Übersicht zu Snowpipe-REST-Endpunkten zum Laden von Daten¶
Dieses Thema bietet eine Übersicht zu den Verwendungsdetails, die beim Aufrufen der öffentlichen REST-Endpunkte zum Laden von Daten und zum Abrufen von Ladeverlaufsberichten relevant sind.
Authentifizierung¶
Bei Aufrufen der öffentlichen Snowpipe-REST-Endpunkte wird eine schlüsselbasierte Authentifizierung und nicht die typische Benutzername/Kennwort-Authentifizierung verwendet, da der Datenerfassungsservice keine Clientsitzungen umfasst.
Um dem allgemeinen Prinzip der geringsten Berechtigungen zu folgen, empfehlen wir, einen separaten Benutzer und eine eigene Rolle für das Erfassen von Dateien über eine Pipe zu erstellen. Der Benutzer sollte mit dieser Rolle als Standardrolle erstellt werden, und die Rolle sollte über die minimalen Berechtigungen verfügen, die zum Einfügen von Dateien in die Zieltabelle zum Datenladen erforderlich sind.
Prozessablauf¶
Ihre Clientanwendung ruft einen öffentlichen REST-Endpunkt mit einer Liste von Datendateinamen und einem referenzierten Pipenamen auf (Java- und Python-SDKs werden Ihnen zur Verfügung gestellt). Wenn in dem Stagingbereich neue Datendateien gefunden werden, die der Liste entsprechen, werden sie in die Warteschlange gestellt. Von Snowflake bereitgestellte Computeressourcen laden basierend auf in der Pipe definierten Parametern Daten aus der Warteschlange in eine Snowflake-Tabelle.
Die folgende Abbildung zeigt den Prozessablauf der Snowpipe-REST-API:
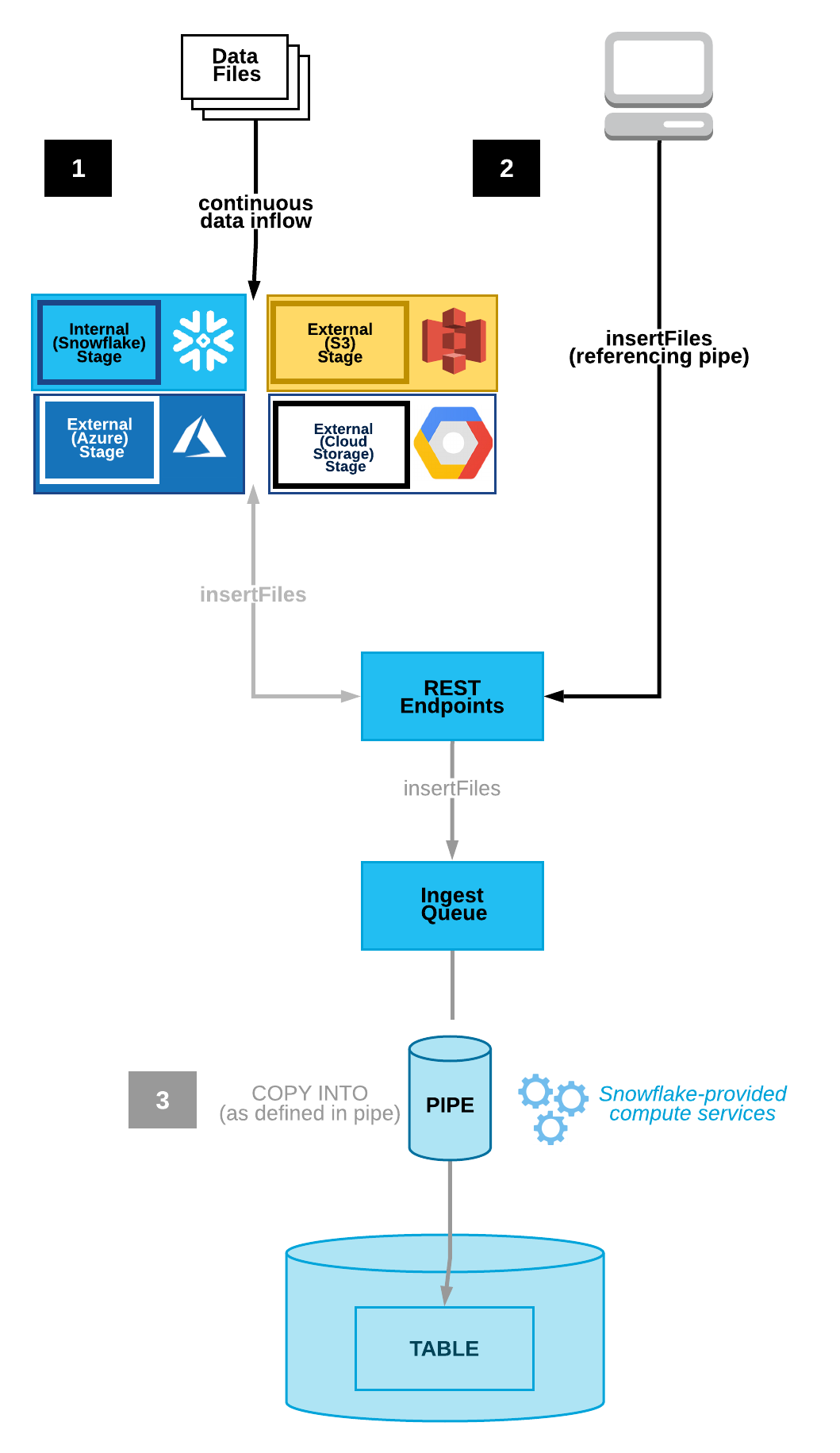
Datendateien werden in einen internen (Snowflake) oder externen (Amazon S3, Google Cloud Storage oder Microsoft Azure) Stagingbereich kopiert.
Ein Client ruft den
insertFiles-Endpunkt mit einer Liste der zu erfassenden Dateien und einer definierten Pipe auf.Der Endpunkt verschiebt die Dateien in eine Erfassungswarteschlange.
Ein von Snowflake bereitgestelltes virtuelles Warehouse lädt Daten aus den Warteschlangendateien in die Zieltabelle, basierend auf den in der angegebenen Pipe definierten Parametern.
Workflow¶
Dieser Abschnitt bietet einen umfassenden Überblick über den Setup- und Lade-Workflow.
Konfiguration von Snowpipe¶
Erstellen Sie ein benanntes Stagingobjekt, in dem Ihre Datendateien bereitgestellt werden. Snowpipe unterstützt sowohl interne (Snowflake) Stagingbereiche als auch externe Stagingbereiche, d. h. S3-Buckets.
Erstellen Sie ein Pipeobjekt mit CREATE PIPE.
Konfigurieren Sie die Sicherheit für den Benutzer, der das kontinuierliche Datenladen ausführen soll. Wenn Sie das Snowpipe-Datenladen auf einen einzelnen Benutzer beschränken möchten, müssen Sie die Schlüsselpaar-Authentifizierung für den Benutzer nur einmal konfigurieren. Danach müssen Sie nur noch Zugriffssteuerungsrechte für die Datenbankobjekte vergeben, die für jede Datenladeoperation verwendet werden.
Installieren Sie ein Client-SDK (Java oder Python) für den Aufruf der öffentlichen Snowpipe REST-Endpunkte.
Verwenden der Snowpipe-REST-API zum Laden von Daten¶
Option 1: Verwenden eines Clients zum Aufrufen der REST-API¶
Verwenden Sie einen Client, um die REST-API aufzurufen. Es wird ein Java- und Python-SDK-Beispielcode bereitgestellt. Weitere Informationen dazu finden Sie unter Option 1: Load data with the Snowpipe REST API.
Rufen Sie einen REST-Endpunkt mit einer Liste von Dateien auf, die beim Staging kontinuierlich geladen werden sollen.
Rufen Sie den Ladeverlauf ab.
Option 2: Verwenden von AWS Lambda zum Aufrufen der REST-API¶
Automatisieren Sie Snowpipe, indem Sie eine AWS Lambda-Funktion verwenden, um die REST-API aufzurufen. Eine Lambda-Funktion kann die REST-API aufrufen, um Daten nur aus Dateien zu laden, die in Amazon S3 gespeichert sind. Weitere Informationen dazu finden Sie unter Option 2: Automate Snowpipe with AWS Lambda.
Create an AWS Lambda function that calls the Snowpipe REST API to load data from your external (i.e. S3) stage.
Rufen Sie den Ladeverlauf ab.