Snowpark Checkpoints¶
Snowpark Checkpoints는 Apache PySpark 에서 Snowpark Python으로 마이그레이션한 코드를 검증하는 테스트 라이브러리입니다. 두 플랫폼에서 DataFrame 작업의 출력을 비교하여 Snowpark 구현이 PySpark 작업과 기능적으로 동등한 결과를 생성하는지 확인합니다. 마이그레이션 프로세스 전반에 걸쳐 데이터 무결성과 분석 일관성을 유지하기 위해 노력합니다.
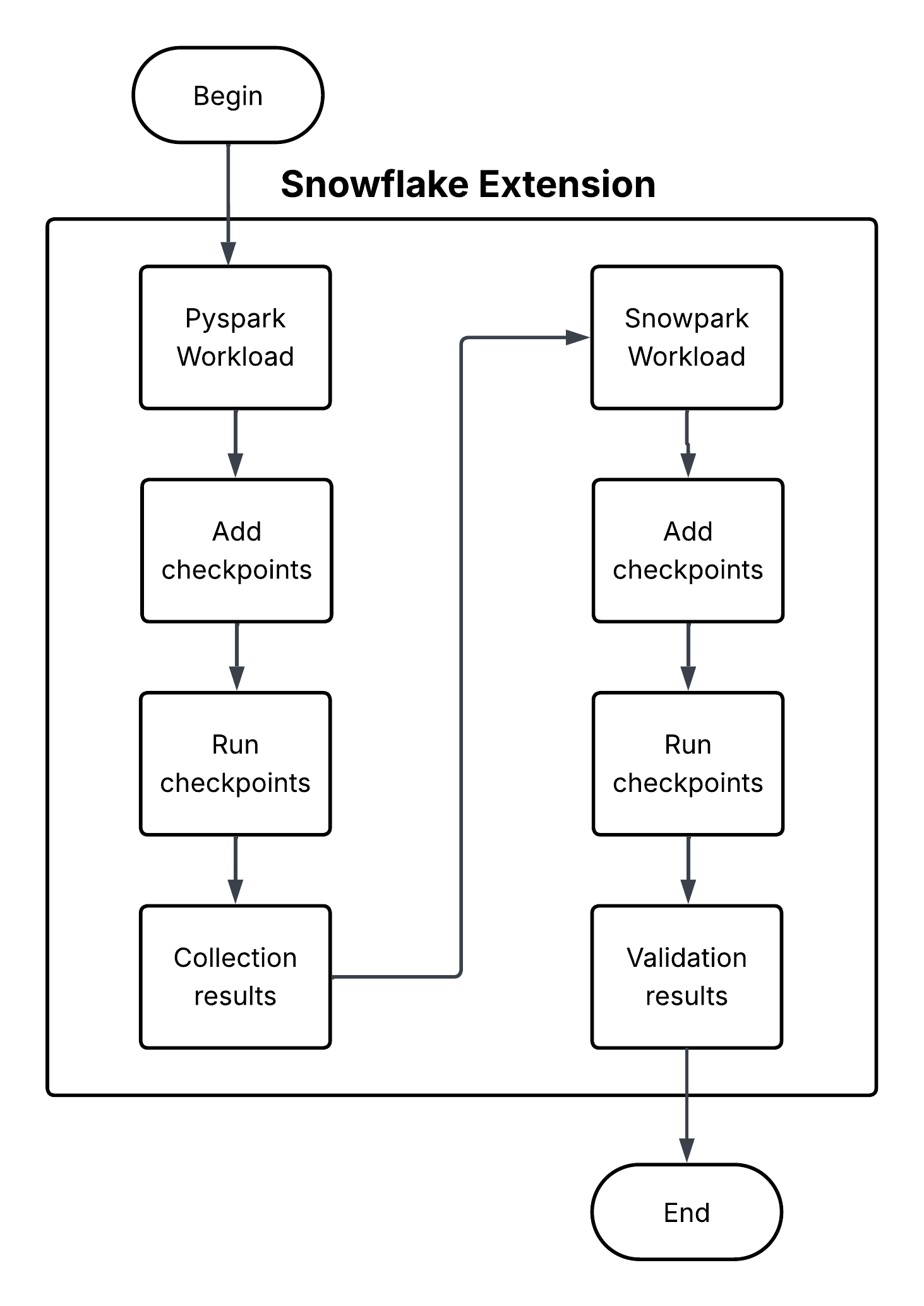
Snowpark Checkpoints는 Apache PySpark 에서 Snowpark Python으로 마이그레이션한 코드를 검증하는 테스트 라이브러리입니다. 두 플랫폼에서 DataFrame 작업의 출력을 비교하여 Snowpark 구현이 PySpark 작업과 기능적으로 동등한 결과를 생성하는지 확인합니다. 마이그레이션 프로세스 전반에 걸쳐 데이터 무결성과 분석 일관성을 유지하기 위해 노력합니다.