ML Lineage: ML-Datenfluss verfolgen¶
Bemerkung
ML Lineage ist im Paket snowflake-ml-python in der Version 1.6.0 und höher verfügbar.
ML Lineage bietet eine umfassende Ablaufverfolgung der Daten, während sie durch Ihre Pipeline für Machine Learning-Pipeline fließen. Mit diesem Feature können Sie die Abstammung verschiedener Datenartefakte nachverfolgen, einschließlich Quelltabellen/Views/Stagingbereiche, Feature-Ansichten, Datensätze, registrierte Modelle und bereitgestellte Modelldienste. Darüber hinaus erfasst ML Lineage die Beziehungen zwischen geklonten Artefakten und Artefakten ähnlicher Typen und gewährleistet so einen vollständigen Überblick über Datentransformationen und Abhängigkeiten innerhalb Ihrer Pipeline. Eine mögliche Pipeline ist unten abgebildet:
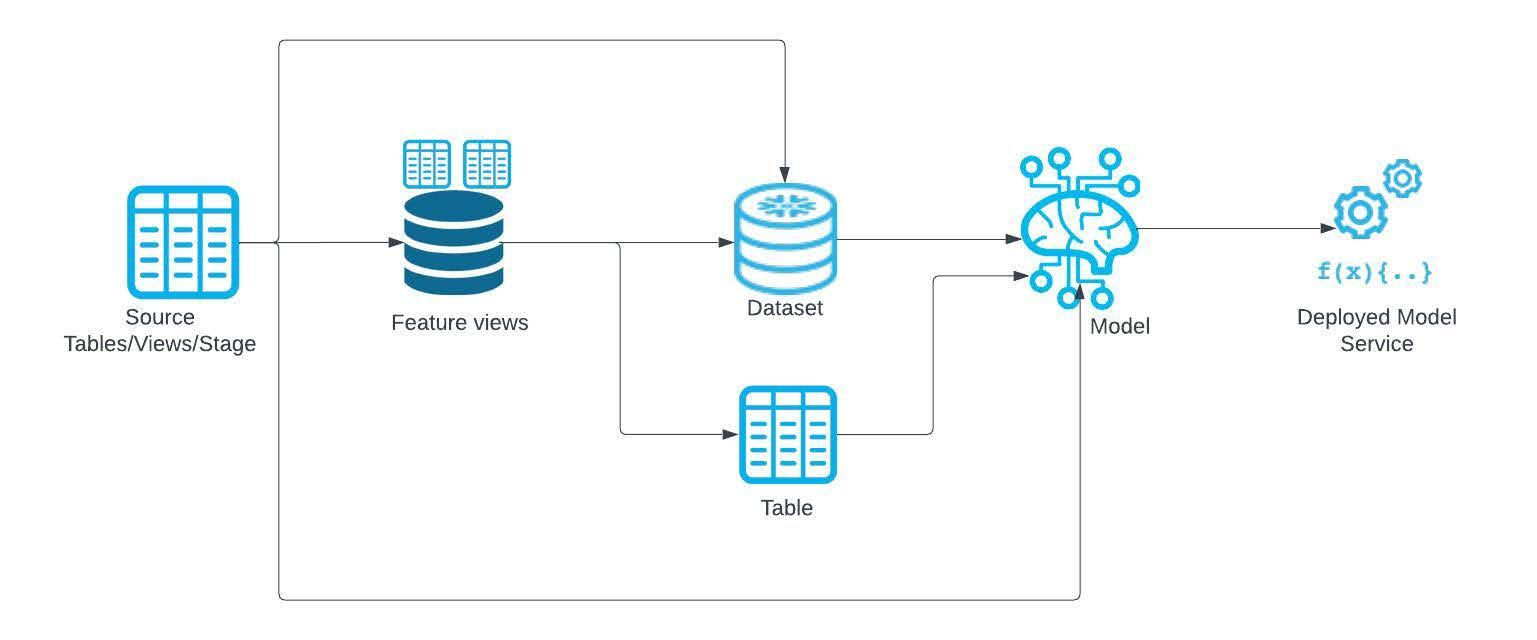
Die Abstammungsbeziehungen, die zwischen den Knotentypen in Ihrer Pipeline verfolgt werden können, sind in der folgenden Tabelle zusammengefasst. Jede Zeile steht für die Quelle der Abhängigkeit und jede Spalte für das Ziel. Der Schnittpunkt einer Zeile oder Spalte enthält ein Symbol, das anzeigt, ob diese Beziehung durch ML Lineage erfasst wird.
Tabelle/Ansicht/Stagingbereich |
Feature-Ansicht |
Datensatz |
Modell |
Eingesetzter Modelldienst |
|
|---|---|---|---|---|---|
Tabelle/Ansicht/Stagingbereich |
✔ |
✔ |
✔ |
✔ |
- |
Feature-Ansicht |
✔ (nur zu Tabelle) |
✔ |
✔ |
- |
- |
Datensatz |
✔ |
- |
✔ |
✔ |
- |
Modell |
❌ |
- |
- |
✔ |
✔ |
Eingesetzter Modelldienst |
❌ |
- |
- |
- |
- |
✔: Diese Beziehung wird von ML Lineage erfasst.
❌: Diese Beziehung wird von ML Lineage noch nicht erfasst, ist aber auf der Roadmap.
-: Diese Kombination von Objekten stellt keine Beziehung dar.
Mit ML Lineage können Sie verstehen, wie Machine Learning-Artefakte miteinander in Beziehung stehen, und Sie können Fragen wie diese beantworten:
Woher stammen die Daten, mit denen ich mein Modell trainiert habe?
Von welchen Feature-Ansichten hängt mein Datensatz ab?
Welche Modelle wurden mit Daten aus meinem Datensatz trainiert?
Welche Dienste nutzen mein Modell?
Schauen Sie sich das Quickstart-Notebook an, um zu erfahren, wie Sie ML Lineage APIs verwenden. Fahren Sie fort mit einem vollständigeren End-to-End-ML-Quickstart mit Feature Store und Model Registry, der ML Lineage in einen vollständigen ML-Workflow einbindet.
Einschränkungen¶
Tabellen und Ansichten, die aus Modellvorhersagen erstellt werden, erfassen derzeit nicht die Abstammungsbeziehung zurück zum Modell.
Herkunftsinformationen werden derzeit nicht repliziert.
Snowflake beabsichtigt, diese Beschränkungen in zukünftigen Versionen von ML Lineage zu beheben.
Erforderliche Berechtigungen¶
Benutzer benötigen die Berechtigung VIEW LINEAGE, um die Herkunft von Python-APIs zu ermitteln. Diese Berechtigung wird automatisch an die Rolle ACCOUNTADMIN vergeben, die sie dann an andere Rollen auf Kontoebene vergeben kann. Beispiel:
ML Lineage erstellen¶
Im Allgemeinen zeichnet Snowflake Informationen zur Herkunft auf, wenn Objekte erstellt werden. Die Herkunft von Modellen wird erfasst, wenn das Modell in der Model Registry eingetragen wird. Das Trainieren eines Modells mit Snowpark ML erzeugt automatisch Herkunftsdatensätze, wenn das Modell mit einem Snowpark-DataFrame trainiert wird.
Andere Szenarios, wie z. B. die unten aufgeführten, können mit ein wenig zusätzlichem Aufwand ebenfalls Herkunftsnachweise erzeugen.
Trainieren eines Modells mit Snowpark MLfrom einer anderen Art von Datenquelle (z. B. pandas-DataFrame).
Trainieren eines Modells, ohne Snowpark ML oder einen Snowpark-DataFrame zu verwenden.
Trainieren eines Modells außerhalb von Snowflake.
In diesen Szenarien können Sie immer noch das Quelldatenobjekt und das trainierte Modell miteinander verbinden, indem Sie ein Snowpark-DataFrame, das durch das Quelldatenobjekt unterstützt wird, als sample_data an die log_model-Methode der Model Registry übergeben, wie unten gezeigt.
Bemerkung
Nur Objekte, die erstellt wurden, nachdem das ML Lineage-Feature in Ihrem Konto aktiviert wurde, enthalten Herkunftsinformationen.
Abfragen von ML Lineage¶
Sie können die Herkunft von ML-Artefakten auf mehrere Arten abfragen.
Snowsight-UI¶
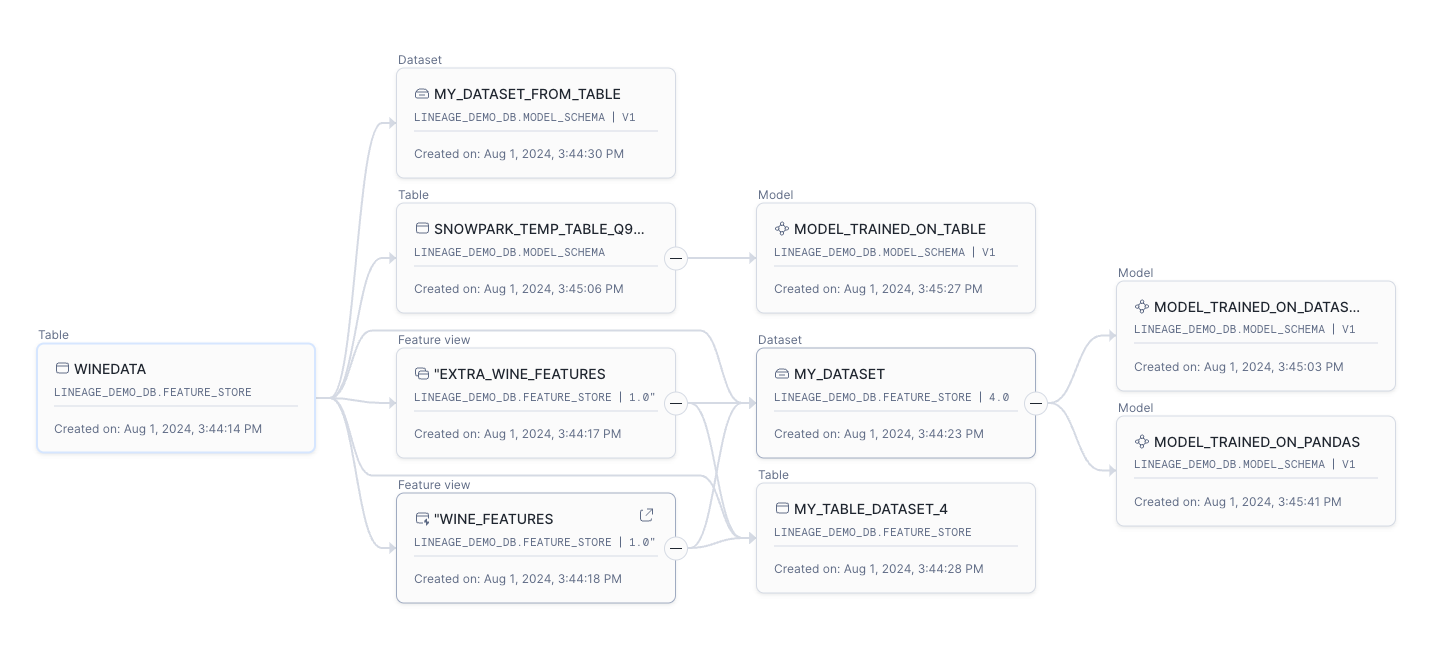
Die Landing Page eines jeden Artefakts hat eine Registerkarte Lineage. In der Standardansicht werden Objekte angezeigt, die einen Schritt vor- oder nachgelagert zum ausgewählten Objekt sind. Für eine detailliertere Ermittlung der Herkunft innerhalb der Snowsight-UI, siehe Datenabfolge.
Nachfolgend sehen Sie ein Beispiel für die Snowsight-Ansicht der Herkunftsdaten.
Snowpark-ML-Bibliothek¶
Die Snowpark ML-Bibliothek (das snowflake-ml-python-Paket) bietet eine benutzerfreundliche API für alle Snowflake ML-Artefaktobjekte, um die Herkunft sowohl in vor- als auch in nachgelagerter Richtung zu untersuchen. Sie gibt verbundene Artefaktobjekte zurück, und Sie können API-Aufrufe verketten, um in die gewünschte Richtung weiter zu forschen. Diese API arbeitet direkt mit Snowflake ML Python-Objekten. Weitere Informationen dazu finden Sie unter Snowpark ML Lineage-API.
Snowpark Python-Bibliothek¶
Die Snowpark-Bibliothek bietet eine flexible API, um Daten und ML-Herkunft von unterstützten Snowflake-Artefakten in größerer Tiefe in der Richtung Ihrer Wahl zu untersuchen. Es akzeptiert Domänen und vollqualifizierte Namen und gibt einen DataFrame mit Details zu den verbundenen Artefakten zurück. Weitere Informationen finden Sie unter snowflake.snowpark.lineage.Lineage.trace in der Snowpark Python API-Referenz.
Snowflake SQL¶
Die SQL-Funktion SNOWFLAKE.CORE.GET_LINEAGE kann zur Abfrage von Herkunftsinformationen verwendet werden, ähnlich wie die Snowpark-Bibliothek. Weitere Informationen dazu finden Sie unter GET_LINEAGE (SNOWFLAKE.CORE).
Snowpark ML Lineage-API¶
Die Methode lineage, die für die Objekte FeatureView, ModelVersion und Dataset verfügbar ist, ruft die Ablaufverfolgung für das aktuelle Objekt ab, sodass Sie die Ablaufverfolgung von Datenobjekten verfolgen können, die aus dem Snowflake Feature Store oder der Model Registry abgerufen wurden.
Für alle unterstützten Objekte akzeptiert die Methode lineage die folgenden Argumente:
directionentwederUPSTREAModerDOWNSTREAM.DOWNSTREAMist die Standardeinstellung.domain_filter, eine Liste der Zielobjekttypen, für die die Herkunft abgerufen werden soll. Die Standardeinstellung ist, dass alle Herkunftsbeziehungen zurückgegeben werden. Die verfügbaren Domänen sind"feature_view","dataset","model","table"und"view".
Die Methode gibt eine Liste der verbundenen Herkunftsknoten zurück. Diese Knoten können Instanzen von Dataset, FeatureView oder ModelVersion sein, wenn Sie diese Klassen in Ihre Python-Sitzung importiert haben. Andernfalls wird jeder Knoten durch eine generische LineageNode-Instanz dargestellt.
Beispiele¶
Die folgenden Beispiele zeigen, wie Sie häufige Fragen mit der Snowpark ML Herkunft-API beantworten können.
Woher stammen bei einer Modellversion die Trainingsdaten?
Von welchen Feature-Ansichten hängt ein bestimmter Datensatz ab?
Welche Modelle wurden mit Daten aus einem bestimmten Datensatz trainiert?
Weitere vollständige Beispiele finden Sie in diesen Ressourcen: