Snowpipe Streaming¶
Snowpipe Streaming ist der Echtzeit-Erfassungsservice von Snowflake, der auf der leistungsstarken Architektur basiert. Er ermöglicht es Anwendungen, Streaming-Daten direkt in Snowflake-Tabellen zu laden, wenn Zeilen eintreffen, ohne Dateien bereitzustellen oder Zwischenspeicher zu verwalten. Die Daten stehen innerhalb von Sekunden nach der Erfassung für Abfragen zur Verfügung und unterstützen Anwendungsfälle von IoT-Telemetrie und Change Data Capture (CDC)-Pipelines zur Betrugserkennung und für Live-Analysen.
Snowpipe Streaming bietet:
Bis zu 10 GB /s-Durchsatz pro Tabelle
bis zu 5 Sekunden End-to-End-Latenz zwischen Erfassung und Abfrage
Genau einmalige Zustellung durch integrierte Offset-Token-Verfolgung
Geordnete Datenaufnahme innerhalb jedes Kanals
Streaming in von Snowflake verwaltete:doc:
Apache Iceberg</user-guide/tables-iceberg>-Tabellen
Warum sollten Sie Snowpipe Streaming verwenden?¶
Genau einmalige Bereitstellung: Das integrierte Tracking von Offset-Tokens ermöglicht eine „exactly-once“-Semantik. Ihre Anwendung verfolgt bestätigte Offsets und Wiederholungen ab der letzten übertragenen Position bei der Wiederherstellung und verhindert so doppelte Daten und Datenverluste. Weitere Informationen dazu finden Sie unter Offset-Tokens und genau einmalige Zustellung.
Geordnete Datenaufnahme: Zeilen werden innerhalb jedes Channels in der vorgegebenen Reihenfolge aufgenommen. Kanäle lassen sich auf natürliche Weise den Quellpartitionen (z. B. Kafka-Themenpartitionen) zuordnen, wodurch eine deterministische Wiederholung und eine verlustlose Wiederherstellung ermöglicht wird.
** Hoher Durchsatz, geringe Latenz **: Ausgelegt für Unterstützung von Erfassungsgeschwindigkeiten von bis zu 10 GB/s pro Tabelle, wobei die Daten in nur 5 Sekunden abfragebereit sind.
Transformationen während der Ausführung: Bereinigen, Umwandeln und Transformieren von Daten während der Erfassung mithilfe von COPY-Befehlssyntax innerhalb des PIPEObjekts. Zeilen werden gefiltert, Spalten neu angeordnet, Datentypen konvertiert und Ausdrücke angewendet, bevor die Daten in die Zieltabelle geschrieben werden – ohne dass ein separater ETL-Schritt erforderlich ist.
Vor dem Clustering zum Zeitpunkt der Datenaufnahme: Sortieren von Daten während der Erfassung, um die Abfrageleistung bei Tabellen mit Gruppierungsschlüsseln zu optimieren.
Unterstützung von Apache Iceberg-Tabellen: Streamen von Daten in von Snowflake verwaltete Iceberg-Tabellen, einschließlich Iceberg-Tabellen der Version 2 und der Version 3. Weitere Informationen dazu finden Sie unter High-Performance-Architektur von Snowpipe Streaming mit Apache Iceberg™-Tabellen.
Schemaentwicklung: Passen Tabellenschemas automatisch an sich ändernde Datenstrukturen an. Snowflake kann neue Spalten, die im eingehenden Stream erkannt werden, ohne manuelle DDL-Änderungen hinzufügen.
Vereinfachte Pipelines: SDKs schreiben Zeilen direkt in Tabellen, wodurch Staging-Dateien oder zwischengeschaltete Cloud-Speicher nicht mehr benötigt werden.
Serverlos und skalierbar: Computeressourcen skalieren automatisch auf der Grundlage der Datenaufnahmelast. Keine zu verwaltende Infrastruktur.
Transparente Preise: Durchsatzbasierte Abrechnung, berechnet durch Credits pro unkomprimierter GB der aufgenommenen Daten. Weitere Informationen dazu finden Sie unter Snowpipe Streaming high-performance architecture: Understand your costs.
So stellen Sie die Verbindung her¶
Snowpipe Streaming unterstützt mehrere Erfassungspfade, um unterschiedlichen Workloads gerecht zu werden:
Integration |
Am besten geeignet für |
|---|---|
Kundenspezifische Anwendungen mit hohem Durchsatz Erfordert Java 11 oder höher. |
|
Data Engineering und Python-native-Workflows. Erfordert Python 3.9 oder höher. |
|
Leichte Workloads, IoT-Geräte und Edge-Bereitstellungen. |
|
Apache Kafka-Themenaufnahme. |
Sowohl Java- als auch Python-SDKs verwenden einen Rust-basierten Client-Core, um die clientseitige Performance zu verbessern und den Ressourcenverbrauch zu reduzieren.
Bemerkung
Wir empfehlen, mit dem Snowpipe Streaming-SDK über die REST API zu beginnen, um von der verbesserten Leistung und dem einfacheren Einstieg zu profitieren.
Um zu beginnen, siehe Tutorial: Erste Schritte mit SDK oder Tutorial: Erste Schritte mit REST API.
Technische Details zum PIPE-Objekt, zu Channels, Offset-Tokens und unterstützten Datentypen finden Sie unter Key concepts.
Empfohlen für¶
Streaming-Workloads mit hohem Volumen, die bis zu 10 GB/s-Durchsatz erfordern
Echtzeitanalysen und -dashboards mit einer Datenaktualität von nur 5 Sekunden
IoT und Edge-Bereitstellungen unter Verwendung der REST API
CDC (Change Data Capture)-Pipelines mit genau einmaligen Bereitstellungsgarantien
Apache Kafka topic ingestion using the Snowflake Connector for Kafka
Streaming in Apache Iceberg-Tabellen für die Analyse offener Tabellenformate
Bemerkung
Suchen Sie nach SQL-nativem Streaming? Siehe Dynamische Tabellen und Streams mit Aufgaben für deklarative Streaming-Pipelines.
Snowpipe Streaming versus Snowpipe¶
Snowpipe Streaming ist als Ergänzung zu Snowpipe gedacht, nicht als Ersatz. Verwenden Sie Snowpipe Streaming in Szenarien, in denen Daten als Zeilen eintreffen (z. B. aus Apache Kafka-Themen, IoT-Geräten oder Anwendungsereignissen) anstelle von Dateien. Mit Snowpipe Streaming müssen Sie keine Dateien erstellen, um Daten in Snowflake-Tabellen zu laden.
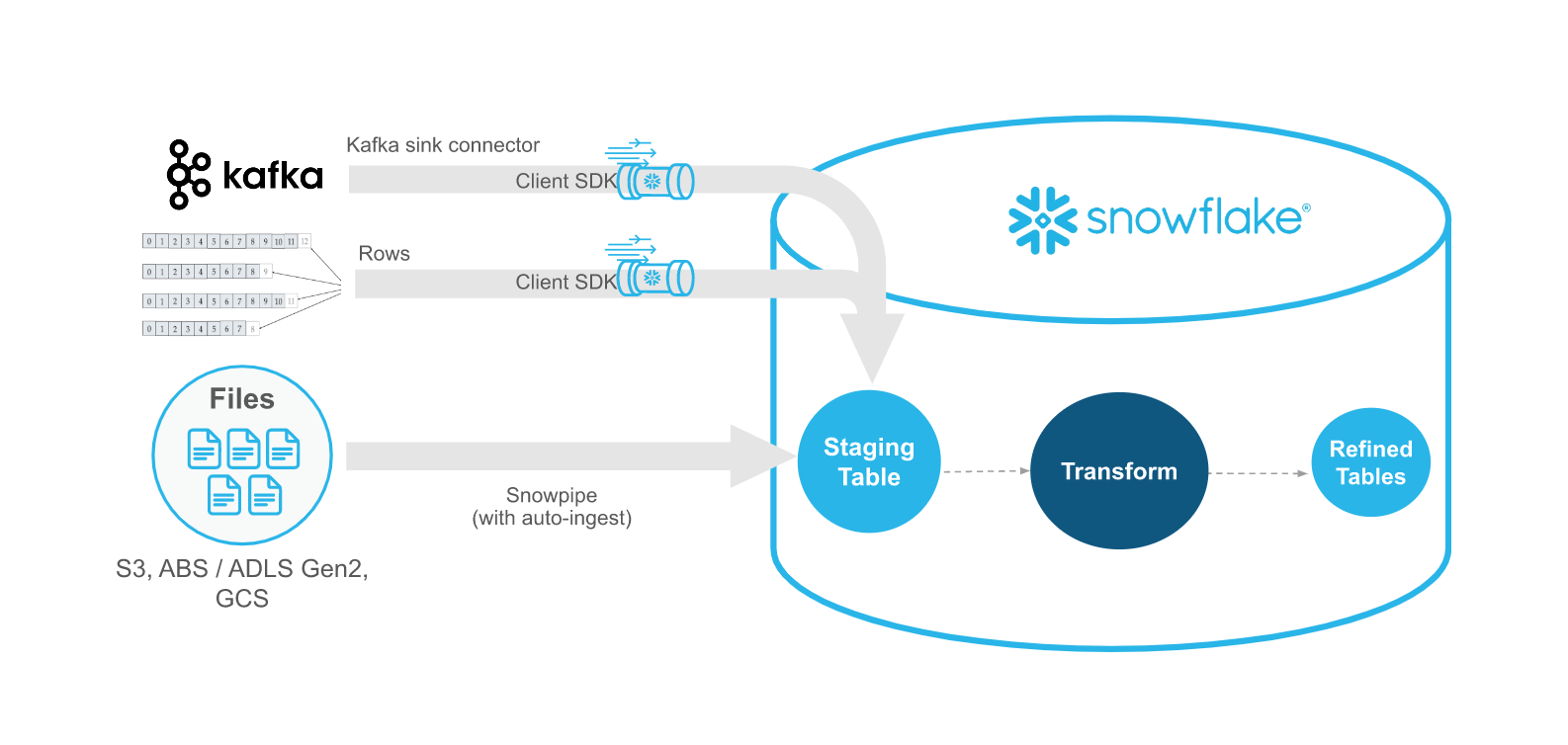
In der folgenden Tabelle werden die Unterschiede zwischen Snowpipe Streaming und Snowpipe beschrieben:
Kategorie |
Snowpipe Streaming |
Snowpipe |
|---|---|---|
Form der zu ladenden Daten |
Zeilen |
Dateien. Wenn Ihre bestehende Datenpipeline Dateien im Blobspeicher generiert, empfehlen wir die Verwendung von Snowpipe. |
Reihenfolge der Daten |
Geordnete Einfügungen innerhalb jedes Kanals |
Nicht unterstützt. Snowpipe kann Daten aus Dateien in einer Reihenfolge laden, die von den Zeitstempeln der Dateierstellung im Cloudspeicher abweicht. |
Ladeverlauf |
Ladeverlauf wird in Ansicht SNOWPIPE_STREAMING_FILE_MIGRATION_HISTORY (Account Usage) erfasst |
Aufgezeichneter Ladehverlauf in COPY_HISTORY (Account Usage) und COPY_HISTORY-Funktion (Information Schema) |
Pipeobjekt |
Das PIPE-Objekt ist die serverseitige Verarbeitungsschicht für alle Streaming-Datenaufnahmen. Es übernimmt die Validierung von Schemas, die Transformationen während der Übertragung und das Pre-Clustering. Für jede Tabelle wird automatisch eine Standard-Pipe erstellt, oder Sie können eine kundenspezifische Pipe für eine erweiterte Verarbeitung erstellen. |
Ein Pipe-Objekt stellt Stagingdateien in eine Warteschlange und lädt sie in Zieltabelle(n). |
Unter diesem Thema¶
Die wichtigsten Konzepte
Erste Schritte
Datenaufnahmeziele
Vorgänge
Referenz
Klassische Architektur¶
Wichtig
Die klassische Architektur, die die snowflake-ingest-sdk Java-SDK verwendet, wird eingestellt. Es sind keine sofortigen Änderungen erforderlich. Aktuelle Workloads werden weiterhin vollständig unterstützt.
Weitere Details dazu finden Sie unter:doc:Hinweis zu geplanten Einstellungen<snowpipe-streaming-classic-deprecation>.
Wenn Sie bereits Workloads haben, die auf der klassischen Architektur ausgeführt werden, finden Sie entsprechende Informationen unter Klassische Architektur. Einen ausführlichen Vergleich der Unterschiede finden Sie unter Vergleich zwischen leistungsstarken und klassischen SDKs.
Wenn Sie auf die High-Performance-Architektur umstellen, siehe Migrationsleitfaden.