Notebooks on Container Runtime¶
Visão geral¶
You can run Snowflake Notebooks on Container Runtime. Container Runtime is powered by Snowpark Container Services, giving you a flexible container infrastructure that supports building and operationalizing a wide variety of workflows entirely within Snowflake. Container Runtime provides software and hardware options to support advanced data science and machine learning workloads. Compared to virtual warehouses, Container Runtime provides a more flexible compute environment where you can install packages from multiple sources and select compute resources, including GPU machine types, while still running SQL queries on warehouses for optimal performance.
This document describes some considerations for using notebooks on Snowflake Container Runtime. You can also try the Getting Started with Snowflake Notebook Container Runtime quickstart to learn more about using the Container Runtime in your development.
Pré-requisitos¶
Before you start using Snowflake Notebooks on Container Runtime, the ACCOUNTADMIN role must complete the notebook setup steps for creating the necessary resources and granting privileges to those resources. For detailed steps, see Configuração do administrador.
Create a notebook on Container Runtime¶
When you create a notebook on Container Runtime, you choose a warehouse, runtime, and compute pool to provide the resources to run your notebook. The runtime you choose gives you access to different Python packages based on your use case. Different warehouse sizes or compute pools have different cost and performance implications. All of these settings can be changed later if needed.
Nota
Um usuário com as funções ACCOUNTADMIN, ORGADMIN ou SECURITYADMIN não pode criar ou possuir diretamente um notebook no Container Runtime. Os Notebooks criados ou de propriedade direta dessas funções não serão executados. No entanto, se um notebook for de propriedade de uma função da qual as funções ACCOUNTADMIN, ORGADMIN ou SECURITYADMIN herdam privilégios, como a função PUBLIC, você poderá usar essas funções para executar esse notebook.
Para criar um Snowflake Notebook para execução no Container Runtime, siga estas etapas:
Faça login na Snowsight.
No menu de navegação, selecione Projects » Notebooks.
Selecione + Notebook.
Insira um nome para seu notebook.
Selecione um banco de dados e um esquema para armazenar seu notebook. Este parâmetro não pode ser alterado após a criação do notebook.
Nota
O banco de dados e o esquema são necessários apenas para armazenar seus notebooks. Você pode consultar qualquer banco de dados e esquema aos quais sua função tenha acesso a partir do seu notebook.
Selecione Run on container para o Runtime.
Selecione Runtime version das opções CPU ou GPU.
- Selecione um Compute pool.
O Snowflake provisiona automaticamente dois pools de computação em cada conta para a execução de notebooks: SYSTEM_COMPUTE_POOL_CPU e SYSTEM_COMPUTE_POOL_GPU.
Altere o warehouse selecionado a ser usado para executar consultas SQL e Snowpark.
Para criar e abrir seu notebook, selecione Create.
Runtime version:
Dois tipos de versão de tempo de execução estão disponíveis: CPU e GPU. Cada imagem de tempo de execução contém um conjunto base de versões e pacotes Python verificados e integrados pelo Snowflake. Todas as imagens de tempo de execução oferecem suporte à análise de dados, modelagem e treinamento com o Snowpark Python, Snowflake ML e Streamlit.
Para instalar pacotes adicionais de um repositório público, você pode usar o pip. Uma integração de acesso externo (EAI) é necessária para que o Snowflake Notebooks instale pacotes de pontos de extremidade externos. Para configurar EAIs, consulte Configurar acesso externo para o Snowflake Notebooks. Entretanto, se um pacote já fizer parte da imagem base, você não poderá alterar a versão do pacote instalando uma versão diferente com pip install. Para obter uma lista dos pacotes pré-instalados, execute o seguinte comando a partir de uma célula no notebook:
Compute pool:
Um pool de computação fornece os recursos de computação para o kernel do seu notebook e o código Python. Use pools de computação menores e baseados em CPU para começar e selecione pools de computação com mais memória e baseados em GPU para otimizar cenários de uso intensivo de GPU, como visão computacional ou LLMs/VLMs.
Observe que cada nó de computação está limitado a executar um notebook por usuário por vez. Você deve definir o parâmetro MAX_NODES com um valor maior que um ao criar pools de computação para notebooks. Para obter um exemplo, consulte Recursos de computação. Para mais detalhes sobre pools de computação do Snowpark Container Services, consulte Snowpark Container Services: como trabalhar com pools de computação.
Quando um notebook não estiver sendo usado, considere desligá-lo para liberar recursos do nó. Você pode desligar um notebook selecionando End session no menu suspenso de conexão.
Se um notebook for executado no Container Runtime, a função precisará do privilégio USAGE em um pool de computação, e não no warehouse do Notebook. Os pools de computação são máquinas virtual baseadas em CPU ou GPU gerenciadas pelo Snowflake. Ao criar um pool de computação, defina o parâmetro MAX_NODES como maior que um, pois cada notebook exigirá um nó completo para ser executado. Para obter mais informações, consulte Snowpark Container Services: como trabalhar com pools de computação.
Você pode visualizar a utilização de seus recursos. Para obter mais informações, consulte Sobre o Legacy Snowflake Notebooks.
Nota
No AWS, os notebooks executados nos pools de computação de GPU usam o armazenamento NVMe de alto desempenho como dispositivo de inicialização padrão.
Executar um notebook no Container Runtime¶
Depois de criar seu notebook, você pode começar a executar o código imediatamente adicionando e executando células. Para obter mais informações sobre como adicionar células, consulte Desenvolvimento e execução de código nos Snowflake Notebooks.
Importação de mais pacotes¶
Além dos pacotes pré-instalados para colocar seu notebook em funcionamento, você pode instalar pacotes de fontes públicas às quais tenha acesso externo definido. Você também pode usar pacotes armazenados em um estágio ou em um repositório privado. Você precisa usar a função ACCOUNTADMIN ou uma função que possa criar integrações de acesso externo (EAIs) para definir e conceder acesso para visitar pontos de extremidade externos específicos. Use o comando ALTER NOTEBOOK para habilitar o acesso externo no seu notebook. Uma vez concedido, você verá EAIs em Notebook settings. Ative as EAIs antes de começar a instalar a partir de canais externos. Para obter instruções, consulte Configurar um notebook com acesso externo e segredos.
O exemplo a seguir instala um pacote externo usando pip install em uma célula de código:
Atualização das configurações do notebook¶
Você pode atualizar configurações, como quais pools de computação ou warehouse usar, a qualquer momento em Notebook settings, que podem ser acessadas pelo menu  Ações do Notebook no canto superior direito.
Ações do Notebook no canto superior direito.
Uma das configurações que você pode atualizar em Notebook settings é a configuração de tempo limite de inatividade. O tempo limite de inatividade padrão é 1 hora, e você pode defini-lo para até 72 horas. Para definir isso em SQL, use o comando CREATE NOTEBOOK ou ALTER NOTEBOOK para definir a propriedade IDLE_AUTO_SHUTDOWN_TIME_SECONDS do notebook.
Instalação de pacotes privados¶
Pip oferece suporte à instalação de pacotes de fontes privadas com autenticação básica, como o JFrog Artifactory. Configure o notebook para integração de acesso externo (EAI) para que ele possa acessar o repositório.
Crie uma regra de rede para especificar o repositório que deseja acessar. Por exemplo, esta regra de rede especifica um repositório JFrog:
Crie um segredo que represente as credenciais necessárias para autenticação no local de rede externo.
Crie uma integração de acesso externo que permita o acesso ao repositório:
Associe a integração de acesso externo e o segredo ao notebook.
Para acessar a configuração de acesso externo, selecione
(menu Notebook actions) no canto superior direito do notebook.Selecione Notebook settings e depois selecione a guia External access.
Selecione a EAI para se conectar ao repositório.
O notebook é reiniciado.
Depois que o notebook for reiniciado, é possível instalar a partir do repositório:
Instalação de pacotes privados com conectividade privada¶
Se seu repositório de pacotes privados exigir conectividade privada, siga estas etapas para configurar sua conta. Se precisar de ajuda, é possível entrar em contato com seu administrador de conta para configurar a regra de rede.
Siga as etapas em Saída da rede usando conectividade privada para configurar a saída de rede usando a conectividade privada.
Crie um segredo que represente as credenciais necessárias para autenticação no local de rede externo.
Crie uma EAI com a regra de rede da etapa 1. Por exemplo:
Associe a integração de acesso externo e o segredo ao notebook.
Para acessar a configuração de acesso externo, selecione
(menu Notebook actions) no canto superior direito do notebook.Selecione Notebook settings e depois selecione a guia External access.
Selecione a EAI para se conectar ao seu repositório privado.
O notebook é reiniciado.
Depois que o notebook for reiniciado, é possível fornecer o
--index-urlde seu repositório:
Execução de cargas de trabalho ML¶
Os Notebooks no Container Runtime são adequados para executar cargas de trabalho de ML, como treinamento de modelos e ajuste de parâmetros. Os tempos de execução vêm pré-instalados com os pacotes de ML populares. Com o acesso à integração externa configurado, é possível instalar qualquer outro pacote necessário usando !pip install.
Para obter uma experiência ideal, use as bibliotecas OSS para desenvolver modelos ou para importar notebooks que usam componentes OSS. O Container Runtime otimizou as APIs, como:
DataConnectorpara uma ingestão de dados mais rápidaAPIs de treinamento distribuído para ajuste de modelos em escala
APIs de ajuste de hiperparâmetro distribuído para utilizar eficientemente todos os recursos disponíveis.
Para obter mais informações, consulte Snowflake Container Runtime.
Nota
Como o Runtime vem pré-instalado com muitos pacotes, uma alteração em qualquer versão requer a reinicialização do kernel. Para obter mais informações, consulte Explore Legacy Notebooks.
Usar bibliotecas OSS ML¶
O exemplo a seguir usa uma biblioteca OSS ML, xgboost, com uma sessão Snowpark ativa para buscar dados diretamente na memória para treinamento:
Limitações¶
Depois que uma sessão do notebook do Container Runtime é iniciada, ela pode ser executada por até sete dias sem interrupção. Após sete dias, ela poderá ser interrompida e desligada se houver um evento de manutenção de serviço programado SPCS. As configurações de tempo de inatividade do notebook ainda se aplicam. Para obter detalhes sobre a manutenção do serviço SPCS, consulte Manutenção do pool de computação.
Considerações sobre custo e faturamento¶
Ao executar notebooks no Container Runtime for , você pode incorrer em custos de </user-guide/cost-understanding-compute>computação de warehouse `:doc: e computação do SPCS</developer-guide/snowpark-container-services/accounts-orgs-usage-views> `Snowflake Notebooks. Warehouses são necessários não apenas para executar consultas, mas também para oferecer suporte a certas funcionalidades de front-end em Snowflake Notebooks. Por exemplo, ao usar um pool de computação para execução do Python, um warehouse ainda pode ser necessário para renderizar saídas ou manipular componentes interativos.
Snowflake Notebooks contam com warehouses virtuais para executar com eficiência consultas SQL e do Snowpark. Como resultado, você pode incorrer em custos de computação do warehouse ao executar células SQL ou consultas push-down do Snowpark em células Python.
O diagrama a seguir mostra onde a computação acontece para células SQL, Snowpark e Python em um notebook:
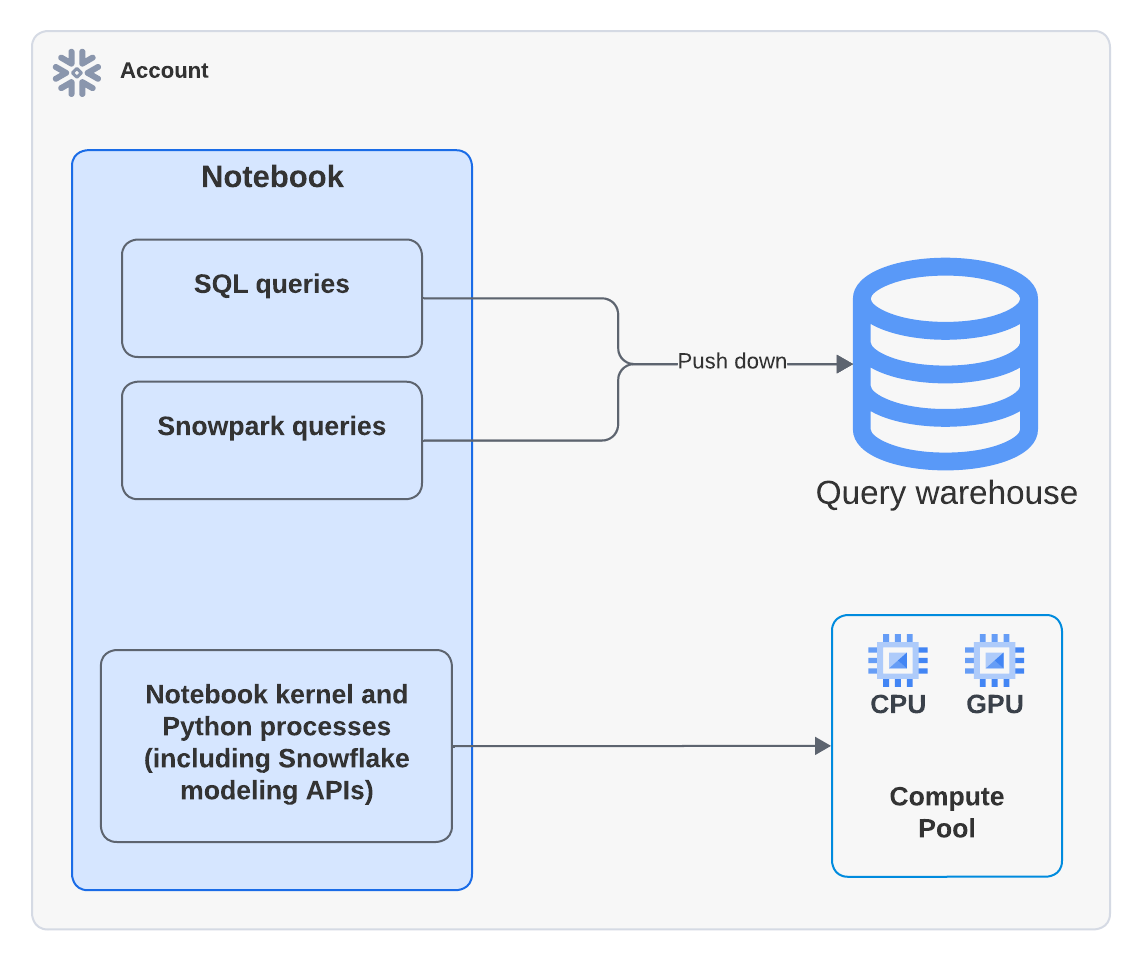
Nota
Quando você executa um notebook que usa um pool de computação, o código Python é executado no pool de computação. No entanto, você poderá ver atividade em Query History mostrando que um warehouse foi usado para executar o comando EXECUTE NOTEBOOK. Este é um comportamento esperado. O warehouse é usado brevemente para inicializar o ambiente de execução, mas não consome nenhum crédito do warehouse. Toda a execução de código é feita pelo pool de computação.
Por exemplo, o seguinte exemplo Python usa a biblioteca xgboost. Os dados são puxados para o contêiner e a computação é manipulada inteiramente por Snowpark Container Services:
Para saber mais sobre os custos de warehouse, consulte Visão geral de warehouses.