dependencies=["sentence-transformers", "conda-forge::pytorch", "transformers"]
)
# Deploy the model to SPCS
pip_model.create_service(
service_name="my_minilm_service",
service_compute_pool="my_gpu_pool", # Using GPU_NV_S - smallest GPU node that can run the model
ingress_enabled=True,
gpu_requests="1", # Model fits in GPU memory; only needed for GPU pool
max_instances=4, # 4 instances were able to run 10M inferences from an XS warehouse
)
# See all services running a model
pip_model.list_services()
# Run on SPCS
pip_model.run(input_data, function_name="encode", service_name="my_minilm_service")
# Delete the service
pip_model.delete_service("my_minilm_service")
Em SQL, você pode chamar a função de serviço da seguinte forma:
SELECT my_minilm_service!encode('This is a test sentence.');
Você também pode chamar seu ponto de extremidade HTTP da seguinte forma.
import json
from pprint import pprint
import requests
# Put the endpoint url with method name `encode`
URL='https://<random_str>-<account>.snowflakecomputing.app/encode'
# Prepare data to be sent
data = {
'data': []
}
for idx, x in enumerate(input_data):
data['data'].append([idx, x])
# Send over HTTP
def send_request(data: dict):
output = requests.post(URL, json=data, headers=headers)
assert (output.status_code == 200), f"Failed to get response from the service. Status code: {output.status_code}"
return output.content
# Test
results = send_request(data=data)
pprint(json.loads(results))
Como implementar um modelo PyTorch para inferência com base em GPU¶
Consulte este guia de início rápido para um exemplo de treinamento e implementação de um modelo de recomendação de aprendizado profundo PyTorch (DLRM) no SPCS para inferência com GPU.
Práticas recomendadas¶
- Compartilhamento do repositório de imagens
É comum que vários usuários ou funções utilizem o mesmo modelo. Usar um único repositório de imagens permite que a imagem seja criada uma vez e reutilizada por todos os usuários, economizando tempo e despesas. Todas as funções que usarão o repositório precisam dos privilégios SERVICE READ, SERVICE WRITE, READ e WRITE no repositório. Como a imagem pode precisar ser reconstruída para atualizar dependências, você deve manter os privilégios de gravação; não os revogue depois que a imagem for construída inicialmente.
- Escolha do tipo de nó e número de instâncias
Use o menor nó de GPU em que o modelo se encaixa na memória. Escale aumentando o número de instâncias, em vez de aumentar
num_workersem um nó de GPU maior. Por exemplo, se o modelo se encaixar no tipo de instância GPU_NV_S (GPU_NV_SM no Azure), usegpu_requests=1e aumente a escala aumentandomax_instances, em vez de usar uma combinação degpu_requestsenum_workersem uma instância maior de GPU.- Escolhendo o tamanho do warehouse
Quanto maior for o warehouse, mais solicitações paralelas serão enviadas aos servidores de inferência. A inferência é uma operação cara, então use um warehouse menor sempre que possível. Usar um tamanho de warehouse maior que médio não acelera o desempenho da consulta e gera custo adicionais.
Solução de problemas¶
Monitoramento das implementações SPCS¶
É possível monitorar a implementação inspecionando os serviços que estão sendo iniciados usando a seguinte consulta SQL.
SHOW SERVICES IN COMPUTE POOL my_compute_pool;
Dois trabalhos são lançados:
MODEL_BUILD_xxxxx: Os caracteres finais do nome são randomizados para evitar conflitos de nomes. Este trabalho cria a imagem e termina depois que ela é criada. Se uma imagem já existir, o trabalho será ignorado.
Os logs são úteis para a depuração de problemas, como conflitos nas dependências de pacotes. Para ver os logs deste trabalho, execute o SQL abaixo, certificando-se de usar os mesmos caracteres finais:
CALL SYSTEM$GET_SERVICE_LOGS('MODEL_BUILD_xxxxx', 0, 'model-build');MYSERVICE: O nome do serviço conforme especificado na chamada para
create_service. Este trabalho é iniciado se o trabalho de MODEL_BUILD for bem-sucedido ou ignorado. Para ver os logs deste trabalho, execute o SQL abaixo:CALL SYSTEM$GET_SERVICE_LOGS('MYSERVICE', 0, 'model-inference');Se os logs não estiverem disponíveis no
SYSTEM$GET_SERVICE_LOGporque o trabalho ou serviço de criação foi excluído, você pode verificar a tabela de eventos (se ativada) para ver os logs:SELECT RESOURCE_ATTRIBUTES, VALUE FROM <EVENT_TABLE_NAME> WHERE true AND timestamp > dateadd(day, -1, current_timestamp()) -- choose appropriate timestamp range AND RESOURCE_ATTRIBUTES:"snow.database.name" = '<db of the service>' AND RESOURCE_ATTRIBUTES:"snow.schema.name" = '<schema of the service>' AND RESOURCE_ATTRIBUTES:"snow.service.name" = '<Job or Service name>' AND RESOURCE_ATTRIBUTES:"snow.service.container.instance" = '0' -- choose all instances or one particular AND RESOURCE_ATTRIBUTES:"snow.service.container.name" != 'snowflake-ingress' --skip logs from internal sidecar ORDER BY timestamp ASC;
Conflitos de pacotes¶
Dois sistemas determinam os pacotes instalados no contêiner de serviço: o próprio modelo e o servidor de inferência. Para minimizar os conflitos com as dependências do seu modelo, o servidor de inferência requer apenas os seguintes pacotes:
gunicorn<24.0.0
starlette<1.0.0
uvicorn-standard<1.0.0
Certifique-se de que as dependências do modelo, juntamente com as dependências acima, possam ser resolvidas por pip ou conda, independentemente da que você escolher.
Se um modelo tiver conda_dependencies e pip_requirements definidos, eles serão instalados da seguinte forma via conda:
Canais:
conda-forge
nodefaults
Dependências:
all_conda_packages
- pip:
all_pip_packages
O Snowflake obtém os pacotes Anaconda do conda-forge ao criar imagens de contêineres porque o canal conda do Snowflake está disponível apenas em warehouses, e o canal defaults exige que os usuários aceitem os termos de uso do Anaconda, o que não é possível durante uma criação automatizada. Para obter pacotes de um canal diferente, como defaults, especifique cada pacote com o nome do canal, como em defaults::pkg_name.
Nota
Se você especificar conda_dependencies e pip_requirements, a imagem do contêiner será criada com sucesso, mesmo que os dois conjuntos de dependências não sejam compatíveis, o que pode fazer com que a imagem do contêiner resultante não funcione como o esperado. O Snowflake recomenda usar apenas conda_dependencies ou apenas pip_requirements, não ambos.
Serviço sem memória¶
Alguns modelos não são seguros para threads, então o Snowflake carrega uma cópia separada do modelo na memória para cada processo de trabalho. Isso pode causar condições de falta de memória para modelos grandes com um número maior de trabalhadores. Tente reduzir num_workers.
Desempenho de consulta insatisfatório¶
Normalmente, a inferência é limitada pelo número de instâncias no serviço de inferência. Tente passar um valor mais alto para max_instances ao implantar o modelo.
Não é possível alterar a especificação do serviço¶
As especificações da compilação de modelo e serviços de inferência não podem ser alteradas usando ALTER SERVICE. Somente é possível alterar atributos como TAG, MIN_INSTANCES e assim por diante. No entanto, como a imagem é publicada no repositório de imagens, você pode copiar a especificação, modificá-la e criar um novo serviço a partir dela, que pode ser iniciado manualmente.
Pacote não encontrado¶
A implementação do modelo falhou durante a fase de criação da imagem. Os logs model-build sugerem que um pacote solicitado não foi encontrado. (Essa etapa usa conda-forge por padrão se o pacote for mencionado em conda_dependencies)
A instalação do pacote pode falhar por qualquer um dos seguintes motivos:
O nome ou a versão do pacote é inválido. Verifique a ortografia e a versão do pacote.
A versão solicitada do pacote não existe em
conda-forge. Você pode tentar remover a especificação da versão para obter a versão mais recente disponível emconda-forgeou usarpip_requirements. Você pode consultar todos os pacotes disponíveis aqui.Às vezes, você pode precisar de um pacote de um canal especial (por exemplo,
pytorch). Adicione um prefixochannel_name::à dependência, comopytorch::torch.
Incompatibilidade de versão do Huggingface Hub¶
Um serviço de inferência de modelo Hugging Face pode falhar com a mensagem de erro:
ImportError: huggingface-hub>=0.30.0,<1.0 is required for a normal functioning of this module, but found huggingface-hub==0.25.2
Isso ocorre porque o pacote transformers não especifica as dependências corretas do huggingface-hub, mas as verifica no código. Para resolver esse problema, registre o modelo novamente, dessa vez especificando explicitamente a versão necessária do huggingface-hub em conda_dependencies ou pip_requirements.
Torch não compilado com CUDA ativado¶
A causa típica desse erro é que você especificou conda_dependencies e pip_requirements. Conforme mencionado na seção Conflitos de pacotes, o conda é o gerenciador de pacotes usado para criar a imagem do contêiner. O Anaconda não resolve os pacotes de conda_dependencies e pip_requirements juntos e dá precedência aos pacotes do conda. Isso pode levar a uma situação em que os pacotes conda não são compatíveis com os pacotes pip. Você pode ter especificado torch no pip_requirements, e não no conda_dependencies. Considere a possibilidade de consolidar as dependências em conda_dependencies ou pip_requirements. Se isso não for possível, prefira especificar os pacotes mais importantes em conda_dependencies.
Uso de um repositório de imagens personalizado para imagens de inferência¶
Quando você implementa um modelo no Snowpark Container Services, o Snowflake Model Serving cria uma imagem de contêiner contendo o modelo e suas dependências. Para armazenar esta imagem, você precisa de um repositório de imagens. O Snowflake fornece um repositório de imagens padrão, que é usado automaticamente se você não especificar um repositório ao criar o serviço. Para usar um repositório diferente, passe seu nome no argumento:code:image_repo do método create_service.
Para usar um repositório de imagens que você não possui, certifique-se de que a função que criará a imagem do contêiner tenha os privilégios READ, WRITE, SERVICE READe SERVICE WRITE no repositório. Conceda esses privilégios da seguinte forma:
GRANT READ ON IMAGE REPOSITORY my_inference_images TO ROLE myrole;
GRANT WRITE ON IMAGE REPOSITORY my_inference_images TO ROLE myrole;
GRANT SERVICE READ ON IMAGE REPOSITORY my_inference_images TO ROLE myrole;
GRANT SERVICE WRITE ON IMAGE REPOSITORY my_inference_images TO ROLE myrole;