Tabelas dinâmicas¶
As tabelas dinâmicas são tabelas que se atualizam automaticamente com base em uma consulta definida e na atualização do destino, simplificando a transformação de dados e o gerenciamento de pipeline sem exigir atualizações manuais ou agendamento personalizado.
When you create a dynamic table, you define a query that specifies how data should be transformed from base objects. Snowflake handles the refresh schedule of the dynamic table and updates the table automatically to reflect the changes made to the base objects based on the query.
Principais considerações e práticas recomendadas gerais¶
Restrições de imutabilidade: Use restrições de imutabilidade para poder controlar as atualizações de tabelas dinâmicas. As restrições mantêm linhas específicas estáticas enquanto permitem atualizar o restante da tabela de forma incremental. Elas impedem alterações indesejadas nos dados marcados enquanto permitem atualizações normais em outras partes da tabela. Para obter mais informações, consulte Criação de tabelas dinâmicas com restrições de imutabilidade.
Performance considerations: Dynamic tables use incremental processing for workloads that support it, which can improve performance by recomputing only the data that has changed, rather than performing a full refresh. For more information, see Práticas recomendadas para otimizar o desempenho da tabela dinâmica.
Divida tabelas dinâmicas complexas: divida seu pipeline em tabelas dinâmicas menores e focadas para melhorar o desempenho e simplificar a solução de problemas. Para obter mais informações, consulte Práticas recomendadas para criar tabelas dinâmicas.
Como funcionam as tabelas dinâmicas¶
O Snowflake executa a consulta de definição especificada na instrução CREATE DYNAMIC TABLE e suas tabelas dinâmicas são atualizadas por meio de um processo automatizado.
The following diagram shows how this process computes the changes made to the base objects and merges them into the dynamic table by using compute resources associated with the table.
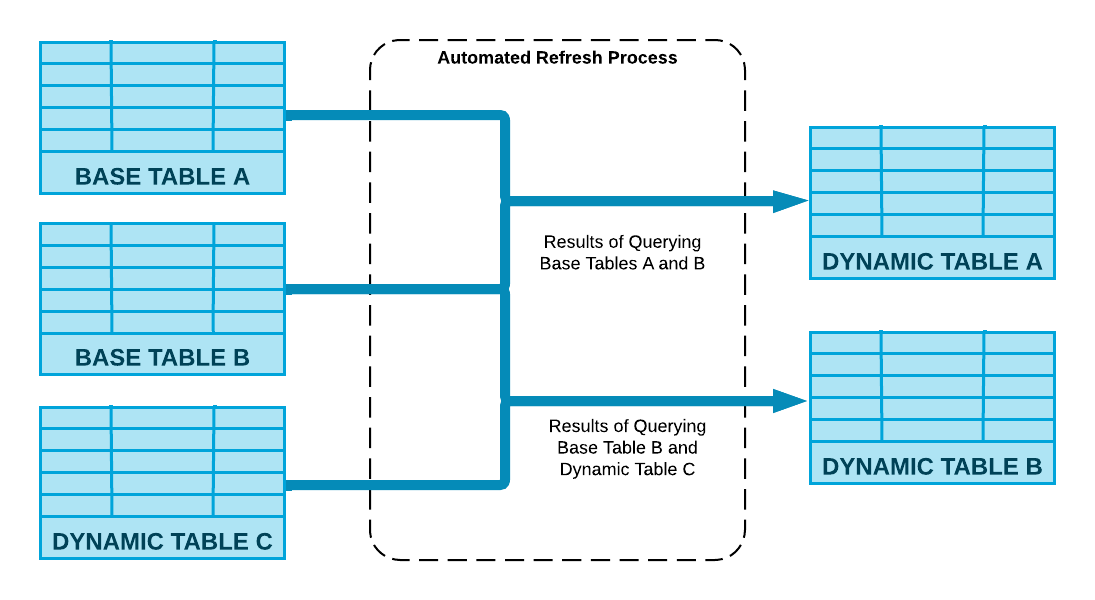
Atraso no destino¶
Use o atraso no destino para definir o nível de atualização dos seus dados. Normalmente, a atualização dos dados da tabela não estará tão atrás disso em relação à atualização dos dados da tabela base. Com o atraso no destino, você controla a frequência de atualização da tabela e o nível de atualização dos dados.
For more information, see Entendendo o atraso de destino da tabela dinâmica.
Dynamic table refresh¶
As tabelas dinâmicas tentam atualizar dentro da meta de atraso especificada por você. Por exemplo, um atraso no destino de cinco minutos garante que os dados na tabela dinâmica não fiquem mais de cinco minutos atrasados em relação às atualizações de dados na tabela base. Você define o modo de atualização ao criar a tabela e, depois, as atualizações podem ocorrer em um cronograma ou de forma manual.
For more information, see Compreensão da inicialização e atualização de tabelas dinâmicas and Atualize manualmente as tabelas dinâmicas.
Quando usar tabelas dinâmicas¶
Dynamic tables are ideal for the following scenarios:
You want to materialize query results without writing custom code.
You want to avoid manually tracking data dependencies and managing refresh schedules. Dynamic tables enable you to define pipeline outcomes declaratively, without managing transformation steps manually.
You want to chain together multiple tables for data transformations in a pipeline.
You don’t need fine-grained control over refresh schedules, and you only need to specify a target freshness for the pipeline. Snowflake handles the orchestration of data refreshes, including scheduling and execution, based on your target freshness requirements.
Exemplos de casos de uso¶
Dimensões de alteração lenta (SCDs): as tabelas dinâmicas podem ser usadas para implementar SCDs de tipo 1 e tipo 2 lendo a partir de um fluxo de alterações e usando funções de janela sobre chaves por registro ordenadas por um carimbo de data/hora de alteração. Esse método lida com inserções, exclusões e atualizações que ocorrem fora de ordem, simplificando a criação das SCDs. Para mais informações, consulte Dimensões de alteração lenta com tabelas dinâmicas.
** Junções e agregações:** você pode usar tabelas dinâmicas para pré-computar junções e agregações lentas de forma incremental, para permitir consultas rápidas.
Transições de lote para fluxos: as tabelas dinâmicas oferecem suporte a transições contínuas de lote para fluxos com um único comando ALTER DYNAMIC TABLE. Você pode controlar a frequência de atualização em seu pipeline para equilibrar o custo e a atualização dos dados.