Snowpark Checkpoints¶
Snowpark Checkpoints は、 Apache PySpark から Snowpark Python に移行したコードを検証するテストライブラリです。両プラットフォームの DataFrame 操作の出力を比較し、Snowparkの実装が PySpark の実装と機能的に同等の結果を生成することを保証します。統合プロセスを通じて、データの整合性と分析の一貫性を維持するよう努めます。
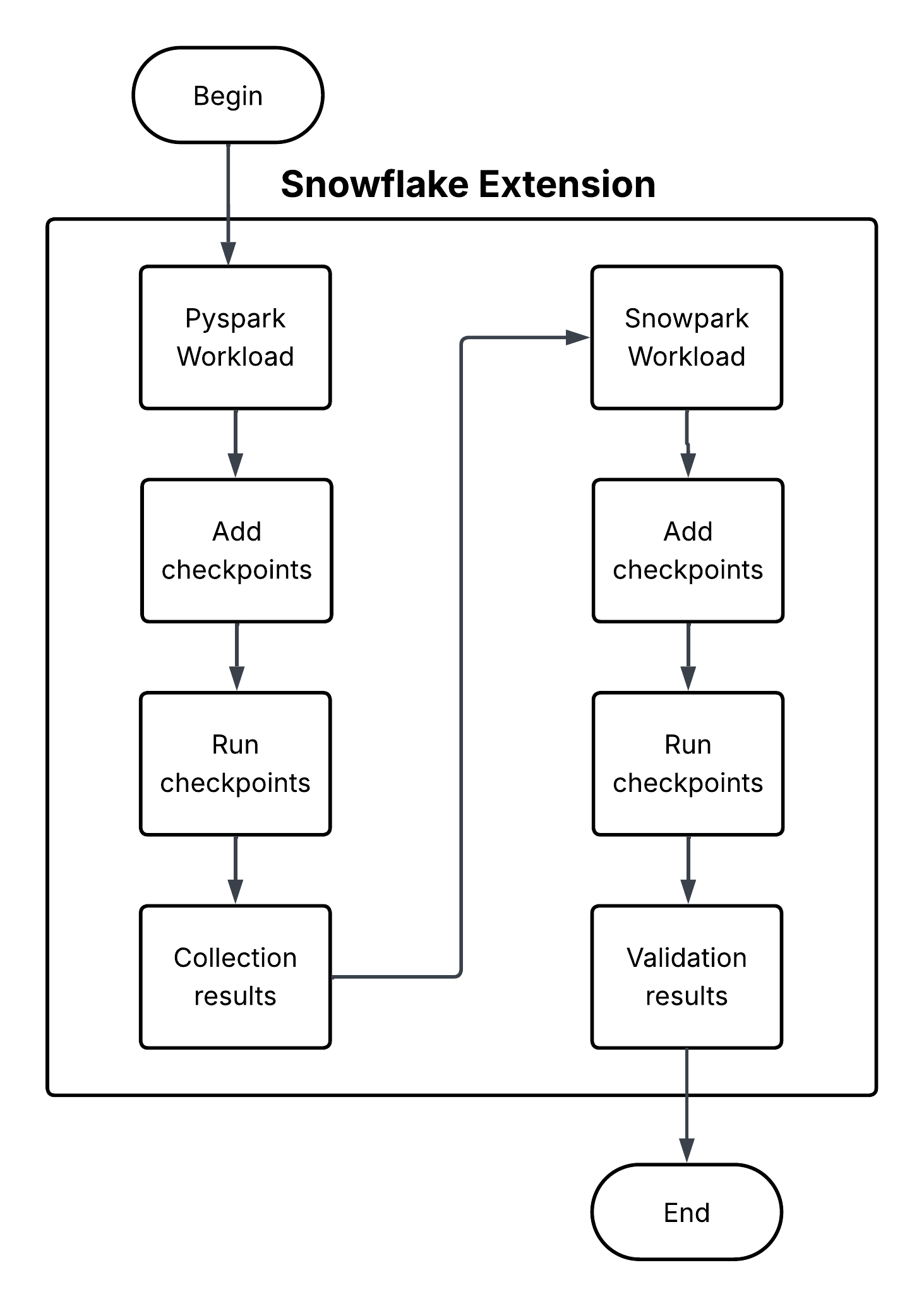
Snowpark Checkpoints は、 Apache PySpark から Snowpark Python に移行したコードを検証するテストライブラリです。両プラットフォームの DataFrame 操作の出力を比較し、Snowparkの実装が PySpark の実装と機能的に同等の結果を生成することを保証します。統合プロセスを通じて、データの整合性と分析の一貫性を維持するよう努めます。