Bibliotecas CUDA-X no Snowflake ML¶
Use as integrações CUDA-X do Snowflake Container Runtime para dimensionar perfeitamente as transformações de dados e ML sobre GPUs sem alterar seu código. O Snowflake integrou as bibliotecas cuML e cuDF da NVIDIA ao ambiente de tempo de execução. Com essa integração, você pode usar bibliotecas como scikit-learn, umap-learn ou hdbscan com suas GPUs. Você não precisa aprender novas estruturas nem lidar com dependências complexas.
Você pode executar processamentos complexos, como modelagem de tópicos, genômica e reconhecimento de padrões, sem comprometer o tamanho dos dados ou a complexidade algorítmica. Reduzir o tempo de processamento oferece a oportunidade de iterar ainda mais em seus modelos.
A integração com as bibliotecas CUDA-X permite o processamento acelerado por GPU de grandes conjuntos de dados no Snowflake ML Container Runtime. A velocidade de processamento pode ser ordens de magnitude mais rápida do que usar o Container Runtime exclusivamente.
Bibliotecas NVIDIA CUDA-X para ciência de dados¶
Bibliotecas de código aberto como cuML e cuDF utilizam GPUs para fluxos de trabalho de dados mais eficientes e escaláveis. Você pode usar essas bibliotecas para processar dados com bilhões de linhas e milhões de dimensões. Para obter mais informações sobre essas bibliotecas, consulte CIÊNCIA de dados do NVIDIA CUDA-X.
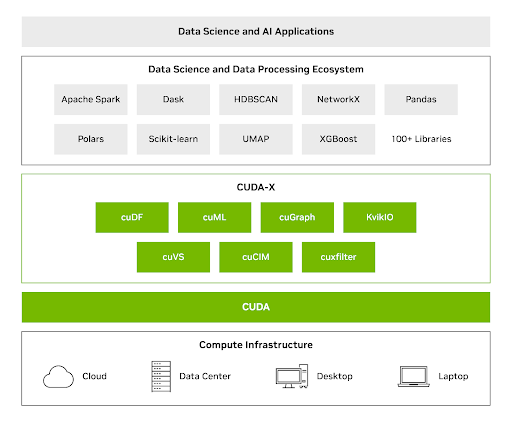
As bibliotecas CUDA-X DS combinam o poder das GPUs com bibliotecas Python comumente utilizadas para análise de dados, aprendizado de máquina e análise de gráficos, proporcionando grandes ganhos de velocidade sem exigir que as equipes reescrevam o código. Com o CUDA-X DS, você pode usar os aumentos de velocidade da GPU para processar conjuntos de dados de até terabytes com uma única GPU.
O NVIDIA cuML pode proporcionar as seguintes melhorias de desempenho em relação aos fluxos de trabalho de CPU:
Até 50 vezes para scikit-learn
Até 60 vezes para UMAP
Até 175 vezes para HDBSCAN
Casos de uso¶
A integração das bibliotecas CUDA-X no Snowflake ML Container Runtime utiliza GPUs com Scikit-learn e pandas para os seguintes casos de uso:
Modelagem de tópicos em grande escala¶
A modelagem de tópicos em conjuntos de dados grandes e ricos em recursos requer:
Uso de modelos de incorporação
Aplicação de redução de dimensionalidade em escala
Uso de clustering e exibição para extrair tópicos precisos e relevantes
O paralelismo de GPUs pode ajudar você a executar os fluxos de trabalho anteriores com mais eficiência. Ao acelerar seu processamento com cuML, você pode transformar milhões de avaliações de produtos de texto bruto em clusters de tópicos bem definidos, que podem ser reduzidos de horas em CPU para minutos em GPU, sem modificações no código Python existente. Isso destaca a aceleração perfeita e imediata para as bibliotecas UMAP e HDBSCAN.
Para obter mais informações sobre como realizar modelagem de tópicos em GPUs no Snowflake, consulte https://quickstarts.snowflake.com/guide/accelerate-topic-modeling-with-gpus-in-snowflake-ml/#0
Fluxos de trabalho de genômica computacional¶
Use as integrações do CUDA-X do Snowflake para acelerar significativamente o processamento de sequências biológicas. Você pode converter sequências de DNA em vetores de características para tarefas de classificação escalonáveis, como prever famílias de genes.
Executar código pandas e scikit-learn diretamente em GPUs com cuDF e cuML acelera o carregamento de dados, o pré-processamento e o treinamento de modelos em conjunto. Essa aceleração da GPU para fluxos de trabalho existentes, sem alterações de código, permite que os pesquisadores priorizem insights biológicos e design de modelos em vez de programação de GPUs de baixo nível.
Desenvolvimento no Snowflake¶
Use as bibliotecas CUDA-X para desenvolver e implantar modelos de aprendizado de máquina acelerados por GPU no Snowflake ML Container Runtime. Esta seção fornece um guia passo a passo para integrar essas ferramentas aos seus fluxos de trabalho em Python.
Para começar, faça o seguinte:
Defina seu script Python em um notebook Snowflake ou em um trabalho de ML
Selecione o tempo de execução da GPU e um pool de computação da GPU para seu trabalho de ML ou notebook
Após concluir as etapas anteriores, execute o seguinte código para configurar os aceleradores CUDA-X em seu ambiente.
Agora você pode executar operações do pandas diretamente em GPUs ou ajustar o modelo scikit-learn, umap ou hdbscan (observe que nenhuma alteração de código é necessária para executar em GPUs). Este exemplo mostra como usar hdbscan em grandes conjuntos de dados:
Caso de uso aplicado: modelagem de tópicos em escala¶
A eficiência computacional é crucial para modelagem de tópicos e análise de textos em larga escala. GPUs usam processamento paralelo para reduzir o tempo de processamento de horas para minutos. Esta seção demonstra como acelerar modelos de ML em um conjunto de dados de 200 mil avaliações de produtos de beleza usando aceleração de GPU com CUDA-X.
Você pode usar o CUDA-X para fazer o seguinte:
Transformar texto bruto em representações numéricas (incorporações) para aprendizado de máquina.
Acelerar a redução da dimensionalidade
Para utilizar as bibliotecas CUDA, adicione %load_ext cuml.accel no início do seu código. Isso reduz o tempo de processamento de horas para minutos.
O código de exemplo a seguir usa a classe SentenceTransformer para criar incorporações.
O código de exemplo a seguir usa HDBSCAN para reduzir dados de alta dimensionalidade. Ele retém os tópicos de cluster.
Caso de uso aplicado: execução de fluxos de trabalho genômicos complexos¶
A organização da família de genes, que inclui parálogos e ortólogos, é crucial para a compreensão da evolução, função e processos biológicos conservados dos genes.
Com as bibliotecas CUDA-X, você pode criar um modelo de classificação para prever famílias de genes a partir de sequências de DNA. Este modelo pode acelerar a anotação genômica, identificar novas funções gênicas e fornecer insights sobre vias evolutivas.
O conjunto de dados contém uma série de sequências de nucleotídeos em texto simples e os respectivos rótulos de classe de família de genes. As classes correspondem a sete famílias de genes humanos distintas.
O código a seguir usa o transformador de nucleotídeos da Hugging Face para converter as sequências de DNA em vetores. O transformador tokeniza e agrupa as sequências em lotes para transformar cada sequência de gene em um vetor de 1280 características.
Você pode usar o código a seguir para avaliar dois modelos de classificação de conjunto:
Um classificador Random Forest
Um classificador XGBoost