Notebooks auf Container Runtime für ML¶
Übersicht¶
Sie können Snowflake Notebooks auf Container Runtime für ML ausführen. Container Runtime für ML basiert auf Snowpark Container Services und bietet Ihnen eine flexible Container-Infrastruktur, mit der Sie eine Vielzahl von Workflows vollständig innerhalb von Snowflake erstellen und operationalisieren können. Container Runtime für ML bietet Software- und Hardware-Optionen zur Unterstützung fortgeschrittener Data Science- und Machine Learning-Workloads. Im Vergleich zu virtuellen Warehouses bietet Container Runtime für ML eine flexiblere Umgebung, in der Sie Pakete aus verschiedenen Quellen installieren und Computeressourcen, einschließlich GPU-Maschinentypen, auswählen können, während Sie gleichzeitig SQL-Abfragen auf Warehouses für eine optimale Performance durchführen.
This document describes some considerations for using notebooks on Container Runtime for ML. You can also try the Getting Started with Snowflake Notebook Container Runtime quickstart to learn more about using the Container Runtime for ML in your development.
Voraussetzungen¶
Bevor Sie Snowflake Notebooks für Container Runtime für ML verwenden können, muss die Rolle ACCOUNTADMIN die Schritte zur Einrichtung des Notebooks abschließen, um die erforderlichen Ressourcen zu erstellen und Berechtigungen für diese Ressourcen zu erteilen. Detaillierte Schritte finden Sie unter Administrator-Einrichtung.
Notebook auf Container Runtime für ML erstellen¶
Wenn Sie ein Notebook auf Container Runtime für ML erstellen, wählen Sie ein Warehouse, eine Laufzeit und einen Computepool, um die Ressourcen für die Ausführung Ihres Notebooks bereitzustellen. Die von Ihnen gewählte Laufzeit ermöglicht Ihnen den Zugriff auf verschiedene Python-Pakete, je nach Ihrem Anwendungsfall. Unterschiedliche Warehouse-Größen oder Computepools haben unterschiedliche Auswirkungen auf Kosten und Leistung. Alle diese Einstellungen können bei Bedarf später geändert werden.
Bemerkung
Ein Benutzer mit den Rollen ACCOUNTADMIN, ORGADMIN oder SECURITYADMIN kann nicht direkt ein Notebook auf Container Runtime erstellen oder besitzen. Notebooks, die von diesen Rollen erstellt wurden oder ihnen direkt gehören, können nicht ausgeführt werden. Wenn ein Notebook jedoch im Besitz einer Rolle ist, von der die Rollen ACCOUNTADMIN, ORGADMIN oder SECURITYADMIN Berechtigungen erben, wie z. B. die Rolle PUBLIC, dann können Sie diese Rollen verwenden, um das Notebook auszuführen.
Gehen Sie folgendermaßen vor, um ein Snowflake-Notebook zu erstellen, das auf der Container Runtime läuft:
Melden Sie sich bei Snowsight an.
Wählen Sie im Navigationsmenü die Option Projects » Notebooks aus.
Wählen Sie + Notebook aus.
Geben Sie einen Namen für Ihr Notebook ein.
Wählen Sie eine Datenbank und ein Schema aus, in dem Sie Ihr Notebook speichern möchten. Dieser Parameter kann nach dem Erstellen des Notebooks nicht mehr geändert werden.
Bemerkung
Die Datenbank und das Schema werden nur für die Speicherung Ihrer Notebooks benötigt. Sie können jede Datenbank und jedes Schema, auf das Ihre Rolle Zugriff hat, von Ihrem Notebook aus abfragen.
Wählen Sie Run on container für Runtime aus.
Wählen Sie aus den CPU- oder GPU-Optionen aus.
- Wählen Sie Compute pool aus.
Snowflake stellt automatisch zwei Computepools in jedem Konto für die Ausführung von Notebooks bereit: SYSTEM_COMPUTE_POOL_CPU und SYSTEM_COMPUTE_POOL_GPU.
Ändern Sie das ausgewählte Warehouse, das Sie für die Ausführung von SQL- und Snowpark-Abfragen verwenden möchten.
Um Ihr Notizbuch zu erstellen und zu öffnen, wählen Sie Create aus.
Runtime version:
Es sind zwei Typen von Laufzeitversionen verfügbar: CPU und GPU. Jedes Laufzeit-Image enthält einen Basissatz von Python-Paketen und Versionen, die von Snowflake überprüft und integriert wurden. Alle Laufzeit-Images unterstützen Datenanalyse, Modellierung und Training mit Snowpark Python, Snowflake ML, und Streamlit.
Um zusätzliche Pakete aus einem öffentlichen Repository zu installieren, können Sie pip verwenden. Für Snowflake-Notebooks ist eine Integration des externen Zugriffs (EAI) erforderlich, um Pakete von externen Endpunkten zu installieren. Um EAIs zu konfigurieren, lesen Sie Einrichten des externen Zugriffs für Snowflake Notebooks. Wenn ein Paket jedoch bereits Teil des Basisbilds ist, können Sie die Version des Pakets nicht ändern, indem Sie eine andere Version mit pip install installieren. Um eine Liste der vorinstallierten Pakete zu erhalten, führen Sie den folgenden Befehl über eine Zelle im Notebook aus:
!pip freeze
Compute pool:
Ein Computepool stellt die Computeressourcen für Ihren Notebook-Kernel und Python-Code bereit. Verwenden Sie für den Anfang kleinere, CPU-basierte Computepools und wählen Sie für die Optimierung auf GPU basierende Computepools mit höherem Speicher für intensive GPU-Nutzungsszenarios wie Computer Vision oder LLMs/VLMs.
Beachten Sie, dass auf jedem Serverknoten jeweils nur ein Notebook pro Benutzer ausgeführt werden kann. Sie sollten den Parameter MAX_NODES auf einen Wert größer als eins einstellen, wenn Sie Computepools für Notebooks erstellen. Ein Beispiel dazu finden Sie unter Computeressourcen. Weitere Informationen zu Snowpark Container Services Computpools finden Sie unter Snowpark Container Services: Verwenden von Computepools.
Wenn ein Notebook nicht benutzt wird, sollten Sie es herunterfahren, um Ressourcen im Knoten freizugeben. Sie können ein Notebook herunterfahren, indem Sie End session aus der Dropdown-Liste der Verbindungen auswählen.
Wenn ein Notebook auf Container Runtime läuft, benötigt die Rolle die Berechtigung USAGE auf einem Computepool statt auf dem Notebook Warehouse. Computepools sind CPU-basierte oder GPU-basierte virtuelle Maschinen, die von Snowflake verwaltet werden. Wenn Sie einen Computepool erstellen, setzen Sie den Parameter MAX_NODES auf einen Wert größer als eins, da für jedes Notebook ein vollständiger Knoten benötigt wird. Weitere Informationen dazu finden Sie unter Snowpark Container Services: Verwenden von Computepools.
Sie können Ihre Ressourcenauslastung einsehen. Weitere Informationen dazu finden Sie unter Allgemeine Informationen zu Snowflake Notebooks.
Bemerkung
Auf AWS verwenden Notebooks, die auf GPU Computepools laufen, den Hochleistungs-NVMe-Speicher als Standard-Boot-Gerät.
Führen Sie ein Notebook auf der Container Runtime aus¶
Nachdem Sie Ihr Notebook erstellt haben, können Sie sofort mit der Ausführung von Code beginnen, indem Sie Zellen hinzufügen und ausführen. Informationen zum Hinzufügen von Zellen finden Sie unter Code in Snowflake Notebooks entwickeln und ausführen.
Weitere Pakete importieren¶
Zusätzlich zu den vorinstallierten Paketen, mit denen Sie Ihr Notebook in Betrieb nehmen können, können Sie auch Pakete aus öffentlichen Quellen installieren, für die Sie einen externen Zugang eingerichtet haben. Sie können auch Pakete verwenden, die in einem Stagingbereich oder in einem privaten Repository gespeichert sind. Sie müssen die Rolle ACCOUNTADMIN oder eine Rolle verwenden, die externe Zugriffsintegrationen erstellen kann (EAIs), um den Zugriff auf bestimmte externe Endpunkte einzurichten und zu gewähren. Verwenden Sie den Befehl ALTER NOTEBOOK, um den externen Zugriff auf Ihrem Notebook zu aktivieren. Sobald sie zugewiesen wurden, sehen Sie die EAIs in Notebook settings. Schalten Sie die EAIs um, bevor Sie die Installation von externen Kanälen starten. Eine Anleitung dazu finden Sie unter Konfigurieren Sie ein Notebook mit externem Zugriff und Geheimnissen.
Das folgende Beispiel installiert ein externes Paket mit pip install in einer Codezelle:
!pip install transformers scipy ftfy accelerate
Aktualisieren der Notebook-Einstellungen¶
Sie können die Einstellungen, wie z. B. die zu verwendenden Computepools oder das Warehouse, jederzeit unter Notebook settings aktualisieren, auf das Sie über das Menü  Notebook-Aktionen oben rechts zugreifen können.
Notebook-Aktionen oben rechts zugreifen können.
Eine der Einstellungen, die Sie unter Notebook settings aktualisieren können, ist die Einstellung für den Timeout nach Leerlauf. Die Standardeinstellung für den Timeout im Leerlauf ist 1 Stunde. Sie können ihn auf bis zu 72 Stunden einstellen. Um dies in SQL festzulegen, verwenden Sie den Befehl CREATE NOTEBOOK oder ALTER NOTEBOOK, um die Eigenschaft IDLE_AUTO_SHUTDOWN_TIME_SECONDS des Notebooks einzustellen.
Installieren privater Pakete¶
Pip unterstützt die Installation von Paketen aus privaten Quellen mit Basisaauthentifizierung, wie JFrog Artifactory. Konfigurieren Sie das Notebook für die Integration des externen Zugriffs (EAI), damit es auf das Repository zugreifen kann.
Erstellen Sie eine Netzwerkregel, um das Repository anzugeben, auf das Sie zugreifen möchten. Diese Netzwerkregel gibt zum Beispiel ein JFrog Repository an:
CREATE OR REPLACE NETWORK RULE jfrog_network_rule MODE = EGRESS TYPE = HOST_PORT VALUE_LIST = ('<your-repo>.jfrog.io');
Erstellen Sie ein Geheimnis, das die Anmeldeinformationen repräsentiert, die für die Authentifizierung beim externen Netzwerkstandort erforderlich sind.
CREATE OR REPLACE SECRET jfrog_token TYPE = GENERIC_STRING SECRET_STRING = '<your-jfrog-token>';
Erstellen Sie eine Integration des externen Zugriffs, die den Zugriff auf das Repository ermöglicht:
CREATE OR REPLACE EXTERNAL ACCESS INTEGRATION jfrog_integration ALLOWED_NETWORK_RULES = (jfrog_network_rule) ALLOWED_AUTHENTICATION_SECRETS = (jfrog_token) ENABLED = TRUE; GRANT USAGE ON INTEGRATION jfrog_integration TO ROLE data_scientist;
Ordnen Sie die Integration für den externen Zugriff und das Geheimnis dem Notebook zu.
ALTER NOTEBOOK my_notebook SET EXTERNAL_ACCESS_INTEGRATIONS = (jfrog_integration), SECRETS = ('jfrog_token' = jfrog_token);
Um auf die Konfiguration des externen Zugriffs zuzugreifen, wählen Sie das Menü
(Notebook actions) oben rechts auf Ihrem Notebook.Wählen Sie Notebook settings aus, und wählen Sie dann die Registerkarte External access aus.
Wählen Sie die EAI, um eine Verbindung zum Repository herzustellen.
Das Notebook startet neu.
Sobald das Notebook neu gestartet ist, können Sie aus dem Repository installieren:
!pip install hello-jfrog --index-url https://<user>:<token>@<your-repo>.jfrog.io/artifactory/api/pypi/test-pypi/simple
Installation von privaten Paketen mit privater Konnektivität¶
Wenn Ihr privates Paketarchiv eine private Konnektivität erfordert, folgen Sie diesen Schritten, um Ihr Konto zu konfigurieren. Wenn Sie Hilfe benötigen, können Sie sich mit Ihrem Kontoadministrator abstimmen, um die Netzwerkregel einzurichten.
Folgen Sie den Schritten unter Netzwerkausgang über private Konnektivität, um den Netzwerkausgang über private Konnektivität einzurichten.
Erstellen Sie ein Geheimnis, das die Anmeldeinformationen repräsentiert, die für die Authentifizierung beim externen Netzwerkstandort erforderlich sind.
CREATE OR REPLACE SECRET jfrog_token TYPE = GENERIC_STRING SECRET_STRING = '<your-jfrog-token>';
Erstellen Sie eine EAI mit der Netzwerkregel aus Schritt 1. Beispiel:
CREATE OR REPLACE EXTERNAL ACCESS INTEGRATION private_repo_integration ALLOWED_NETWORK_RULES = (PRIVATE_LINK_NETWORK_RULE) ALLOWED_AUTHENTICATION_SECRETS = (jfrog_token) ENABLED = TRUE; GRANT USAGE ON INTEGRATION private_repo_integration TO ROLE data_scientist;
Ordnen Sie die Integration für den externen Zugriff und das Geheimnis dem Notebook zu.
ALTER NOTEBOOK my_notebook SET EXTERNAL_ACCESS_INTEGRATIONS = (jfrog_integration), SECRETS = ('jfrog_token' = jfrog_token);
Um auf die Konfiguration des externen Zugriffs zuzugreifen, wählen Sie das Menü
(Notebook actions) oben rechts auf Ihrem Notebook.Wählen Sie Notebook settings aus, und wählen Sie dann die Registerkarte External access aus.
Wählen Sie die EAI, um eine Verbindung zu Ihrem privaten Repository herzustellen.
Das Notebook startet neu.
Nachdem das Notebook neu gestartet wurde, können Sie die
--index-urlIhres Repositorys angeben:!pip install my_package --index-url https://my-private-repo-url.com/simple
Ausführen von ML-Workloads¶
Notebooks auf Container Runtime eignen sich gut für die Ausführung von ML Workloads wie Modelltraining und Parameterabstimmung. Die Laufzeiten sind mit den gängigen ML-Paketen vorinstalliert. Wenn der Zugriff auf die externe Integration eingerichtet ist, können Sie alle anderen Pakete, die Sie benötigen, über !pip install installieren.
Verwenden Sie OSS-Bibliotheken, um Modelle zu entwickeln oder um Notebooks zu importieren, die OSS-Komponenten verwenden. Die Container Runtime verfügt über optimierte APIs wie die folgenden:
DataConnectorfür schnellere DateneingabeVerteilte Trainings-APIs für skalierbare Modellanpassung
Verteilte Hyperparameter-Abstimmungs-APIs, um alle verfügbaren Ressourcen effizient zu nutzen.
Weitere Informationen dazu finden Sie unter Container Runtime für ML.
Bemerkung
Da die Runtime mit vielen Paketen vorinstalliert ist, erfordert ein Wechsel zu einer beliebigen Version einen Neustart des Kernels. Weitere Informationen dazu finden Sie unter Notebooks untersuchen.
OSS ML-Bibliotheken¶
Das folgende Beispiel verwendet eine OSS ML-Bibliothek, xgboost, mit einer aktiven Snowpark-Sitzung, um Daten für das Training direkt in den Speicher zu holen:
from snowflake.snowpark.context import get_active_session
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
session = get_active_session()
df = session.table("my_dataset")
# Pull data into local memory
df_pd = df.to_pandas()
X = df_pd[['feature1', 'feature2']]
y = df_pd['label']
# Split data into test and train in memory
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=34)
# Train in memory
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
# Predict
y_pred = model.predict(X_test)
Einschränkungen¶
Nachdem eine Container Runtime-Notebook-Sitzung gestartet wurde, kann sie bis zu sieben Tage ohne Unterbrechung laufen. Nach sieben Tagen kann es zu einer Unterbrechung und Abschaltung kommen, wenn ein planmäßiger SPCS-Service-Wartungsfall eintritt. Die Einstellungen für die Leerlaufzeit des Notebooks gelten weiterhin. Einzelheiten zur SPCS-Service-Wartung finden Sie unter Wartung von Computepools.
Hinweise zu Kosten und Abrechnung¶
Wenn Sie Notebooks auf Container Runtime ausführen, können Ihnen sowohl </user-guide/cost-understanding-compute>Warehouse-Computekosten :doc: als auch SPCS</developer-guide/snowpark-container-services/accounts-orgs-usage-views>-Computekosten `Snowflake Notebooks entstehen. Warehouses werden nicht nur für die Ausführung von Abfragen benötigt, sondern auch für die Unterstützung bestimmter Frontend-Funktionen in Snowflake Notebooks. Wenn Sie beispielsweise einen Computepool für die Python-Ausführung verwenden, wird möglicherweise weiterhin ein Warehouse für das Rendern von Ausgaben oder die Handhabung interaktiver Komponenten benötigt.
Snowflake Notebooks sind auf virtuelle Warehouses angewiesen, um SQL- und Snowpark-Abfragen effizient auszuführen. Daher können Warehouse-Computekosten anfallen, wenn Sie SQL-Zellen oder Snowpark-Pushdown-Abfragen in Python-Zellen ausführen.
Das folgende Diagramm zeigt, wo die Berechnungen für SQL-, Snowpark- und Python-Zellen innerhalb eines Notebooks erfolgen:
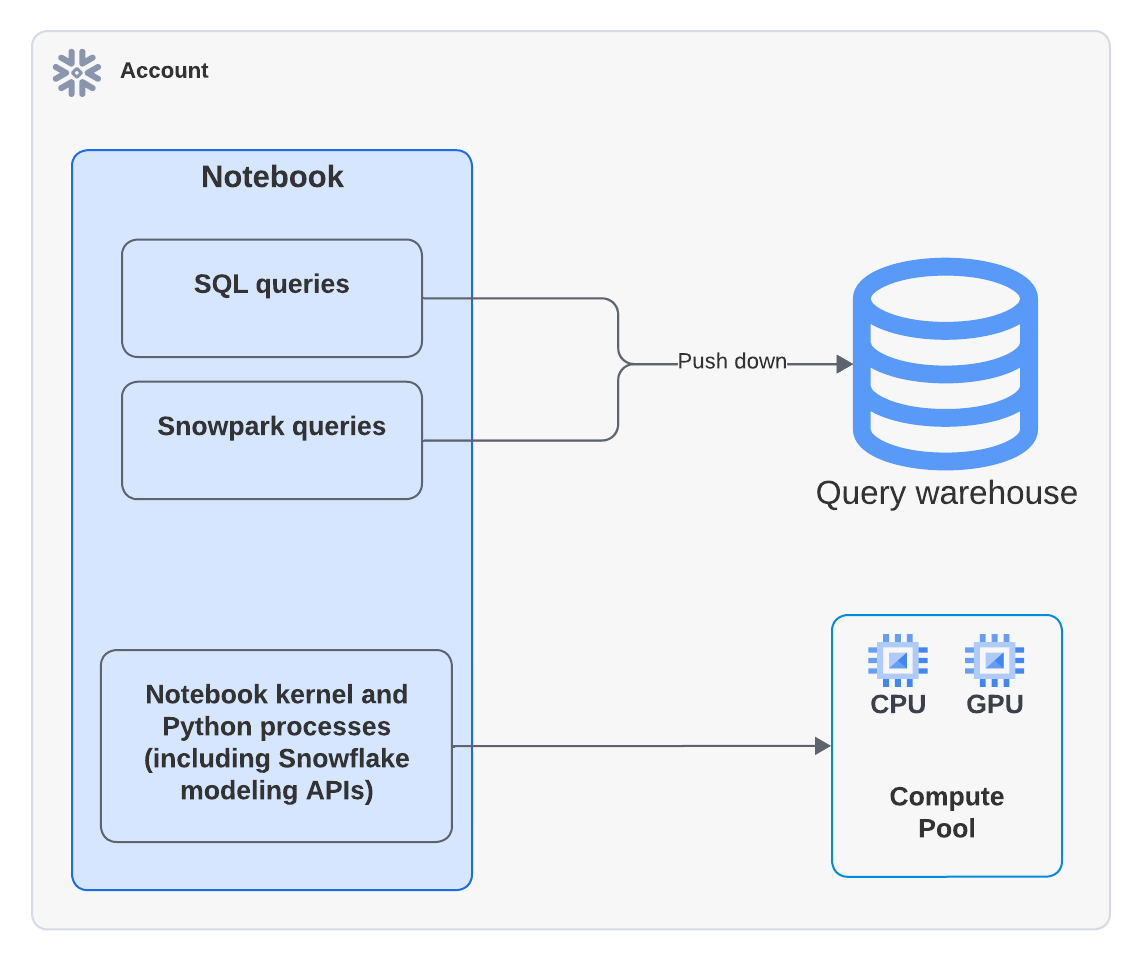
Bemerkung
Wenn Sie ein Notebook ausführen, das einen Computepool verwendet, läuft der Python-Code auf dem Computepool. Sie können jedoch Aktivitäten in Query History sehen, was darauf hinweist, dass ein Warehouse zur Ausführung des Befehls EXECUTE NOTEBOOK verwendet wurde. Dies ist ein erwartetes Verhalten. Das Warehouse wird kurz verwendet, um die Ausführungsumgebung zu initialisieren, verbraucht aber keine Warehouse-Credits. Die gesamte Ausführung von Code wird vom Computepool übernommen.
Das folgende Python-Beispiel verwendet zum Beispiel die xgboost-Bibliothek. Die Daten werden in den Container gezogen und die Berechnung wird vollständig von Snowpark Container Services übernommen:
from snowflake.snowpark.context import get_active_session
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
session = get_active_session()
df = session.table("my_dataset")
# Pull data into local memory
df_pd = df.to_pandas()
X = df_pd[['feature1', 'feature2']]
y = df_pd['label']
# Split data into test and train in memory
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=34)
Mehr über Warehouse-Kosten erfahren Sie unter Übersicht zu Warehouses.