Identificação de sequências de linhas que correspondem a um padrão¶
Introdução¶
Em alguns casos, pode ser necessário identificar sequências de linhas de tabela que correspondam a um padrão. Por exemplo, você pode precisar:
Determinar quais usuários seguiram uma sequência específica de páginas e ações em seu site antes de abrir um tíquete de suporte ou fazer uma compra.
Encontrar os estoques com preços que seguiram uma recuperação em forma de V ou de W durante um período.
Procurar padrões em dados de sensor que possam indicar a proximidade de uma falha do sistema.
Para identificar sequências de linhas que correspondam a um padrão específico, use a subcláusula MATCH_RECOGNIZE da cláusula FROM.
Nota
Você não pode usar a cláusula MATCH_RECOGNIZE em uma expressão de tabela comum (CTE) **recursiva**.
Um exemplo simples que identifica uma sequência de linhas¶
Como exemplo, suponha que uma tabela contenha dados sobre preços de ações. Cada linha contém o preço de fechamento de cada ticker em um dia específico. A tabela contém as seguintes colunas:
Nome da coluna |
Descrição |
|---|---|
|
A data do preço de fechamento. |
|
O preço de fechamento das ações nessa data. |
Suponha que você queira detectar um padrão no qual o preço da ação diminui e depois aumenta, produzindo um formato em “V” no gráfico do preço da ação.
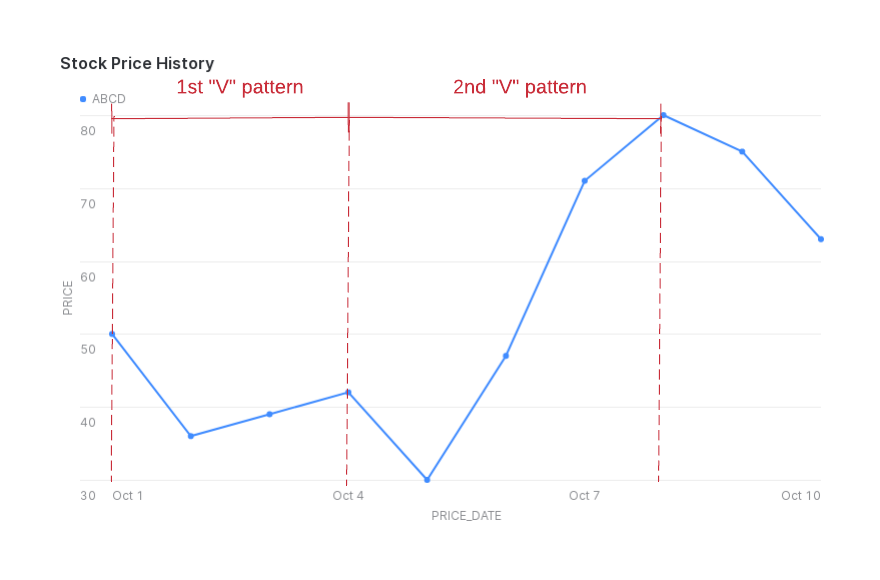
(Este exemplo não leva em conta os casos em que o preço das ações não muda de dia para dia).
Neste exemplo, para um determinado ticker, você quer encontrar sequências de linhas onde o valor na coluna price diminui antes de aumentar.
Para cada sequência de linhas que corresponda a este padrão, você quer retornar:
Um número que identifica a sequência (a primeira sequência correspondente, a segunda sequência correspondente, etc.).
O dia anterior à redução do preço das ações.
O último dia em que o preço das ações aumentou.
O número de dias no padrão “V”.
O número de dias em que o preço das ações diminuiu.
O número de dias em que o preço das ações aumentou.
A figura a seguir ilustra as reduções de preço (NUM_DECREASES) e os aumentos (NUM_INCREASES) dentro do padrão “V” que os dados retornados capturam. Note que ROWS_IN_SEQUENCE inclui uma linha inicial que não é contada em NUM_DECREASES ou NUM_INCREASES.

Para produzir esta saída, você pode usar a cláusula MATCH_RECOGNIZE mostrada abaixo.
Como mostrado acima, a cláusula MATCH_RECOGNIZE consiste em muitas subcláusulas, cada uma com um propósito diferente (por exemplo, especificar o padrão a atender, especificar os dados a retornar, etc.).
As próximas seções explicam cada uma das subcláusulas deste exemplo.
Configuração dos dados para este exemplo¶
Para configurar os dados utilizados neste exemplo, execute as seguintes instruções SQL:
Etapa 1: Especificação da ordem e do agrupamento de linhas¶
O primeiro passo para identificar uma sequência de linhas é definir o agrupamento e a ordem das linhas que se deseja pesquisar. Para o exemplo de encontrar um padrão “V” no preço das ações de uma empresa:
As linhas devem ser agrupadas por empresa, já que se deseja encontrar um padrão no preço para uma determinada empresa.
Dentro de cada grupo de linhas (os preços para uma determinada empresa), as linhas devem ser classificadas por data em ordem crescente.
Em uma cláusula MATCH_RECOGNIZE, você usa as subcláusulas PARTITION BY e ORDER BY para especificar o agrupamento e a ordem das linhas. Por exemplo:
Etapa 2: Definição do padrão a atender¶
Em seguida, determine o padrão que corresponde à sequência de linhas que você deseja encontrar.
Para especificar este padrão, você usa algo semelhante a uma expressão regular. Em expressões regulares, você usa uma combinação de literais e metacaracteres para especificar um padrão a ser atendido em uma cadeia de caracteres.
Por exemplo, para encontrar uma sequência de caracteres que inclua:
qualquer caractere único, seguido por
uma ou mais letras maiúsculas, seguidas por
uma ou mais letras minúsculas
você pode usar a seguinte expressão regular compatível com Perl:
onde:
.corresponde a qualquer caractere único.[A-Z]+corresponde a uma ou mais letras maiúsculas.[a-z]+corresponde a uma ou mais letras minúsculas.
+ é um quantificador que especifica que um ou mais dos caracteres anteriores precisam corresponder.
Por exemplo, a expressão regular acima corresponde a sequências de caracteres como:
1Stock@SFComputing%Fn
Em uma cláusula MATCH_RECOGNIZE, você usa uma expressão semelhante para especificar o padrão de linhas a corresponder. Neste caso, encontrar linhas que correspondam a um padrão “V” envolve encontrar uma sequência de linhas que inclua:
a linha antes que o preço das ações diminua, seguida por
uma ou mais linhas onde o preço das ações diminui, seguidas por
uma ou mais linhas onde o preço das ações aumenta
Você pode expressar isso como o seguinte padrão de linhas:
Os padrões de linhas consistem em variáveis de padrão, quantificadores (que são similares aos usados em expressões regulares), e operadores. Uma variável de padrão define uma expressão que é avaliada em relação a uma linha.
Neste padrão de linhas:
row_before_decreaserow_with_price_decreaseerow_with_price_increasesão variáveis de padrão. As expressões para estas variáveis de padrão precisam ser avaliadas como:qualquer linha (a linha antes que o preço das ações diminua)
uma linha onde o preço das ações diminui
uma linha onde o preço das ações aumenta
row_before_decreaseé semelhante a.em uma expressão regular. Na expressão regular a seguir,.corresponde a qualquer caractere único que apareça antes da primeira letra maiúscula no padrão.Da mesma forma, no padrão de linhas,
row_before_decreasecorresponde a qualquer linha única que apareça antes da primeira linha com uma redução de preço.Os quantificadores
+apósrow_with_price_decreaseerow_with_price_increaseespecificam que uma ou mais linhas de cada um deles devem coincidir.
Em uma cláusula MATCH_RECOGNIZE, você usa a subcláusula PATTERN para especificar o padrão de linhas a atender:
Para especificar as expressões para as variáveis de padrão, você usa a subcláusula DEFINE:
onde:
row_before_decreasenão precisa ser definido aqui porque deve ser avaliado para qualquer linha.row_with_price_decreaseé definido como uma expressão para uma linha com uma redução de preço.row_with_price_increaseé definido como uma expressão para uma linha com um aumento de preço.
Para comparar os preços em diferentes linhas, as definições dessas variáveis usam a função de navegação LAG() para especificar o preço para a linha anterior.
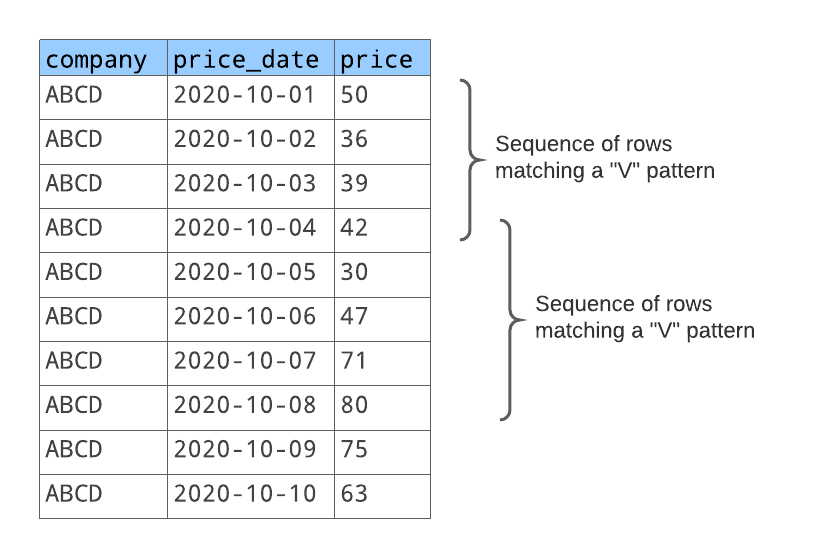
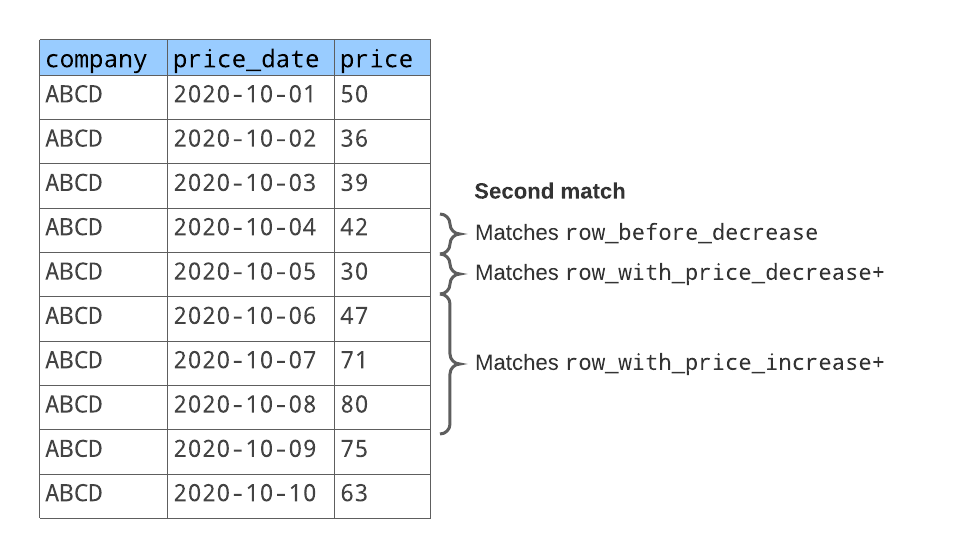
O padrão das linhas corresponde a duas sequências de linhas, como ilustrado abaixo:

Para a primeira sequência de linhas correspondente:
row_before_decreasecorresponde à linha com o preço de ação50.row_with_price_decreasecorresponde à linha seguinte com o preço de ação36.row_with_price_increasecorresponde às duas linhas seguintes com os preços de ações39e42.
Para a segunda sequência de linhas correspondente:
row_before_decreasecorresponde à linha com o preço de ação42. (Esta é a mesma linha que se encontra no final da primeira sequência de linhas correspondente).row_with_price_decreasecorresponde à linha seguinte com o preço de ação30.row_with_price_increasecorresponde às duas linhas seguintes com os preços de ações47,71e80.
Etapa 3: Especificação das linhas a retornar¶
MATCH_RECOGNIZE pode retornar:
uma única linha que resume cada sequência correspondente, ou
cada linha em cada sequência correspondente
Para este exemplo, você deseja retornar um resumo de cada sequência correspondente. Use a subcláusula ONE ROW PER MATCH para especificar que uma única linha deve ser devolvida para cada sequência correspondente.
Etapa 4: Especificação das medidas a selecionar¶
Quando você usa ONE ROW PER MATCH, MATCH_RECOGNIZE não retorna nenhuma das colunas da tabela (exceto a coluna especificada por PARTITION BY), mesmo quando MATCH_RECOGNIZE está em uma instrução SELECT *. Para especificar os dados a serem retornados por esta instrução, você precisa definir medidas. As medidas são colunas adicionais de dados calculadas para cada sequência de linhas correspondente (por exemplo, a data de início da sequência, a data final da sequência, o número de dias na sequência, etc.).
Use a subcláusula MEASURES para especificar estas colunas adicionais a retornar na saída. O formato geral para definir uma medida é:
onde:
expressionespecifica as informações sobre a sequência que você deseja retornar. Para a expressão, você pode usar funções com colunas da tabela e variáveis de padrão que você definiu anteriormente.column_nameespecifica o nome da coluna que será retornada na saída.
Para este exemplo, você pode definir as seguintes medidas:
Um número que identifica a sequência (a primeira sequência correspondente, a segunda sequência correspondente, etc.).
Para esta medida, use a função
MATCH_NUMBER(), que retorna o número da correspondência. Os números começam com1para a primeira correspondência de uma partição de linhas. Se houver várias partições, o número começa com1para cada partição.O dia anterior à redução do preço das ações.
Para esta medida, use a função
FIRST(), que retorna o valor da expressão para a primeira linha na sequência correspondente. Neste exemplo,FIRST(price_date)retorna o valor da colunaprice_datena primeira linha em cada sequência correspondente, que é a data antes do preço da ação ter diminuído.O último dia em que o preço das ações aumentou.
Para esta medida, use a função
LAST(), que retorna o valor da expressão para a última linha na sequência correspondente.O número de dias no padrão “V”.
Para esta medida, use
COUNT(*). Como você está especificandoCOUNT(*)na definição de uma medida, o asterisco (*) especifica que você quer contar todas as linhas em uma sequência correspondente (não todas as linhas da tabela).O número de dias em que a ação diminuiu.
Para esta medida, use
COUNT(row_with_price_decrease.*). O período seguido por um asterisco (.*) especifica que você deseja contar todas as linhas em uma sequência correspondente que corresponda à variável de padrãorow_with_price_decrease.O número de dias em que a ação aumentou.
Para esta medida, use
COUNT(row_with_price_increase.*).
A seguir está a subcláusula MEASURES que define as medidas acima:
Veja a seguir um exemplo da produção com as medidas selecionadas:
Como mencionado anteriormente, a saída inclui a coluna company porque a cláusula PARTITION BY especifica essa coluna.
Etapa 5: Especificação de onde continuar a encontrar a próxima correspondência¶
Após encontrar uma sequência de linhas correspondente, MATCH_RECOGNIZE continua a encontrar a próxima sequência correspondente. Você pode especificar onde MATCH_RECOGNIZE deve começar a pesquisar pela próxima sequência correspondente.
Como mostrado na ilustração de sequências correspondentes, uma linha pode ser parte de mais de uma sequência correspondente. Neste exemplo, a linha para 2020-10-04 faz parte de dois padrões em “V”.
Para este exemplo, para encontrar a próxima sequência correspondente, você pode começar de uma linha onde o preço aumentou. Para especificar isto na cláusula MATCH_RECOGNIZE, use AFTER MATCH SKIP:
onde TO LAST row_with_price_increase especifica que você quer começar a pesquisar na última linha onde o preço aumentou.
Partição e classificação das linhas¶
O primeiro passo para identificar padrões em linhas é ordená-las de forma a encontrar seus padrões. Por exemplo, se você quiser encontrar um padrão de alterações nos preços das ações ao longo do tempo para as ações de cada empresa:
Divida as linhas por empresa, para que você possa pesquisar os preços de ações de cada empresa.
Ordene as linhas em cada partição por data, para que você possa encontrar alterações no preço das ações de uma empresa ao longo do tempo.
Para particionar os dados e especificar a ordem das linhas, use as subcláusulas PARTITION BY e ORDER BY em MATCH_RECOGNIZE. Por exemplo:
(A cláusula PARTITION BY para MATCH_RECOGNIZE funciona da mesma forma que a cláusula PARTITION BY para funções de janela).
Um benefício adicional do particionamento é que ele pode tirar proveito do processamento paralelo.
Definição do padrão de linhas a atender¶
Com MATCH_RECOGNIZE, você pode encontrar uma sequência de linhas que correspondem a um padrão. Você especifica este padrão em termos de linhas que correspondem a condições específicas.
No exemplo da tabela de preços diários de ações para diferentes empresas, suponha que você queira encontrar uma sequência de três linhas na qual:
Em um determinado dia, o preço das ações de uma empresa é inferior a 45,00.
No dia seguinte, o preço das ações diminui em pelo menos 10%.
No outro dia, o preço das ações aumenta em pelo menos 3%.
Para encontrar essa sequência, você especifica um padrão que corresponde a três linhas com as seguintes condições:
Na primeira linha da sequência, o valor da coluna
pricedeve ser inferior a 45,00.Na segunda linha, o valor da coluna
pricedeve ser menor ou igual a 90% do valor da linha anterior.Na terceira linha, o valor da coluna
pricedeve ser maior ou igual a 105% do valor da linha anterior.
A segunda e terceira linhas têm condições que exigem uma comparação entre os valores das colunas em diferentes linhas. Para comparar o valor em uma linha com o valor na linha anterior ou seguinte, use as funções LAG() ou LEAD():
LAG(column)retorna o valor decolumnna linha anterior.LEAD(column)retorna o valor decolumnna linha seguinte.
Para este exemplo, é possível especificar as condições para as três linhas como:
A primeira linha da sequência deve ter
price < 45.00.A segunda linha deve ter
LAG(price) * 0.90 >= price.A terceira linha deve ter
LAG(price) * 1.05 <= price.
Ao especificar o padrão para a sequência dessas três linhas, você usa uma variável de padrão para cada linha que tem uma condição diferente. Use a subcláusula DEFINE para definir cada variável de padrão como uma linha que deve atender a uma condição especificada. O exemplo a seguir define três variáveis de padrão para as três linhas:
Para definir o próprio padrão, use a subcláusula PATTERN. Nessa subcláusula, use uma expressão regular para especificar o padrão a atender. Para os blocos de construção da expressão, use as variáveis de padrão que você definiu. Por exemplo, o seguinte padrão encontra a sequência de três linhas:
A instrução SQL abaixo usa as subcláusulas DEFINE e PATTERN mostradas acima:
As próximas seções explicam como definir padrões que correspondem a números específicos de linhas e linhas que aparecem no início ou no final de uma partição.
Nota
MATCH_RECOGNIZE usa rastreamento inverso para atender padrões. Como é o caso de outros mecanismos de expressão regular que usam rastreamento inverso, algumas combinações de padrões e dados para correspondência podem levar muito tempo para serem executadas, o que pode resultar em altos custos de computação.
Para melhorar o desempenho, defina um padrão que seja o mais específico possível:
Certifique-se de que cada linha corresponda apenas a um símbolo ou a um pequeno número de símbolos
Evite usar símbolos que façam correspondência a cada linha (por exemplo, símbolos que não estejam na cláusula
DEFINEou símbolos que sejam definidos como verdadeiro)Defina um limite superior para quantificadores (por exemplo,
{,10}em vez de*).
Por exemplo, o seguinte padrão pode resultar em aumento de custos se nenhuma linha corresponder:
Se houver um limite superior para o número de linhas que você deseja fazer a correspondência, você pode especificar esse limite nos quantificadores para melhorar o desempenho. Além disso, em vez de especificar que você deseja encontrar any_symbol depois de symbol1, você pode procurar uma linha que não seja symbol1 (not_symbol1, neste exemplo);
Em geral, você deve monitorar o tempo de execução da consulta para verificar se ela não está demorando mais do que o esperado.
Uso de quantificadores com variáveis de padrão¶
Na subcláusula PATTERN, você usa uma expressão regular para especificar um padrão de linhas a corresponder. Você usa variáveis de padrão para identificar linhas na sequência que atendam a condições específicas.
Se precisar corresponder várias linhas que atendam a uma condição específica, você pode usar um quantificador, como faria em uma expressão regular.
Por exemplo, você pode usar o quantificador + para especificar que o padrão precisa incluir uma ou mais linhas nas quais o preço da ação diminui 10%, seguida por uma ou mais linhas nas quais o preço da ação aumenta 5%:
Correspondência de padrões relativos ao início ou ao fim de uma partição¶
Para encontrar uma sequência de linhas relativas ao início ou ao fim de uma partição, pode-se usar os metacaracteres ^ e $ na subcláusula PATTERN. Esses metacaracteres em um padrão de linha têm um propósito semelhante que os mesmos metacaracteres têm em uma expressão regular:
^representa o início de uma partição.$representa o fim de uma partição.
O padrão a seguir corresponde a uma ação com preço maior que 75,00 no início da partição:
Observe que ^ e $ especificam as posições e não representam as linhas nessas posições (muito parecido com ^ e $ em uma expressão regular especificando a posição e não os caracteres nessas posições). Em PATTERN (^ GT75), a primeira linha (não a segunda) deve ter um preço superior a 75,00. Em PATTERN (GT75 $), a última linha (não a penúltima) deve ser maior que 75.
Aqui está um exemplo completo com ^. Observe que embora o estoque XYZ tenha um preço superior a 60,00 em mais de uma linha nesta partição, somente a linha no início da partição é considerada uma correspondência.
Aqui está um exemplo completo com $. Observe que, embora a ação ABCD tenha um preço superior a 50,00 em mais de uma linha nesta partição, somente a linha no final da partição é considerada uma correspondência.
Especificação de linhas da saída¶
Instruções que utilizam MATCH_RECOGNIZE podem escolher quais linhas produzir.
Geração de uma linha vs. geração de todas as linhas para cada correspondência¶
Quando MATCH_RECOGNIZE encontra uma correspondência, a saída pode ser uma linha de resumo para toda a correspondência ou uma linha para cada ponto de dados no padrão.
ALL ROWS PER MATCHespecifica que a saída inclui todas as linhas na correspondência.ONE ROW PER MATCHespecifica que a saída inclui apenas uma linha para cada correspondência em cada partição.A cláusula de projeção da instrução SELECT pode usar apenas a saída da instrução
MATCH_RECOGNIZE. Com efeito, isto significa que a instrução SELECT só pode usar colunas das seguintes subcláusulas deMATCH_RECOGNIZE:A subcláusula
PARTITION BY.Todas as linhas em uma correspondência são da mesma partição e, portanto, têm o mesmo valor para as expressões da subcláusula
PARTITION BY.A cláusula
MEASURES.Quando você usa
MATCH_RECOGNIZE ... ONE ROW PER MATCH, a subcláusulaMEASURESgera não apenas expressões que retornam o mesmo valor para todas as linhas na correspondência (por exemplo,MATCH_NUMBER()), mas também expressões que podem retornar valores diferentes para linhas diferentes na correspondência (por exemplo,MATCH_SEQUENCE_NUMBER()). Se você usa expressões que podem retornar valores diferentes para linhas diferentes na correspondência, a saída não é determinística.
Se você está familiarizado com funções agregadas e
GROUP BY, a seguinte analogia pode ser útil na compreensão deONE ROW PER MATCH:A cláusula
PARTITION BYemMATCH_RECOGNIZEagrupa os dados de forma semelhante à forma comoGROUP BYagrupa os dados em umSELECT.A cláusula
MEASURESem umMATCH_RECOGNIZE ... ONE ROW PER MATCHpermite funções agregadas, tais comoCOUNT(), que retornam o mesmo valor para cada linha da correspondência, como fazMATCH_NUMBER().
Se você usar apenas funções agregadas e expressões que retornam o mesmo valor para cada linha da correspondência, então
... ONE ROW PER MATCHse comporta de forma semelhante aGROUP BYe funções agregadas.
O padrão é ONE ROW PER MATCH.
Os exemplos a seguir mostram a diferença nas saídas entre ONE ROW PER MATCH e ALL ROWS PER MATCH. Estes dois exemplos de código são quase idênticos, exceto pela cláusula ...ROW(S) PER MATCH. (Em um uso típico, uma instrução SQL com ONE ROW PER MATCH tem subcláusulas MEASURES diferentes de uma instrução SQL com ALL ROWS PER MATCH).
Exclusão de linhas da saída¶
Para algumas consultas, você pode querer incluir apenas parte do padrão na saída. Por exemplo, você pode querer encontrar padrões em que as ações subiram muitos dias seguidos, mas exibir apenas os picos e algumas informações resumidas (por exemplo, o número de dias de aumento de preços antes de cada pico).
Você pode usar uma sintaxe de exclusão no padrão para dizer a MATCH_RECOGNIZE para pesquisar uma determinada variável de padrão sem incluí-la na saída. Para incluir uma variável de padrão como parte do padrão a ser pesquisado, mas não como parte da saída, use a notação {- <variável_de_padrão> -}.
Aqui está um exemplo simples que mostra a diferença entre utilizar a sintaxe de exclusão e não utilizá-la. Este exemplo contém duas consultas, cada uma das quais pesquisa um preço de estoque que começou em menos de $45, depois diminuiu e depois aumentou. A primeira consulta não usa sintaxe de exclusão e, portanto, mostra todas as linhas. A segunda consulta usa a sintaxe de exclusão e não mostra o dia em que o preço das ações caiu.
O próximo exemplo é mais realista. Ele pesquisa padrões em que o preço de uma ação subiu um ou mais dias seguidos, e depois caiu um ou mais dias seguidos. Como a saída pode ser bastante grande, ele usa a exclusão para mostrar apenas o primeiro dia em que a ação subiu (se subiu mais de um dia seguido) e apenas o primeiro dia em que caiu (se caiu mais de um dia seguido). O padrão é mostrado abaixo:
Este padrão pesquisa os seguintes eventos em ordem:
Um preço inicial inferior a 45.
Um UP, possivelmente seguido imediatamente por outros que não estão incluídos na saída.
Um DOWN, possivelmente seguido imediatamente por outros que não estão incluídos na saída.
Aqui estão o código e a saída para versões do padrão anterior sem exclusão e com exclusão:
Retorno de informações sobre a correspondência¶
Informações básicas sobre correspondências¶
Em muitos casos, você deseja que sua consulta liste não apenas informações da tabela que contém os dados, mas também informações sobre os padrões que foram encontrados. Quando você quer informações sobre as próprias correspondências, especifica essas informações na cláusula MEASURES.
A cláusula MEASURES pode incluir as seguintes funções, que são específicas de MATCH_RECOGNIZE:
MATCH_NUMBER(): Cada vez que uma partida é encontrada, é atribuído a ela um número de correspondência sequencial, começando em um. Esta função retorna o número de correspondência.MATCH_SEQUENCE_NUMBER(): Como um padrão geralmente envolve mais de um ponto de dados, você pode querer saber qual ponto de dados está associado a cada valor da tabela. Esta função retorna o número sequencial do ponto de dados dentro da correspondência.CLASSIFIER(): O classificador é o nome da variável de padrão à qual a linha corresponde.
A consulta abaixo inclui uma cláusula MEASURES com o número da correspondência, o número da sequência da correspondência e o classificador.
A subcláusula MEASURES pode produzir muito mais informações do que isso. Para obter mais detalhes, consulte a documentação de referência de MATCH_RECOGNIZE.
Janelas, quadros de janela e funções de navegação¶
A cláusula MATCH_RECOGNIZE opera em uma “janela” de linhas. Se MATCH_RECOGNIZE contiver uma subcláusula PARTITION, então cada partição é uma janela. Se não houver subcláusula PARTITION, então toda a entrada é uma única janela.
A subcláusula PATTERN de MATCH_RECOGNIZE especifica os símbolos da esquerda para a direita. Por exemplo:
Se você imaginar os dados como uma sequência de linhas em ordem crescente da esquerda para a direita, pode pensar em MATCH_RECOGNIZE como se movendo para a direita (por exemplo, da data mais antiga para a data mais recente no exemplo do preço de ações), pesquisando por um padrão nas linhas dentro de cada janela.
MATCH_RECOGNIZE começa com a primeira linha na janela e verifica se essa linha e as linhas subsequentes correspondem ao padrão.
No caso mais simples, depois de determinar se há uma correspondência de padrão começando na primeira linha da janela, MATCH_RECOGNIZE move-se para a direita uma linha e repete o processo, verificando se a segunda linha é o início de uma ocorrência do padrão. MATCH_RECOGNIZE continua se movendo para a direita até chegar ao final da janela.
(MATCH_RECOGNIZE pode mover-se para a direita por mais de uma linha. Por exemplo, você pode dizer a MATCH_RECOGNIZE para começar a pesquisar o próximo padrão após o final do padrão atual).
Imagine isso como se houvesse um “quadro” movendo-se para a direita dentro da janela. A borda esquerda desse quadro está na primeira linha do conjunto de linhas que estão sendo verificadas para uma correspondência. A borda direita do quadro não é definida até que uma correspondência seja encontrada; quando isso acontece, a borda direita do quadro é a última linha da correspondência. Por exemplo, se o padrão de pesquisa fosse pattern (start down up), então a linha que corresponde a up é a última linha antes da borda direita do quadro.
(Se não for encontrada nenhuma correspondência, então a borda direita do quadro nunca é definida e nunca é referenciada).
Em casos simples, você pode imaginar um quadro de janela deslizante, como ilustrado abaixo:
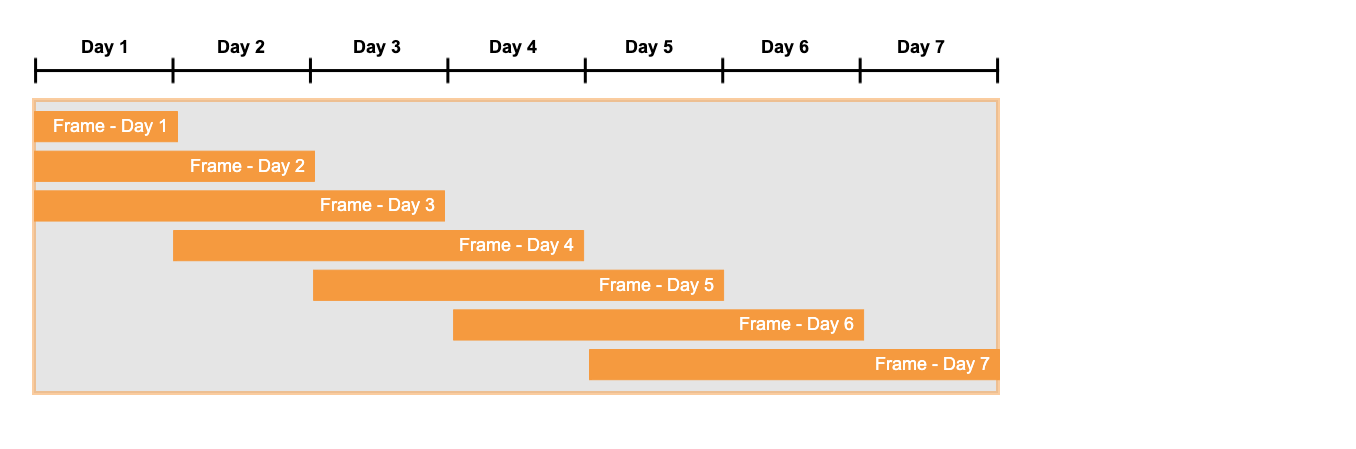
Você já viu funções de navegação tais como LAG() utilizadas em expressões na subcláusula DEFINE (por exemplo, DEFINE down_10_percent as LAG(price) * 0.9 >= price). A consulta a seguir mostra que as funções de navegação também podem ser usadas na subcláusula MEASURES. Neste exemplo, as funções de navegação mostram as bordas (e portanto o tamanho) do quadro da janela que contém a correspondência atual.
Cada linha de saída desta consulta inclui os valores das funções de navegação LAG(), LEAD(), FIRST(), e LAST() para aquela linha. O tamanho do quadro da janela é o número de linhas entre FIRST() e LAST(), incluindo a primeira e a última linhas propriamente ditas.
As cláusulas DEFINE e PATTERN na consulta abaixo selecionam grupos de três linhas (1-3 de outubro, 2-4 de outubro, 3-5 de outubro, etc.).
A saída desta consulta também mostra que as funções LAG() e LEAD() retornam NULL para expressões que tentam referenciar linhas fora do grupo de correspondência (ou seja, fora do quadro da janela).
As regras para funções de navegação nas cláusulas DEFINE são ligeiramente diferentes das regras para funções de navegação nas cláusulas MEASURES. Por exemplo, a função PREV() está disponível na cláusula MEASURES, mas atualmente não está na cláusula DEFINE. Em vez disso, você pode usar LAG() na cláusula DEFINE. A documentação de referência para MATCH_RECOGNIZE lista a regra correspondente para cada função de navegação.
A subcláusula MEASURES também pode incluir o seguinte:
Funções agregadas. Por exemplo, se o padrão pode corresponder a um número variável de linhas (por exemplo, porque corresponde a 1 ou mais preços de ações em queda), você pode querer saber o número total de linhas na correspondência; para isso, use
COUNT(*).Expressões gerais que operam sobre valores em cada linha da correspondência. Elas podem ser expressões matemáticas, expressões lógicas, etc. Por exemplo, você pode observar valores na linha e imprimir descritores de texto tais como “ABOVE AVERAGE“.
Lembre-se de que, se você agrupar linhas (
ONE ROW PER MATCH) e se uma coluna tiver valores diferentes para linhas diferentes no grupo, o valor selecionado para aquela coluna e para aquela correspondência é não determinístico, e expressões baseadas naquele valor provavelmente também são não determinísticas.
Para obter mais informações sobre a subcláusula MEASURES, consulte a documentação de referência para MATCH_RECOGNIZE.
Especificação de onde pesquisar a próxima correspondência¶
Por padrão, após MATCH_RECOGNIZE encontrar uma correspondência, ele começa a procurar a próxima imediatamente após o final da correspondência mais recente. Por exemplo, se MATCH_RECOGNIZE encontrar uma correspondência nas linhas 2, 3 e 4, então MATCH_RECOGNIZE começará a procurar a próxima correspondência na linha 5. Isto evita a sobreposição de correspondências.
No entanto, você pode escolher pontos de partida alternativos.
Considere os seguintes dados:
Suponha que você pesquise os dados de um padrão W (para baixo, para cima, para baixo e para cima). Existem três formas W:
Meses: 1, 2, 3, 4 e 5.
Meses: 3, 4, 5, 6 e 7.
Meses: 5, 6, 7, 8 e 9.
Você pode usar a cláusula SKIP para especificar se deseja todos os padrões ou apenas os padrões não sobrepostos. A cláusula SKIP também aceita outras opções. A cláusula SKIP está documentada com mais detalhes em MATCH_RECOGNIZE.
Práticas recomendadas¶
Inclua uma cláusula ORDER BY em sua cláusula
MATCH_RECOGNIZE.Lembre-se de que este ORDER BY se aplica somente dentro da cláusula
MATCH_RECOGNIZE. Se você quiser que toda a consulta retorne resultados em uma ordem específica, então use uma cláusulaORDER BYadicional no nível mais externo da consulta.
Nomes de variáveis de padrão:
Use nomes de variável significativos para tornar seus padrões mais fáceis de entender e depurar.
Verifique erros ortográficos nos nomes das variáveis de padrão nas cláusulas
PATTERNeDEFINE.
Evite usar padrões para subcláusulas que tenham padrões. Torne suas escolhas explícitas.
Teste seu padrão com uma pequena amostra de dados antes de escalar para seu conjunto de dados completo.
MATCH_NUMBER(),MATCH_SEQUENCE_NUMBER()eCLASSIFIER()são muito úteis na depuração.Considere o uso de uma cláusula
ORDER BYno nível mais externo da consulta para forçar a saída a estar na ordem usandoMATCH_NUMBER()eMATCH_SEQUENCE_NUMBER(). Se os dados de saída estiverem em outra ordem, então a saída pode não parecer corresponder ao padrão.
Como evitar erros analíticos¶
Correlação vs. causalidade¶
A correlação não garante a causalidade. MATCH_RECOGNIZE pode retornar “falsos positivos” (casos em que você vê um padrão onde há apenas uma coincidência).
A correspondência de padrões também pode resultar em “falsos negativos” (casos em que há um padrão no mundo real, mas o padrão não aparece na amostra de dados).
Na maioria dos casos, encontrar uma correspondência (por exemplo, encontrar um padrão que sugere uma fraude de seguro) é apenas o primeiro passo de uma análise.
Os seguintes fatores normalmente aumentam o número de falsos positivos:
Grandes conjuntos de dados.
Pesquisar um grande número de padrões.
Pesquisar padrões curtos ou simples.
Os seguintes fatores normalmente aumentam o número de falsos negativos.
Pequenos conjuntos de dados.
Não pesquisar todos os padrões relevantes possíveis.
Pesquisar padrões mais complexos do que o necessário.
Padrões que não diferenciam a ordem¶
Embora a maior parte da correspondência de padrões exija que os dados estejam em ordem (por exemplo, por hora), há exceções. Por exemplo, se uma pessoa comete uma fraude de seguro tanto em um acidente de automóvel como em um arrombamento em casa, não importa em que ordem as fraudes ocorrem.
Se o padrão que você está procurando não é afetado pela ordem, você pode usar operadores como “alternativa” (|) e PERMUTE para tornar suas pesquisas menos sujeitas à ordem.
Exemplos¶
Esta seção contém exemplos adicionais.
Você pode encontrar ainda mais exemplos em MATCH_RECOGNIZE.
Encontrar aumentos de preços em vários dias¶
A seguinte consulta encontra todos os padrões em que o preço da empresa ABCD subiu dois dias seguidos:
Demonstrar o operador PERMUTE¶
Este exemplo demonstra o operador PERMUTE no padrão. Pesquise todos os picos de aumento e redução nos gráficos limitando a dois o número de aumentos de preços:
Demonstrar a opção SKIP TO NEXT ROW¶
Este exemplo demonstra a opção SKIP TO NEXT ROW. Esta consulta pesquisa curvas em forma de W no gráfico de cada empresa. As correspondências podem se sobrepor.
Sintaxe de exclusão¶
Este exemplo mostra a sintaxe de exclusão no padrão. Este padrão (como o padrão anterior) pesquisa formas W, mas a saída desta consulta exclui preços em queda. Note que, nesta consulta, a correspondência continua depois da última linha de uma correspondência:
Pesquisa de padrões em linhas não adjacentes¶
Em algumas situações, você pode querer procurar padrões em linhas não contíguas. Por exemplo, se estiver analisando arquivos de log, você pode querer pesquisar todos os padrões nos quais um erro fatal foi precedido por uma sequência particular de avisos. Pode não haver uma forma natural de dividir e classificar as linhas de modo que todas as mensagens relevantes (linhas) fiquem em uma única janela e adjacentes. Nessa situação, você pode precisar de um padrão que procure eventos específicos, mas não exija que os eventos sejam contíguos nos dados.
Abaixo está um exemplo de cláusulas DEFINE e PATTERN que reconhecem linhas contíguas ou não contíguas que se encaixam no padrão. O símbolo ANY_ROW é definido como TRUE (portanto, corresponde a qualquer linha). O * após cada ocorrência de ANY_ROW diz para permitir 0 ou mais ocorrências de ANY_ROW entre o primeiro e o segundo aviso, e entre o segundo aviso e a mensagem de registro de erros fatais. Assim, todo o padrão diz para pesquisar WARNING1, seguido por qualquer número de linhas, seguido por WARNING2, seguido por qualquer número de linhas, seguido por FATAL_ERROR. Para omitir as linhas irrelevantes da saída, a consulta usa sintaxe de exclusão ({- e -}).
Solução de problemas¶
Erros no uso de ONE ROW PER MATCH e na especificação de colunas na cláusula de seleção¶
A cláusula ONE ROW PER MATCH atua de forma semelhante a uma função agregada. Isso limita as colunas de saída que você pode usar. Por exemplo, se você usa ONE ROW PER MATCH e cada correspondência contém três linhas com datas diferentes, então você não pode especificar a coluna de data como uma coluna de saída na cláusula SELECT porque nenhuma data única é correta para todas as três linhas.
Resultados inesperados¶
Verifique se há erros ortográficos nas cláusulas
PATTERNeDEFINE.Se um nome de variável de padrão usado na cláusula
PATTERNnão estiver definido na cláusulaDEFINE(por exemplo, porque o nome foi digitado incorretamente na cláusulaPATTERNouDEFINE), então nenhum erro será relatado. Ao invés disso, o nome da variável de padrão é simplesmente considerado como verdadeiro para cada linha.Revise a cláusula
SKIPpara ter certeza de que é apropriado, por exemplo, incluir ou excluir padrões sobrepostos.