ML Lineage: Trace ML data flow¶
Note
ML Lineage is available in the snowflake-ml-python package version 1.6.0 and later.
ML Lineage provides comprehensive tracing of data as it flows through your machine learning pipeline. This feature enables you to track the lineage between various data artifacts, including source tables/views/stages, feature views, datasets, registered models, and deployed model services. Additionally, ML Lineage captures the relationships between cloned artifacts and artifacts of similar types, ensuring a complete view of data transformations and dependencies within your pipeline. A possible pipeline is illustrated below:
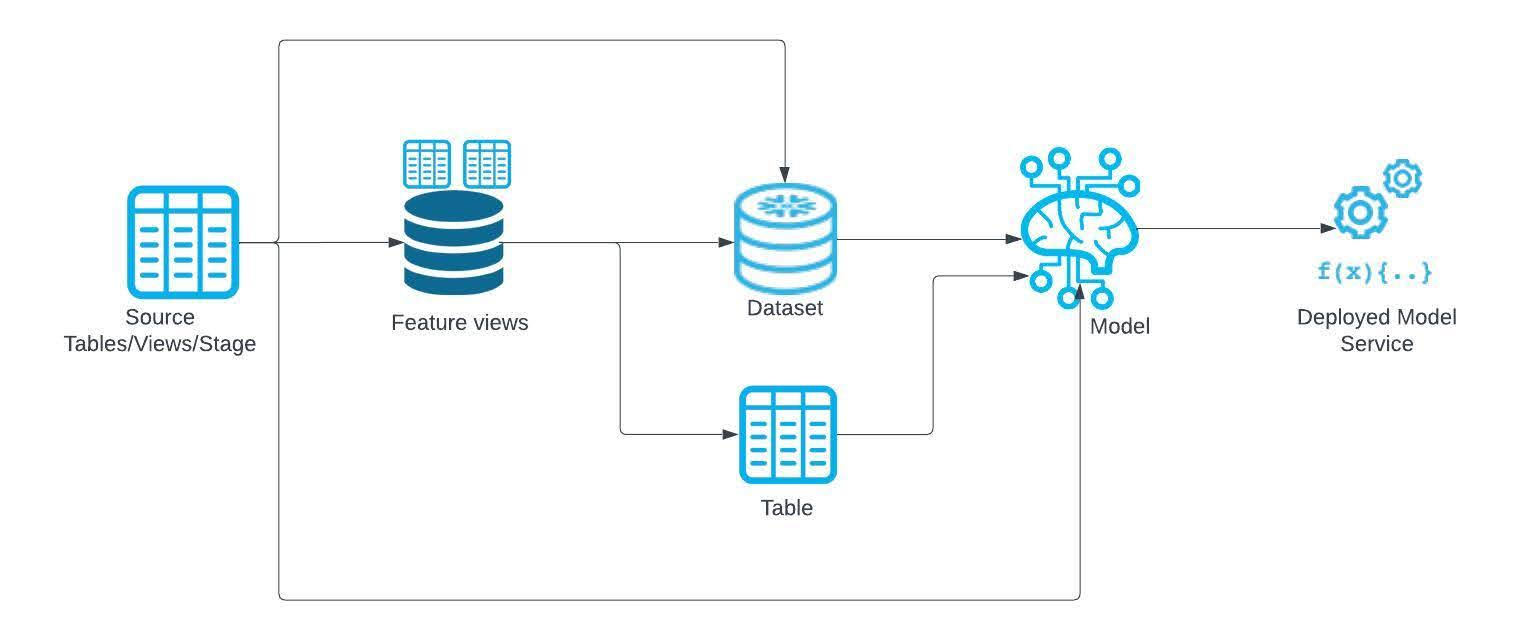
The lineage relationships that can be tracked between the types of nodes in your pipeline are summarized in the table below. Each row represents the source of the dependency, and each column represents the target. The intersection of a row or column contains an icon indicating whether that relationship is captured by ML Lineage.
| Table/View/Stage | Feature View | Dataset | Model | Deployed Model Service | |
|---|---|---|---|---|---|
| Table/View/Stage | ✔ | ✔ | ✔ | ✔ | - |
| Feature View | ✔ (only to table) | ✔ | ✔ | - | - |
| Dataset | ✔ | - | ✔ | ✔ | - |
| Model | ❌ | - | - | ✔ | ✔ |
| Deployed Model Service | ❌ | - | - | - | - |
- ✔: This relationship is captured by ML Lineage.
- ❌: This relationship is not yet captured by ML Lineage, but is on the roadmap.
- -: This combination of objects does not represent a relationship.
With ML Lineage, you can understand how machine learning artifacts relate to each other and can answer questions like:
- Where did the data come from to train my model?
- What feature views does my dataset depend on?
- What models were trained on data from my dataset?
- Which services use my model?
Dive into the Quick Start Notebook to see how to use ML Lineage APIs. Follow up with more complete end-to-end ML quickstart with Feature Store and Model Registry that incorporates ML Lineage in a full ML workflow.
Limitations¶
- Tables and views created from model predictions do not currently capture the lineage relationship back to the model.
- Lineage information is not replicated at this time.
Snowflake intends to address these limitations in future releases of ML Lineage.
Required privileges¶
Users need the VIEW LINEAGE privilege to explore lineage from Python APIs. This privilege is automatically granted to the ACCOUNTADMIN role, which can then grant it to other roles at the account level. For example:
Creating ML Lineage¶
Generally, Snowflake records lineage information when objects are created. Lineage for models is captured when the model is logged to the Model Registry. Training a model using Snowpark ML automatically generates lineage records if the model is trained from a Snowpark DataFrame.
Other scenarios, such as those listed below, can also generate lineage records with a little extra effort.
- Training a model using Snowpark MLfrom some other kind of data source (such as a pandas DataFrame).
- Training a model without using Snowpark ML or a Snowpark DataFrame.
- Training a model outside of Snowflake.
In these scenarios, you can still associate the source data object and the trained model by passing a Snowpark DataFrame
backed by the source data object as sample_data to the Model Registry’s log_model method, as shown below.
Note
Only objects created after the ML Lineage feature is enabled in your account contain lineage information.
Querying ML Lineage¶
You can query the lineage of ML artifacts in several ways.
Snowsight UI¶
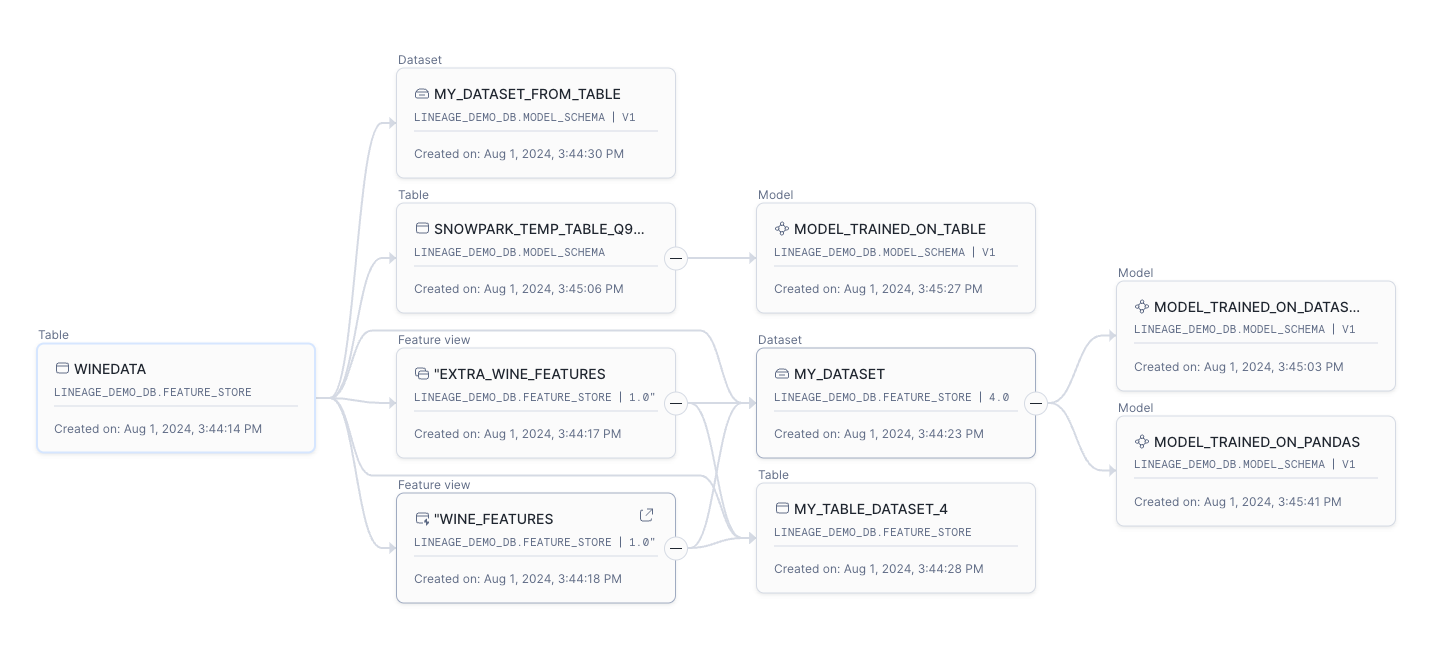
Every artifact’s landing page has a Lineage tab. The default view displays upstream and downstream objects one step away from the selected object. For a more detailed exploration of lineage within the Snowsight UI, see Data Lineage.
A sample of the Snowsight view of lineage data is shown below.
Snowpark ML library¶
The Snowpark ML library (the snowflake-ml-python package) offers a user-friendly API on all Snowflake ML artifact
objects to explore lineage in both upstream and downstream directions. It returns connected artifact objects, and you
can chain API calls to further explore in the desired direction. This API works directly with Snowflake ML Python
objects. For more information, see Snowpark ML lineage API.
Snowpark Python library¶
The Snowpark library provides a flexible API to explore data and ML lineage of supported Snowflake artifacts at greater depths in the direction of your choice. It accepts domains and fully qualified names, returning a DataFrame with details of connected artifacts. For more information, see snowflake.snowpark.lineage.Lineage.trace in the Snowpark Python API Reference.
Snowflake SQL¶
The SQL function SNOWFLAKE.CORE.GET_LINEAGE can be used to query lineage information similar to the Snowpark
library. For more information, see GET_LINEAGE (SNOWFLAKE.CORE).
Snowpark ML lineage API¶
The lineage method available on FeatureView, ModelVersion, and Dataset objects retrieves
lineage relationships for the current object, so you can trace the lineage of data objects retrieved from the Snowflake
Feature Store or Model Registry.
For all supported objects, the lineage method accepts the following arguments:
direction, eitherUPSTREAMorDOWNSTREAM.DOWNSTREAMis the default.domain_filter, a list of target object types for which lineage will be retrieved. The default is to return all lineage relationships. The available domains are"feature_view","dataset","model","table", and"view".
The method returns a list of connected lineage nodes. These nodes can be instances of Dataset,
FeatureView, or ModelVersion, if you have imported these classes into your Python session. Otherwise,
each node is represented by a generic LineageNode instance.
Examples¶
The following examples demonstrate how to answer common questions using the Snowpark ML lineage API.
-
Given a model version, where did its training data come from?
-
Which feature views does a particular dataset depend on?
-
Which models were trained on data from a given dataset?
For more complete examples, see these resources: