Identifizieren von Sequenzen von Zeilen, die einem Muster entsprechen¶
Einführung¶
In einigen Fällen müssen Sie möglicherweise Sequenzen von Tabellenzeilen identifizieren, die mit einem Muster übereinstimmen. Das wäre in folgenden Beispielen der Fall:
Ermitteln, welche Benutzer einer bestimmten Sequenz von Seiten und Aktionen auf Ihrer Website gefolgt sind, bevor sie ein Support-Ticket geöffnet oder einen Kauf getätigt haben.
Suchen von Aktien, deren Kurse über einen bestimmten Zeitraum einer V- oder W-förmigen Erholung gefolgt sind.
Suchen nach Mustern in Sensordaten, die auf einen bevorstehenden Systemausfall hinweisen könnten.
Um Sequenzen von Zeilen zu identifizieren, die mit einem bestimmten Muster übereinstimmen, verwenden Sie die MATCH_RECOGNIZE-Unterklausel der FROM-Klausel.
Bemerkung
Sie können die MATCH_RECOGNIZE-Klausel nicht in einem rekursiven allgemeinen Tabellenausdruck verwenden.
Einfaches Beispiel für das Erkennen einer Sequenz von Zeilen¶
Angenommen, eine Tabelle enthält Daten über Aktienkurse. Jede Zeile enthält den Schlusskurs zum jeweiligen Tickersymbol an einem bestimmten Tag. Die Tabelle enthält folgende Spalten:
Spaltenname |
Beschreibung |
|---|---|
|
Datum des Schlusskurses. |
|
Schlusskurs der Aktie an diesem Datum. |
Angenommen, Sie möchten ein Muster erkennen, bei dem der Aktienkurs fällt und dann steigt, was eine V-Form in der Grafik des Aktienkurses erzeugt.
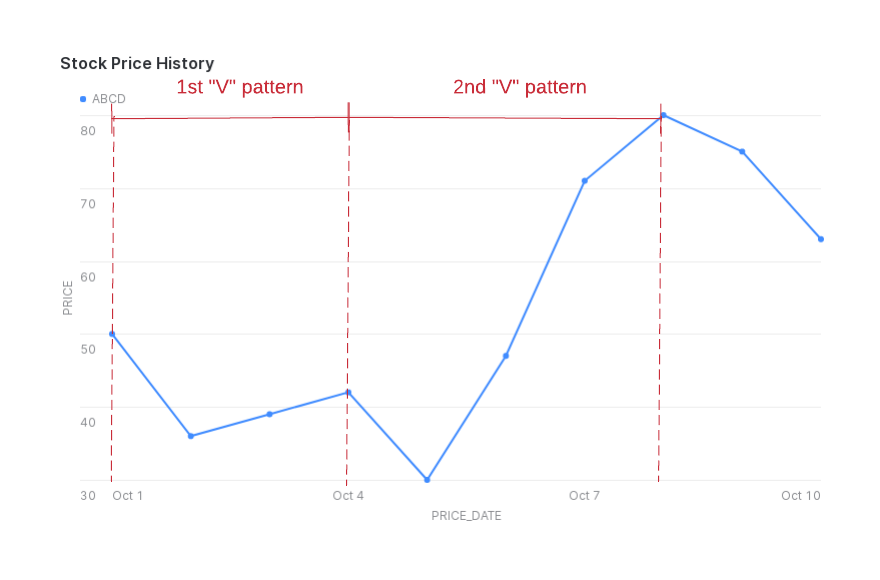
(Dieses Beispiel berücksichtigt nur die Fälle, in denen sich der Aktienkurs von Tag zu Tag ändert).
Im folgenden Beispiel möchten Sie für ein bestimmtes Tickersymbol Sequenzen von Zeilen finden, in denen der Wert in der Spalte price abnimmt, bevor er zunimmt.
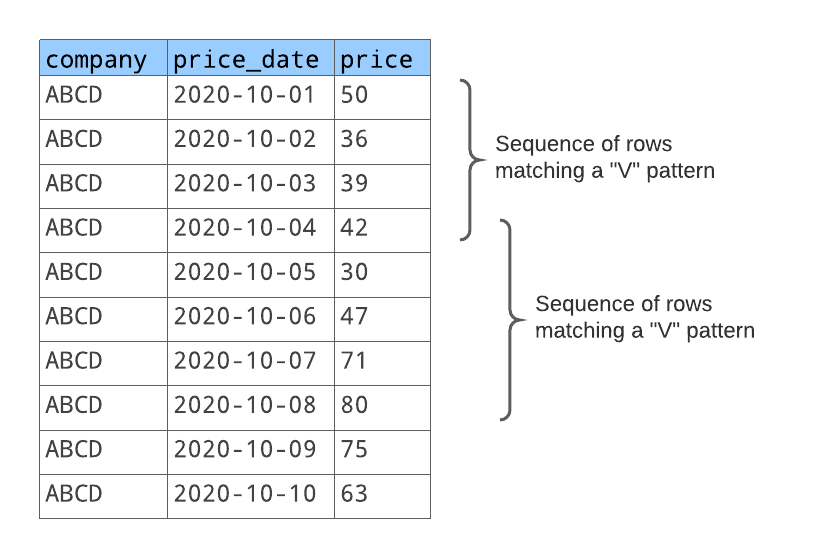
Für jede Zeilensequenz, die mit diesem Muster übereinstimmt, soll Folgendes zurückgegeben werden:
Eine Nummer, die die Sequenz identifiziert (die erste übereinstimmende Sequenz, die zweite übereinstimmende Sequenz usw.).
Der Tag, bevor der Aktienkurs gesunken ist.
Der letzte Tag, an dem der Aktienkurs gestiegen ist.
Die Anzahl der Tage im V-Muster.
Die Anzahl der Tage, an denen der Aktienkurs gesunken ist.
Die Anzahl der Tage, an denen der Aktienkurs gestiegen ist.
Die folgende Abbildung veranschaulicht die Kursrückgänge (NUM_DECREASES) und -steigerungen (NUM_INCREASES) innerhalb des V-Musters, das die zurückgegebenen Daten erfassen. Beachten Sie, dass ROWS_IN_SEQUENCE eine Anfangszeile enthält, die in NUM_DECREASES oder NUM_INCREASES nicht mitgezählt wird.

Um diese Ausgabe zu erzeugen, können Sie die unten gezeigte MATCH_RECOGNIZE-Klausel verwenden.
Wie oben gezeigt, besteht die MATCH_RECOGNIZE-Klausel aus vielen Unterklauseln, von denen jede einen anderen Zweck erfüllt (z. B. die Angabe des Musters, das abgeglichen werden soll, die Angabe der zurückzugebenden Daten usw.).
In den nächsten Abschnitten wird jede der Unterklauseln in diesem Beispiel erläutert.
Einrichten der Daten für dieses Beispiel¶
Um die in diesem Beispiel verwendeten Daten einzurichten, führen Sie die folgenden SQL-Anweisungen aus:
Schritt 1: Festlegen der Reihenfolge und Gruppierung von Zeilen¶
Der erste Schritt bei der Identifizierung einer Zeilensequenz besteht darin, die Gruppierung und die Sortierreihenfolge der zu durchsuchenden Zeilen festzulegen. Für das Beispiel der Suche nach einem V-Muster im Aktienkurs für ein Unternehmen sähe dies wie folgt aus:
Die Zeilen sollten nach Firma gruppiert werden, da Sie ein Muster im Kurs einer bestimmten Firma finden möchten.
Innerhalb jeder Gruppe von Zeilen (die Kurse einer bestimmten Firma) sollten die Zeilen nach Datum in aufsteigender Reihenfolge sortiert sein.
In einer MATCH_RECOGNIZE-Klausel verwenden Sie die Unterklauseln PARTITION BY und ORDER BY, um die Gruppierung und Reihenfolge der Zeilen anzugeben. Beispiel:
Schritt 2: Definieren des zu übereinstimmenden Musters¶
Legen Sie als Nächstes das Muster fest, das mit der zu suchenden Zeilensequenz übereinstimmt.
Um dieses Muster anzugeben, verwenden Sie etwas Ähnliches wie einen regulären Ausdruck. In regulären Ausdrücken verwenden Sie eine Kombination aus Literalen und Metazeichen, um ein Muster anzugeben, das in einer Zeichenfolge übereinstimmen soll.
Im folgenden Beispiel soll eine Sequenz von Zeichen gesucht werden, die Folgendes enthält:
ein beliebiges Einzelzeichen, gefolgt von
einem oder mehreren Großbuchstaben, gefolgt von
einem oder mehreren Kleinbuchstaben
Dafür können Sie den folgenden Perl-kompatiblen regulären Ausdruck verwenden:
Wobei:
Ein Punkt (
.) stimmt mit jedem beliebigen Einzelzeichen überein.[A-Z]+stimmt mit einem oder mehreren Großbuchstaben überein.[a-z]+stimmt mit einem oder mehreren Kleinbuchstaben überein.
+ ist ein Quantifizierer, der angibt, dass eines oder mehrere der vorangehenden Zeichen übereinstimmen müssen.
Beispielsweise passt der obige reguläre Ausdruck auf Zeichensequenzen wie:
1Stock@SFComputing%Fn
In einer MATCH_RECOGNIZE-Klausel verwenden Sie einen ähnlichen Ausdruck, um das Muster der abzugleichenden Zeilen anzugeben. In diesem Fall beinhaltet das Suchen von Zeilen, die mit einem V-Muster übereinstimmen, das Suchen einer Sequenz von Zeilen, die Folgendes enthält:
die Zeile, bevor der Aktienkurs sinkt, gefolgt von
einer oder mehreren Zeilen, in denen der Aktienkurs sinkt, gefolgt von
einer oder mehreren Zeilen, in denen der Aktienkurs steigt
Sie können dies als das folgende Zeilenmuster ausdrücken:
Zeilenmuster bestehen aus Mustervariablen, Quantifizierern (die ähnlich denen in regulären Ausdrücken verwendet werden) und Operatoren. Eine Mustervariable definiert einen Ausdruck, der auf einer Zeile ausgewertet wird.
Bei diesem Zeilenmuster:
row_before_decrease,row_with_price_decrease, undrow_with_price_increasesind Mustervariablen. Die Ausdrücke für diese Mustervariablen sollen Folgendes ergeben:eine beliebige Zeile (die Zeile, bevor der Aktienkurs sinkt)
eine Zeile mit fallendem Aktienkurs
eine Zeile mit steigendem Aktienkurs
row_before_decreaseist vergleichbar mit.in einem regulären Ausdruck. Im folgenden regulären Ausdruck stimmt.mit jedem einzelne Zeichen überein, das vor dem ersten Großbuchstaben im Muster auftritt.In ähnlicher Weise stimmt
row_before_decreaseim Zeilenmuster mit jeder Zeile überein, die vor der ersten Zeile mit einem gesunkenen Kurs auftritt.Die
+-Quantifizierer nachrow_with_price_decreaseundrow_with_price_increasegeben an, dass für jede dieser Zeilen eine oder mehrere Zeilen übereinstimmen müssen.
In einer MATCH_RECOGNIZE-Klausel verwenden Sie die Unterklausel PATTERN, um das Zeilenmuster anzugeben, das übereinstimmen soll:
Um die Ausdrücke für die Mustervariablen anzugeben, verwenden Sie die Unterklausel DEFINE:
Wobei:
row_before_decreasemuss hier nicht definiert werden, da es auf eine beliebige Zeile ergeben soll.row_with_price_decreaseist als Ausdruck für eine Zeile mit einem gesunkenen Kurs definiert.row_with_price_increaseist als Ausdruck für eine Zeile mit einem erhöhten Kurs definiert.
Um die Preise in unterschiedlichen Zeilen zu vergleichen und den Preis für die vorherige Zeile anzugeben, verwenden die Definitionen dieser Variablen die Navigationsfunktion LAG().
Das Zeilenmuster stimmt mit zwei Zeilensequenzen überein, wie unten dargestellt:

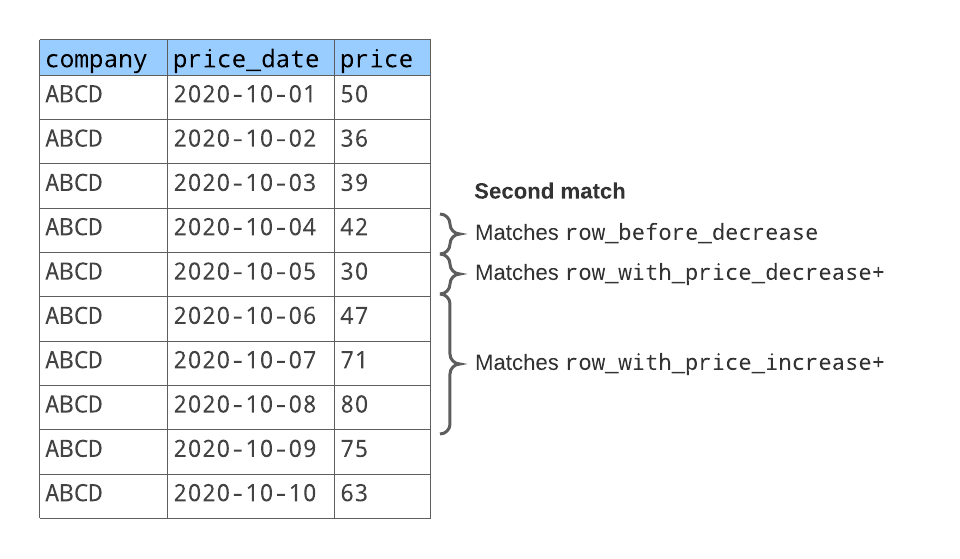
Bei der ersten übereinstimmende Zeilensequenz:
row_before_decreasestimmt mit der Zeile mit dem Aktienkurs50überein.row_with_price_decreasestimmt mit der nächsten Zeile mit dem Aktienkurs36überein.row_with_price_increasestimmt mit den nächsten beiden Zeilen mit den Aktienkursen39und42überein.
Für die zweite übereinstimmende Zeilensequenz:
row_before_decreasestimmt mit der Zeile mit dem Aktienkurs42überein. (Dies ist die gleiche Zeile, die am Ende der ersten übereinstimmenden Zeilensequenz steht).row_with_price_decreasestimmt mit der nächsten Zeile mit dem Aktienkurs30überein.row_with_price_increasestimmt mit den nächsten beiden Zeilen mit den Aktienkursen47,71und80überein.
Schritt 3: Festlegen der zurückzugebenden Zeilen¶
MATCH_RECOGNIZE kann Folgendes zurückgeben:
eine einzelne Zeile, die alle übereinstimmenden Sequenz zusammenfasst, oder
jede Zeile in jeder übereinstimmenden Sequenz
In diesem Beispiel möchten Sie eine Zusammenfassung für jede übereinstimmende Sequenz zurückgeben. Verwenden Sie die Unterklausel ONE ROW PER MATCH, um anzugeben, dass für jede übereinstimmende Sequenz genau eine Zeile zurückgegeben werden soll.
Schritt 4: Festlegen der auszuwählenden Measures¶
Wenn Sie ONE ROW PER MATCH verwenden, gibt MATCH_RECOGNIZE keine der Spalten in der Tabelle zurück (bis auf die durch PARTITION BY angegebene Spalte), selbst wenn MATCH_RECOGNIZE in einer SELECT *-Anweisung enthalten ist. Um die Daten festzulegen, die von dieser Anweisung zurückgegeben werden sollen, müssen Sie Measures definieren. Measures sind zusätzliche Datenspalten, die für jede übereinstimmende Sequenz von Zeilen berechnet werden (z. B. das Startdatum der Sequenz, das Enddatum der Sequenz, die Anzahl der Tage in der Sequenz usw.).
Verwenden Sie die Unterklausel MEASURES, um diese zusätzlichen Spalten anzugeben, die in der Ausgabe zurückgegeben werden sollen. Das allgemeine Format für die Definition eines Measures ist wie folgt:
Wobei:
expressiongibt Informationen zu der Sequenz an, die Sie zurückgeben möchten. Für den Ausdruck können Sie Funktionen mit Spalten der Tabelle und Mustervariablen verwenden, die Sie zuvor definiert haben.column_namegibt den Namen der Spalte an, die in der Ausgabe zurückgegeben wird.
In diesem Beispiel können Sie die folgenden Measures definieren:
Eine Nummer, die die Sequenz identifiziert (die erste übereinstimmende Sequenz, die zweite übereinstimmende Sequenz usw.).
Verwenden Sie für diesen Measure die Funktion
MATCH_NUMBER(), die die Nummer der Übereinstimmung zurückgibt. Die Nummern beginnen mit1für die erste Übereinstimmung in einer Partition von Zeilen. Wenn es mehrere Partitionen gibt, beginnt die Nummer in jeder Partition mit1.Der Tag, bevor der Aktienkurs gesunken ist.
Verwenden Sie für diesen Measure die Funktion
FIRST(), die den Wert des Ausdrucks für die erste Zeile in der übereinstimmenden Sequenz zurückgibt. In diesem Beispiel gibtFIRST(price_date)den Wert der Spalteprice_datein der ersten Zeile jeder übereinstimmenden Sequenz zurück, also das Datum, bevor der Aktienkurs gefallen ist.Der letzte Tag, an dem der Aktienkurs gestiegen ist.
Verwenden Sie für diesen Measure die Funktion
LAST(), die den Wert des Ausdrucks für die letzte Zeile in der übereinstimmenden Sequenz zurückgibt.Die Anzahl der Tage im V-Muster.
Verwenden Sie für diesen Measure
COUNT(*). Da SieCOUNT(*)in der Definition eines Measure angeben, gibt das Sternchen (*) an, dass Sie alle Zeilen in einer übereinstimmenden Sequenz zählen möchten (nicht alle Zeilen in der Tabelle).Die Anzahl der Tage, an denen der Kurs gefallen ist.
Verwenden Sie für diesen Measure
COUNT(row_with_price_decrease.*). Der Punkt gefolgt von einem Sternchen (.*) gibt an, dass Sie alle Zeilen in einer übereinstimmenden Sequenz zählen möchten, die mit der Mustervariablenrow_with_price_decreaseübereinstimmen.Die Anzahl der Tage, an denen der Kurs gestiegen ist.
Verwenden Sie für diesen Measure
COUNT(row_with_price_increase.*).
Es folgt die Unterklausel MEASURES, die den obigen Measure definiert:
Im Folgenden sehen Sie ein Beispiel für die Ausgabe mit den ausgewählten Measures:
Wie bereits erwähnt, enthält die Ausgabe die Spalte company, da die Klausel PARTITION BY diese Spalte angibt.
Schritt 5: Festlegen, wo die Suche nach der nächsten Übereinstimmung fortgesetzt werden soll¶
Nachdem eine übereinstimmende Zeilensequenz gefunden wurde, fährt MATCH_RECOGNIZE fort, die nächste übereinstimmende Sequenz zu finden. Sie können angeben, wo MATCH_RECOGNIZE mit der Suche nach der nächsten übereinstimmenden Sequenz beginnen soll.
Wie in der Darstellung von übereinstimmenden Sequenzen gezeigt, kann eine Zeile Teil von mehr als einer übereinstimmenden Sequenz sein. Im folgenden Beispiel ist die Zeile für 2020-10-04 Teil von zwei V-Mustern.
In diesem Beispiel können Sie, um die nächste übereinstimmende Sequenz zu finden, von einer Zeile ausgehen, in der der Kurs gestiegen ist. Um dies in der MATCH_RECOGNIZE-Klausel anzugeben, verwenden Sie AFTER MATCH SKIP:
wobei TO LAST row_with_price_increase angibt, dass Sie die Suche bei der letzten Zeile beginnen möchten, in der der Kurs gestiegen ist.
Partitionierung und Sortierung von Zeilen¶
Der erste Schritt bei der Identifizierung von Mustern über Zeilen hinweg besteht darin, die Zeilen in eine Reihenfolge zu bringen, die es Ihnen ermöglicht, Ihre Muster zu finden. Wenn Sie z. B. ein Muster von Änderungen der Aktienkurse im Zeitverlauf für die Aktien einer Firma finden möchten:
Partitionieren Sie die Zeilen nach Firmen, sodass Sie über die Aktienkurse der einzelnen Firmen suchen können.
Sortieren Sie die Zeilen innerhalb jeder Partition nach Datum, sodass Sie Änderungen des Aktienkurses eines Unternehmens im Zeitverlauf finden können.
Um die Daten zu partitionieren und die Reihenfolge der Zeilen anzugeben, verwenden Sie die Unterklauseln PARTITION BY und ORDER BY in MATCH_RECOGNIZE. Beispiel:
(Die PARTITION BY-Klausel für MATCH_RECOGNIZE funktioniert auf die gleiche Weise wie die PARTITION BY-Klausel für Fensterfunktionen).
Ein zusätzlicher Vorteil der Partitionierung ist, dass sich damit die Vorteile der Parallelverarbeitung nutzen lassen.
Definieren des Musters der abzugleichenden Zeilen¶
Mit MATCH_RECOGNIZE können Sie eine Sequenz von Zeilen suchen, die mit einem Muster übereinstimmen. Sie geben dieses Muster in Form von Zeilen an, die bestimmten Bedingungen entsprechen.
Nehmen Sie im Beispiel der Tabelle mit den täglichen Aktienkursen für verschiedene Firmen an, dass Sie eine Sequenz von drei Zeilen finden möchten, für die Folgendes gilt:
An einem bestimmten Tag liegt der Aktienkurs eines Unternehmens unter 45,00.
Am nächsten Tag sinkt der Aktienkurs um mindestens 10 %.
Am folgenden Tag steigt der Aktienkurs um mindestens 3 %.
Um diese Sequenz zu finden, geben Sie ein Muster an, das mit drei Zeilen übereinstimmt, die folgende Bedingungen erfüllen:
In der ersten Zeile der Sequenz muss der Wert der Spalte
pricekleiner sein als 45,00.In der zweiten Zeile muss der Wert der Spalte
pricekleiner oder gleich 90 % des Wertes der vorherigen Zeile betragen.In der dritten Zeile muss der Wert der Spalte
pricegrößer oder gleich 105 % des Wertes der vorherigen Zeile betragen.
Die zweite und dritte Zeile haben Bedingungen, die einen Vergleich zwischen Spaltenwerten in verschiedenen Zeilen erfordern. Um den Wert in einer Zeile mit dem Wert in der vorherigen oder nächsten Zeile zu vergleichen, verwenden Sie die Funktionen LAG() oder LEAD():
LAG(column)gibt den Wert voncolumnin der vorherigen Zeile zurück.LEAD(column)gibt den Wert voncolumnin der nächsten Zeile zurück.
Für dieses Beispiel können Sie die Bedingungen für die drei Zeilen wie folgt angeben:
Für die erste Zeile in der Sequenz muss
price < 45.00gelten.Für die zweite Zeile muss
LAG(price) * 0.90 >= pricegelten.Für die dritte Zeile muss
LAG(price) * 1.05 <= pricegelten.
Wenn Sie das Muster für die Sequenz dieser drei Zeilen angeben, verwenden Sie für jede Zeile, die eine andere Bedingung hat, eine Mustervariable. Verwenden Sie die Unterklausel DEFINE, um jede Mustervariable als eine Zeile zu definieren, die eine bestimmte Bedingung erfüllen muss. Das folgende Beispiel definiert drei Mustervariablen für die drei Zeilen:
Um das Muster selbst zu definieren, verwenden Sie die Unterklausel PATTERN. Verwenden Sie in dieser Unterklausel einen regulären Ausdruck, um das abzugleichende Muster anzugeben. Verwenden Sie für die Bausteine des Ausdrucks die Mustervariablen, die Sie definiert haben. Das folgende Muster findet zum Beispiel die Sequenz von drei Zeilen:
Die folgende SQL-Anweisung verwendet die oben gezeigten Unterklauseln DEFINE und PATTERN:
In den nächsten Abschnitten wird erläutert, wie Sie Muster definieren, die mit einer bestimmten Anzahl von Zeilen übereinstimmen und mit Zeilen, die am Anfang oder Ende einer Partition erscheinen.
Bemerkung
MATCH_RECOGNIZE verwendet die Rückverfolgung, um Muster abzugleichen. Wie bei anderen regulären Ausdrücken, die Backtracking verwenden, können einige Kombinationen von Mustern und Daten, die übereinstimmen müssen, eine lange Ausführungszeit benötigen, was zu hohen Computekosten führen kann.
Um die Leistung zu verbessern, definieren Sie ein Muster, das so spezifisch wie möglich ist:
Stellen Sie sicher, dass in jeder Zeile nur ein Symbol oder eine kleine Anzahl von Symbolen übereinstimmt.
Vermeiden Sie die Verwendung von Symbolen, die in jeder Zeile übereinstimmen (z. B. Symbole, die nicht in der
DEFINE-Klausel enthalten sind, oder Symbole, die als „true“ definiert sind).Definieren Sie eine Obergrenze für Quantifizierer (z. B.
{,10}statt*).
Beispielsweise kann das folgende Muster zu erhöhten Kosten führen, wenn keine Zeilen übereinstimmen:
Wenn es eine Obergrenze für die Anzahl der Zeilen gibt, die Sie abgleichen möchten, können Sie diese Grenze in den Quantifizierern angeben, um die Leistung zu verbessern. Außerdem können Sie, anstatt anzugeben, dass Sie any_symbol finden möchten, das auf symbol1 folgt, nach einer Zeile suchen, die nicht symbol1 ist (not_symbol1 in diesem Beispiel).
Im Allgemeinen sollten Sie die Abfrageausführungszeit überwachen, um sicherzustellen, dass die Abfrage nicht länger als erwartet dauert.
Verwenden von Quantifizierern mit Mustervariablen¶
In der Unterklausel PATTERN verwenden Sie einen regulären Ausdruck, um ein abzugleichendes Muster von Zeilen anzugeben. Sie verwenden Mustervariablen, um Zeilen in der Sequenz zu identifizieren, die bestimmte Bedingungen erfüllen.
Wenn Sie mehrere Zeilen abgleichen müssen, die eine bestimmte Bedingung erfüllen, können Sie einen Quantifizierer verwenden, wie in einem regulären Ausdruck.
Sie können z. B. den Quantifizierer + verwenden, um anzugeben, dass das Muster eine oder mehrere Zeilen enthalten muss, in denen der Aktienkurs um 10 % fällt, gefolgt von einer oder mehreren Zeilen, in denen der Aktienkurs um 5 % steigt:
Abgleichen von Mustern relativ zum Anfang oder Ende einer Partition¶
Um eine Sequenz von Zeilen relativ zum Anfang oder Ende einer Partition zu finden, können Sie die Metazeichen ^ und $ in der Unterklausel PATTERN verwenden. Diese Metazeichen in einem Zeilenmuster haben einen ähnlichen Zweck wie die gleichen Metazeichen in einem regulären Ausdruck:
^stellt den Anfang einer Partition dar.$stellt das Ende einer Partition dar.
Das folgende Muster stimmt mit einer Aktie überein, deren Preis zu Beginn der Partition größer als 75,00 ist:
Beachten Sie, dass mit ^ und $ Positionen angegeben werden und nicht die Zeilen an diesen Positionen (ähnlich wie ^ und $ in einem regulären Ausdruck die Position angeben und nicht die Zeichen an diesen Positionen). In PATTERN (^ GT75) muss die erste Zeile (nicht die zweite Zeile) einen Preis haben, der größer ist als 75,00. In PATTERN (GT75 $) muss die letzte Zeile (nicht die vorletzte Zeile) größer als 75 sein.
Hier ist ein vollständiges Beispiel mit ^. Beachten Sie, dass, obwohl die Aktie XYZ in mehr als einer Zeile in dieser Partition einen höheren Preis als 60,00 hat, nur die Zeile am Anfang der Partition als Übereinstimmung betrachtet wird.
Hier ist ein vollständiges Beispiel mit $. Beachten Sie, dass, obwohl die Aktie ABCD in mehr als einer Zeile in dieser Partition einen höheren Preis als 50,00 hat, nur die Zeile am Ende der Partition als Übereinstimmung betrachtet wird.
Festlegen von Ausgabezeilen¶
Bei Anweisungen, die MATCH_RECOGNIZE verwenden, kann ausgewählt werden, welche Zeilen ausgegeben werden.
Generieren einer Zeile für jede Übereinstimmung vs. Generieren aller Zeilen für jede Übereinstimmung¶
Wenn MATCH_RECOGNIZE eine Übereinstimmung findet, kann die Ausgabe entweder eine Zusammenfassungszeile für die gesamte Übereinstimmung oder eine Zeile für jeden Datenpunkt im Muster umfassen.
ALL ROWS PER MATCHgibt an, dass die Ausgabe alle Zeilen in der Übereinstimmung enthält.ONE ROW PER MATCHgibt an, dass die Ausgabe nur eine Zeile für jede Übereinstimmung in jeder Partition enthält.Die Projektionsklausel der SELECT-Anweisung kann nur die Ausgabe von
MATCH_RECOGNIZEverwenden. Das bedeutet im Endeffekt, dass die SELECT-Anweisung nur Spalten aus den folgenden Unterklauseln vonMATCH_RECOGNIZEverwenden kann:Die Unterklausel
PARTITION BY.Alle Zeilen in einer Übereinstimmung stammen aus derselben Partition und haben daher denselben Wert für die Ausdrücke der
PARTITION BY-Unterklausel.Die
MEASURES-Klausel.Wenn Sie
MATCH_RECOGNIZE ... ONE ROW PER MATCHverwenden, generiert die UnterklauselMEASURESnicht nur Ausdrücke, die für alle Zeilen in der Übereinstimmung denselben Wert zurückgeben (z. B.MATCH_NUMBER()), sondern auch Ausdrücke, die für verschiedene Zeilen in der Übereinstimmung unterschiedliche Werte zurückgeben können (z. B.MATCH_SEQUENCE_NUMBER()). Wenn Sie Ausdrücke verwenden, die für verschiedene Zeilen in der Übereinstimmung unterschiedliche Werte zurückgeben können, ist die Ausgabe nicht deterministisch.
Wenn Sie mit Aggregatfunktionen und
GROUP BYvertraut sind, könnte die folgende Analogie hilfreich sein, umONE ROW PER MATCHzu verstehen:Die
PARTITION BY-Klausel inMATCH_RECOGNIZEgruppiert die Daten ähnlich wieGROUP BYdie Daten inSELECT.Die
MEASURES-Klausel in einemMATCH_RECOGNIZE ... ONE ROW PER MATCHerlaubt Aggregatfunktionen, wie z. B.COUNT(), die für jede Zeile in der Übereinstimmung denselben Wert zurückgeben, wie esMATCH_NUMBER()tut.
Wenn Sie nur Aggregatfunktionen und Ausdrücke verwenden, die für jede Zeile in der Übereinstimmung denselben Wert zurückgeben, dann verhält sich
... ONE ROW PER MATCHähnlich wieGROUP BYund Aggregatfunktionen.
Die Voreinstellung ist ONE ROW PER MATCH.
Die folgenden Beispiele zeigen den Unterschied in den Ausgaben von ONE ROW PER MATCH und ALL ROWS PER MATCH. Diese beiden Codebeispiele sind bis auf die ...ROW(S) PER MATCH-Klausel fast identisch. (Bei typischer Verwendung hat eine SQL-Anweisung mit ONE ROW PER MATCH andere MEASURES-Unterklauseln als eine SQL-Anweisung mit ALL ROWS PER MATCH.)
Ausschließen von Zeilen aus der Ausgabe¶
Bei einigen Abfragen möchten Sie vielleicht nur einen Teil des Musters in die Ausgabe aufnehmen. Sie möchten z. B. Muster finden, in denen Aktien viele Tage hintereinander gestiegen sind, aber nur die Spitzenwerte und einige zusammenfassende Informationen anzeigen (z. B. die Anzahl der Tage mit Kursanstiegen vor jedem Spitzenwert).
Sie können die Ausschlusssyntax im Muster verwenden, um MATCH_RECOGNIZE anzuweisen, nach einer bestimmten Mustervariablen zu suchen, sie aber nicht in die Ausgabe aufzunehmen. Um eine Mustervariable als Teil des zu suchenden Musters, aber nicht als Teil der Ausgabe aufzunehmen, verwenden Sie die Notation {- <Mustervariable> -}.
Hier ist ein einfaches Beispiel, das den Unterschied zwischen der Verwendung der Ausschlusssyntax und ohne deren Verwendung zeigt. Dieses Beispiel enthält zwei Abfragen, die jeweils nach einem Aktienkurs suchen, der bei unter 45 USD begann, dann fiel und wieder anstieg. Die erste Abfrage verwendet keine Ausschlusssyntax und zeigt daher alle Zeilen an. Die zweite Abfrage verwendet die Ausschlusssyntax und zeigt nicht den Tag an, an dem der Aktienkurs fiel.
Das nächste Beispiel ist realistischer. Es wird nach Mustern gesucht, in denen ein Aktienkurs einen oder mehrere Tage in Folge gestiegen und dann einen oder mehrere Tage in Folge gefallen ist. Da die Ausgabe recht groß sein kann, wird hier durch Ausschluss nur der erste Tag angezeigt, an dem die Aktie gestiegen ist (wenn sie mehr als einen Tag in Folge gestiegen ist), und nur der erste Tag, an dem sie gefallen ist (wenn sie mehr als einen Tag in Folge gefallen ist). Das Muster ist unten dargestellt:
Dieses Muster sucht nach Ereignissen in der folgenden Reihenfolge:
Ein Startkurs kleiner als 45.
Ein UP, möglicherweise unmittelbar gefolgt von anderen, die nicht in der Ausgabe enthalten sind.
Ein DOWN, möglicherweise unmittelbar gefolgt von anderen, die nicht in der Ausgabe enthalten sind.
Hier sind der Code und die Ausgabe für Versionen des vorherigen Musters ohne Ausschluss und mit Ausschluss:
Zurückgeben von Informationen zur Übereinstimmung¶
Grundlegende Informationen zur Übereinstimmung¶
In vielen Fällen möchten Sie, dass Ihre Abfrage nicht nur Informationen aus der Tabelle auflistet, die die Daten enthält, sondern auch Informationen zu den gefundenen Mustern. Wenn Sie Informationen zu den Übereinstimmungen selbst wünschen, geben Sie diese Informationen in der MEASURES-Klausel an.
Die MEASURES-Klausel kann die folgenden Funktionen enthalten, die spezifisch für MATCH_RECOGNIZE sind:
MATCH_NUMBER(): Jedes Mal, wenn eine Übereinstimmung gefunden wird, wird ihr eine fortlaufende Übereinstimmungsnummer zugewiesen, beginnend bei 1. Diese Funktion gibt die Übereinstimmungsnummer zurück.MATCH_SEQUENCE_NUMBER(): Da ein Muster normalerweise mehr als einen Datenpunkt umfasst, möchten Sie vielleicht wissen, welcher Datenpunkt mit jedem Wert aus der Tabelle verbunden ist. Diese Funktion gibt die fortlaufende Nummer des Datenpunktes innerhalb der Übereinstimmung zurück.CLASSIFIER(): Der Klassifizierer ist der Name der Mustervariablen, mit der die Zeile übereinstimmt.
Die Abfrage unten enthält eine MEASURES-Klausel mit der Übereinstimmungsnummer, der Übereinstimmungssequenznummer und dem Klassifizierer.
Die Unterklausel MEASURES kann viel mehr Informationen als diese liefern. Weitere Informationen dazu finden Sie in der MATCH_RECOGNIZE-Referenzdokumentation.
Fenster, Fensterrahmen und Navigationsfunktionen¶
Die MATCH_RECOGNIZE-Klausel operiert auf einem „Fenster“ von Zeilen. Wenn MATCH_RECOGNIZE eine PARTITION-Unterklausel enthält, dann ist jede Partition ein eigenes Fenster. Wenn es keine PARTITION-Unterklausel gibt, dann ist die gesamte Eingabe ein Fenster.
Die PATTERN-Unterklausel von MATCH_RECOGNIZE gibt die Symbole in der Reihenfolge von links nach rechts an. Beispiel:
Wenn Sie sich die Daten als eine Sequenz von Zeilen in aufsteigender Reihenfolge von links nach rechts vorstellen, können Sie sich MATCH_RECOGNIZE als eine Bewegung nach rechts vorstellen (z. B. vom frühesten zum spätesten Datum im Aktienkurs-Beispiel), wobei Sie in den Zeilen innerhalb jedes Fensters nach einem Muster suchen.
MATCH_RECOGNIZE beginnt mit der ersten Zeile im Fenster und prüft, ob diese Zeile und die nachfolgenden Zeilen mit dem Muster übereinstimmen.
Im einfachsten Fall wird nach der Feststellung, ob es eine Musterübereinstimmung ab der ersten Zeile im Fenster gibt, MATCH_RECOGNIZE eine Zeile nach rechts bewegt und dann der Vorgang wiederholt, wobei geprüft wird, ob die zweite Zeile der Beginn eines Auftretens des Musters ist. MATCH_RECOGNIZE bewegt sich weiter nach rechts, bis das Ende des Fensters erreicht ist.
(MATCH_RECOGNIZE kann sich um mehr als eine Zeile nach rechts bewegen. Sie können beispielsweise MATCH_RECOGNIZE so definieren, dass nach dem Ende des aktuellen Musters mit der Suche nach dem nächsten Muster begonnen wird).
Sie können sich das grob so vorstellen, als gäbe es einen „Rahmen“, der sich innerhalb des Fensters nach rechts bewegt. Der linke Rand dieses Rahmens befindet sich an der ersten Zeile in der Menge der Zeilen, die gerade auf eine Übereinstimmung geprüft werden. Der rechte Rand des Rahmens wird erst definiert, wenn eine Übereinstimmung gefunden wurde. Sobald eine Übereinstimmung gefunden wurde, ist der rechte Rand des Rahmens die letzte Zeile der Übereinstimmung. Wenn das Suchmuster z. B. pattern (start down up) wäre, dann ist die Zeile, die mit dem up übereinstimmt, die letzte Zeile vor dem rechten Rand des Rahmens.
(Wenn keine Übereinstimmung gefunden wird, dann ist der rechte Rand des Rahmens nie definiert und wird nie referenziert).
In einfachen Fällen können Sie sich einen gleitenden Fensterrahmen wie unten abgebildet vorstellen:
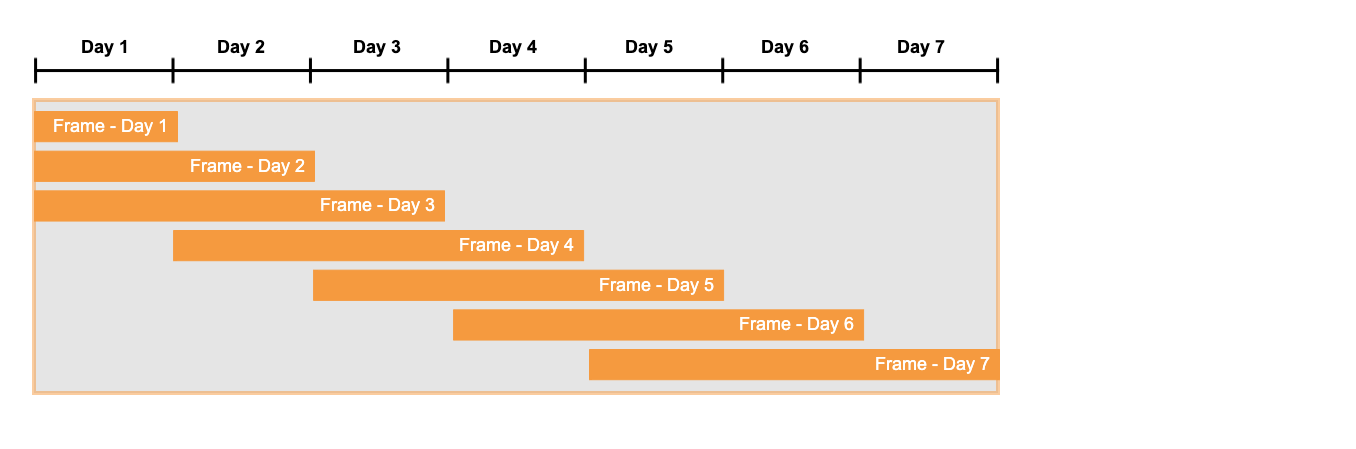
Sie haben bereits gesehen, dass Navigationsfunktionen wie LAG() in Ausdrücken der DEFINE-Unterklausel verwendet werden (z. B. DEFINE down_10_percent as LAG(price) * 0.9 >= price). Die folgende Abfrage zeigt, dass Navigationsfunktionen auch in der MEASURES-Unterklausel verwendet werden können. In diesem Beispiel zeigen die Navigationsfunktionen die Ränder (und damit die Größe) des Fensterrahmens an, der die aktuelle Übereinstimmung enthält.
Jede Ausgabezeile dieser Abfrage enthält die Werte der Navigationsfunktionen LAG(), LEAD(), FIRST() und LAST() für diese Zeile. Die Größe des Fensterrahmens ist die Anzahl der Zeilen zwischen FIRST() und LAST(), einschließlich der ersten und letzten Zeile selbst.
Die DEFINE- und PATTERN-Klauseln in der folgenden Abfrage wählen Gruppen von drei Zeilen aus (1.-3. Oktober, 2.-4. Oktober, 3.-5. Oktober usw.).
Die Ausgabe dieser Abfrage zeigt auch, dass die Funktionen LAG() und LEAD() NULL für Ausdrücke zurückgeben, die versuchen, Zeilen außerhalb der Übereinstimmungsgruppe zu referenzieren (d. h. außerhalb des Fensterrahmens).
Die Regeln für Navigationsfunktionen in DEFINE-Klauseln unterscheiden sich leicht von den Regeln für Navigationsfunktionen in MEASURES-Klauseln. So ist beispielsweise die Funktion PREV() derzeit in der MEASURES-Klausel verfügbar, aber nicht in der DEFINE-Klausel. Stattdessen können Sie LAG() in der DEFINE-Klausel verwenden. In der Referenzdokumentation für MATCH_RECOGNIZE sind die entsprechenden Regeln für jede Navigationsfunktion aufgeführt.
Die Unterklausel MEASURES kann auch Folgendes enthalten:
Aggregatfunktionen. Wenn das Muster z. B. mit einer unterschiedlichen Anzahl von Zeilen übereinstimmen kann (z. B. weil es mit einer oder mehr fallenden Aktienkursen übereinstimmt), dann möchten Sie vielleicht die Gesamtzahl der übereinstimmenden Zeilen wissen. Sie können dies durch Verwendung von
COUNT(*)anzeigen.Allgemeine Ausdrücke, die auf Werte in jeder Zeile der Übereinstimmung angewendet werden. Dies können mathematische Ausdrücke, logische Ausdrücke usw. sein. Sie können z. B. die Werte in der Zeile betrachten und Textbeschreibungen wie „ABOVE AVERAGE“ ausgeben.
Wenn Sie Zeilen gruppieren (
ONE ROW PER MATCH) und eine Spalte unterschiedliche Werte für unterschiedliche Zeilen in der Gruppe hat, müssen Sie daran denken, dass der für diese Spalte ausgewählte Wert für diese Übereinstimmung nicht deterministisch ist und Ausdrücke, die auf diesem Wert basieren, wahrscheinlich ebenfalls nicht deterministisch sind.
Weitere Informationen zur Unterklausel MEASURES finden Sie in der Referenzdokumentation zu MATCH_RECOGNIZE.
Angeben, wo nach der nächsten Übereinstimmung gesucht werden soll¶
Nachdem MATCH_RECOGNIZE eine Übereinstimmung gefunden hat, wird standardmäßig direkt nach dem Ende der letzten Übereinstimmung mit der Suche nach der nächsten Übereinstimmung begonnen. Wenn z. B. MATCH_RECOGNIZE eine Übereinstimmung in den Zeilen 2, 3 und 4 findet, dann beginnt MATCH_RECOGNIZE die Suche nach der nächsten Übereinstimmung in Zeile 5. Dies verhindert sich überlappende Übereinstimmungen.
Sie können jedoch alternative Startpunkte wählen.
Betrachten Sie die folgenden Daten:
Angenommen, Sie suchen in den Daten nach einem W-Muster (abwärts, aufwärts, abwärts, aufwärts). Es gibt drei W-Formen:
Monate: 1, 2, 3, 4 und 5.
Monate: 3, 4, 5, 6 und 7.
Monate: 5, 6, 7, 8 und 9.
Mit der SKIP-Klausel können Sie angeben, ob Sie alle Muster oder nur nicht überlappende Muster haben möchten. Die SKIP-Klausel unterstützt auch andere Optionen. Die SKIP-Klausel ist unter MATCH_RECOGNIZE ausführlicher dokumentiert.
Best Practices¶
Fügen Sie Ihrer
MATCH_RECOGNIZE-Klausel eine ORDER BY-Klausel hinzu.Beachten Sie, dass diese ORDER BY-Klausel nur innerhalb der
MATCH_RECOGNIZE-Klausel gilt. Wenn die gesamte Abfrage die Ergebnisse in einer bestimmten Reihenfolge zurückgeben soll, dann verwenden Sie eine zusätzlicheORDER BY-Klausel auf der äußersten Ebene der Abfrage.
Namen von Mustervariablen:
Verwenden Sie für Mustervariablen aussagekräftige Namen, damit Ihre Muster leichter zu verstehen und zu debuggen sind.
Prüfen Sie auf typografische Fehler in den Namen von Mustervariablen in den Klauseln
PATTERNundDEFINE.
Vermeiden Sie die Verwendung von Standardwerten für Unterklauseln, die Standardwerte haben. Machen Sie Ihre Auswahl explizit.
Testen Sie Ihr Muster mit einer kleinen Stichprobe von Daten, bevor Sie es auf Ihr gesamtes Dataset hochskalieren.
Die Funktionen
MATCH_NUMBER(),MATCH_SEQUENCE_NUMBER()undCLASSIFIER()sind bei der Fehlersuche sehr hilfreich.Ziehen Sie in Erwägung, eine
ORDER BY-Klausel in der äußersten Ebene der Abfrage zu verwenden, um eine geordnete Ausgabe mithilfe vonMATCH_NUMBER()undMATCH_SEQUENCE_NUMBER()zu erzwingen. Wenn die Ausgabedaten in einer anderen Reihenfolge sind, dann scheint die Ausgabe nicht mit dem Muster übereinzustimmen.
Vermeiden von Analysefehlern¶
Korrelation vs. Kausalität¶
Korrelation ist keine Garantie für Kausalität. MATCH_RECOGNIZE kann „falsch-positive“ Ergebnisse liefern (Fälle, in denen Sie ein Muster sehen, aber es ist nur ein Zufall).
Der Musterabgleich kann auch zu „falsch-negativen“ Ergebnissen führen (Fälle, in denen es ein Muster in der realen Welt gibt, das Muster aber nicht in der Datenprobe erscheint).
In den meisten Fällen ist das Finden einer Übereinstimmung (z. B. das Finden eines Musters, das auf Versicherungsbetrug hindeutet) nur der erste Schritt in einer Analyse.
Die folgenden Faktoren erhöhen typischerweise die Anzahl der falsch-positiven Ergebnisse:
Große Datasets
Suche nach einer großen Anzahl von Mustern
Suche nach kurzen oder einfachen Mustern
Die folgenden Faktoren erhöhen typischerweise die Anzahl der falsch-negativen Ergebnisse:
Kleine Datasets
Keine Suche nach allen möglichen relevanten Mustern
Suche nach Mustern, die komplexer als nötig sind
Reihenfolge-unabhängige Muster¶
Obwohl die meisten Musterabgleiche erfordern, dass die Daten in einer bestimmten Reihenfolge vorliegen (z. B. nach Zeit), gibt es Ausnahmen. Wenn zum Beispiel eine Person Versicherungsbetrug sowohl bei einem Autounfall als auch bei einem Wohnungseinbruch begeht, spielt es keine Rolle, in welcher Reihenfolge die Betrügereien geschehen.
Wenn das gesuchte Muster nicht Reihenfolge-abhängig ist, können Sie Operatoren wie „Alternative“ (|) und PERMUTE verwenden, um Ihre Suche weniger Reihenfolge-abhängig zu machen.
Beispiele¶
Dieser Abschnitt enthält zusätzliche Beispiele.
Noch mehr Beispiele finden Sie unter MATCH_RECOGNIZE.
Mehrtägige Kurssteigerungen finden¶
Die folgende Abfrage findet alle Muster, in denen der Kurs der Firma ABCD an zwei aufeinanderfolgenden Tagen gestiegen ist:
Beispiel für den PERMUTE-Operator¶
In diesem Beispiel wird der PERMUTE-Operator im Muster veranschaulicht. Suchen Sie nach allen Aufwärts- und Abwärtsspitzen in den Charts, und begrenzen Sie die Anzahl der steigenden Kurse auf zwei:
Beispiel für SKIP TO NEXT ROW-Option¶
In diesem Beispiel wird die Option SKIP TO NEXT ROW veranschaulicht. Diese Abfrage sucht nach W-förmigen Kurven im Chart der jeweiligen Firma. Die Übereinstimmungen können sich überschneiden.
Syntax für Ausschluss¶
In diesem Beispiel wird die Ausschlusssyntax im Muster gezeigt. Dieses Muster (wie das vorherige Muster) sucht nach W-Formen, aber die Ausgabe dieser Abfrage schließt fallende Kurse aus. Beachten Sie, dass in dieser Abfrage der Abgleich nach der letzten Zeile eines Treffers fortgesetzt wird:
Suche nach Mustern in nicht benachbarten Zeilen¶
In manchen Situationen möchten Sie vielleicht nach Mustern in nicht zusammenhängenden Zeilen suchen. Wenn Sie z. B. Protokolldateien analysieren, möchten Sie vielleicht nach allen Mustern suchen, in denen einem schwerwiegenden Fehler eine bestimmte Sequenz von Warnungen vorausgegangen ist. Vielleicht gibt es keine natürliche Möglichkeit, die Zeilen so zu partitionieren und zu sortieren, dass alle relevanten Meldungen (Zeilen) in einem einzigen Fenster und nebeneinander liegen. In dieser Situation benötigen Sie möglicherweise ein Muster, das nach bestimmten Ereignissen sucht, aber nicht erfordert, dass die Ereignisse in den Daten zusammenhängend sind.
Unten sehen Sie ein Beispiel für DEFINE- und PATTERN-Klauseln, die entweder zusammenhängende oder nicht zusammenhängende Zeilen erkennen, die dem Muster entsprechen. Das Symbol ANY_ROW ist als TRUE definiert (es stimmt also mit jeder Zeile überein). Der * nach jedem Auftreten von ANY_ROW besagt, dass zwischen der ersten Warnung und der zweiten Warnung sowie zwischen der zweiten Warnung und der fatalen Fehlerprotokollmeldung ANY_ROW keinmal, einmal oder mehrmals auftreten darf. Das gesamte Muster sagt also, dass nach WARNING1 gesucht werden soll, gefolgt von einer beliebigen Anzahl von Zeilen, gefolgt von WARNING2, gefolgt von einer beliebigen Anzahl von Zeilen, gefolgt von FATAL_ERROR. Damit die irrelevanten Zeilen nicht mit in der Ausgabe erscheinen, verwendet die Abfrage die Ausschluss-Syntax ({- und -}).
Problembehandlung¶
Fehler bei Verwendung von ONE ROW PER MATCH und Angeben von Spalten in der Select-Klausel¶
Die ONE ROW PER MATCH-Klausel verhält sich ähnlich wie eine Aggregatfunktion. Dies schränkt die möglichen Ausgabespalten ein, die Sie verwenden können. Wenn Sie z. B. ONE ROW PER MATCH verwenden und jede Übereinstimmung drei Zeilen mit unterschiedlichen Datumsangaben enthält, können Sie die Datumsspalte nicht als Ausgabespalte in der SELECT-Klausel angeben, da ein einzelnes Datum nicht für alle drei Zeilen korrekt sein kann.
Unerwartete Ergebnisse¶
Prüfen Sie, ob die
PATTERN- undDEFINE-Klauseln typografische Fehler aufweisen.Wenn ein in der
PATTERN-Klausel verwendeter Mustervariablenname in derDEFINE-Klausel nicht definiert ist (z. B. weil der Name entweder in derPATTERN- oder in derDEFINE-Klausel falsch eingegeben wurde), wird kein Fehler gemeldet. Stattdessen wird einfach angenommen, dass der Name der Mustervariablen für jede Zeile wahr ist.Überprüfen Sie die
SKIP-Klausel, um sicherzustellen, dass sie angemessen ist, z. B. um überlappende Muster ein- oder auszuschließen.