Visão geral do conector do Spark¶
O Conector do Snowflake para Spark permite usar o Snowflake como uma fonte de dados do Apache Spark, semelhante a outras fontes de dados (PostgreSQL, HDFS, S3, etc.).
Neste tópico:
Nota
Como alternativa ao uso do Spark, considere escrever seu código para usar Snowpark API em seu lugar. O Snowpark permite realizar todo o seu trabalho dentro do Snowflake (em vez de em um cluster de computação Spark separado). O Snowpark também suporta o pushdown de todas as operações, incluindo UDFs do Snowflake.
Interação entre o Snowflake e o Spark¶
O conector suporta a movimentação de dados bidirecional entre um cluster do Snowflake e um cluster do Spark. O cluster do Spark pode ser auto-hospedado ou acessado através de outro serviço, como o Qubole, AWS EMR ou Databricks.
Usando o conector, você pode realizar as seguintes operações:
Preencher um Spark DataFrame a partir de uma tabela (ou consulta) do Snowflake.
Gravar o conteúdo de um Spark DataFrame em uma tabela do Snowflake.
O conector usa Scala 2.12.x ou 2.13.x para realizar estas operações e usa o driver Snowflake JDBC para se comunicar com o Snowflake.
Nota
O Conector Snowflake para Spark não é estritamente necessário para conectar o Snowflake e o Apache Spark; outros drivers JDBC de terceiros podem ser usados. Entretanto, recomendamos o uso do Conector do Snowflake para Spark porque o conector, em conjunto com o driver Snowflake JDBC, foi otimizado para a transferência de grandes quantidades de dados entre os dois sistemas. Ele também proporciona um melhor desempenho ao apoiar o pushdown de consultas do Spark para o Snowflake.
Transferência de dados¶
O Conector do Snowflake para Spark suporta dois modos de transferência:
A transferência interna utiliza um local temporário criado e administrado internamente/transparentemente pelo Snowflake.
A transferência externa utiliza um local de armazenamento, geralmente temporário, criado e gerenciado pelo usuário.
Dica
Use a transferência de dados externa se uma das seguintes opções for verdadeira:
Você está usando a versão 2.1.x ou inferior do conector Spark (que não suporta transferência interna).
Sua transferência provavelmente levará 36 horas ou mais (a transferência interna usa credenciais temporárias que expiram após 36 horas).
Caso contrário, nós recomendamos usar a transferência de dados interna.
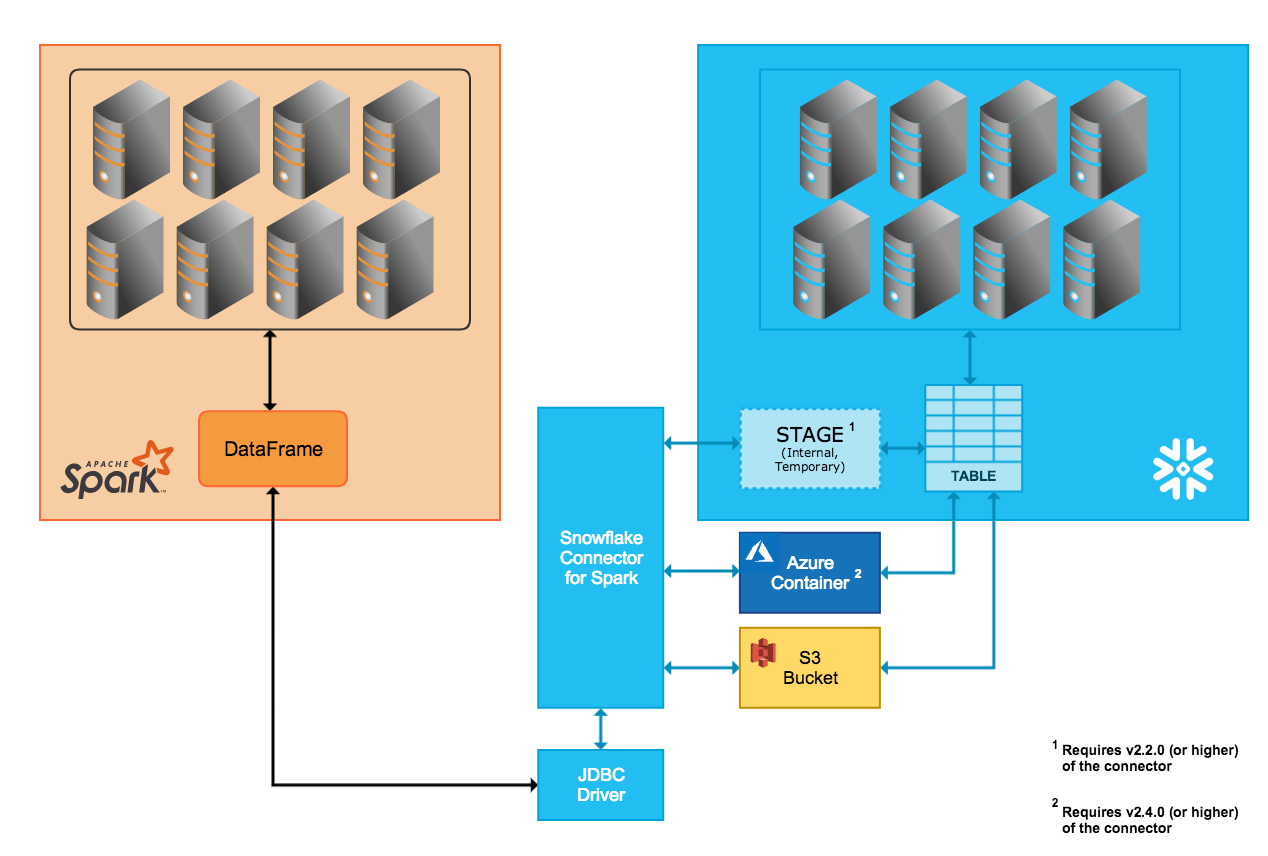
Transferência de dados interna¶
A transferência de dados entre os dois sistemas é facilitada através de um estágio interno do Snowflake que o conector cria e gerencia automaticamente:
Ao conectar-se ao Snowflake e iniciar uma sessão no Snowflake, o conector cria o estágio interno.
Durante toda a duração da sessão do Snowflake, o conector utiliza o estágio para armazenar dados enquanto os transfere para seu destino.
Ao final da sessão do Snowflake, o conector descarta o estágio, removendo assim todos os dados temporários do estágio.
Note que o suporte para transferência interna requer uma versão específica (ou superior) do conector, baseada na plataforma de nuvem para sua conta Snowflake:
- AWS:
O modo de transferência interna de dados tem suporte somente na versão 2.2.0 (e superior) do conector.
- Azure:
O modo de transferência interna de dados tem suporte somente na versão 2.4.0 (e superior) do conector.
- GCP:
O modo de transferência interna de dados tem suporte somente na versão 2.7.0 (e superior) do conector.
Transferência de dados externa¶
A transferência de dados entre os dois sistemas é facilitada através de um local de armazenamento que o usuário especifica e arquivos criados automaticamente pelo conector:
- AWS:
Os arquivos de transferência de dados são criados e armazenados em um bucket S3.
- Azure:
Os arquivos de transferência de dados são criados e armazenados em um contêiner de armazenamento de blobs. A transferência externa via Azure tem suporte somente na versão 2.4.0 (e superior) do conector.
O(s) parâmetro(s) para especificar o local de armazenamento está(ão) documentado(s) em Definição das opções de configuração para o conector:
Nota
Para a transferência de dados externa, o local de armazenamento deve ser criado e configurado como parte da instalação/configuração do conector Spark.
Além disso, os arquivos criados pelo conector durante a transferência externa destinam-se a ser temporários, mas o conector não exclui automaticamente os arquivos do local de armazenamento. Para excluir os arquivos, use qualquer um dos seguintes métodos:
Exclua-os manualmente.
Defina o parâmetro
purgepara o conector. Para obter mais informações sobre este parâmetro, consulte Definição das opções de configuração para o conector.Defina um parâmetro do sistema de armazenamento, como o parâmetro de política de ciclo de vida do Amazon S3, para limpar os arquivos após a transferência ser feita.
Mapeamento de colunas¶
Quando você copia dados de uma tabela do Spark para uma tabela do Snowflake, se os nomes das colunas não corresponderem você pode mapear os nomes das colunas do Spark para o Snowflake usando o parâmetro columnmapping, que está documentado em Definição das opções de configuração para o conector.
Nota
O mapeamento de colunas tem suporte apenas para transferência interna de dados.
Pushdown de consultas¶
Para um desempenho ideal, você normalmente quer evitar a leitura de muitos dados ou a transferência de grandes resultados intermediários entre sistemas. Idealmente, a maior parte do processamento deveria acontecer perto do local onde os dados são armazenados para aproveitar as capacidades dos armazenamentos participantes e eliminar dinamicamente os dados que não são necessários.
O pushdown de consultas alavanca estas eficiências de desempenho, permitindo que grandes e complexos planos lógicos do Spark (em sua totalidade ou em parte) sejam processados no Snowflake, usando assim o Snowflake para fazer a maior parte do trabalho real.
O pushdown de consultas tem suporte na versão 2.1.0 (e superior) do Conector do Snowflake para Spark.
O pushdown não é possível em todas as situações. Por exemplo, UDFs do Spark não podem ser enviadas para o Snowflake. Consulte Pushdown para a lista de operações com suporte para o pushdown.
Nota
Se você precisar de pushdown para todas as operações, considere escrever seu código para usar Snowpark API em seu lugar. O Snowpark também suporta o pushdown de UDFs do Snowflake.
Integração do Databricks¶
O Databricks integrou o Conector do Snowflake para Spark no Databricks Unified Analytics Platform para fornecer conectividade nativa entre o Spark e o Snowflake.
Para obter mais detalhes, incluindo exemplos de código usando Scala e Python, consulte Fontes de dados – Snowflake (na documentação do Databricks) ou Configuração do Snowflake para Spark no Databricks.
Integração do Qubole¶
O Qubole integrou o Conector do Snowflake para Spark no ecossistema Qubole Data Service (QDS) para fornecer conectividade nativa entre o Spark e o Snowflake. Através desta integração, o Snowflake pode ser adicionado como um armazenamento de dados do Spark diretamente no Qubole.
Uma vez que o Snowflake tenha sido adicionado como um armazenamento de dados do Spark, os engenheiros e cientistas de dados podem usar o Spark e QDS UI, API e Notebooks para:
Realizar transformações avançadas de dados, tais como preparar e consolidar fontes de dados externas no Snowflake ou refinar e transformar os dados do Snowflake.
Construir, treinar e executar modelos de aprendizado de máquina e AI no Spark usando os dados já existentes no Snowflake.
Para obter mais detalhes, consulte o Guia de integração Qubole-Snowflake (na documentação do Qubole) ou Configuração do Snowflake para Spark no Qubole.