Snowflake ML: Umfassendes maschinelles Lernen¶
Snowflake ML ist ein integrierter Satz von Funktionen für durchgängiges maschinelles Lernen auf einer einzigen Plattform auf Basis Ihrer verwalteten Daten. Es handelt sich dabei um eine einheitliche Umgebung für die Entwicklung und Produktion von ML, die für großangelegtes verteiltes Feature-Engineering, Modelltraining und Inferenz auf CPU und GPU compute ohne manuelle Abstimmung oder Konfiguration optimiert ist.
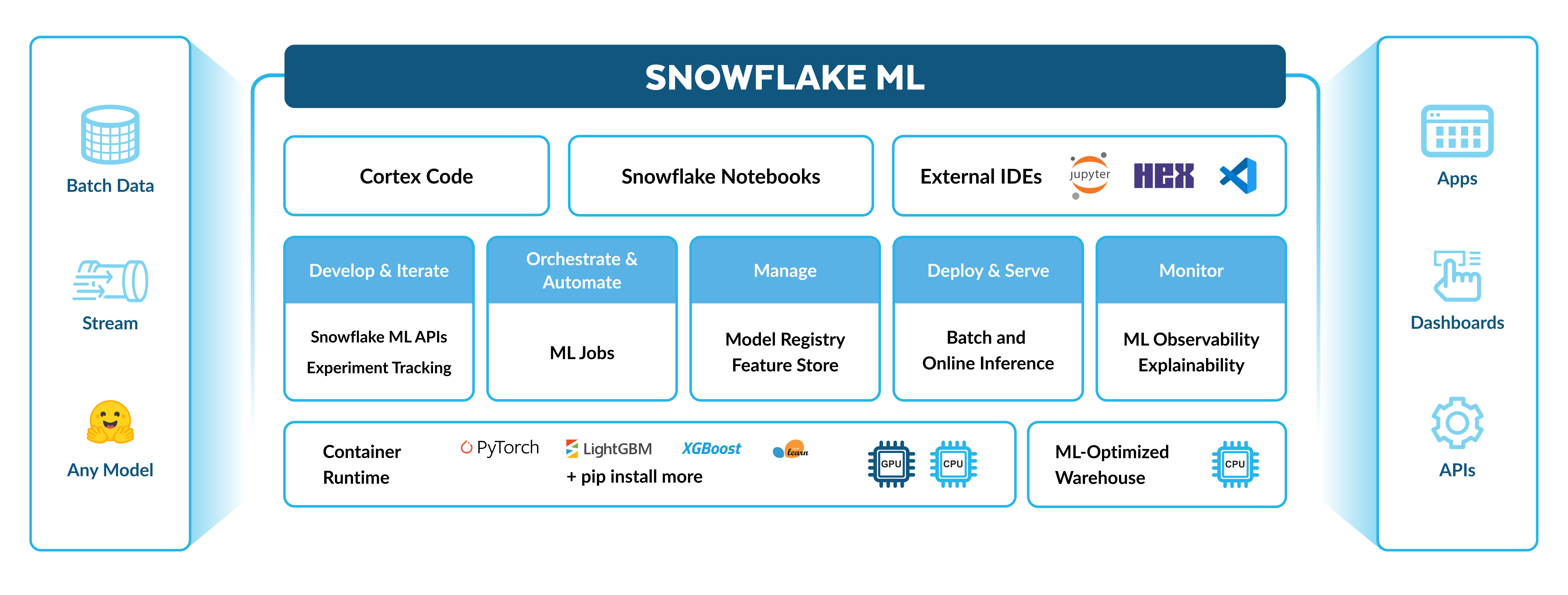
Die Skalierung von ML-End-to-End-Workflows in Snowflake ist nahtlos. Sie können Folgendes tun:
Daten vorbereiten
Erstellen und verwenden Sie Features mit dem Snowflake Feature Store
Trainieren Sie Modelle mit CPUs oder GPUs mit einem beliebigen Open-Source-Paket von Snowflake Notebooks für Container Runtime
Erstellen Sie Experimente, um Ihre trainierten Modelle anhand festgelegter Kennzahlen zu evaluieren
Operationalisieren Sie Ihre Pipelines mit Snowflake ML-Jobs
Stellen Sie Ihr Modell mit der Snowflake Model Registry für Inferenzen im großen Maßstab bereit
Überwachen Sie Ihre Produktionsmodelle mit ML-Beobachtbarkeit und -Erklärbarkeit
Verwenden Sie ML Lineage, um die Quelldaten zu Features, Datensets und Modellen in Ihrer ML-Pipeline zu verfolgen
Snowflake ML ist außerdem flexibel und modular. Sie können die Modelle, die Sie in Snowflake entwickelt haben, außerhalb von Snowflake einsetzen, und extern trainierte Modelle können problemlos zur Inferenz in Snowflake verwendet werden.
Funktionen für Datenwissenschaftler und ML-Ingenieure¶
Snowflake Notebooks auf Container Runtime¶
Snowflake Notebooks auf Container Runtime bieten eine Jupyter-ähnliche Umgebung für das Training und die Feinabstimmung umfangreicher Modelle in Snowflake, ohne Infrastrukturmanagement. Beginnen Sie das Training mit vorinstallierten Paketen wie PyTorch, XGBoost oder Scikit-learn, oder installieren Sie ein beliebiges Paket aus Open-Source-Repositories wie HuggingFace oder PyPI. Container Runtime ist für den Betrieb auf der Infrastruktur von Snowflake optimiert und bietet Ihnen hocheffizientes Laden von Daten, verteiltes Modelltraining und Hyperparameter-Tuning.
Snowflake Feature Store¶
Snowflake Feature Store ist eine integrierte Lösung zum Definieren, Verwalten, Speichern und Auffinden von ML Features, die aus Ihren Daten abgeleitet wurden. Der Snowflake Feature Store unterstützt das automatische, inkrementelle Aktualisieren aus Batch- und Streaming-Datenquellen, sodass Feature-Pipelines nur einmal definiert werden müssen, um kontinuierlich mit neuen Daten aktualisiert zu werden.
ML Jobs¶
Verwenden Sie Snowflake ML Jobs zur Entwicklung und Automatisierung von ML-Pipelines. ML-Jobs ermöglichen es auch Teams, die lieber von einer externen IDE (VS-Code, PyCharm, SageMaker-Notebooks) aus arbeiten, Funktionen, Dateien oder Module an die Container Runtime von Snowflake zu verteilen.
Experimente¶
Verwenden Sie Experimente, um die Ergebnisse Ihres Modelltrainings aufzuzeichnen und eine Sammlung von Modellen auf organisierte Weise zu bewerten. Experimente helfen Ihnen, das beste Modell für Ihren Anwendungsfall auszuwählen, um es live in die Produktion zu übertragen. Das Training kann entweder in einem Experiment während des Modelltrainings auf Snowflake protokolliert werden oder Sie können Ihre eigenen Metadaten und Artefakte aus vorherigen Trainings hochladen. Nachdem Sie das Training abgeschlossen haben, können Sie sich alle Ergebnisse in Snowsight ansehen und das richtige Modell für Ihre Bedürfnisse auswählen.
Snowflake Model Registry und Model Serving¶
Die Snowflake Model Registry ermöglicht die Protokollierung und Verwaltung aller Ihrer ML-Modelle, unabhängig davon, ob sie auf Snowflake oder anderen Plattformen trainiert wurden. Sie können die Modelle aus der Modellregistrierung verwenden, um Inferenzen im großen Maßstab durchzuführen. Sie können Model Serving verwenden, um die Modelle zur Inferenz an Snowpark Container Service zu übermitteln.
ML-Beobachtbarkeit¶
ML-Beobachtbarkeit bietet Tools zur Überwachung von Modellleistungsmetriken in Snowflake. Sie können Modelle in der Produktion verfolgen, Performance- und Drift-Metriken überwachen und Warnmeldungen für Performance-Schwellenwerte einstellen. Verwenden Sie außerdem die Funktion ML-Erklärbarkeit, um Shapley-Werte für Modelle in der Snowflake Model Registry zu berechnen, unabhängig davon, wo sie trainiert wurden.
ML-Abfolge¶
ML Lineage ist eine Funktion zum Nachverfolgen der durchgängigen Herkunft von ML-Artefakten von Quelldaten zu Features, Datensätzen und Modellen. Dies ermöglicht Reproduzierbarkeit, Konformität und Fehlersuche über den gesamten Lebenszyklus von ML-Assets.
Snowflake Datasets¶
Snowflake Datasets bietet einen unveränderlichen, versionierten Schnappschuss Ihrer Daten, der sich für die Aufnahme durch Ihre Modelle des maschinellen Lernens eignet.
Funktionen für Business-Analysten¶
Für Business-Analysten verkürzen Sie mit ML-Funktionen die Entwicklungszeit für gängige Szenarien wie Prognosen und die Erkennung von Anomalien in Ihrem Unternehmen mit SQL.
Zusätzliche Ressourcen¶
Sehen Sie sich die folgenden Ressourcen an, um mit Snowflake ML zu beginnen:
Wenden Sie sich an Ihren Snowflake-Vertreter, um frühzeitigen Zugang zu den Dokumentationen der weiteren Features zu erhalten, die sich derzeit in der Entwicklung befinden.