Einführung in Java-UDFs¶
Sie können den Handler für eine benutzerdefinierte Funktion (UDF) in Java schreiben. Unter den Themen in diesem Abschnitt wird beschrieben, wie Sie einen Java-Handler entwerfen und schreiben. Außerdem werden Beispiele bereitgestellt.
Eine Einführung in UDFs, einschließlich einer Liste der Sprachen, in denen Sie einen UDF-Handler schreiben können, finden Sie unter Überblick über benutzerdefinierte Funktionen.
Sobald der Handler verfügbar ist, erstellen Sie die UDF mit SQL. Weitere Informationen zur Verwendung von SQL für das Erstellen oder Aufrufen einer UDF finden Sie unter Erstellen einer benutzerdefinierten Funktion bzw. Ausführen einer UDF.
Snowflake unterstützt derzeit das Schreiben von UDFs mit den folgenden Java-Versionen:
11.x
17.x
Bemerkung
Informationen zu Einschränkungen bezüglich Java-UDF-Handlern finden Sie unter Java-UDF-Beschränkungen.
Funktionsweise eines Java-Handlers¶
Wenn ein Benutzer eine UDF aufruft, übergibt der Benutzer den Namen und die Argumente der UDF an Snowflake. Snowflake ruft den zugehörigen Handler-Code (ggf. mit Argumenten) auf, um die Verarbeitungslogik der UDF auszuführen. Die Handler-Methode gibt dann die Ausgabe an Snowflake zurück, und Snowflake gibt die Ausgabe an den Client zurückgibt.
Für jede Zeile, die an eine UDF übergeben wird, gibt UDF entweder einen Einzelwert oder, falls als Tabellenfunktion definiert, eine Menge von Zeilen zurück.
Java-UDFs können sowohl neuen Code als auch Aufrufe bestehender Bibliotheken enthalten, was sowohl Flexibilität als auch die Wiederverwendung von Code ermöglicht. Wenn Sie z. B. bereits Datenanalysecode in Java haben, dann können Sie diesen wahrscheinlich in eine Java-UDF einbinden.
Nachfolgend finden Sie eine vereinfachte Darstellung des Datenflusses:
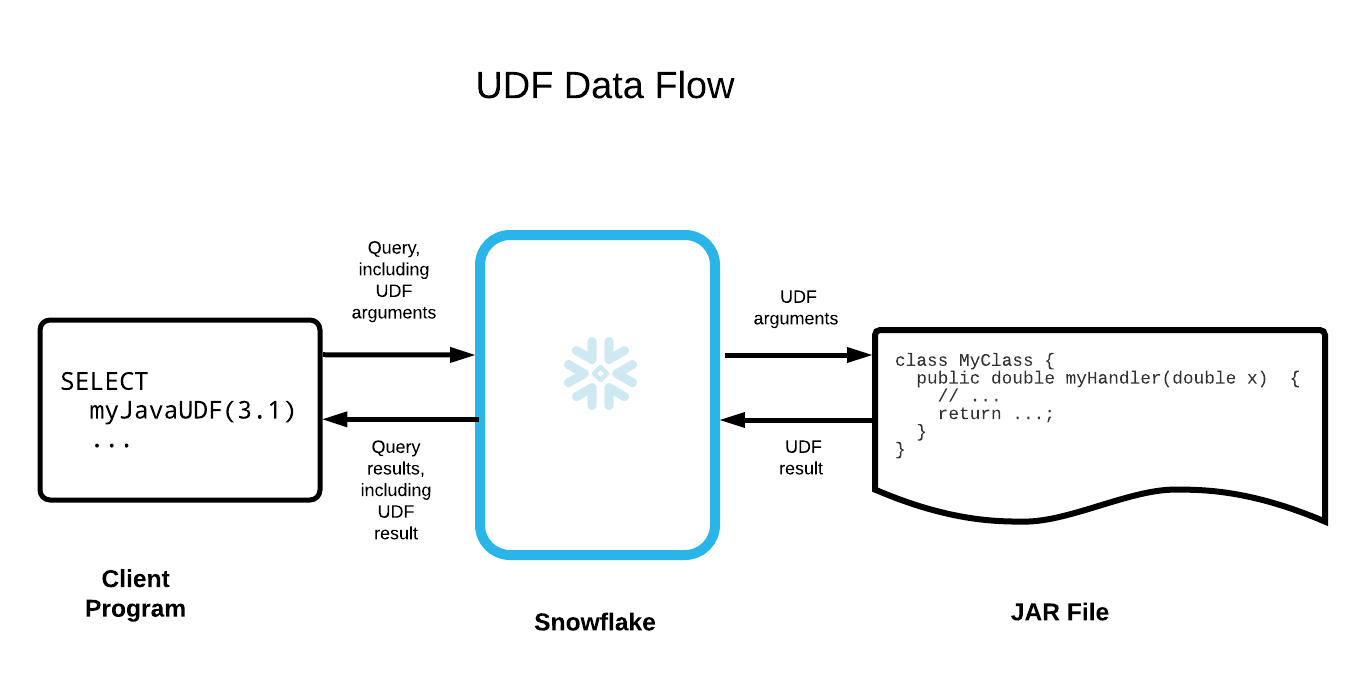
Beispiel¶
Der Code im folgenden Beispiel erstellt eine UDF namens echo_varchar mit der Handler-Methode TestFunc.echoVarchar. Die Java-Argumente und -Rückgabetypen werden von Snowflake gemäß den unter Zuordnung von Datentypen zwischen SQL und Java beschriebenen Zuordnungen in und aus SQL konvertiert.
Hinweise zum Entwurf¶
Beachten Sie beim Entwerfen eines effizienten Handlers die folgenden Hinweise.
Allgemeine Überlegungen. Allgemeine Hinweise zu UDFs und Prozeduren finden Sie unter Richtlinien und Einschränkungen beim Entwurf von Funktionen und Prozeduren.
SQL-Java-Typzuordnung. Beim Austausch von Argumenten und Rückgabewerten mit einer UDF konvertiert Snowflake zwischen der Handler-Sprache und SQL. Weitere Informationen zur Auswahl von Datentypen für Ihren Handler-Code finden Sie unter Auswählen Ihrer Datentypen.
Code-Pakete. Sie können Ihren Handler-Code entweder inline mit der CREATE FUNCTION-Anweisung oder in einem Stagingbereich in einer JAR-Datei als kompilierten Code zur Verfügung stellen. Weitere Informationen zu den Unterschieden zwischen den beiden Methoden finden Sie unter Speichern von Handler-Code inline oder in einem Stagingbereich.
Code-Optimierung. Informationen zur Optimierung Ihres Handler-Codes, z. B. wenn der Code zeilenübergreifende Zustände verarbeitet, finden Sie unter Optimieren von Initialisierung und Steuerung des globalen Zustands in skalaren UDFs.
Best Practices. Informationen zu bewährten Methoden finden Sie unter Befolgen von Best Practices und Sicherheitsverfahren für UDFs und Prozeduren.
Codieren von Handlern¶
Unter den folgenden Themen wird von den Grundlagen bis zu detaillierten Beispielen das Schreiben eines UDF-Handlers in Java erläutert.
Java-Klassendefinition. Die Logik einer UDF wird in eine Java-Klasse geschrieben. Weitere Informationen dazu, wie Snowflake mit Ihrem Code interagiert, finden Sie unter Entwerfen der Klasse.
Fehlerbehandlung. Informationen dazu, wie Snowflake von Handlern generierte Fehler behandelt, finden Sie unter Fehlerbehandlung.
Tabellarische Rückgabewerte. Sie können sowohl tabellarische Werte als auch skalare (Einzel-)Werte aus einer UDF zurückgeben. Informationen zum Schreiben eines Handlers, der tabellarische Werte zurückgibt, finden Sie unter Tabellarische Java-UDFs (UDTFs).
Protokollierung und Ereignisablaufverfolgung. Informationen zum Erfassen von Protokoll- und Ablaufverfolgungsdaten während der Ausführung Ihres Handler-Codes finden Sie unter Protokollierung, Ablaufverfolgung und Metriken.
Abhängigkeiten. Sie können Ihrem Code zur Laufzeit Abhängigkeiten zur Verfügung stellen, indem Sie diese in einen Stagingbereich hochladen. Weitere Informationen dazu finden Sie unter Abhängigkeiten für Code zur Verfügung stellen.
Organisation von Handler-Dateien. Wenn Sie beabsichtigen, kompilierten Handler-Code in eine JAR-Datei zu packen, organisieren und erstellen Sie Ihren Code mithilfe unter Organisieren Ihrer Dateien bereitgestellten Vorschläge.
Codebeispiele. Zahlreiche Beispiele für Handler in Java finden Sie unter Beispiele für Java-UDF-Handler.