Dynamische Tabellen¶
Dynamische Tabellen sind Tabellen, die auf der Grundlage einer definierten Abfrage und Zielaktualität automatisch aktualisiert werden. Dies vereinfacht die Datenumwandlung und das Pipeline-Management, ohne dass manuelle Aktualisierungen oder eine benutzerdefinierte Planung erforderlich sind.
Wenn Sie eine dynamische Tabelle erstellen, definieren Sie eine Abfrage, die angibt, wie Daten aus Basisobjekten transformiert werden sollen. Snowflake verwaltet den Aktualisierungszeitplan der dynamischen Tabelle und aktualisiert die Tabelle automatisch, um die Änderungen widerzuspiegeln, die aufgrund der Abfrage an den Basisobjekten vorgenommen wurden.
Wichtige Hinweise und allgemeine Best Practices¶
Unveränderlichkeitseinschränkungen: Verwenden Sie Unveränderlichkeitseinschränkungen, um die Aktualisierungen dynamischer Tabellen zu steuern. Die Einschränkungen halten bestimmte Zeilen statisch, während gleichzeitig inkrementelle Aktualisierungen der restlichen Tabelle ermöglicht werden. Sie verhindern unerwünschte Änderungen an markierten Daten, während andere Teile der Tabelle normale Aktualisierungen ermöglichen. Weitere Informationen dazu finden Sie unter Erläuterungen zu Unveränderlichkeitseinschränkungen.
Primärschlüssel: Snowflake verwendet zuverlässige Primärschlüssel, um Änderungen in Pipelines dynamischer Tabellen effizienter zu verfolgen. Wenn eine dynamische Tabelle über einen vom System abgeleiteten Primärschlüssel verfügt, können nachgelagerte Tabellen eine inkrementelle Aktualisierung verwenden, auch wenn die vorgelagerte Tabelle den vollständigen Aktualisierungsmodus verwendet. Weitere Informationen dazu finden Sie unter Erläuterungen zu Primärschlüsseln in dynamischen Tabellen.
Hinweise zur Leistung: Dynamische Tabellen verwenden die inkrementelle Verarbeitung für Workloads, die dies unterstützen. Dies kann die Leistung verbessern, indem nur geänderte Daten verarbeitet werden, anstatt ganze Tabellen neu zu berechnen. Die Leistung hängt von Ihren Abfragemustern und Ihrer Datenorganisation ab. Hinweise zur Optimierung der Leistung dynamischer Tabellen finden Sie unter Leistung und Optimierung dynamischer Tabellen.
Aufschlüsseln komplexer dynamischer Tabellen: Teilen Sie Ihre Pipeline in kleinere, fokussierte dynamische Tabellen auf, um die Leistung zu verbessern und die Problembehandlung zu vereinfachen. Weitere Informationen dazu finden Sie unter Best Practices für das Erstellen dynamischer Tabellen.
Funktionsweise von dynamischen Tabellen¶
Snowflake führt die in Ihrer CREATE DYNAMIC TABLE-Anweisung angegebene Definitionsabfrage aus, und Ihre dynamischen Tabellen werden durch einen automatischen Aktualisierungsprozess aktualisiert.
Das folgende Diagramm zeigt, wie dieser Prozess die Änderungen an den Basisobjekten berechnet und sie in der dynamischen Tabelle zusammenführt, indem die mit der Tabelle verbundenen Computeressourcen verwendet werden.
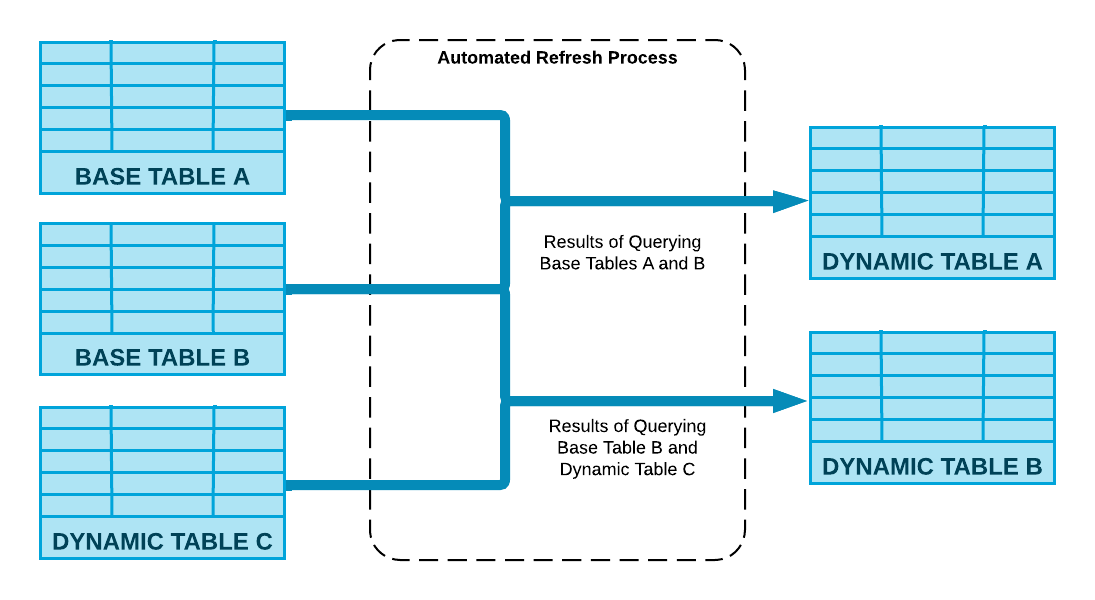
Zielverzögerung¶
Verwenden Sie Zielverzögerung, um festzulegen, wie aktuell Ihre Daten sein sollen. Normalerweise liegt die Aktualität der Tabellendaten nicht weit hinter der Aktualität der Basistabellen zurück. Mit der Zielverzögerung steuern Sie, wie oft die Tabelle aktualisiert wird und wie aktuell die Daten bleiben. Die Zielverzögerung wirkt sich auf die Aktualisierungshäufigkeit und die Computekosten aus.
Weitere Informationen dazu finden Sie unter Die Zielverzögerung dynamischer Tabellen verstehen. Eine Anleitung, wie Sie die Aktualität von Daten mit der Leistung in Einklang bringen können, finden Sie unter Optimieren der Leistung dynamischer Tabellen.
Aktualisierung dynamischer Tabellen¶
Dynamische Tabellen sind bestrebt, innerhalb der von Ihnen festgelegten Zielverzögerung aktualisiert zu werden. Eine Zielverzögerung von 5 Minuten stellt beispielsweise sicher, dass die Daten in der dynamischen Tabelle nicht mehr als 5 Minuten hinter den Datenaktualisierungen der Basistabelle zurückbleiben. Sie legen den Aktualisierungsmodus fest, wenn Sie die Tabelle erstellen. Danach können die Aktualisierungen nach einem Zeitplan oder manuell erfolgen.
Weitere Informationen dazu finden Sie unter Initialisierung und Aktualisierung dynamischer Tabellen verstehen und Dynamische Tabellen manuell aktualisieren.
Einsatzszenarios für dynamische Tabellen¶
Dynamische Tabellen sind ideal für die folgenden Szenarien:
Sie möchten Abfrageergebnisse materialisieren, ohne benutzerdefinierten Code zu schreiben.
Sie möchten das manuelle Verfolgen von Datenabhängigkeiten und das Verwalten von Aktualisierungszeitplänen vermeiden. Mit dynamischen Tabellen können Sie die Ergebnisse von Pipelines deklarativ definieren, ohne Transformationsschritte manuell verwalten zu müssen.
Sie möchten mehrere Tabellen für Datentransformationen in einer Pipeline miteinander verketten.
Sie benötigen keine fein abgestufte Kontrolle über die Aktualisierungszeitpläne, und Sie müssen nur eine Zielaktualität für die Pipeline angeben. Snowflake übernimmt die Orchestrierung von Datenaktualisierungen, einschließlich Planung und Ausführung, auf der Grundlage Ihrer Anforderungen an die Aktualität von Zielen.
Beispielhafte Anwendungsfälle¶
Langsam wechselnde Dimensionen (SCDs): Dynamische Tabellen können verwendet werden, um SDCs vom Typ 1 und Typ 2 zu implementieren, indem sie aus einem Änderungsstream lesen und mithilfe von Fensterfunktionen nach über nach Änderungszeitpunkt geordneten Schlüsseln arbeiten. Diese Methode behandelt Einfügungen, Löschungen und Aktualisierungen, die nicht in der richtigen Reihenfolge erfolgen, und vereinfacht so die Erstellung von SCDs. Weitere Informationen dazu finden Sie unter Slowly Changing Dimensions mit dynamischen Tabellen.
Joins und Aggregationen: Um schnelle Abfragen zu ermöglichen, können Sie dynamische Tabellen verwenden, um langsame Joins und Aggregationen inkrementell vorzuberechnen. Hinweise zur Optimierung dieser Operatoren für die inkrementelle Aktualisierung finden Sie unter Optimieren von Abfragen für inkrementelle Aktualisierungen.
Übergänge von Batch zu Streaming: Dynamische Tabellen unterstützen nahtlose Übergänge von Batch zu Streaming mit einem einzigen ALTER DYNAMIC TABLE-Befehl. Sie können die Aktualisierungshäufigkeit in Ihrer Pipeline steuern, um ein Gleichgewicht zwischen Kosten und Aktualität der Daten herzustellen.