Snowflake ML-Modellentwicklung¶
Bemerkung
Das Snowflake ML Modeling-API ist ab snowflake-ml-python-Paketversion 1.1.1 allgemein verfügbar.
Die Snowflake ML Modeling-API verwendet bekannte Python-Frameworks wie scikit-learn, LightGBM und XGBoost für die Vorverarbeitung von Daten, das Feature-Engineering und das Training von Modellen in Snowflake.
Die Entwicklung von Modellen mit Snowflake ML-Modeling bietet folgende Vorteile:
Feature-Engineering und Vorverarbeitung: Verbessern Sie die Performance und Skalierbarkeit mit verteilter Ausführung für häufig verwendete Scikit-learn-Vorverarbeitungsfunktionen.
Modelltraining: Beschleunigen Sie das Training für Scikit-learn-, XGBoost- und LightGBM-Modelle, ohne manuell gespeicherte Prozeduren oder benutzerdefinierte Funktionen (UDFs) erstellen zu müssen, durch Verwendung der verteilten Hyperparameter-Optimierung.
Tipp
Unter Einführung in das maschinelle Lernen finden Sie ein Beispiel für einen durchgängigen ML-Workflow, einschließlich der Modellierungs-API.
Bemerkung
Bei diesem Thema wird davon ausgegangen, dass snowflake-ml-python und seine Abhängigkeiten bei der Modellierung bereits installiert sind. Siehe Lokale Verwendung von Snowflake ML.
Entwicklung von Modellen¶
Mit Container Runtime for ML, verfügbar in Notebooks on Container Runtime, können Sie populäre Open-Source ML Pakete mit Ihren Snowflake-Daten verwenden, indem Sie einen oder mehrere GPU-Knoten innerhalb der Snowflake Cloud nutzen und so Sicherheit und Governance für den gesamten ML-Workflow gewährleisten. Die enthaltenen Daten zum Laden und Trainieren APIs werden automatisch auf alle verfügbaren CPUs oder GPUs eines Knotens verteilt, was das Trainieren von Modellen mit großen Datensätzen beschleunigt.
Weitere Informationen finden Sie unter Erste Schritte mit Snowflake Notebook Container Runtime, in dem ein einfacher ML Workflow vorgestellt wird, der die Möglichkeiten der Container Runtime für ML nutzt.
Neben der Flexibilität und Leistungsfähigkeit von Container Runtime für ML bietet Snowflake ML Modeling API Schätzer- und Transformer, die APIs ähnlich denen der Bibliotheken scikit-learn, xgboost und lightgbm sind. Sie können diese APIs verwenden, um Modelle des maschinellen Lernens zu erstellen und zu trainieren, die mit Snowflake ML-Operationen wie dem Snowpark Model Registry verwendet werden können.
Beispiele¶
Schauen Sie sich die folgenden Beispiele an, um einen Eindruck von den Ähnlichkeiten zwischen Snowflake Modeling API und den Bibliotheken für maschinelles Lernen zu bekommen, die Sie vielleicht kennen.
Vorverarbeitung¶
Dieses Beispiel veranschaulicht die Verwendung der Datenvorverarbeitungs- und Datentransformationsfunktionen von Snowflake Modeling. Die beiden im Beispiel verwendeten Vorverarbeitungsfunktionen (MixMaxScaler und OrdinalEncoder) nutzen die Snowflake-Engine für die verteilte Verarbeitung, um erhebliche Leistungsverbesserungen gegenüber clientseitigen oder gespeicherten Prozedurimplementierungen zu erzielen. Weitere Details dazu finden Sie unter Verteilte Vorverarbeitung.
import numpy as np
import pandas as pd
import random
import string
from sklearn.datasets import make_regression
from snowflake.ml.modeling.preprocessing import MinMaxScaler, OrdinalEncoder
from snowflake.ml.modeling.pipeline import Pipeline
from snowflake.snowpark import Session
# Create a session with your preferred method
# session =
NUMERICAL_COLS = ["X1", "X2", "X3"]
CATEGORICAL_COLS = ["C1", "C2", "C3"]
FEATURE_COLS = NUMERICAL_COLS + CATEGORICAL_COLS
CATEGORICAL_OUTPUT_COLS = ["C1_OUT", "C2_OUT", "C3_OUT"]
FEATURE_OUTPUT_COLS = ["X1_FEAT_OUT", "X2_FEAT_OUT", "X3_FEAT_OUT", "C1_FEAT_OUT", "C2_FEAT_OUT", "C3_FEAT_OUT"]
# Create a dataset with numerical and categorical features
X, _ = make_regression(
n_samples=1000,
n_features=3,
noise=0.1,
random_state=0,
)
X = pd.DataFrame(X, columns=NUMERICAL_COLS)
def generate_random_string(length):
return "".join(random.choices(string.ascii_uppercase, k=length))
categorical_feature_length = 2
categorical_features = {}
for c in CATEGORICAL_COLS:
categorical_column = [generate_random_string(categorical_feature_length) for _ in range(X.shape[0])]
categorical_features[c] = categorical_column
X = X.assign(**categorical_features)
features_df = session.create_dataframe(X)
# Fit a pipeline with OrdinalEncoder and MinMaxScaler on Snowflake
pipeline = Pipeline(
steps=[
(
"OE",
OrdinalEncoder(
input_cols=CATEGORICAL_COLS,
output_cols=CATEGORICAL_OUTPUT_COLS,
)
),
(
"MMS",
MinMaxScaler(
input_cols=NUMERICAL_COLS + CATEGORICAL_OUTPUT_COLS,
output_cols=FEATURE_OUTPUT_COLS,
)
),
]
)
pipeline.fit(features_df)
# Use the pipeline to transform a dataset.
result = pipeline.transform(features_df)
Laden von Daten¶
![]() Vorschau-Feature – Offen
Vorschau-Feature – Offen
Verfügbar bei allen Konten.
Dieses Beispiel zeigt, wie Sie Daten aus einer Snowflake-Tabelle in ein pandas-DataFrame oder ein pytorch-Dataset laden können. Dazu verwenden Sie die DataConnector API, die das Laden von Daten auf mehrere Kerne oder GPUs verteilt, um das Laden zu beschleunigen.
Bemerkung
Die DataConnector API ist in der Container Runtime für ML verfügbar und kann von Snowsight-Notebooks aus genutzt werden, die auf Snowpark Container Services (SPCS) laufen.
from snowflake.ml.data.data_connector import DataConnector
# Retrieve data from a snowflake table
table_name = 'LARGE_TABLE_MULTIPLE_GBs'
snowpark_df = session.table(table_name)
# Materialize it into a pandas dataframe using DataConnector
pandas_df = DataConnector.from_dataframe(snowpark_df).to_pandas()
# Materialize it into a pytroch dataset using DataConnector
torch_dataset = data.to_torch_dataset(batch_size=1024)
Training¶
Dieses Beispiel zeigt, wie ein einfaches xgboost-Klassifizierungsmodell mit Snowflake ML Modeling trainiert und dann Vorhersagen erstellt werden. Die API ist hier ähnlich wie xgboost, mit nur wenigen Unterschieden bezüglich der Angabe der Spalten. Weitere Informationen zu diesen Unterschieden finden Sie unter Allgemeine Unterschiede der API.
import pandas as pd
from sklearn.datasets import make_classification
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session
# Create a session with your preferred method
# session =
FEATURE_COLS = ["X1", "X2", "X3", "X4", "X5", "X6"]
LABEL_COLS = ["Y"]
OUTPUT_COLS = ["PREDICTIONS"]
# Set up data.
X, y = make_classification(
n_samples=40000,
n_features=6,
n_informative=4,
n_redundant=1,
random_state=0,
shuffle=True,
)
X = pd.DataFrame(X, columns=FEATURE_COLS)
y = pd.DataFrame(y, columns=LABEL_COLS)
features_pandas = pd.concat([X, y], axis=1)
features_df = session.create_dataframe(features_pandas)
# Train an XGBoost model on snowflake.
xgboost_model = XGBClassifier(
input_cols=FEATURE_COLS,
label_cols=LABEL_COLS,
output_cols=OUTPUT_COLS
)
xgboost_model.fit(features_df)
# Use the model to make predictions.
predictions = xgboost_model.predict(features_df)
predictions[OUTPUT_COLS].show()
Feature-Vorverarbeitung von Merkmalen und Training auf nicht synthetischen Daten¶
In diesem Beispiel werden die Daten hochenergetischer Gammateilchen von einem bodengestützten Luft-Tscherenkow-Teleskop verwendet. Das Teleskop beobachtet hochenergetische Gammateilchen, indem es sich die Strahlung geladener Teilchen zunutze macht, die in den von den Gammastrahlen ausgelösten elektromagnetischen Schauern erzeugt werden. Der Detektor erfasst die Cherenkov-Strahlung (sichtbare bis ultraviolette Wellenlängen), die durch die Atmosphäre dringt, und ermöglicht so die Rekonstruktion der Parameter des Gammaschauers. Das Teleskop spürt auch Hadronenstrahlen auf, die in kosmischen Schauern häufig vorkommen und Signale erzeugen, die Gammastrahlen nachahmen.
Ziel ist es, ein Klassifizierungsmodell zur Unterscheidung von Gammastrahlen und Hadronenstrahlen zu entwickeln. Das Modell ermöglicht es den Wissenschaftlern, das Hintergrundrauschen herauszufiltern und sich auf die echten Gammastrahlensignale zu konzentrieren. Gammastrahlen ermöglichen es den Wissenschaftlern, kosmische Ereignisse wie die Geburt und das Sterben von Sternen, kosmische Explosionen und das Verhalten von Materie unter extremen Bedingungen zu beobachten.
Die Teilchendaten stehen zum Download bereit unter MAGIC-Gammateleskop. Laden Sie die Daten herunter, und entpacken Sie sie. Setzen Sie die Variable DATA_FILE_PATH so, dass sie auf die Datendatei verweist, und führen Sie den folgenden Code aus, um die Daten in Snowflake zu laden.
DATA_FILE_PATH = "~/Downloads/magic+gamma+telescope/magic04.data"
# Setup
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session
import posixpath
import os
##
# Note: Create session https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/api/snowflake.snowpark.Session
##
session = Session.builder.configs(SnowflakeLoginOptions()).create()
session.sql("""
CREATE OR REPLACE TABLE Gamma_Telescope_Data(
F_LENGTH FLOAT,
F_WIDTH FLOAT,
F_SIZE FLOAT,
F_CONC FLOAT,
F_CONC1 FLOAT,
F_ASYM FLOAT,
F_M3_LONG FLOAT,
F_M3_TRANS FLOAT,
F_ALPHA FLOAT,
F_DIST FLOAT,
CLASS VARCHAR(10))
""").collect()
session.sql("CREATE OR REPLACE STAGE SNOWPARK_ML_TEST_DATA_STAGE").collect()
session.file.put(
DATA_FILE_PATH,
"SNOWPARK_ML_TEST_DATA_STAGE/magic04.data",
auto_compress=False,
overwrite=True,
)
session.sql("""
COPY INTO Gamma_Telescope_Data FROM @SNOWPARK_ML_TEST_DATA_STAGE/magic04.data
FILE_FORMAT = (TYPE = 'CSV' field_optionally_enclosed_by='"',SKIP_HEADER = 0);
""").collect()
session.sql("select * from Gamma_Telescope_Data limit 5").collect()
Sobald Sie die Daten geladen haben, verwenden Sie den folgenden Code zum Trainieren und Vorhersagen unter Verwendung der folgenden Schritte.
Nehmen Sie eine Vorverarbeitung der Daten vor:
Ersetzen Sie fehlende Werte durch den Mittelwert.
Zentrieren Sie die Daten mit einem Standard-Skalierer.
Trainieren eines xgboost-Klassifikators, um den Typ der Ereignisse zu bestimmen.
Testen der Genauigkeit des Modells anhand von Trainings- und Test-Datensets.
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.modeling.preprocessing import StandardScaler
from snowflake.ml.modeling.impute import SimpleImputer
from snowflake.ml.modeling.pipeline import Pipeline
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.modeling.metrics import accuracy_score
##
# Note: Create session https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/api/snowflake.snowpark.Session
##
session = Session.builder.configs(SnowflakeLoginOptions()).create()
# Step 1: Create train and test dataframes
all_data = session.sql("select *, IFF(CLASS = 'g', 1.0, 0.0) as LABEL from Gamma_Telescope_Data").drop("CLASS")
train_data, test_data = all_data.random_split(weights=[0.9, 0.1], seed=0)
# Step 2: Construct training pipeline with preprocessing and modeling steps
FEATURE_COLS = [c for c in train_data.columns if c != "LABEL"]
LABEL_COLS = ["LABEL"]
pipeline = Pipeline(steps = [
("impute", SimpleImputer(input_cols=FEATURE_COLS, output_cols=FEATURE_COLS)),
("scaler", StandardScaler(input_cols=FEATURE_COLS, output_cols=FEATURE_COLS)),
("model", XGBClassifier(input_cols=FEATURE_COLS, label_cols=LABEL_COLS))
])
# Step 3: Train
pipeline.fit(train_data)
# Step 4: Eval
predict_on_training_data = pipeline.predict(train_data)
training_accuracy = accuracy_score(df=predict_on_training_data, y_true_col_names=["LABEL"], y_pred_col_names=["OUTPUT_LABEL"])
predict_on_test_data = pipeline.predict(test_data)
eval_accuracy = accuracy_score(df=predict_on_test_data, y_true_col_names=["LABEL"], y_pred_col_names=["OUTPUT_LABEL"])
print(f"Training accuracy: {training_accuracy} \nEval accuracy: {eval_accuracy}")
Verteilte Hyperparameter-Optimierung¶
Dieses Beispiel zeigt, wie die verteilte Hyperparameter-Optimierung mit der Snowflake-Implementierung von GridSearchCV von scikit-learn durchgeführt wird.. Die einzelnen Ausführungen werden parallel unter Verwendung verteilter Warehouse-Computeressourcen ausgeführt. Weitere Informationen zur Optimierung verteilter Hyperparameter finden Sie unter Verteilte Hyperparameter-Optimierung.
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from sklearn.datasets import make_classification
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.modeling.model_selection.grid_search_cv import GridSearchCV
FEATURE_COLS = ["X1", "X2", "X3", "X4", "X5", "X6"]
LABEL_COLS = ["Y"]
OUTPUT_COLS = ["PREDICTIONS"]
# Create a session using your favorite login option.
# In this example we use a session builder with `SnowflakeLoginOptions`.
session = Session.builder.configs(SnowflakeLoginOptions()).create()
# Set up data.
def set_up_data(session: Session, n_samples: int) -> DataFrame:
X, y = make_classification(
n_samples=n_samples,
n_features=6,
n_informative=2,
n_redundant=0,
random_state=0,
shuffle=True,
)
X = pd.DataFrame(X, columns=FEATURE_COLS)
y = pd.DataFrame(y, columns=LABEL_COLS)
features_pandas = pd.concat([X, y], axis=1)
features_pandas.head()
features_df = session.create_dataframe(features_pandas)
return features_df
features_df = set_up_data(session, 10**4)
# Create a warehouse to use for the tuning job.
session.sql(
"""
CREATE or replace warehouse HYPERPARAM_WH
WITH WAREHOUSE_SIZE = 'X-SMALL'
WAREHOUSE_TYPE = 'Standard'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = FALSE;"""
).collect()
session.use_warehouse("HYPERPARAM_WH")
# Tune an XGB Classifier model using sklearn GridSearchCV.
DISTRIBUTIONS = dict(
n_estimators=[10, 50],
learning_rate=[0.01, 0.1, 0.2],
)
estimator = XGBClassifier()
grid_search_cv = GridSearchCV(estimator=estimator, param_grid=DISTRIBUTIONS, input_cols=FEATURE_COLS, label_cols=LABEL_COLS, output_cols=OUTPUT_COLS)
grid_search_cv.fit(features_df)
# Use the best model to make predictions.
predictions = grid_search_cv.predict(features_df)
predictions[OUTPUT_COLS].show()
# Retrieve sklearn model, and print the best score
sklearn_grid_search_cv = grid_search_cv.to_sklearn()
print(sklearn_grid_search_cv.best_score_)
Um die Leistungsfähigkeit der verteilten Optimierung wirklich zu erkennen, trainieren Sie mit einer Million Datenzeilen.
large_features_df = set_up_data(session, 10**6)
# Scale up the warehouse for a faster fit. This takes 2m15s to run on an L warehouse versus 4m5s on a XS warehouse.
session.sql(f"ALTER WAREHOUSE {session.get_current_warehouse()} SET WAREHOUSE_SIZE='LARGE'").collect()
grid_search_cv.fit(large_features_df)
print(grid_search_cv.to_sklearn().best_score_)
Snowflake-Modeling-Klassen¶
Alle Snowflake-Modellierungs- und Vorverarbeitungsklassen befinden sich im Namespace snowflake.ml.modeling. Die Module von snowflake-ml-python haben dieselben Namen wie die entsprechenden Module im sklearn-Namespace. Das Modul, das sklearn.calibration entspricht, ist zum Beispiel snowflake.ml.modeling.calibration. Die Module xgboost und lightgbm entsprechen den Modulen snowflake.ml.modeling.xgboost bzw. snowflake.ml.modeling.lightgbm.
Die Modeling-API bietet Wrapper für die zugrunde liegenden scikit-learn-, xgboost- und lightgbm-Klassen, von denen die meisten im virtuellen Warehouse als gespeicherte Prozeduren (die auf einem einzigen Warehouse-Knoten ausgeführt werden) ausgeführt werden. Es werden nicht alle Klassen von scikit-learn unterstützt. Eine Auflistung der derzeit verfügbaren Klassen finden Sie in der Python-API-Referenz.
Einige Klassen (u. a. Vorverarbeitungs- und Metrikklassen) unterstützen die verteilte Ausführung und können im Vergleich zur lokalen Ausführung derselben Operationen erhebliche Leistungsvorteile bieten. Weitere Informationen dazu finden Sie unter Verteilte Vorverarbeitung und Verteilte Hyperparameter-Optimierung. In der folgenden Tabelle sind die spezifischen Klassen aufgeführt, die eine verteilte Ausführung unterstützen.
|
Verteilte Klassen |
|---|---|
|
|
|
|
|
|
|
|
Allgemeine Unterschiede der API¶
Tipp
In der API-Referenz finden Sie alle Details zur Modellierung API.
Die Snowflake-Modellierungsklassen umfassen Algorithmen zur Datenvorverarbeitung, -umwandlung und -vorhersage auf der Grundlage von scikit-learn, xgboost und lightgbm. Die Snowpark Python-Klassen sind Ersatz für die entsprechenden Klassen aus den Originalpaketen mit ähnlichen Signaturen. Diese APIs sind jedoch für Snowpark-DataFrames und nicht für NumPy-Arrays konzipiert.
Obwohl die API ähnlich wie scikit-learn ist, gibt es einige wichtige Unterschiede. In diesem Abschnitt wird erklärt, wie Sie die Methoden __init__ (Konstruktor), fit und predict für die Snowflake-Schätzer- und Transformer-Klassen aufrufen.
Der Konstruktor aller Snowflake- Modellklassen akzeptiert zusätzlich zu den Parametern, die von den entsprechenden Klassen in scikit-learn, xgboost oder lightgbm akzeptiert werden, fünf weitere Parameter(
input_cols,output_cols,sample_weight_col,label_colsunddrop_input_cols), fünf weitere Parameter. Dabei handelt es sich um Zeichenfolgen oder Sequenzen von Zeichenfolgen, die die Namen der Eingabespalten, der Ausgabespalten, der Spalte für die Gewichtung des Samples und der Beschriftungsspalten in einem Snowpark- oder Pandas-DataFrame angeben. Wenn einige der von Ihnen verwendeten Datensets unterschiedliche Namen haben, können Sie diese Namen nach der Instanziierung mithilfe einer der bereitgestellten Set-Methoden ändern, z. B.set_input_cols.Da Sie die Spaltennamen bei der Instanziierung der Klasse (oder danach mithilfe von Set-Methoden) angeben, akzeptieren die Methoden
fitundpredictein einziges DataFrame anstelle von separaten Arrays für Inputs, Gewichtungen und Labels. Die angegebenen Spaltennamen werden infitoderpredictfür den Zugriff auf die entsprechende DataFrame-Spalte verwendet. Weitere Informationen dazu finden Sie unter fit und predict.Die Methoden
transformundpredictgeben einen DataFrame zurück, der alle Spalten aus dem an die Methode übergebenen DataFrame enthält, wobei die Ausgabe der Vorhersage in zusätzlichen Spalten gespeichert wird. Sie können die Transformation an Ort und Stelle vornehmen, indem Sie für die Ausgabespalten dieselben Namen wie für die Eingabespalten angeben, oder Sie lassen die Eingabespalten weg, indem Siedrop_input_cols = Trueübergeben. Die Äquivalenten zu scikit-learn, xgboost und lightgbm geben Arrays zurück, die nur die Ergebnisse enthalten.Snowpark Python-Transformer verfügen nicht über eine
fit_transform-Methode. Wie bei scikit-learn wird die Parametervalidierung jedoch nur in der Methodefitausgeführt, sodass Siefitirgendwann vortransformaufrufen müssen, auch wenn der Transformer keine Anpassung vornimmt.fitgibt den Transformer zurück, sodass die Methodenaufrufe verkettet werden können, z. B.Binarizer(threshold=0.5).fit(df).transform(df).Snowflake-Transformer bieten derzeit keine
inverse_transform-Methode. In vielen Anwendungsfällen ist diese Methode unnötig, da die Eingabespalten standardmäßig im Ausgabe-Datenframe beibehalten werden.
Sie können jedes Snowflake-Modellierungsobjekt in das entsprechende scikit-learn-, xgboost- oder lightgbm-Objekt konvertieren, sodass Sie alle Methoden und Attribute des zugrunde liegenden Typs nutzen können. Siehe Abrufen des zugrunde liegenden Modells.
Erstellen eines Modells¶
Zusätzlich zu den Parametern, die von den einzelnen scikit-learn-Modellklassen akzeptiert werden, akzeptieren alle Modellierungsklassen bei der Instanziierung die folgenden weiteren Parameter.
Diese Parameter sind technisch gesehen alle optional, aber Sie werden oft entweder input_cols oder output_cols oder beides angeben wollen. label_cols und sample_weight_col sind in bestimmten, in der Tabelle aufgeführten Situationen erforderlich, können aber in anderen Fällen weggelassen werden.
Tipp
Alle Spaltennamen müssen die von Snowflake vorgegebenen Anforderungen an Bezeichner entsprechen. Um beim Erstellen einer Tabelle die Groß-/Kleinschreibung beibehalten oder Sonderzeichen (außer Dollarzeichen und Unterstrich) verwenden zu können, müssen die Spaltennamen in Anführungszeichen eingeschlossen werden. Verwenden Sie Spaltennamen in Großbuchstaben, wann immer dies möglich ist, um die Kompatibilität mit Pandas-DataFrames zu wahren, das Groß-/Kleinschreibung unterscheidet.
from snowflake.ml.modeling.preprocessing import MinMaxScaler
from snowflake.snowpark import Session
# Snowflake identifiers are not case sensitive by default.
# These column names will be automatically updated to ["COLUMN_1", "COLUMN_2", "COLUMN_3"] by the Snowpark DataFrame.
schema = ["column_1", "column_2", "column_3"]
df = session.create_dataframe([[1, 2, 3]], schema = schema)
df.show()
--------------------------------------
|"COLUMN_1" |"COLUMN_2" |"COLUMN_3"|
--------------------------------------
|1 |2 |3 |
--------------------------------------
# Identify the column names using the Snowflake identifier.
input_cols = ["COLUMN_1", "COLUMN_2", "COLUMN_3"]
mms = MinMaxScaler(input_cols=input_cols)
mms.fit(df)
# To maintain lower case column names, include a double quote within the string.
schema = ['"column_1"', '"column_2"', '"column_3"']
df = session.create_dataframe([[1, 2, 3]], schema = schema)
df.show()
----------------------------------------
|'"column_1"'|'"column_2"'|'"column_3"'|
----------------------------------------
|1 |2 |3 |
----------------------------------------
# Since no conversion took place, the schema labels can be used as the column identifiers.
mms = MinMaxScaler(input_cols=schema)
mms.fit(df)
Parameter |
Beschreibung |
|---|---|
|
Eine Zeichenfolge oder eine Liste von Zeichenfolgen, die Spaltennamen darstellen, die Features enthalten. Wenn Sie diesen Parameter weglassen, werden alle Spalten im Eingabe-DataFrame, mit Ausnahme der durch die Parameter |
|
Eine Zeichenfolge oder eine Liste von Zeichenfolgen, die die Namen von Spalten repräsentieren, die Beschriftungen enthalten. Für überwachte Schätzer müssen Sie Beschriftungsspalten angeben, da ein Ableiten dieser Spalten nicht möglich ist. Diese Beschriftungsspalten werden als Ziele für Modellvorhersagen verwendet und sollten deutlich von |
|
Eine Zeichenfolge oder eine Liste von Zeichenfolgen, die die Namen von Spalten repräsentieren, in denen die Ausgabe von Wenn Sie diesen Parameter weglassen, werden die Namen der Ausgabespalten durch Hinzufügen des Präfixes Um die Umwandlung an Ort und Stelle vorzunehmen, übergeben Sie für |
|
Eine Zeichenfolge oder eine Liste von Zeichenfolgen, die die Namen von Spalten repräsentieren, die von Training, Transformation und Inferenz ausgeschlossen werden sollen. Passthrough-Spalten bleiben zwischen dem Eingangs- und dem Ausgangs-DataFrames unberührt. Diese Option ist hilfreich, wenn Sie die Verwendung bestimmter Spalten, wie z. B. von Indexspalten, während des Trainings oder der Inferenz vermeiden möchten, ohne |
|
Eine Zeichenfolge mit dem Namen der Spalte, die die Gewichtung der Beispiele enthält. Dieses Argument ist für gewichtete Datensets erforderlich. |
|
Ein boolescher Wert, der angibt, ob die Eingabespalten aus dem Ergebnis-DataFrameentfernt werden. Der Standardwert ist |
Beispiel¶
Der DecisionTreeClassifier-Konstruktor hat in scikit-learn keine erforderlichen Argumente; alle Argumente haben Standardwerte. In scikit-learn könnten Sie also Folgendes schreiben:
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
In der Version dieser Klasse von Snowflake müssen Sie die Spaltennamen angeben (oder die Standardwerte akzeptieren, indem Sie sie nicht angeben). Im diesem Beispiel werden sie explizit angegeben.
Sie können einne DecisionTreeClassifier initialisieren, indem Sie die Argumente direkt an den Konstruktor übergeben oder indem Sie sie nach der Instanziierung als Attribute des Modells festlegen. (Die Attribute können jederzeit geändert werden.)
Als Konstruktor-Argumente:
from snowflake.ml.modeling.tree import DecisionTreeClassifier model = DecisionTreeClassifier( input_cols=feature_column_names, label_cols=label_column_names, sample_weight_col=weight_column_name, output_cols=expected_output_column_names )
Durch Einstellen von Modellattributen:
from snowflake.ml.modeling.tree import DecisionTreeClassifier model = DecisionTreeClassifier() model.set_input_cols(feature_column_names) model.set_label_cols(label_column_names) model.set_sample_weight_col(weight_column_name) model.set_output_cols(output_column_names)
fit¶
Der fit-Methode eines Snowflake-Klassifikators wird ein einzelner Snowpark- oder Pandas-Container DataFrame mit allen Spalten, einschließlich Features, Labels und Gewichtungen übergeben. Dies unterscheidet sich von der Methode fit von scikit-learn, die separate Eingaben für Features, Labels und Gewichtungen benötigt.
In scikit-learn sieht der Aufruf der Methode DecisionTreeClassifier.fit wie folgt aus:
model.fit(
X=df[feature_column_names], y=df[label_column_names], sample_weight=df[weight_column_name]
)
In fit von Snowflake müssen Sie nur die DataFrame übergeben. Sie haben die Namen der Eingabe-, Beschriftungs- und Gewichtungsspalten bereits bei der Initialisierung oder mithilfe von Konstruktionsmethoden festgelegt, wie unter Erstellen eines Modells gezeigt.
model.fit(df)
predict¶
Der predict-Methode wird ebenfalls ein einzelner Snowpark- oder Pandas-DataFrame mit allen Feature-Spalten übergeben. Das Ergebnis ist ein DataFrame, der alle Spalten des Eingabe-DataFrame unverändert enthält und an den die Ausgabespalten angehängt sind. Sie müssen die Ausgabespalten aus diesem DataFrame extrahieren. Dies unterscheidet sich von der Methode predict in scikit-learn, die nur die Ergebnisse zurückgibt.
Beispiel¶
In scikit-learn liefert predict nur die Vorhersageergebnisse:
prediction_results = model.predict(X=df[feature_column_names])
Um in Snowflake predict nur die Vorhersageergebnisse zu erhalten, extrahieren Sie die Ausgabespalten aus dem zurückgegebenen DataFrame. Hier ist output_column_names eine Liste mit den Namen der Ausgabespalten:
prediction_results = model.predict(df)[output_column_names]
Verteiltes Training und Inferenz mit SPCS¶
![]() Vorschau-Feature – Offen
Vorschau-Feature – Offen
Verfügbar bei allen Konten.
Bei der Ausführung in einem Snowflake-Notebook auf Snowpark Container Services (SPCS) werden Modelltraining und Inferenz für diese Modellierungsklassen auf dem zugrunde liegenden Compute-Cluster und nicht in einem Warehouse ausgeführt und transparent auf alle Knoten im Cluster verteilt, um alle verfügbaren Rechenkapazitäten zu nutzen.
Die Operationen für die Vorverarbeitung und die Metrik werden an das Warehouse weitergegeben. Viele Klassen für die Vorverarbeitung unterstützen die verteilte Ausführung, wenn sie im Warehouse ausgeführt werden; siehe Verteilte Vorverarbeitung.
Verteilte Vorverarbeitung¶
Viele Snowflake-Datenvorverarbeitungs- und Datentransformationsfunktionen werden mit der Snowflake-Engine für die verteilte Verarbeitung implementiert, die im Vergleich zur Ausführung auf einem einzelnen Knoten (d. h. gespeicherte Prozeduren) erhebliche Leistungsvorteile bietet. Eine Liste der Funktionen, die die verteilte Ausführung unterstützen, finden Sie unter Snowflake-Modeling-Klassen.
Das folgende Diagramm zeigt illustrative Leistungszahlen für große öffentliche Datensets, die in einem Snowpark-optimierten Medium-Warehouse ausgeführt werden, und vergleicht scikit-learn, das in gespeicherten Prozeduren ausgeführt wird, mit den verteilten Implementierungen von Snowflake. In vielen Szenarien kann Ihr Code 25 bis 50 Mal schneller laufen, wenn Sie Snowflake-Modellierungsklassen verwenden.
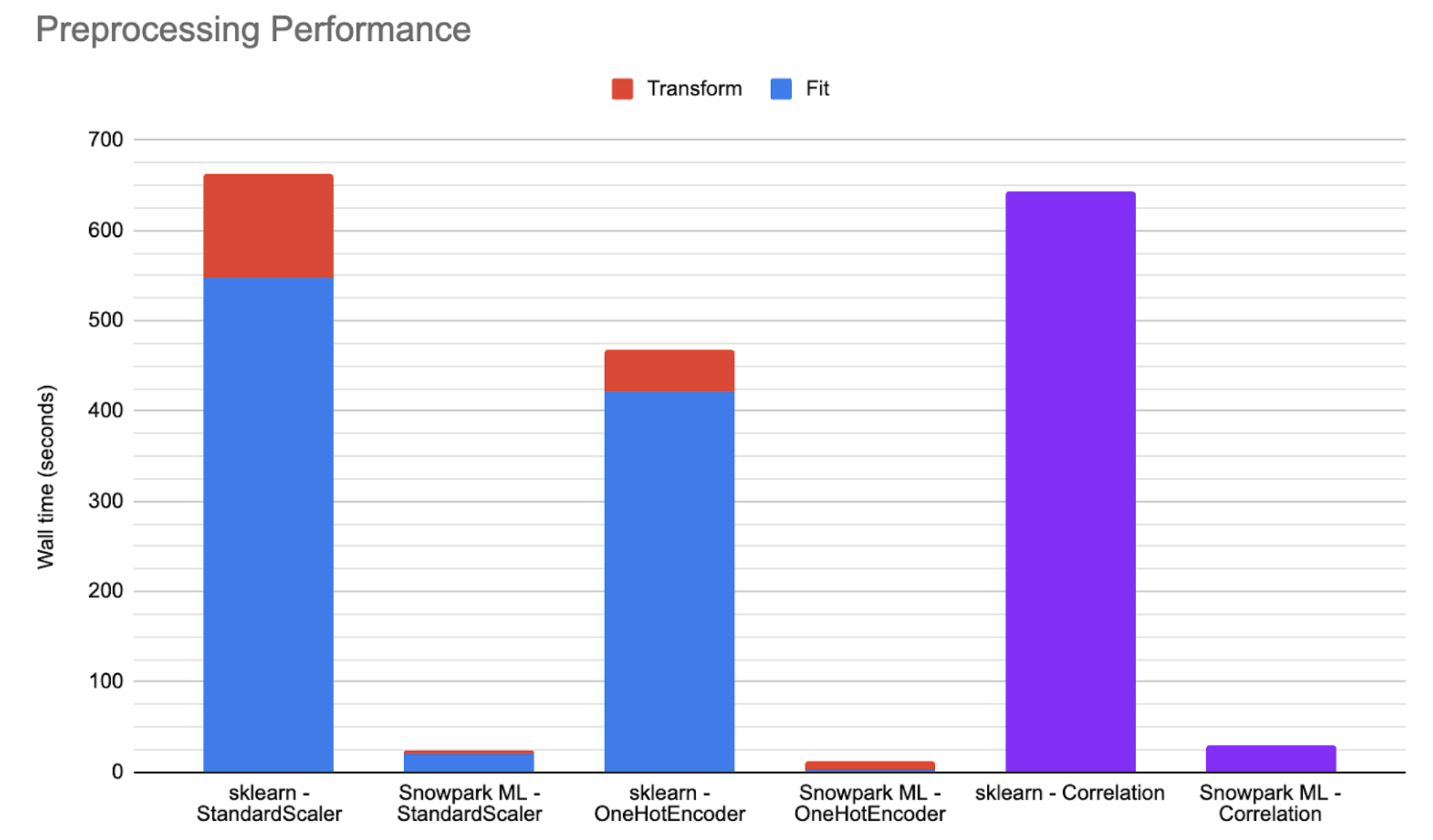
Verteilen von Anpassungen (fit)¶
Die fit-Methode eines Snowflake -Vorverarbeitungstransformers akzeptiert einen Snowpark- oder pandas- DataFrame, passt das Datenset an und gibt den angepassten Transformer zurück.
Bei Snowpark-DataFrames wird die verteilte Anpassung der SQL-Engine verwendet. Der Transformer generiert SQL-Abfragen, um die erforderlichen Zustände (wie Mittelwert, Maximum oder Anzahl) zu berechnen. Diese Abfragen werden dann von Snowflake ausgeführt, und die Ergebnisse werden lokal materialisiert. Bei komplexen Zuständen, die nicht in SQL berechnet werden können, holt der Transformer Zwischenergebnisse aus Snowflake und führt lokale Berechnungen über Metadaten durch.
Bei komplexen Transformern, die während der Transformation temporäre Zustandstabellen benötigen (z. B.
OneHotEncoderoderOrdinalEncoder), werden diese Tabellen lokal mit pandas-DataFrames dargestellt.pandas-DataFrames werden lokal angepasst, ähnlich wie bei der Anpassung mit scikit-learn. Der Transformer erstellt einen entsprechenden scikit-learn-Transformer mit den bereitgestellten Parametern. Dann wird der scikit-learn-Transformator angepasst, und der Snowflake-Transformer leitet die erforderlichen Zustände aus dem scikit-learn-Objekt ab.
Verteilen von Transformationen (transform)¶
Die transform-Methode eines -Vorverarbeitungstransformers nimmt einen Snowpark- oder Pandas-DataFrame entgegen, transformiert diesen und gibt einen transformiertes Datenset zurück.
Bei Snowpark-DataFrames wird die verteilte Transformation mit der SQL-Engine ausgeführt. Der angepasste Transformer generiert einen Snowpark-DataFrame mit zugrunde liegenden SQL-Abfragen, die das transformierte Datenset darstellen. Die Methode
transformführt bei einfachen Transformationen (z. B.StandardScaleroderMinMaxScaler) eine Auswertung im Lazy-Modus durch, sodass bei der Methodetransformim Grunde keine Transformation ausgeführt wird.Bestimmte komplexe Transformationen erfordern jedoch eine Ausführung. Dazu gehören Transformer, die während der Transformation temporäre Zustandstabellen (wie
OneHotEncoderundOrdinalEncoder) benötigen. Bei einer solchen Transformation erstellt der Transformer eine temporäre Tabelle aus dem Pandas-DataFrame (das den Zustand des Objekts speichert) für Joins und andere Operationen.Wenn bestimmte Parameter eingestellt sind, z. B. wenn der Transformator so eingestellt ist, dass er unbekannte Werte, die während der Transformation gefunden werden, durch das Auslösen von Fehlern behandelt, materialisiert der Transformator die Daten, einschließlich der Spalten, unbekannten Werte und so weiter.
Pandas-DataFrames werden lokal transformiert, ähnlich wie bei der Transformation mit scikit-learn. Der Transformer erstellt einen entsprechenden scikit-learn-Transformer unter Verwendung der
to_sklearn-API und führt die Transformation im Arbeitsspeicher aus.
Verteilte Hyperparameter-Optimierung¶
Das Optimieren der Hyperparameter ist ein integraler Bestandteil des Data Science-Workflows. Die Snowflake-API stellt verteilte Implementierungen der scikit-learn-GridSearchCV und RandomizedSearchCV APIs zur Verfügung, um effizientes Hyperparameter-Tuning sowohl auf Ein-Knoten- als auch auf Multi-Knoten-Warehouses zu ermöglichen.
Tipp
Snowflake aktiviert standardmäßig die verteilte Hyperparameter-Optimierung. Um diese zu deaktivieren, verwenden Sie den folgenden Python-Import.
import snowflake.ml.modeling.parameters.disable_distributed_hpo
Das kleinste virtuelle Snowflake-Warehouse (XS) oder das Snowpark-optimierte Warehouse (M) hat einen einzigen Knoten. Mit jeder weiteren Vergrößerung verdoppelt sich die Anzahl der Knoten.
Bei Ein-Knoten-Warehouses (XS) wird standardmäßig die volle Kapazität des Knotens mithilfe des Joblib-Multiprocessing-Frameworks von scikit-learn genutzt.
Tipp
Jede Anpassungsoperation erfordert eine eigene Kopie des in den RAM geladenen Trainingsdatensets. Um extrem große Datensätze zu verarbeiten, deaktivieren Sie die verteilte Hyperparameter-Optimierung (mit import snowflake.ml.modeling.parameters.disable_distributed_hpo), und setzen Sie den Parameter n_jobs auf 1, um die Parallelität zu minimieren.
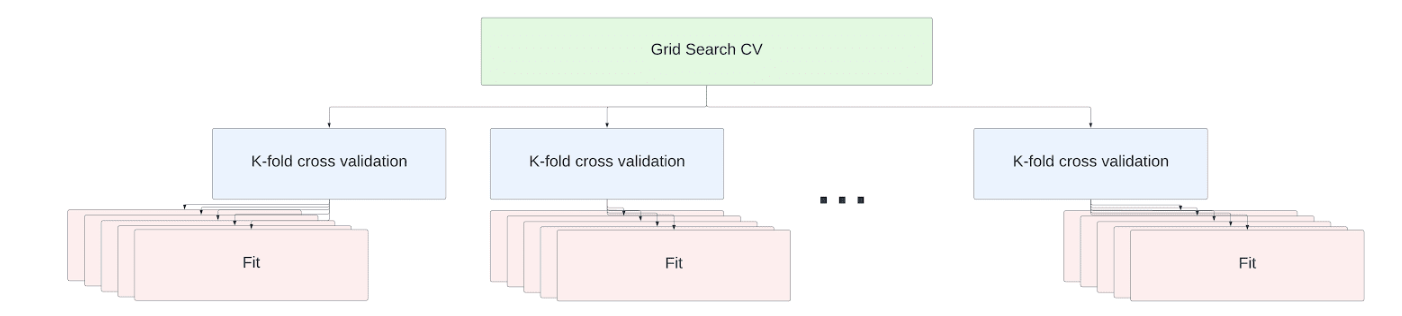
Bei Warehouses mit mehreren Knoten werden die fit-Operationen innerhalb Ihres Tuning-Jobs für die Kreuzvalidierung auf die Knoten verteilt. Für das Hochskalieren sind keine Codeänderungen erforderlich. Die Anpassungen des Schätzers werden parallel auf allen verfügbaren Kernen aller Knoten des Warehouses ausgeführt.
Zur Veranschaulichung betrachten wir das Datenset zum Wohnen in Kalifornien, das mit der scikit-learn-Bibliothek bereitgestellt wird. Die Daten umfassen 20.640 Datenzeilen mit den folgenden Informationen:
MedInc: Mittleres Einkommen im Block
HouseAge: Mittleres Alter der Häuser im Block
AveRooms: Durchschnittliche Anzahl der Zimmer pro Haushalt
AveBedrms: Durchschnittliche Anzahl der Schlafzimmer pro Haushalt
Population: Bevölkerung im Block
AveOccup: Durchschnittliche Anzahl der Haushaltsmitglieder
Latitude, Longitude: Längen- und Breitengrad
Das Ziel des Datensets ist das mittlere Einkommen, ausgedrückt in Hunderttausenden von Dollar.
In diesem Beispiel führen wir eine Grid-Search-Kreuzvalidierung mit einem Random-Forest-Regressor durch, um die beste Hyperparameterkombination zur Vorhersage des mittleren Einkommens zu erhalten.
from snowflake.ml.modeling.ensemble.random_forest_regressor import RandomForestRegressor
from snowflake.ml.modeling.model_selection.grid_search_cv import GridSearchCV
from sklearn import datasets
def load_housing_data() -> DataFrame:
input_df_pandas = datasets.fetch_california_housing(as_frame=True).frame
# Set the columns to be upper case for consistency with Snowflake identifiers.
input_df_pandas.columns = [c.upper() for c in input_df_pandas.columns]
input_df = session.create_dataframe(input_df_pandas)
return input_df
input_df = load_housing_data()
# Use all the columns besides the median value as the features
input_cols = [c for c in input_df.columns if not c.startswith("MEDHOUSEVAL")]
# Set the target median value as the only label columns
label_cols = [c for c in input_df.columns if c.startswith("MEDHOUSEVAL")]
DISTRIBUTIONS = dict(
max_depth=[80, 90, 100, 110],
min_samples_leaf=[1,3,10],
min_samples_split=[1.0, 3,10],
n_estimators=[100,200,400]
)
estimator = RandomForestRegressor()
n_folds = 5
clf = GridSearchCV(estimator=estimator, param_grid=DISTRIBUTIONS, cv=n_folds, input_cols=input_cols, label_cols=label_col)
clf.fit(input_df)
Die Ausführung dieses Beispiels dauert bei einem Snowpark-optimierten Medium-Warehouse (Einzelknoten) etwas mehr als 7 Minuten, bei einem X-Large-Warehouse aber nur 3 Minuten.
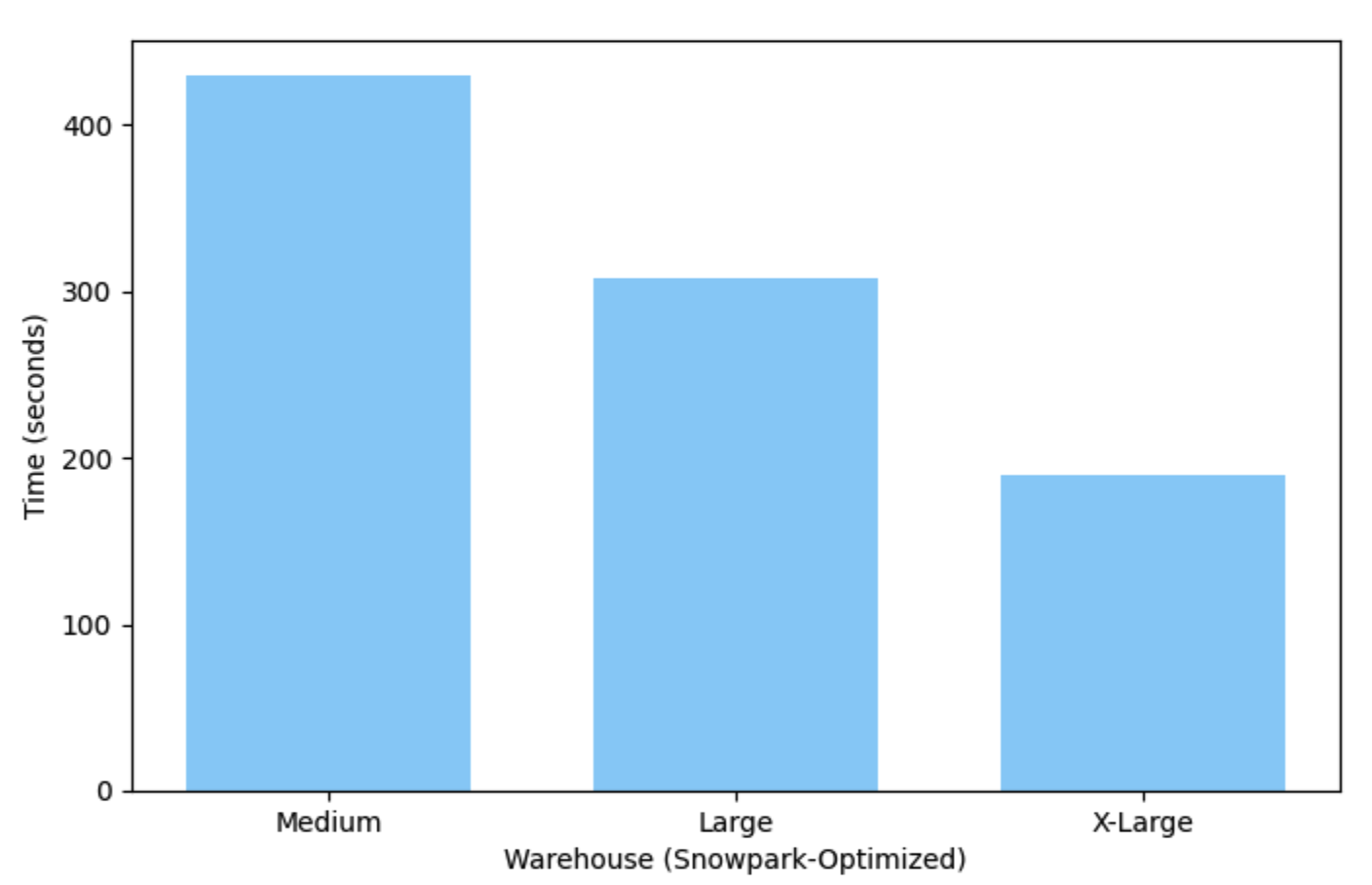
Bereitstellen und Ausführen Ihres Modells¶
Das Ergebnis des Trainings eines Modells ist ein Python-Modellobjekt. Sie können das trainierte Modell für Vorhersagen verwenden, indem Sie die Methode predict des Modells aufrufen. Dadurch wird eine temporäre benutzerdefinierte Funktion zur Ausführung des Modells in Ihrem virtuellen Snowflake-Warehouse erstellt. Diese Funktion wird am Ende Ihrer Snowflake Sitzung automatisch gelöscht (z. B. wenn Ihr Skript endet oder wenn Sie Ihr Notebook schließen).
Um die benutzerdefinierte Funktion nach dem Ende Ihrer Sitzung beizubehalten, können Sie sie auch manuell erstellen. Weitere Informationen dazu finden Sie im Quickstart zu diesem Thema.
Die Snowflake-Modellregistrierung unterstützt auch persistente Modelle und erleichtert deren Suche und Bereitstellung. Siehe Snowflake Model Registry.
Partitionierte benutzerdefinierte Modelle¶
Die Modellregistrierung unterstützt auch eine spezielle Art von benutzerdefinierten Modellen, bei denen Anpassung und Inferenz parallel für eine Reihe von Partitionen ausgeführt werden. Dies kann eine leistungsstarke Methode sein, um viele Modelle auf einmal aus einem Datensatz zu erstellen und die Inferenz sofort auszuführen. Weitere Informationen finden Sie unter Verwenden partitionierter Modelle.
Pipeline für mehrere Transformationen¶
Bei scikit-learn ist es üblich, eine Reihe von Transformationen mit Hilfe einer Pipeline auszuführen. scikit-learn-Pipelines funktionieren nicht mit Snowflake-Klassen, daher wird eine Snowflake-Version von sklearn.pipeline.Pipeline zur Ausführung einer Reihe von Transformationen bereitgestellt. Diese Klasse befindet sich im Paket snowflake.ml.modeling.pipeline und funktioniert genauso wie die Version von scikit-learn.
Abrufen des zugrunde liegenden Modells¶
Snowflake ML-Modelle können mit den folgenden Methoden (je nach Bibliothek) entpackt (unwrapped) werden, d. h. in die zugrunde liegenden Modelltypen von Drittanbietern konvertiert werden:
to_sklearnto_xgboostto_lightgbm
Alle Attribute und Methoden des zugrunde liegenden Modells können dann aufgerufen und lokal für den Schätzer ausgeführt werden. Beispielsweise konvertieren wir im GridSearchCV-Beispiel den Grid-Search-Schätzer in ein Scikit-Learn-Objekt, um das beste Ergebnis zu erhalten.
best_score = grid_search_cv.to_sklearn().best_score_
Bekannte Einschränkungen¶
Die Schätzer und Transformer von Snowflake unterstützen derzeit weder spärliche Eingaben noch spärliche Antworten. Wenn Sie spärliche Daten haben, konvertieren Sie sie in ein dichtes Format, bevor Sie sie an die Schätzer oder Transformer von Snowflake weitergeben.
Das
snowflake-ml-python-Paket unterstützt derzeit keine Matrix-Datentypen. Jede Operation auf Schätzern und Transformern, die eine Matrix als Ergebnis liefern würde, schlägt fehl.Es ist nicht garantiert, dass die Reihenfolge der Zeilen in den Ergebnisdaten mit der Reihenfolge der Zeilen in den Eingabedaten übereinstimmt.
Snowflake ML unterstützt noch keine pandas on Snowflake DataFrames. Konvertieren Sie den Pandas on Snowflake-Datenrahmen in einen Snowpark-Datenrahmen, um ihn mit den Snowflake-Modellierungsklassen zu verwenden. Das folgende Beispiel konvertiert eine DataFrame, die wir aus einer Snowflake-Tabelle gelesen haben:
import modin.pandas as pd import snowflake.snowpark.modin.plugin from snowflake.ml.modeling.xgboost import XGBClassifier snowpark_pandas_df: modin.pandas.DataFrame = read_snowflake('MY_TABLE') # converting to Snowpark DataFrame adds an index column index_label_name = "_INDEX" snowpark_df = snowpark_pandas_df.to_snowpark(index=True, index_label=index_label_name) snowpark_df.show()
Der resultierende Snowpark DataFrame sieht folgendermaßen aus:
-------------------------------------------------- |"COLUMN_1" |"COLUMN_2" |"TARGET" | "_INDEX" | -------------------------------------------------- |1 |2 |3 |1 | --------------------------------------------------
Der DataFrame kann dann verwendet werden, um den XGBoost-Klassifikator wie folgt zu trainieren:
# Identify the column names using the Snowflake identifier input_cols = ["COLUMN_1", "COLUMN_2", "COLUMN_3"] # Pass through the _INDEX column rather than using it for training xgb_clf = XGBClassifier(input_cols=input_cols, passthrough_cols=index_label_name, label_cols="TARGET") xgb_clf.fit(snowpark_df)
Problembehandlung¶
Hinzufügen weiterer Details für die Protokollierung¶
Die Snowflake-Bibliothek zur Modellierung verwendet die Protokollierung von Snowpark Python. Standardmäßig protokolliert snowflake-ml-python Meldungen der INFO-Ebene auf der Standardausgabe. Um detailliertere Protokolle zu erhalten, können Sie den Protokolliergrad auf eine der von unterstützten Stufen ändern.
DEBUG erzeugt Protokolle mit den meisten Details. So setzen Sie den Protokolliergrad auf DEBUG:
import logging, sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
Lösungen für häufige Probleme¶
Die folgende Tabelle enthält einige Vorschläge zur Lösung möglicher Probleme mit Snowflake ML Modeling.
Problem oder Fehlermeldung |
Mögliche Ursache |
Lösung |
|---|---|---|
NameError, wie „Name x ist nicht definiert“, ImportError oder ModuleNotFoundError |
Typografischer Fehler im Modul- oder Klassennamen, oder |
Den korrekten Namen des Moduls und der Klasse finden Sie in der Tabelle der Modellierungsklassen. Stellen Sie sicher, dass |
KeyError („not in index“ oder „none of [Index[..]] are in the [Spalten]“) |
Inkorrekter Spaltenname |
Überprüfen und korrigieren Sie den Spaltennamen. |
SnowparkSQLException, „does not exist or not authorize“ |
Die Tabelle existiert nicht, oder Sie haben nicht die erforderlichen Berechtigungen für diese Tabelle. |
Stellen Sie sicher, dass die Tabelle existiert und die Rolle des Benutzers die erforderlichen Berechtigungen hat. |
SnowparkSQLException, „invalid identifier PETALLENGTH“ |
Inkorrekte Anzahl von Spalten (normalerweise eine fehlende Spalte). |
Überprüfen Sie die Anzahl der Spalten, die Sie beim Erstellen der Modellklasse angegeben haben, und stellen Sie sicher, dass Sie die korrekte Anzahl übergeben. |
InvalidParameterError |
Es wurde ein ungeeigneter Typ oder Wert als Parameter übergeben. |
Überprüfen Sie in einer interaktiven Python-Sitzung mit der Funktion |
TypeError, „unexpected keyword argument“ |
Typographischer Fehler im benannten Argument |
Überprüfen Sie in einer interaktiven Python-Sitzung mit der Funktion |
ValueError, „array with 0 sample(s)“ |
Das Datenset, das Sie übergeben haben, ist leer. |
Stellen Sie sicher, dass das Datenset nicht leer ist. |
SnowparkSQLException, „authentication token has expired“ |
Die Sitzung ist abgelaufen. |
Wenn Sie ein Jupyter-Notebook verwenden, starten Sie den Kernel neu, um eine neue Sitzung zu erstellen. |
ValueError wie „cannot convert string to float“ |
Datentypen stimmen nicht überein. |
Überprüfen Sie in einer interaktiven Python-Sitzung mit der Funktion |
SnowparkSQLException, „cannot create temporary table“ |
Eine Modellklasse wird innerhalb einer gespeicherten Prozedur verwendet, die nicht mit Aufruferrechten ausgeführt wird. |
Erstellen Sie die gespeicherte Prozedur mit Aufruferrechten statt mit Eigentümerrechten. |
SnowparkSQLException, „function available memory exceeded“ |
Ihr Datenset ist größer als 5 GB in einem Standard-Warehouse. |
Wechseln Sie zu einem Snowpark-optimierten Warehouse. |
OSError, „no space left on device“ |
Ihr Modell ist größer als etwa 500 MB in einem Standard-Warehouse. |
Wechseln Sie zu einem Snowpark-optimierten Warehouse. |
Inkompatible xgboost-Version oder Fehler beim Importieren von xgboost |
Sie haben für die Installation |
Führen Sie ein Upgrade oder Downgrade des Pakets durch, wie in der Fehlermeldung gefordert. |
AttributeError mit |
Sie versuchen, eine dieser Methoden auf ein Modell eines anderen Typs anzuwenden. |
Verwenden Sie |
Jupyter Notebook-Kernel stürzt auf arm-basiertem Mac (M1- oder M2-Chip) ab: „The Kernel crashed while executing code in the current cell or a previous cell“ |
XGBoost oder eine andere Bibliothek ist mit der falschen Architektur installiert. |
Erstellen Sie eine neue conda-Umgebung mit |
„lightgbm.basic.LightGBMError: (0000) Do not support special JSON characters in feature name.“ |
LightGBM unterstützt keine in Anführungszeichen gesetzten Spaltennamen in |
Benennen Sie die Spalten in Ihren Snowpark-DataFrames um. Das Ersetzen von nicht alphanumerischen Zeichen durch Unterstriche ist in den meisten Fällen ausreichend. Die nachstehende Python-Hilfsfunktion kann nützlich sein. def fix_values(F, column):
return F.upper(F.regexp_replace(F.col(column), "[^a-zA-Z0-9]+", "_"))
|
Weiterführende Informationen¶
In der Dokumentation der Originalbibliotheken finden Sie vollständige Informationen zu deren Funktionalität.
Quellenangabe¶
Einige Teile dieses Dokuments stammen aus der Scikit-learn-Dokumentation, die unter der BSD-3 „New“- oder „Revised“-Lizenz und Copyright © 2007-2023 The scikit-learn developers lizenziert ist. Alle Rechte vorbehalten.
Einige Teile dieses Dokuments stammen aus der XGboost-Dokumentation, die unter die Apache License 2.0, Januar 2004 und Copyright © 2019 fällt. Alle Rechte vorbehalten.
Einige Teile dieses Dokuments stammen aus der LightGBM-Dokumentation, die MIT-lizenziert ist und unter Copyright © Microsoft Corp. fällt. Alle Rechte vorbehalten.