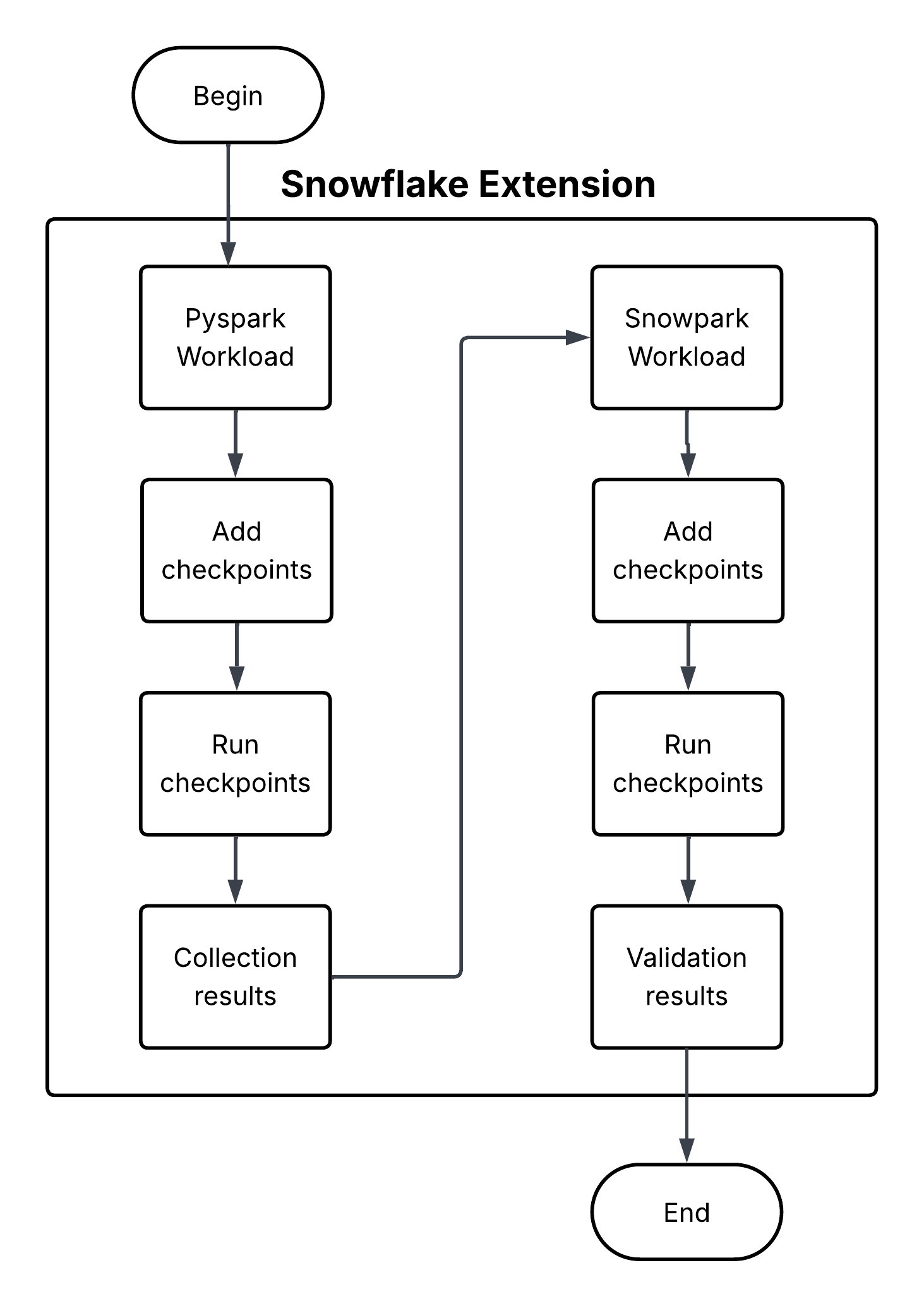
Pontos de verificação do Snowpark¶
O Snowpark Checkpoints é uma biblioteca de testes que valida o código migrado do Apache PySpark para o Snowpark Python. Ele compara as saídas das operações do DataFrame em ambas as plataformas, garantindo que as implementações do Snowpark produzam resultados que sejam funcionalmente equivalentes aos de suas contrapartes do PySpark. Ele se esforça para manter a integridade dos dados e a consistência analítica durante todo o processo de migração.