Análise de dados com funções de janela¶
Este tópico contém informações conceituais introdutórias sobre funções de janela. Se você já tiver familiaridade com o uso de funções de janela, as seguintes informações de referência podem ser suficientes:
Funções de janela, que contém uma lista de funções e links para descrições de funções individuais.
Sintaxe e uso da função de janela, que descreve regras gerais de sintaxe para todas as funções de janela.
Introdução¶
Uma função de janela é uma função SQL analítica que opera em um grupo de linhas relacionadas, conhecidas como partição. Uma partição geralmente é um grupo lógico de linhas ao longo de alguma dimensão familiar, como categoria de produto, local, período de tempo ou unidade de negócios. Os resultados da função são computados sobre cada partição, em relação a um quadro de janela implícito ou explícito. Um quadro de janela é um conjunto fixo ou variável de linhas em relação à linha atual. A linha atual é uma única linha de entrada para a qual o resultado da função está sendo computado. Os resultados da função são calculados linha por linha dentro de cada partição, e cada linha no quadro de janela assume a sua vez como a linha atual.
A sintaxe que define esse comportamento é a cláusula da função OVER. Em muitos casos, a cláusula OVER distingue uma função de janela de uma função SQL regular com o mesmo nome (como AVG ou SUM). A cláusula OVER consiste em três componentes principais:
Uma cláusula PARTITION BY
Uma cláusula ORDER BY
Uma especificação de quadro de janela
Dependendo da função ou consulta em questão, todos esses componentes podem ser opcionais; uma função de janela com uma cláusula OVER vazia é válida: OVER(). Entretanto, na maioria das consultas analíticas, as funções de janela exigem um ou mais componentes de cláusula OVER explícita. Você pode chamar uma função de janela em qualquer contexto que permita outras funções SQL. As seções a seguir explicam os conceitos por trás das funções de janela com mais detalhes e apresentam alguns exemplos introdutórios. Para obter informações completas sobre sintaxe, consulte Sintaxe e uso da função de janela.
Funções de janela versus funções de agregação¶
Uma boa maneira de começar a aprender sobre funções de janela é comparar funções de agregação regulares com suas funções de janela correspondentes. Várias funções de agregação padrão, como SUM, COUNT e AVG, têm funções de janela correspondentes com o mesmo nome. Para distinguir as duas, observe que:
Para uma função de agregação, a entrada é um grupo de linhas e a saída é uma linha.
Para uma função de janela, a entrada é cada linha dentro de uma partição, e a saída é uma linha por linha de entrada.
Por exemplo, a função de agregação SUM retorna um único valor total para todas as linhas de entrada, enquanto uma função de janela retorna vários totais: um para cada linha (a linha atual) em relação a todas as outras linhas na partição.
Para ver como isso funciona, primeiro crie e carregue a tabela menu_items, que contém o custo dos produtos vendidos e os preços dos itens do menu do foodtruck. Use uma função AVG regular para encontrar o custo médio de produtos para itens de menu em diferentes categorias:
Observe que a função retorna um resultado agrupado para avg_cogs.
Alternativamente, você pode especificar uma cláusula OVER e usar AVG como uma função de janela. (O resultado é limitado a 15 linhas da tabela de 60 linhas.)
Observe que a função retorna uma média para cada linha em cada partição e redefine o cálculo quando o valor da coluna de particionamento muda. Para tornar o valor da função de janela mais aparente, adicione uma cláusula ORDER BY e um quadro de janela à definição da função. Retorne também os valores menu_cogs_usd brutos, além das médias, para que você possa ver como os cálculos específicos funcionam. Esta consulta é um exemplo simples de uma “média móvel”, um cálculo contínuo que depende de um quadro de janela explícito. Para mais exemplos como este, consulte Análise de dados de séries temporais.
O quadro de janela ajusta os cálculos médios de modo que apenas a linha atual e as duas linhas que a seguem (dentro da partição) sejam consideradas. A última linha em uma partição não tem linhas seguintes, então a média da última linha Beverage, por exemplo, é a mesma que o valor menu_cogs_usd correspondente (0.65). A saída da função de janela depende da linha individual que é passada para a função e dos valores das outras linhas que se qualificam para o quadro de janela.
Nota
Ao utilizar funções de janela com cláusulas ORDER BY, garanta que a ordenação seja determinística. Se várias linhas tiverem o mesmo valor nas colunas ORDER BY, adicione outras colunas como desempates para garantir resultados consistentes e previsíveis em todas as execuções de consultas. Neste exemplo, menu_cogs_usd foi incluído como desempate porque várias linhas podem ter o mesmo valor menu_price_usd.
Organização das linhas para funções de janela¶
O exemplo de função de janela AVG anterior usa uma cláusula ORDER BY dentro da definição de função para garantir que o quadro de janela esteja sujeito aos dados classificados (por menu_price_usd neste caso).
Dois tipos de funções de janela requerem uma cláusula: ORDER BY:
Funções de janela com quadros de janela explícitos, que realizam operações contínuas em subconjuntos de linhas em cada partição, como calcular totais acumulados ou médias móveis. Sem uma cláusula ORDER BY, o quadro de janela não tem sentido; o conjunto de linhas “anteriores” e “seguintes” deve ser determinístico.
Funções de janela de classificação, como CUME_DIST, RANK e DENSE_RANK, que retornam informações com base na “classificação” de uma linha. Por exemplo, se você classificar as lojas em ordem decrescente de lucro por mês, a loja com o maior lucro será classificada como 1; a segunda loja mais lucrativa será classificada como 2 e assim por diante.
A cláusula ORDER BY para uma função de janela aceita a mesma sintaxe da cláusula ORDER BY principal que classifica os resultados finais de uma consulta. Essas duas cláusulas ORDER BY são separadas e distintas. Uma cláusula ORDER BY dentro de uma cláusula OVER controla apenas a ordem na qual a função de janela processa as linhas; ela não controla a saída da consulta inteira. Em muitos casos, suas consultas de função de janela conterão ambos os tipos de cláusulas ORDER BY.
Nota
A cláusula ORDER BY para funções de janela não oferece suporte ao uso de uma posição ordinal, como OVER (PARTITION BY 1 ORDER BY 2). Nesse contexto, 2 é interpretado como a constante 2. Ele não se refere à segunda coluna da consulta.
As cláusulas PARTITION BY e ORDER BY dentro da cláusula OVER também são independentes. Você pode usar a cláusula ORDER BY sem a cláusula PARTITION BY e vice-versa.
Verifique a sintaxe das funções de janela individuais antes de escrever consultas. Os requisitos de sintaxe para a cláusula ORDER BY variam de acordo com a função:
Algumas funções de janela requerem uma cláusula ORDER BY.
Algumas funções de janela utilizam uma cláusula ORDER BY se ela estiver presente, mas não a exigem.
Algumas funções de janela não permitem uma cláusula ORDER BY.
Algumas funções de janela interpretam uma cláusula ORDER BY como um quadro de janela implícito.
Cuidado
Em termos gerais, SQL é uma linguagem explícita, com poucas cláusulas implícitas. Entretanto, para algumas funções de janela, uma cláusula ORDER BY implica um quadro de janela. Para obter mais detalhes, consulte Notas de uso para quadros de janela.
Como o comportamento implícito em vez de explícito pode levar a resultados difíceis de entender, o Snowflake recomenda declarar os quadros de janela explicitamente.
Utilização de diferentes tipos de quadros de janela¶
Quadros de janelas são definidos explicitamente ou implicitamente. Eles dependem da presença de uma cláusula ORDER BY dentro da cláusula OVER:
Para sintaxe de quadro explícita, consulte
windowFrameClauseem Sintaxe. Você pode definir limites abertos: do início da partição até a linha atual; da linha atual até o fim da partição; ou completamente “ilimitados” de ponta a ponta. Como alternativa, você pode usar offsets explícitos (inclusive) que são relativos à linha atual na partição.Quadros implícitos são usados por padrão quando a cláusula OVER não inclui
windowFrameClause. O quadro padrão depende da função em questão. Consulte também Notas de uso para quadros de janela.
Quadros de janela baseados em intervalos versus quadros de janela baseados em linhas¶
O Snowflake oferece suporte a dois tipos principais de quadros de janela:
- Baseado em linha:
Uma sequência exata de linhas pertence ao quadro, com base em um offset físico a partir da linha atual. Por exemplo,
5 PRECEDINGsignifica as cinco linhas que precedem a linha atual. O offset deve ser um número. O modo ROWS é inclusivo e é sempre relativo à linha atual. Se o número especificado de linhas anteriores ou seguintes se estender além dos limites da partição, o Snowflake tratará o valor como NULL.Se o quadro tiver limites abertos em vez de limites explicitamente numerados, um offset físico semelhante será aplicado. Por exemplo, ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW significa que o quadro consiste em todo o conjunto de linhas (zero ou mais) que precedem fisicamente a linha atual e a própria linha atual.
- Baseado em intervalo:
Um intervalo lógico de linhas pertence ao quadro, dado um offset a partir do valor ORDER BY da linha atual. Por exemplo,
5 PRECEDINGsignifica linhas com valores ORDER BY que têm o valor ORDER BY da linha atual, mais ou menos um máximo de 5 (mais para ordem DESC, menos para ordem ASC). O valor de offset pode ser um número ou um intervalo.Se o quadro tiver limites abertos em vez de numerados, um offset lógico semelhante será aplicado. Por exemplo, RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW significa que o quadro consiste em todas as linhas que precedem fisicamente a linha atual, a própria linha atual e quaisquer linhas adjacentes que tenham o mesmo valor ORDER BY que a linha atual. Para um quadro de janela RANGE, CURRENT ROW não significa fisicamente a linha atual; significa todas as linhas que têm o mesmo valor ORDER BY que a linha física atual.
As distinções entre quadros de janela ROWS BETWEEN e RANGE BETWEEN são importantes porque as consultas de função de janela podem retornar resultados muito diferentes, dependendo da expressão ORDER BY, dos dados nas tabelas e da definição exata do quadro. Os exemplos a seguir demonstram as diferenças de comportamento.
Comparação de RANGE BETWEEN e ROWS BETWEEN com offsets explícitos¶
Um quadro de janela baseado em intervalo requer uma coluna ou expressão ORDER BY e uma especificação RANGE BETWEEN. O limite lógico do quadro de janela depende do valor ORDER BY (uma constante numérica ou literal de intervalo) para a linha atual.
Por exemplo, uma tabela de séries temporais chamada heavy_weather é definida da seguinte forma:
As linhas de exemplo nesta tabela têm a seguinte aparência:
Suponha que uma consulta calcule uma média móvel de 3 horas (AVG) sobre a coluna precip (precipitação), usando um quadro de janela ordenado por start_time:
Dadas as linhas de amostra acima, quando a linha atual é 2021-12-30 11:23:00.000 (a primeira linha de amostra), apenas as duas próximas linhas caem dentro do quadro (2021-12-30 11:43:00.000 e 2021-12-30 13:53:00.000). Os carimbos de data/hora subsequentes são maiores que 3 horas depois.
Entretanto, se você alterar o quadro de janela para um intervalo de 1 dia, todas as linhas de amostra que seguem a linha atual ficarão dentro do quadro porque todas elas têm carimbos de data/hora na mesma data (2021-12-30):
Se você alterasse essa sintaxe de RANGE BETWEEN para ROWS BETWEEN, o quadro teria que especificar limites fixos, que representam um número exato de linhas: a linha atual mais o seguinte número exato ordenado de linhas, como 1, 3 ou 10 linhas, independentemente dos valores retornados pela expressão ORDER BY.
Consulte também Exemplo de RANGE BETWEEN com deslocamentos numéricos explícitos.
Comparação de RANGE BETWEEN e ROWS BETWEEN com limites abertos¶
O exemplo a seguir compara os resultados quando os seguintes quadros de janela são calculados em relação ao mesmo conjunto de linhas:
Este exemplo seleciona de uma pequena tabela chamada menu_items. Consulte Criação e carregamento da tabela menu_items.
A função de janela SUM agrega os valores menu_price_usd para cada partição menu_category. Com a sintaxe ROWS BETWEEN, é fácil ver como os totais acumulados são cumulativos dentro de cada partição.
Quando a sintaxe RANGE BETWEEN é usada com uma consulta idêntica, os cálculos não são tão óbvios a princípio; eles dependem de uma interpretação diferente de linha atual: a própria linha atual mais quaisquer linhas adjacentes que tenham o mesmo valor ORDER BY que essa linha.
Por exemplo, os valores sum_price para a segunda e terceira linhas no resultado são ambos 8.00 porque o valor ORDER BY para essas linhas é o mesmo. Esse comportamento ocorre em dois outros lugares no conjunto de resultados, onde sum_price é calculado consecutivamente como 24.00 e 12.00.
Quadros de janela para cálculos cumulativos e deslizantes¶
Os quadros de janela são um mecanismo muito flexível para executar diferentes tipos de consultas analíticas, incluindo cálculos cumulativos e cálculos móveis. Para retornar somas cumulativas, por exemplo, você pode especificar um quadro de janela que começa em um ponto fixo e se move linha por linha por toda a partição:
Outro exemplo desse tipo de quadro pode ser:
O número de linhas que se qualificam para esses quadros é variável, mas os pontos inicial e final dos quadros são fixos, usando limites nomeados em vez de limites numérico ou de intervalo.
Se você quiser que o cálculo da função de janela deslize para frente sobre um número específico (ou intervalo) de linhas, você pode usar offsets explícitos:
Neste caso, o resultado é um quadro deslizante que consiste em um máximo de sete linhas (3 + linha atual + 3). Outro exemplo desse tipo de quadro pode ser:
Quadros de janela podem conter uma mistura de limites nomeados e offsets explícitos.
Quadros de janela deslizantes¶
Um quadro de janela deslizante é um quadro de largura fixa que “desliza” pelas linhas da partição, cobrindo uma parte diferente da partição a cada vez. O número de linhas no quadro permanece o mesmo, exceto no início ou no fim de uma partição, onde pode conter menos linhas.
Janelas deslizantes são frequentemente usadas para calcular médias móveis, que são baseadas em um intervalo de tamanho fixo (como um número de dias). A média é “móvel” porque, embora o tamanho do intervalo seja constante, os valores reais no intervalo mudam ao longo do tempo (ou em alguma outra dimensão).
Por exemplo, analistas do mercado de ações frequentemente analisam as ações com base, em parte, na média móvel do preço de uma ação em 13 semanas. O preço médio móvel hoje é a média de preço no final de hoje e o preço no final de cada dia durante as últimas 13 semanas. Se as ações forem negociadas 5 dias por semana e se não houver feriados nas últimas 13 semanas, a média móvel será o preço médio em cada um dos 65 dias de negociação mais recentes (incluindo hoje).
O exemplo a seguir mostra o que acontece com uma média móvel de 13 semanas (91 dias) do preço de uma ação no último dia de junho e nos primeiros dias de julho:
Em 30 de junho, a função retorna o preço médio para 1º de abril a 30 de junho (inclusive).
Em 1º de julho, a função retorna o preço médio para 2 de abril a 1º de julho (inclusive).
Em 2 de julho, a função retorna o preço médio para 3 de abril a 2 de julho (inclusive).
O exemplo a seguir usa uma pequena janela deslizante (de 3 dias) nos primeiros 7 dias do mês. Este exemplo leva em conta o fato de que no início do período, a partição pode não estar cheia:
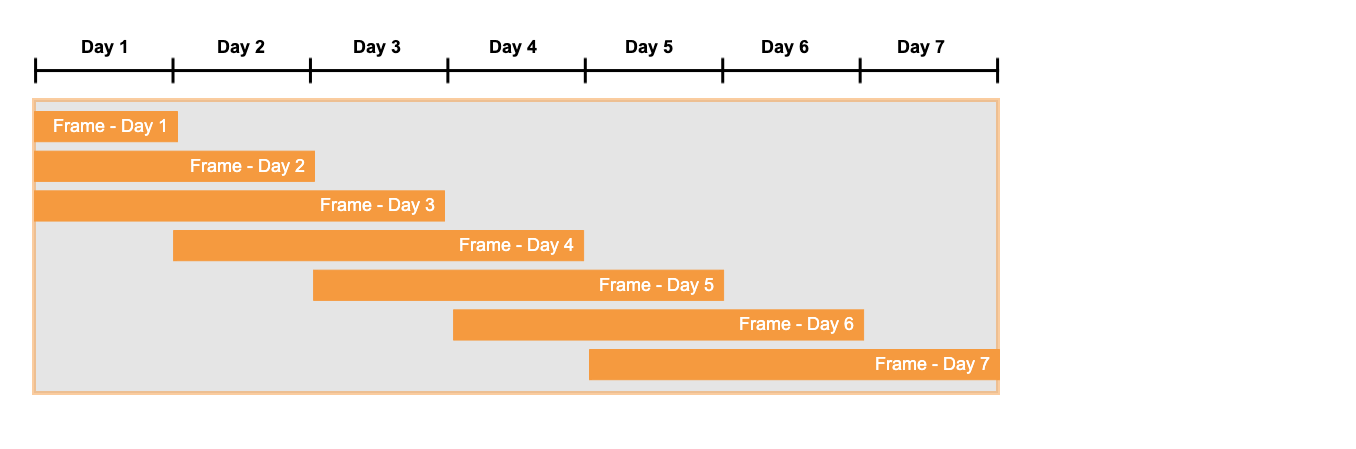
Como você pode ver no modelo correspondente de um resultado de consulta, a última coluna contém a soma dos dados de vendas dos três dias mais recentes. Por exemplo, o valor da coluna para o dia 4 é 36, que é a soma das vendas para dias 2, 3 e 4 (11 + 12 + 13):
Funções da janela de classificação¶
A sintaxe para uma função de janela de classificação é essencialmente a mesma que a sintaxe para outras funções de janela. As exceções incluem:
As funções da janela de classificação exigem a cláusula ORDER BY dentro da cláusula OVER.
Para algumas funções de classificação, como a própria RANK, nenhum argumento de entrada é necessário. Para a função RANK, o valor retornado é baseado somente na classificação numérica, conforme determinado pela cláusula ORDER BY dentro da cláusula OVER. Portanto, é desnecessário passar um nome de coluna ou expressão para a função.
A função de classificação mais simples é chamada RANK. Você pode usar esta função para:
Classificar os vendedores em relação à receita (vendas), da mais alta para a mais baixa.
Classificação de países com base no GDP per capita (PIB por pessoa), do mais alto para o mais baixo.
Classificação dos países em relação à poluição do ar, do mais baixo para o mais alto.
Esta função identifica a posição de classificação numérica de uma linha em um conjunto ordenado de linhas. A primeira linha tem classificação 1, a segunda tem classificação 2 e assim por diante. O exemplo a seguir mostra a ordem de classificação dos vendedores com base em Amount Sold:
As linhas já devem estar ordenadas antes que as classificações possam ser atribuídas. Portanto, você deve usar uma cláusula ORDER BY dentro da cláusula OVER.
Considere o seguinte exemplo: você gostaria de saber como está o lucro da sua loja entre as filiais da rede de lojas (se sua loja está em primeiro, segundo, terceiro lugar e assim por diante). Este exemplo classifica cada loja por lucratividade dentro de sua cidade. As linhas são colocadas em ordem decrescente (maior lucro primeiro), então a loja mais lucrativa é classificada como 1:
Nota
A coluna net_profit não precisa ser passada como argumento para a função RANK. Em vez disso, as linhas de entrada são classificadas por net_profit. A função RANK precisa apenas retornar a posição da linha (1, 2, 3 e assim por diante) dentro da partição.
A saída de uma função de classificação depende do seguinte:
A linha individual passada à função.
Os valores das outras linhas na partição.
A ordem de todas as linhas na partição.
O Snowflake fornece diversas funções de classificação diferentes. Para obter uma lista dessas funções e mais detalhes sobre a sintaxe, consulte Funções de janela.
Para classificar sua loja em relação a todas as outras lojas da rede, e não apenas quanto a outras lojas de sua cidade, use a consulta abaixo:
A consulta a seguir usa a primeira cláusula ORDER BY para controlar o processamento pela função de janela e a segunda cláusula ORDER BY para controlar a ordem de toda a saída da consulta:
Exemplo ilustrado¶
Este exemplo utiliza um cenário de vendas para ilustrar muitos dos conceitos descritos anteriormente neste tópico.
Suponha que você precise gerar um relatório financeiro que mostre valores baseados nas vendas da última semana:
Vendas diárias
Classificação dentro da semana (ou seja, vendas classificadas da maior para a menor na semana)
Vendas até agora nesta semana (ou seja, a “soma acumulada” para todos os dias desde o início da semana até o dia atual, inclusive)
Total de vendas da semana
Média móvel de três dias (ou seja, a média do dia atual e dos dois dias anteriores)
O relatório pode parecer com isto:
O SQL para esta consulta é um tanto complexo. Em vez de mostrar o exemplo como uma única consulta, esta discussão divide o SQL para as colunas individuais.
Em um cenário do mundo real, você teria anos de dados, então, para calcular somas e médias para uma semana específica de dados, você precisaria usar uma janela de uma semana ou usar um filtro semelhante a:
Entretanto, para este exemplo, suponha que a tabela contenha apenas os dados da semana mais recente.
Cálculo da classificação de vendas¶
A coluna Rank é calculada usando a função RANK:
Embora haja 7 dias no período de tempo, há apenas 5 classificações diferentes (1, 2, 3, 5, 6). Houve dois empates (para 3º lugar e 6º lugar), portanto não há linhas com linhas 4 ou 7.
Cálculo das vendas até agora nesta semana¶
A coluna Sales So Far This Week é calculada usando SUM como uma função de janela com um quadro de janela:
Esta consulta ordena as linhas por data e depois, para cada data, calcula a soma das vendas desde o início da janela até a data atual (inclusive).
Cálculo do total de vendas desta semana¶
A coluna Total Sales This Week é calculada usando SUM.
Calculando uma média móvel de três dias¶
A coluna 3-Day Moving Average é calculada usando AVG como uma função de janela com um quadro de janela:
A diferença entre este quadro de janela e o quadro de janela descrito anteriormente é o ponto de partida: um limite fixo versus um offset explícito.
O resultado¶
Aqui está a versão final da consulta, mostrando todas as colunas:
Exemplos adicionais¶
Esta seção fornece mais exemplos de funções de janela e ilustra como as cláusulas PARTITION BY e ORDER BY funcionam juntas.
Estes exemplos utilizam a seguinte tabela e dados:
Função de janela com cláusula ORDER BY¶
A cláusula ORDERBY controla a ordem dos dados dentro de cada janela (e cada partição se houver mais de uma partição). Isto é útil se você quiser mostrar uma “soma corrente” ao longo do tempo à medida que novas linhas são adicionadas.
Uma soma corrente pode ser calculada desde o início da janela até a linha atual (inclusive) ou desde a linha atual até o final da janela.
Uma consulta pode usar uma janela “deslizante”, que é uma janela de largura fixa que processa n linhas especificadas em relação à linha atual (por exemplo, as 10 linhas mais recentes, incluindo a linha atual).
Quadros de janelas com limites fixos¶
Quando o quadro de janela tem um limite fixo, os valores podem ser calculados do início da janela até a linha atual (ou da linha atual até o final da janela):
O resultado de consulta inclui comentários adicionais que mostram como a coluna CUMULATIVE_SUM_QUANTITY foi calculada:
Quadros de janelas com deslocamentos explícitos¶
No mundo financeiro, os analistas frequentemente estudam “médias móveis”.
Por exemplo, você pode ter um gráfico no qual o eixo X é o tempo e o eixo Y mostra o preço médio da ação nas últimas 13 semanas (ou seja, uma média móvel de 13 semanas). Em um gráfico de uma média móvel de 13 semanas do preço de uma ação, o preço mostrado para 30 de junho não é o preço da ação em 30 de junho, mas a média do preço da ação para as 13 semanas até 30 de junho inclusive (ou seja, de 1º de abril até 30 de junho). O valor em 1º de julho é o preço médio para 2 de abril até 1º de julho; o valor em 2 de julho é o preço médio para 3 de abril até 2 de julho e assim por diante. Cada dia, a janela efetivamente adiciona o valor do dia mais recente à média móvel e remove o valor do dia mais antigo. Isto suaviza as flutuações do dia a dia e pode facilitar o reconhecimento de tendências.
As médias móveis podem ser calculadas usando um quadro de janela deslizante. O quadro tem uma largura específica em linhas. No exemplo de preço de ações acima, 13 semanas são 91 dias, portanto a janela deslizante seria de 91 dias. Se as medições forem feitas uma vez por dia (por exemplo, no final do dia), a janela terá 91 linhas de “largura”.
Para definir uma janela com 91 linhas de largura:
Nota
O quadro de janela inicial pode ter menos de 91 dias de largura. Por exemplo, suponhamos que você queira o preço médio móvel de uma ação para 13 semanas. Se a ação foi criada em 1º de abril, então em 3 de abril havia apenas 3 dias de informação de preços; assim, a janela tem apenas 3 linhas de largura.
O exemplo a seguir mostra o resultado da soma em um quadro de janela deslizante com largura suficiente para armazenar dois exemplos:
O resultado de consulta inclui comentários adicionais que mostram como a coluna SLIDING_SUM_QUANTITY foi calculada:
Observe que a funcionalidade “janela deslizante” requer a cláusula ORDER BY; a função depende da ordem das linhas que entram e saem do quadro de janela.
Totais acumulados com cláusulas PARTITION BY e ORDER BY¶
Você pode combinar as cláusulas PARTITION BY e ORDER BY para obter somas acumuladas dentro das partições. Neste exemplo, as partições são de um mês, e como as somas se aplicam somente dentro de uma partição, a soma é redefinida como 0 no início de cada novo mês:
O resultado da consulta inclui comentários adicionais mostrando como a coluna MONTHLY_CUMULATIVE_SUM_QUANTITY foi calculada:
Você pode combinar partições e quadros de janela deslizantes. No exemplo abaixo, a janela deslizante normalmente tem duas linhas de largura, mas cada vez que uma nova partição (ou seja, um novo mês) é alcançada, a janela deslizante começa com apenas a primeira linha naquela partição:
O resultado da consulta inclui comentários adicionais mostrando como a coluna MONTHLY_SLIDING_SUM_QUANTITY foi calculada:
Calcular a razão entre um valor e uma soma de valores¶
Você pode usar a função RATIO_TO_REPORT para calcular a proporção de um valor para a soma dos valores em uma partição e, em seguida, retornar a proporção como uma porcentagem dessa soma. A função divide o valor na linha atual pela soma dos valores em todas as linhas de uma partição.
A cláusula PARTITION BY define partições na coluna city. Se você quiser ver a porcentagem de lucro relativa a toda a rede, em vez de apenas às lojas de uma cidade específica, omita a cláusula PARTITION BY: