Snowpipe REST エンドポイントのデータロードの概要¶
このトピックでは、パブリック REST エンドポイントを呼び出してデータをロードし、ロード履歴レポートを取得する際の使用方法の概要を説明します。
認証¶
インジェスションサービスはクライアントセッションを維持しないため、パブリックSnowpipe REST エンドポイントへの呼び出しでは、通常のユーザー名/パスワード認証ではなく、キーベースの認証が使用されます。
最小権限の一般原則に従うために、パイプを使用してファイルをインジェストする際に使用する、別個のユーザーとロールを作成することをお勧めします。ユーザーは、このロールを既定のロールとして作成する必要があります。また、ロールには、データをロードするためにターゲットテーブルにファイルを挿入するための必要な最小限の権限セットが必要です。
プロセスフロー¶
クライアントアプリケーションは、データファイル名のリストと参照されるパイプ名を使用して、パブリック REST エンドポイントを呼び出します(便宜上、JavaおよびPython SDKs を提供)。リストに一致する新しいデータファイルがステージで検出された場合、それらはロードのためにキューに入れられます。Snowflakeが提供するコンピューティングリソースは、パイプで定義されたパラメーターに基づいて、キューからSnowflakeテーブルにデータをロードします。
次の図は、Snowpipe REST API プロセスフローを示しています。
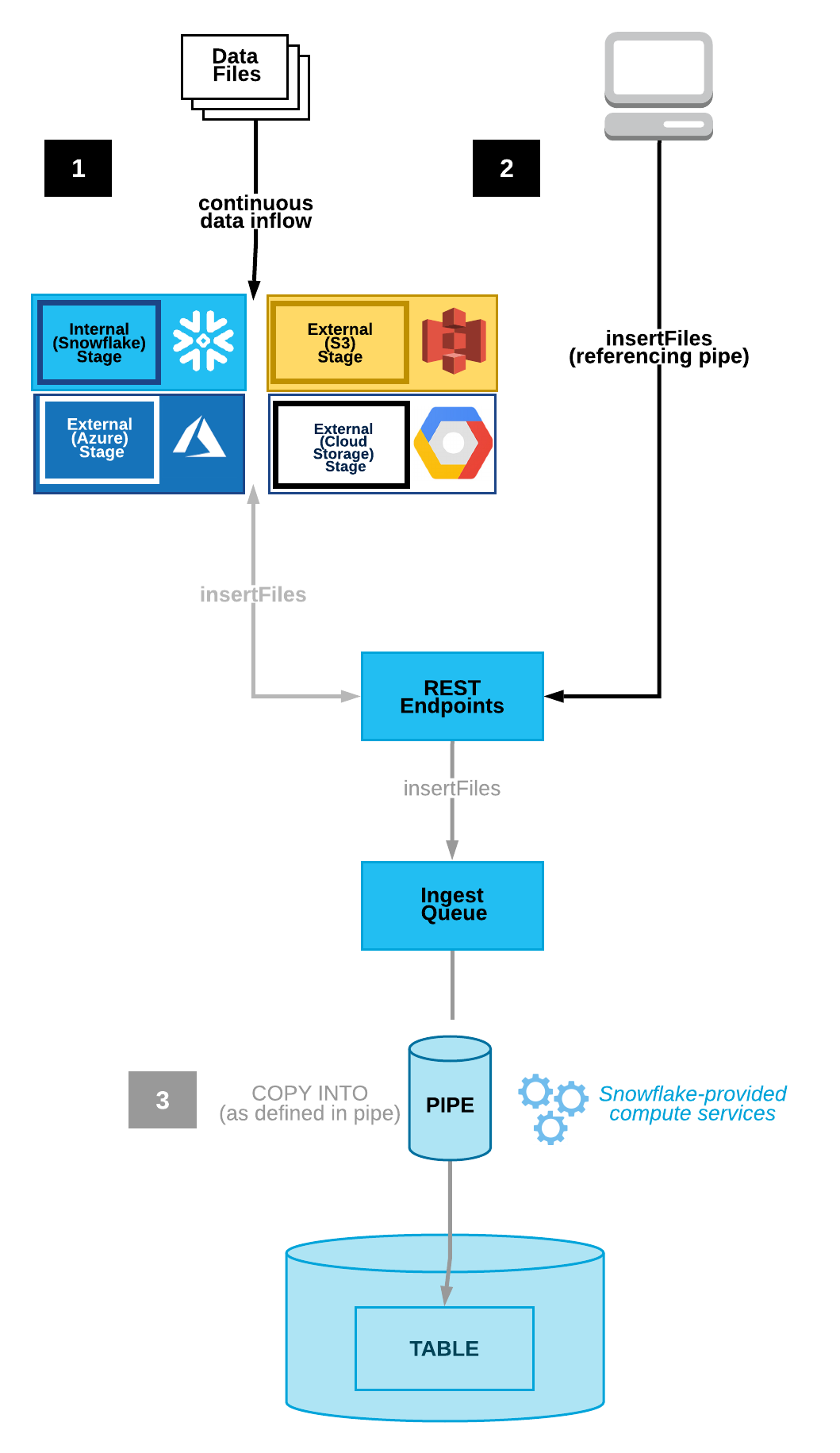
データファイルは、内部(Snowflake)または外部(Amazon S3、Google Cloud Storage、またはMicrosoft Azure)ステージにコピーされます。
クライアントは、インジェストするファイルのリストと定義済みのパイプを使用して
insertFilesエンドポイントを呼び出します。エンドポイントはこれらのファイルをインジェストキューに移動します。
Snowflakeが提供する仮想ウェアハウスは、指定されたパイプで定義されたパラメーターに基づいて、キューに入れられたファイルからターゲットテーブルにデータをロードします。
ワークフロー¶
このセクションでは、設定とロードのワークフローの概要を説明します。
Snowpipeの構成¶
データファイルをステージングする名前付きステージオブジェクトを作成します。Snowpipeは、内部(Snowflake)ステージと外部ステージ(S3バケット)の両方をサポートしています。
CREATE PIPE を使用してパイプオブジェクトを作成します。
継続的なデータロードを実行するユーザーのセキュリティを構成します。Snowpipeのデータロードを1人のユーザーに制限する場合は、そのユーザーのキーペア認証を1回構成するだけで済みます。その後は、各データのロードに使用されるデータベースオブジェクトに対するアクセス制御権限のみを付与する必要があります。
Snowpipeパブリック REST エンドポイントを呼び出すためのクライアント SDK (JavaまたはPython)をインストールします。
Snowpipe REST API を使用したデータのロード¶
オプション1: クライアントを使用して REST API を呼び出す¶
クライアントを使用して REST API を呼び出します。JavaおよびPython SDK サンプルコードが提供されています。詳細については、 Option 1: Load data with the Snowpipe REST API をご参照ください。
ステージング時にロードするには、ファイルのリストを使用して REST エンドポイントを呼び出します。
ロード履歴を取得します。
オプション2: AWS Lambdaを使用して REST APIを呼び出す¶
AWS Lambda関数を使用して REST API を呼び出すことにより、Snowpipeを自動化します。Lambda関数は REST API を呼び出して、Amazon S3にのみ保存されているファイルからデータをロードできます。詳細については、 Option 2: Automate Snowpipe with AWS Lambda をご参照ください。
Create an AWS Lambda function that calls the Snowpipe REST API to load data from your external (i.e. S3) stage.
ロード履歴を取得します。