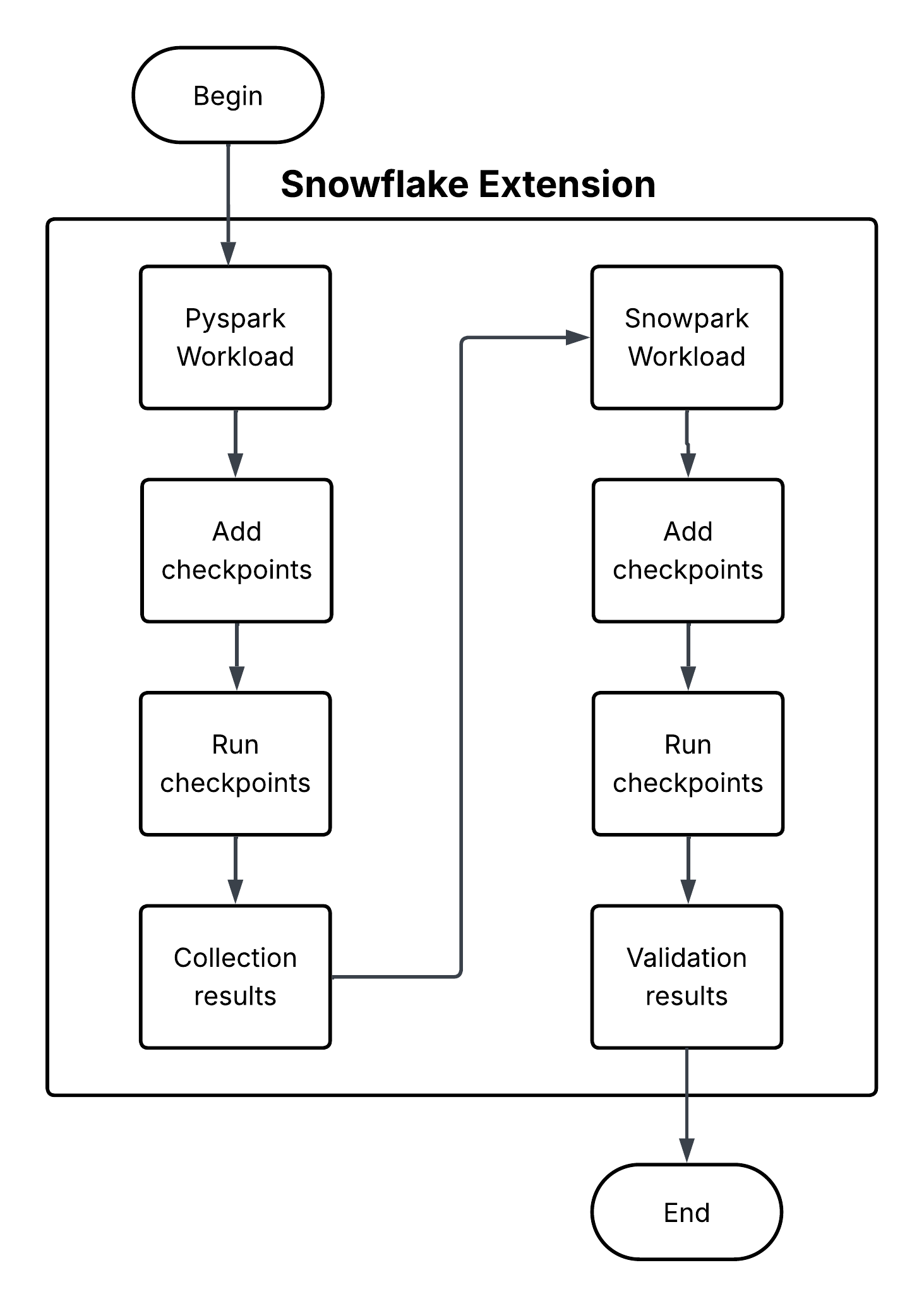
Snowpark Checkpoints¶
Snowpark Checkpoints ist eine Testbibliothek zur Validierung von Code, der von Apache PySpark nach Snowpark Python migriert wurde. Es vergleicht die Ausgaben von DataFrame-Operationen auf beiden Plattformen und stellt so sicher, dass Snowpark-Implementierungen Ergebnisse liefern, die funktionell gleichwertig mit ihren PySpark-Gegenstücken sind. Es ist bestrebt, die Datenintegrität und analytische Konsistenz während des gesamten Migrationsprozesses aufrechtzuerhalten.