Übersicht zum Kafka-Konnektor¶
Dieses Thema bietet eine Übersicht zu Apache Kafka und den Snowflake-Konnektor für Kafka.
Bemerkung
Der Kafka-Konnektor unterliegt den Nutzungsbedingungen für Konnektoren.
Einführung in Apache Kafka¶
Die Apache Kafka-Software verwendet ein Veröffentlichen/Abonnieren-Modell für das Schreiben und Lesen von Datenströmen, ähnlich einer Nachrichtenwarteschlange oder einem Enterprise-Messaging-System. Mit Kafka können Prozesse Nachrichten asynchron lesen und schreiben. Ein Abonnent muss nicht direkt mit einem Herausgeber verbunden sein. Ein Herausgeber kann eine Nachricht in Kafka in eine Warteschlange stellen, damit der Abonnent sie später empfangen kann.
Eine Anwendung veröffentlicht Nachrichten zu einem Thema, und eine Anwendung abonniert ein Thema, um die entsprechenden Nachrichten zu empfangen. Kafka kann Nachrichten verarbeiten und übermitteln; dies liegt jedoch außerhalb des Rahmens dieses Dokuments. Themen können in Partitionen unterteilt werden, um die Skalierbarkeit zu verbessern.
Kafka Connect ist ein Framework zum Verbinden von Kafka mit externen Systemen, einschließlich Datenbanken. Ein Kafka Connect-Cluster ist ein vom Kafka-Cluster getrennter Cluster. Der Kafka Connect-Cluster unterstützt das Ausführen und das horizontale Skalieren von Konnektoren (Komponenten, die das Lesen und/oder Schreiben zwischen externen Systemen unterstützen).
Der Kafka-Konnektor kann in einem Kafka Connect-Cluster ausgeführt werden, um Daten aus Kafka-Themen zu lesen und die Daten in Snowflake-Tabellen zu schreiben.
Snowflake bietet zwei Versionen des Konnektors:
A version for the Confluent package version of Kafka.
Weitere Informationen zu Kafka Connect finden Sie unter https://docs.confluent.io/current/connect/.
Bemerkung
Eine gehostete Version des Kafka-Konnektors ist in Confluent Cloud verfügbar. Weitere Informationen dazu finden Sie unter https://docs.confluent.io/current/cloud/connectors/cc-snowflake-sink.html.
Eine Version für das Apache Kafka-OSS-Paket (Open Source-Software).
Weitere Informationen zu Apache Kafka finden Sie unter https://kafka.apache.org/.
Aus der Perspektive von Snowflake erzeugt ein Kafka-Thema einen Zeilenstream, der in eine Snowflake-Tabelle eingefügt wird. Im Allgemeinen enthält jede Kafka-Nachricht eine Zeile.
So wie viele Plattformen zum Veröffentlichen/Abonnieren von Nachrichten erlaubt auch Kafka eine m:n-Beziehung zwischen Herausgebern und Abonnenten. Eine einzelne Anwendung kann für viele Themen veröffentlicht werden, und eine einzelne Anwendung kann für mehrere Themen abonniert werden. Bei Snowflake besteht das typische Muster darin, dass ein Thema Nachrichten (Zeilen) für eine Snowflake-Tabelle bereitstellt.
Die aktuelle Version des Kafka-Konnektors ist auf das Laden von Daten in Snowflake beschränkt. Der Kafka-Konnektor unterstützt zwei Methoden zum Laden von Daten:
Weitere Informationen finden Sie unter Laden von Daten in Snowflake und Verwenden des Snowflake-Konnektors für Kafka mit Snowpipe Streaming.
Zieltabellen für Kafka-Themen¶
Kafka-Themen können in der Kafka-Konfiguration vorhandenen Snowflake-Tabellen zugeordnet werden. Wenn die Themen nicht zugeordnet sind, erstellt der Kafka-Konnektor für jedes Thema eine neue Tabelle unter Verwendung des Themennamens.
Der Konnektor konvertiert den Themennamen nach den folgenden Regeln in einen gültigen Snowflake-Tabellennamen:
Themennamen in Kleinbuchstaben werden in Tabellennamen in Großbuchstaben umgewandelt.
Wenn das erste Zeichen im Themennamen kein Buchstabe (
a-zoderA-Z) oder Unterstrich (_) ist, wird dem Tabellennamen vom Konnektor ein Unterstrich vorangestellt.Wenn ein Zeichen innerhalb des Themennamens kein zulässiges Zeichen für einen Snowflake-Tabellennamen ist, wird dieses Zeichen durch den Unterstrich ersetzt. Weitere Informationen dazu, welche Zeichen in Tabellennamen gültig sind, finden Sie unter Anforderungen an Bezeichner.
Beachten Sie, dass die Namen von zwei Tabellen im selben Schema möglicherweise identisch sind, wenn der Kafka-Konnektor den Namen der für ein Kafka-Thema erstellten Tabelle anpassen muss. Wenn Sie beispielsweise Daten aus den Themen numbers+x und numbers-x lesen, lauten die für diese Themen erstellten Tabellen NUMBERS_X. Um ein versehentliches Kopieren von Tabellennamen zu vermeiden, hängt der Konnektor ein Suffix an den Tabellennamen an. Das Suffix ist ein Unterstrich, gefolgt von einem generierten Hash-Code.
Tipp
Snowflake empfiehlt, wenn möglich Themennamen auszuwählen, die den Regeln für Snowflake-Bezeichnernamen entsprechen.
Schema von Tabellen für Kafka-Themen¶
Das Schema für eine Tabelle, die vom Kafka-Konnektor geladen wird, hängt vom Tabellentyp ab und davon, wie Sie den Konnektor konfigurieren:
Die meisten Tabellen verwenden das in diesem Abschnitt beschriebene Standardschema.
Wenn Sie schema detection and evolution verwenden, enthält das Schema Spalten, die dem benutzerdefinierten Schema entsprechen.
Wenn Sie in eine Iceberg-Tabelle einlesen, enthält das Schema dieselben Standardspalten (
record_contentundrecord_metadata). Es handelt sich jedoch um strukturierte Spalten vom Typ anstelle von VARIANT.
Mit Snowpipe oder Snowpipe Streaming verfügt jede vom Kafka-Konnektor geladene Snowflake-Tabelle standardmäßig über ein Schema, das aus zwei VARIANT-Spalten besteht:
RECORD_CONTENT. Diese enthält die Kafka-Nachricht.
RECORD_METADATA. Diese enthält Metadaten zur Nachricht, z. B. das Thema, aus dem die Nachricht gelesen wurde.
Wenn Snowflake die Tabelle erstellt, enthält die Tabelle nur diese beiden Spalten. Wenn der Benutzer die Tabelle für den Kafka-Konnektor erstellt, zu der Zeilen hinzugefügt werden sollen, kann die Tabelle mehr als diese beiden Spalten enthalten (zusätzliche Spalten müssen NULL-Werte zulassen, da Daten vom Konnektor keine Werte für diese Spalten enthalten).
Die Spalte RECORD_CONTENT enthält die Kafka-Nachricht.
Eine Kafka-Nachricht hat eine interne Struktur, die von den gesendeten Informationen abhängt. Beispielsweise kann eine Nachricht von einem IoT-Wettersensor den Zeitstempel, zu dem die Daten erfasst wurden, den Ort des Sensors, die Temperatur, die Luftfeuchtigkeit usw. enthalten. Eine Nachricht von einem Inventarsystem kann die Produkt-ID und die Anzahl der verkauften Artikel enthalten, ggf. zusammen mit einem Zeitstempel, der angibt, wann sie verkauft oder versandt wurden.
Normalerweise weist jede Nachricht in einem bestimmten Thema dieselbe Grundstruktur auf. Unterschiedliche Themen verfügen normalerweise über unterschiedliche Strukturen.
Jede Kafka-Nachricht wird im JSON-Format oder Avro-Format an Snowflake übergeben. Der Kafka-Konnektor speichert diese formatierten Informationen in einer einzigen Spalte vom Typ VARIANT. Die Daten werden nicht analysiert und in der Snowflake-Tabelle auch nicht auf mehrere Spalten aufgeteilt.
Die Spalte RECORD_METADATA enthält die folgenden Informationen:
Feld |
Java-. Datentyp |
SQL-. Datentyp |
Erforderlich |
Beschreibung |
|---|---|---|---|---|
topic |
Zeichenfolge |
VARCHAR |
Ja |
Der Name des Kafka-Themas, aus dem der Datensatz stammt. |
partition |
Zeichenfolge |
VARCHAR |
Ja |
Die Nummer der Partition innerhalb des Themas. (Beachten Sie, dass dies die Kafka-Partition ist, nicht die Snowflake-Mikropartition.) |
offset |
long |
INTEGER |
Ja |
Der Offset in dieser Partition. |
CreateTime / . LogAppendTime |
long |
BIGINT |
Nein |
Dies ist der Zeitstempel, der der Nachricht im Kafka-Thema zugeordnet ist. Der Wert ist Millisekunden seit Mitternacht, 1. Januar 1970, UTC. Weitere Informationen dazu finden Sie unter: https://kafka.apache.org/0100/javadoc/org/apache/kafka/clients/producer/ProducerRecord.html |
SnowflakeConnectorPushTime |
long |
BIGINT |
Nein |
Nur verfügbar bei Verwendung von Snowpipe Streaming. Ein Zeitstempel, wann ein Datensatz in einen Ingest-SDK-Puffer verschoben wurde. Der Wert ist die Anzahl der Millisekunden seit Mitternacht am 1. Januar 1970, UTC. Weitere Informationen finden Sie unter Abschätzen der Datenaufnahme-Latenz. |
key |
Zeichenfolge |
VARCHAR |
Nein |
Wenn die Nachricht eine Kafka KeyedMessage ist, ist dies der Schlüssel für diese Nachricht. Damit der Konnektor den Schlüssel in RECORD_METADATA speichern kann, muss der Parameter key.converter in Kafka-Konfigurationseigenschaften auf „org.apache.kafka.connect.storage.StringConverter“ gesetzt sein. Andernfalls ignoriert der Konnektor die Schlüssel. |
Schema-ID |
int |
INTEGER |
Nein |
Wenn Sie Avro mit einer Schemaregistrierung verwenden, um ein Schema anzugeben, ist dies die ID des Schemas in dieser Registrierung. |
headers |
Object |
OBJECT |
Nein |
Ein Header ist ein benutzerdefiniertes Schlüssel-Wert-Paar, das dem Datensatz zugeordnet ist. Jeder Datensatz kann 0, 1 oder mehrere Header haben. |
Die Menge der in der Spalte RECORD_METADATA aufgezeichneten Metadaten kann mithilfe der optionalen Kafka-Konfigurationseigenschaften konfiguriert werden. Weitere Informationen dazu finden Sie unter Installieren und Konfigurieren des Kafka-Konnektors.
Bei den Feldnamen und Werten muss die Groß- und Kleinschreibung beachtet werden.
In JSON-Syntax sieht eine Beispielnachricht möglicherweise wie folgt aus:
Sie können die Snowflake-Tabellen direkt abfragen, indem Sie die entsprechende Syntax zum Abfragen von VARIANT-Spalten verwenden.
Hier ist ein einfaches Beispiel für das Extrahieren von Daten anhand des Themas in RECORD_METADATA:
Die Ausgabe würde ungefähr so aussehen:
Alternativ können Sie die Daten aus diesen vereinfachten Tabellen extrahieren, in einzelne Spalten reduzieren und in andere Tabellen speichern, die normalerweise einfacher abzufragen sind.
Workflow für den Kafka-Konnektor¶
Der Kafka-Konnektor führt den folgenden Vorgang aus, um Kafka-Themen zu abonnieren und Snowflake-Objekte zu erstellen:
Der Kafka-Konnektor abonniert ein oder mehrere Kafka-Themen basierend auf den Konfigurationsinformationen, die über die Kafka-Konfigurationsdatei oder die Befehlszeile (oder das Confluent Control Center; nur Confluent) bereitgestellt werden.
Der Konnektor erstellt die folgenden Objekte für jedes Thema:
Einen internen Stagingbereich zum temporären Speichern von Datendateien für jedes Thema
Eine Pipe zum Erfassen der Datendateien für jede Themenpartition
Eine Tabelle für jedes Thema. Wenn die für jedes Thema angegebene Tabelle nicht vorhanden ist, wird sie vom Konnektor erstellt. Andernfalls erstellt der Konnektor die Spalten RECORD_CONTENT und RECORD_METADATA in der vorhandenen Tabelle und überprüft, ob die anderen Spalten nullwertfähig sind (und erzeugt einen Fehler, wenn dies nicht der Fall ist).
Die folgende Abbildung zeigt für Kafka den Ablauf der Erfassung mit dem Kafka-Konnektor:
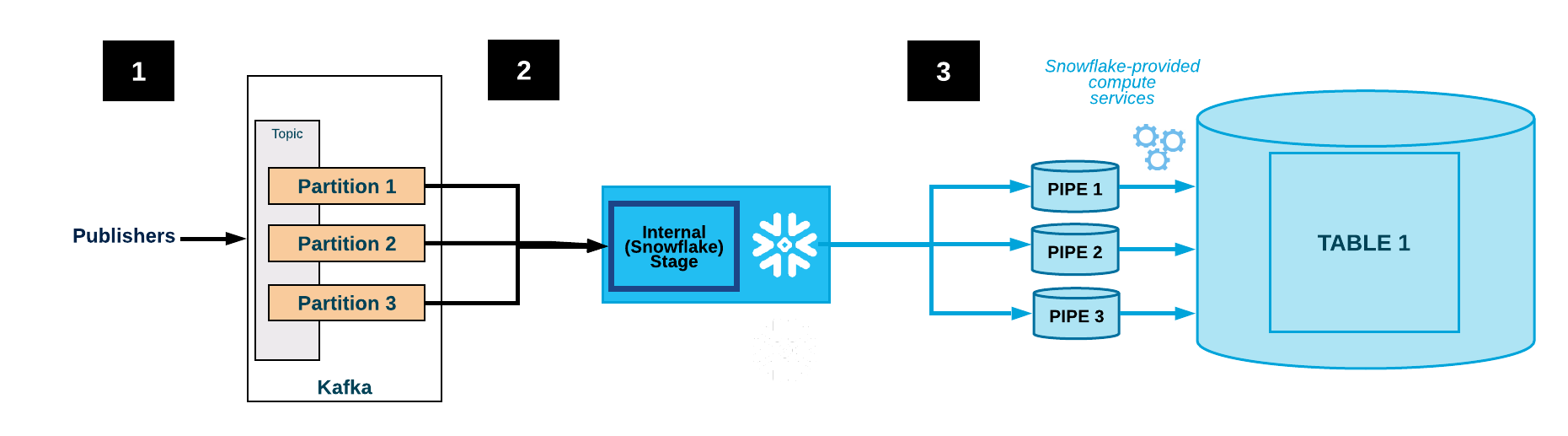
Eine oder mehrere Anwendungen veröffentlichen JSON- oder Avro-Datensätze in einem Kafka-Cluster. Die Datensätze sind in eine oder mehrere Themenpartitionen aufgeteilt.
Der Kafka-Konnektor puffert Nachrichten aus den Kafka-Themen. Wenn ein Schwellenwert (Zeit oder Speicher oder Anzahl der Nachrichten) erreicht ist, schreibt der Konnektor die Nachrichten in eine temporäre Datei in einem internen Stagingbereich. Der Konnektor löst Snowpipe aus, um die temporäre Datei zu erfassen. Snowpipe kopiert einen Zeiger auf die Datendatei in eine Warteschlange.
Ein von Snowflake bereitgestelltes virtuelles Warehouse lädt Daten aus der Stagingdatei über die für die Kafka-Themenpartition erstellte Pipe in die Zieltabelle (d. h. die in der Konfigurationsdatei für das Thema angegebene Tabelle).
(Nicht gezeigt) Der Konnektor überwacht Snowpipe und löscht jede Datei im internen Stagingbereich, nachdem bestätigt wurde, dass die Daten der Datei in die Tabelle geladen wurden.
Wenn ein Fehler das Laden der Daten verhindert hat, verschiebt der Konnektor die Datei in den Tabellen-Stagingbereich und gibt eine Fehlermeldung aus.
Der Konnektor wiederholt die Schritte 2–4.
Achtung
Snowflake befragt die insertReport-API eine Stunde lang. Wenn der Status einer aufgenommenen Datei innerhalb dieser Stunde nicht erfolgreich ist, werden die aufgenommenen Dateien in eine Tabellen-Stagingbereich verschoben.
Es kann mindestens eine Stunde dauern, bis diese Dateien im Tabellen-Stagingbereich zur Verfügung stehen. Dateien werden nur dann in den Tabellen-Stagingbereich verschoben, wenn ihr Erfassungsstatus innerhalb der letzten Stunde nicht gefunden werden konnte.
Fehlertoleranz¶
Sowohl Kafka als auch der Kafka-Konnektor sind fehlertolerant. Meldungen werden weder dupliziert noch unbemerkt gelöscht.
Die Datendeduplizierungslogik im Snowpipe-Workflow für die Datenladekette beseitigt doppelte Kopien von sich wiederholenden Daten, außer in seltenen Szenarios. Wenn beim Laden eines Datensatzes durch Snowpipe ein Fehler festgestellt wird (z. B. der Datensatz war kein wohlgeformtes JSON oder Avro), wird der Datensatz nicht geladen. Stattdessen wird der Datensatz in einen Tabellen-Stagingbereich verschoben.
Der Kafka-Konnektor mit Snowpipe Streaming unterstützt Dead-letter Queues (DLQs, Warteschlangen für nicht zustellbare Meldungen) zur Fehlerbehandlung. Weitere Informationen dazu finden Sie unter Fehlerbehandlung und DLQ-Eigenschaften für den Kafka-Konnektor mit Snowpipe Streaming.
Einschränkungen der Fehlertoleranz mit dem Konnektor¶
Kafka-Themen können mit einer Begrenzung des Speicherplatzes oder der Aufbewahrungsdauer konfiguriert werden.
Die standardmäßige Aufbewahrungsdauer beträgt 7 Tage. Wenn das System länger als die Aufbewahrungsdauer offline ist, werden abgelaufene Datensätze nicht geladen. Auf ähnliche Weise werden einige Nachrichten nicht zugestellt, wenn das Speicherplatzlimit von Kafka überschritten wurde.
Wenn Nachrichten im Kafka-Thema gelöscht oder aktualisiert werden, spiegeln sich diese Änderungen ggf. nicht in der Snowflake-Tabelle wider.
Achtung
Instanzen des Kafka-Konnektors kommunizieren nicht miteinander. Wenn Sie mehrere Instanzen von Snowflake-Konnektor für Apache Kafka zu denselben Themen oder Partitionen starten, werden möglicherweise mehrere Kopien derselben Zeile in die Tabelle eingefügt. Dies wird nicht empfohlen: Jedes Thema sollte nur von einer Instanz des Snowflake-Konnektors für Apache Kafka verarbeitet werden.
Es ist theoretisch möglich, dass Nachrichten von Kafka schneller gesendet werden, als Snowflake sie erfassen kann. In der Praxis ist das jedoch unwahrscheinlich. Sollte es doch dazu kommen, ist zur Behebung des Problems eine Leistungsoptimierung des Kafka Connect-Clusters erforderlich. Beispiel: Beispiel:
Optimieren der Anzahl der Knoten im Connect-Cluster.
Optimieren der Anzahl der Aufgaben, die dem Konnektor zugewiesen sind.
Verstehen der Auswirkungen der Netzwerkbandbreite zwischen dem Konnektor und der Snowflake-Umgebung.
Wichtig
Es gibt keine Garantie, dass die Zeilen in der Reihenfolge eingefügt werden, in der sie ursprünglich veröffentlicht wurden.
Unterstützte Plattformen¶
Der Kafka-Konnektor kann in jedem Kafka Connect-Cluster ausgeführt werden und Daten an ein Snowflake-Konto auf jeder unterstützten Cloudplattform senden.
Protobuf-Datenunterstützung¶
Kafka-Konnektor 1.5.0 (oder höher) unterstützt Protokollpuffer (protobuf) über einen protobuf-Konverter. Weitere Details dazu finden Sie unter Laden von Protobuf-Daten mit dem Snowflake-Konnektor für Kafka.
Abrechnungsdaten¶
Für die Verwendung des Kafka-Konnektors wird keine direkte Gebühr erhoben. Es fallen jedoch indirekte Kosten an:
Snowpipe dient zum Laden der Daten, die der Konnektor von Kafka liest; die Verarbeitungszeit von Snowpipe wird Ihrem Konto in Rechnung gestellt.
Der Datenspeicher wird Ihrem Konto belastet.
Einschränkungen für Kafka-Konnektor¶
SMTs (Single Message Transformations) werden auf Nachrichten angewendet, die über Kafka Connect übertragen werden. Wenn Sie Kafka-Konfigurationseigenschaften konfigurieren und entweder key.converter oder value.converter auf einen der folgenden Werte setzen, wird SMTs für den entsprechenden Schlüssel oder Wert nicht unterstützt:
com.snowflake.kafka.connector.records.SnowflakeJsonConvertercom.snowflake.kafka.connector.records.SnowflakeAvroConvertercom.snowflake.kafka.connector.records.SnowflakeAvroConverterWithoutSchemaRegistry
Wenn weder key.converter noch value.converter festgelegt sind, werden die meisten SMTs unterstützt, mit der aktuellen Ausnahme von regex.router.
Obwohl SMTs von Snowflake-Konvertern nicht unterstützt werden, unterstützt der Kafka-Konnektor, Version 1.4.3 (oder höher) viele Community-basierte Konverter wie die folgenden:
io.confluent.connect.avro.AvroConverterorg.apache.kafka.connect.json.JsonConverter
Weitere Informationen zu SMTs finden Sie unter https://docs.confluent.io/current/connect/transforms/index.html.