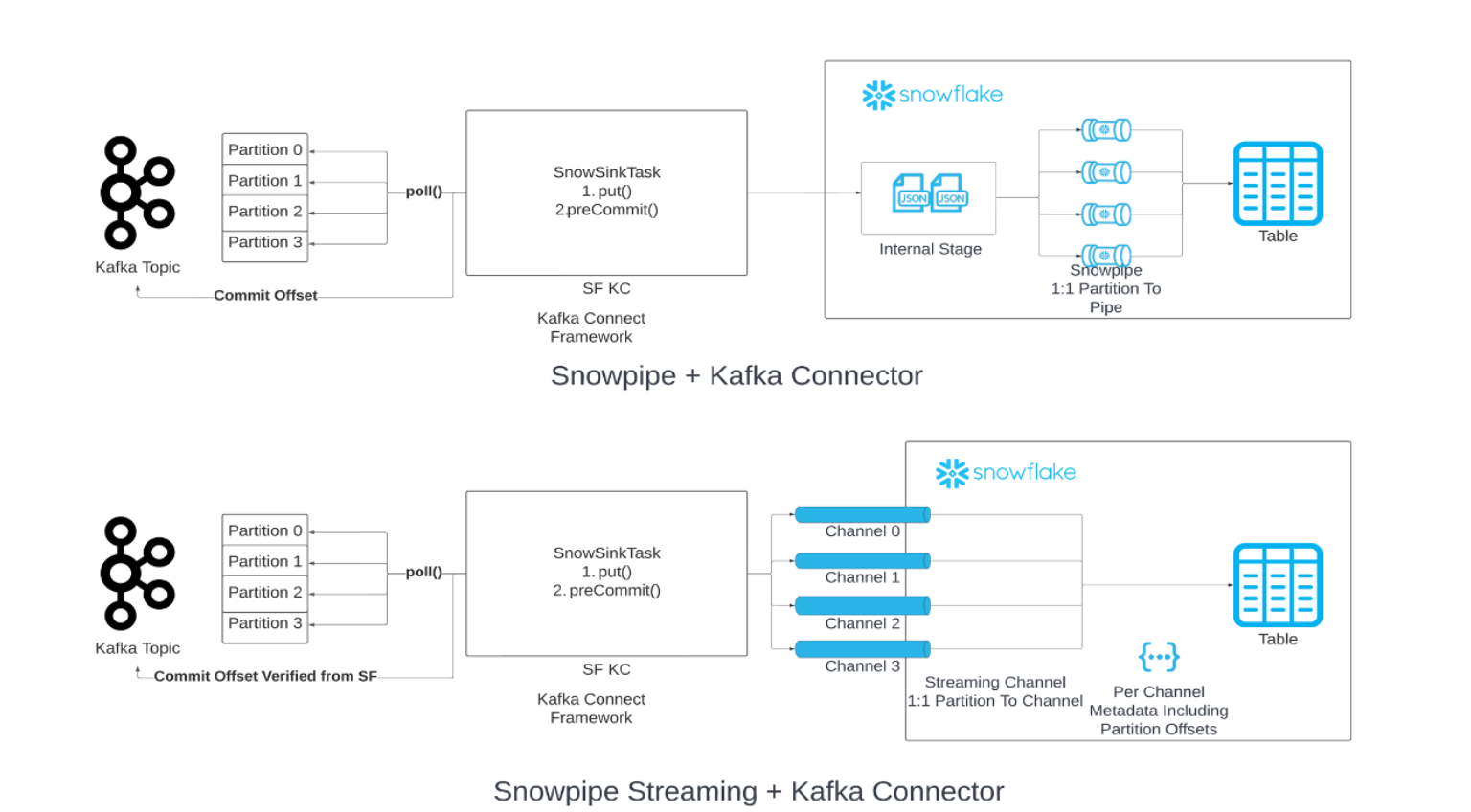
Snowflake Connector for Kafka with Snowpipe Streaming classic¶
Sie können in Ihrem Datenladevorgang aus Kafka Snowpipe durch Snowpipe Streaming ersetzen. Wenn der angegebene Schwellenwert für den Flush-Puffer (Zeit, Arbeitsspeicher oder Anzahl der Meldungen) erreicht ist, ruft der Konnektor die Snowpipe Streaming-API („API“) auf, um Datenzeilen in Snowflake-Tabellen zu schreiben. Diese Architektur führt zu geringeren Latenzen und damit zu geringeren Kosten für das Laden ähnlicher Datenmengen.
Die Version 2.0.0 (oder höher) des Kafka-Konnektors ist für die Verwendung mit Snowpipe Streaming Classic erforderlich. Der Kafka-Konnektor mit Snowpipe Streaming Classic enthält das Snowflake Ingest-SDK und unterstützt das Streaming von Zeilen aus Apache Kafka-Themen direkt in Zieltabellen.
Erforderliche Mindestversion¶
Die erforderliche Mindestversion des Kafka-Konnektors zur Unterstützung von Snowpipe Streaming ist 2.0.0.
Kafka-Konfigurationseigenschaften¶
Speichern Sie Ihre Verbindungseinstellungen in der Eigenschaftendatei des Kafka-Konnektors. Weitere Informationen dazu finden Sie unter Konfigurieren des Kafka-Konnektors.
Erforderliche Eigenschaften¶
Fügen Sie die Verbindungseinstellungen zur Eigenschaftendatei des Kafka-Konnektors hinzu oder bearbeiten Sie diese. Weitere Informationen dazu finden Sie unter Konfigurieren des Kafka-Konnektors.
snowflake.ingestion.methodNur erforderlich, wenn der Kafka-Konnektor als Streaming-Erfassungsclient verwendet wird. Gibt an, ob zum Laden Ihrer Kafka-Topic-Daten Snowpipe Streaming oder Standard-Snowpipe verwendet werden soll. Folgende Werte werden unterstützt:
SNOWPIPE_STREAMINGSNOWPIPE(Standard)
Es sind keine zusätzlichen Einstellungen erforderlich, um den Backend-Dienst für die Warteschlange und das Laden von Topic-Daten auszuwählen. Konfigurieren Sie weitere Eigenschaften in der Eigenschaftendatei Ihres Kafka-Konnektors wie gewohnt.
snowflake.role.nameZugriffssteuerungsrolle, die beim Einfügen der Zeilen in die Tabelle verwendet werden soll.
Eigenschaften der Clientoptimierung¶
enable.streaming.client.optimizationGibt an, ob die Einzelclientoptimierung aktiviert werden soll. Diese Eigenschaft wird vom Kafka-Konnektor, Version 2.1.2 und höher unterstützt. Sie ist standardmäßig aktiviert.
Bei der Einzelclientoptimierung wird pro Kafka-Konnektor nur ein Client für mehrere Themenpartitionen erstellt. Dieses Feature kann die Laufzeit des Clients verkürzen und die Migrationskosten senken, indem größere Dateien erstellt werden.
- Werte:
truefalse
- Standard:
true
Beachten Sie, dass die Aktivierung dieser Eigenschaft in einem Szenario mit hohem Durchsatz (z. B. 50 MB/s pro Konnektor) zu einer höheren Latenz oder höheren Kosten führen kann. Wir empfehlen, dass Sie diese Eigenschaft in Szenarios mit hohem Durchsatz deaktivieren.
Puffer- und Abrufeigenschaften¶
buffer.flush.timeAnzahl der Sekunden zwischen den Pufferentleerungen, wobei jede Leerung zu Einfügeoperationen für die gepufferten Datensätze führt. Der Kafka-Konnektor ruft die Snowpipe Streaming-API einmal nach jeder Leerung auf.
Der Mindestwert für die Eigenschaft
buffer.flush.timeist1(in Sekunden). Bei höheren durchschnittlichen Datenflussraten empfehlen wir, den Standardwert zu verringern, um die Latenz zu verbessern. Wenn die Kosten eine größere Rolle spielen als die Latenz, können Sie die Leerungszeit für den Puffer erhöhen. Achten Sie darauf, den Kafka-Speicherpuffer zu leeren, bevor er voll ist, um Ausnahmen wegen Mangel an Arbeitsspeicher zu vermeiden.- Werte:
Minimum:
1Maximum: Keine Obergrenze.
- Standard:
10
Beachten Sie, dass Snowpipe Streaming die Daten automatisch jede Sekunde flusht, was sich von der Pufferleerungszeit für den Kafka-Konnektor unterscheidet. Nach Erreichen der Kafka-Pufferleerungszeit werden die Daten mit einer Sekunde Latenz über Snowpipe Streaming an Snowflake gesendet. Weitere Informationen dazu finden Sie unter Snowpipe Streaming-Latenz.
buffer.count.recordsAnzahl der Datensätze, die je Kafka-Partition im Arbeitsspeicher zwischengespeichert werden, bevor sie in Snowflake erfasst werden.
- Werte:
Minimum:
1Maximum: Keine Obergrenze.
- Standard:
10000
buffer.size.bytesKumulative Größe der Datensätze in Byte, die pro Kafka-Partition im Arbeitsspeicher zwischengespeichert werden, bevor sie in Snowflake als Datendateien erfasst werden.
Die Datensätze werden beim Schreiben in die Datendateien komprimiert. Infolgedessen kann die Größe der Datensätze im Puffer größer sein als die Größe der aus den Datensätzen erstellten Datendateien.
- Werte:
Minimum:
1Maximum: Keine Obergrenze.
- Standard:
20000000(20 MB)
snowflake.streaming.max.client.lagLegt fest, wie oft Snowflake Ingest Java die Daten an Snowflake entleert, in Sekunden.
Ein niedriger Wert hält die Latenz niedrig, kann aber zu einer schlechteren Abfrageleistung führen, insbesondere wenn
snowflake.streaming.enable.single.bufferaktiviert ist. Weitere Informationen finden Sie in den empfohlenen Latenzkonfigurationen für Snowpipe Streaming.- Werte:
Minimum:
1SekundeMaximum:
600Sekunden
- Standard:
30Sekunden für Version 3.1.1 und später,120Sekunden für Version 3.0.0 und 3.1.0, sonst1Sekunde
snowflake.streaming.enable.single.bufferGibt an, ob der Einzelpuffer für Snowpipe Streaming aktiviert werden soll und ob die Zwischenspeicherung von Daten im internen Puffer des Konnektors übersprungen werden soll.
Diese Eigenschaft wird von Kafka Connector Version 2.3.1 und höher unterstützt.
Der Streaming-Konnektor verwendet neben dem internen Puffer auch den von Snowflake Ingest Java bereitgestellten Puffer. Wenn Sie diese Eigenschaft auf
trueeinstellen, überspringt der -Konnektor den internen Puffer, um die Latenzzeit zu verringern.Beachten Sie, dass durch das Festlegen dieser Eigenschaft auf
truebuffer.flush.timeundbuffer.count.recordsirrelevant werden.- Werte:
truefalse
- Standard:
truefür Version 3.0.0 und höher, ansonstenfalse
Zusätzlich zu den Eigenschaften des Kafka-Konnektors ist die Eigenschaft max.poll.records des Kafka-Verbrauchers zu beachten, die die maximale Anzahl der mit einem einzigen Abruf von Kafka an Kafka Connect zurückgegebenen Datensätze steuert. Der Standardwert von 500 kann erhöht werden, aber achten Sie auf mögliche Einschränkungen des Arbeitsspeichers. Weitere Informationen zu dieser Eigenschaft finden Sie in der Dokumentation zu Ihrem Kafka-Paket:
Fehlerbehandlung und DLQ-Eigenschaften¶
errors.toleranceGibt an, wie mit Fehlern des Kafka-Konnektors umgegangen werden soll:
Diese Eigenschaft unterstützt die folgenden Werte:
- Werte:
NONE: Stoppt das Laden von Daten, wenn der erste Fehler auftritt.ALL: Ignoriert alle Fehler und fährt mit dem Laden der Daten fort.
- Standard:
NONE
errors.log.enableGibt an, ob Fehlermeldungen in die Kafka Connect-Protokolldatei geschrieben werden sollen oder nicht.
Diese Eigenschaft unterstützt die folgenden Werte:
- Werte:
TRUE: Fehlermeldungen werden erfasst.FALSE: Fehlermeldungen werden nicht erfasst.
- Standard:
FALSE
errors.deadletterqueue.topic.nameGibt den DLQ-Topic-Namen (Dead-letter Queue, Warteschlange für nicht zustellbare Meldungen) in Kafka an, um Meldungen an Kafka zu liefern, die nicht in Snowflake-Tabellen erfasst werden konnten. Weitere Informationen dazu finden Sie unter DLQs – Warteschlangen für nicht zustellbare Meldungen (unter diesem Thema).
- Werte:
Kundenspezifische Textzeichenfolge
- Standard:
Keine
„Exactly-once“-Semantik¶
Die „Exactly-once“-Semantik stellt die Lieferung von Kafka-Meldungen ohne Duplizierung oder Datenverlust sicher. Diese Liefergarantie ist standardmäßig für den Kafka-Konnektor mit Snowpipe Streaming eingestellt.
Der Kafka-Konnektor nimmt eine 1:1-Zuordnung zwischen Partition und Kanal vor und verwendet zwei unterschiedliche Offsets:
Verbraucher-Offset: Hier wird der letzte vom Verbraucher verbrauchte Offset erfasst und von Kafka verwaltet.
Offset-Token: Damit wird der zuletzt in Snowflake festgestellte Offset erfasst und von Snowflake verwaltet.
Beachten Sie, dass der Kafka-Konnektor nicht immer mit fehlenden Offsets umgehen kann. Snowflake erwartet, dass alle Datensätze sequenziell aufsteigende Offsets haben. Die fehlenden Offsets machen den Kafka-Konnektor in bestimmten Anwendungsfällen funktionsunfähig. Es wird empfohlen, dass Sie anstelle von NULL-Datensätzen Tombstone-Datensätze verwenden.
Der Kafka-Konnektor erreicht eine genau einmalige Zustellung, wenn die folgenden bewährten Verfahren implementiert werden:
Öffnen/Wiederöffnen eines Kanals:
Beim Öffnen oder Wiederöffnen eines Kanals für eine bestimmte Partition verwendet der Kafka-Konnektor das letzte von Snowflake über die
getLatestCommittedOffsetToken-API abgerufene Offset-Token als Quelle der Wahrheit und setzt den Verbraucher-Offset in Kafka entsprechend zurück.Wenn der Offset des Verbrauchers nicht mehr innerhalb der Datenaufbewahrungsfrist liegt, wird eine Ausnahme ausgelöst, und Sie können entscheiden, welche Maßnahmen Sie ergreifen möchten.
Das einzige Szenario, in dem der Kafka-Konnektor den Verbraucher-Offset in Kafka nicht zurücksetzt und ihn als Quelle der Wahrheit verwendet, ist, wenn das Offset-Token von Snowflake den Wert NULL hat. In diesem Fall akzeptiert der Konnektor den von Kafka gesendeten Offset, und das Offset-Token wird anschließend aktualisiert.
Verarbeiten von Datensätzen:
Um eine zusätzliche Sicherheitsebene gegen nicht kontinuierliche Offsets sicherzustellen, die durch potenzielle Fehler in Kafka entstehen könnten, verwaltet Snowflake eine speicherinterne Variable, die den zuletzt verarbeiteten Offset erfasst. Snowflake akzeptiert Zeilen nur dann, wenn der Offset der aktuellen Zeile gleich dem zuletzt verarbeiteten Offset plus eins ist, wodurch eine zusätzliche Schutzschicht hinzugefügt wird, die sicherstellt, dass der Erfassungsprozess kontinuierlich und genau ist.
Verarbeiten von Ausnahmen, Fehlern, Wiederherstellung bei Abstürzen:
Als Teil des Wiederherstellungsprozesses hält sich Snowflake konsequent an die zuvor beschriebene Logik zum Öffnen und Wiederöffnen des Kanals, indem es den Kanal erneut öffnet und den Offset des Verbrauchers mit dem letzten bestätigten Offset-Token zurücksetzt. Auf diese Weise signalisiert Snowflake Kafka, die Daten ab dem Offset-Wert zu senden, der um eins größer ist als der zuletzt übertragene Offset-Token, sodass die Erfassung ab dem Ausfallpunkt ohne Datenverluste wieder aufgenommen werden kann.
Implementieren eines Wiederholungsmechanismus:
Um möglichen transienten Problemen Rechnung zu tragen, hat Snowflake einen Wiederholungsmechanismus in die API-Aufrufe integriert. Snowflake wiederholt die API-Aufrufe mehrmals, um die Erfolgschancen zu erhöhen und das Risiko zu verringern, dass der Erfassungsprozess durch zeitweilige Fehler beeinträchtigt wird.
Aktualisieren des Verbraucher-Offsets:
In regelmäßigen Abständen aktualisiert Snowflake den Verbraucher-Offset unter Verwendung des neuesten bestätigten Offset-Tokens, um sicherzustellen, dass der Erfassungsprozess kontinuierlich mit dem neuesten Status der Daten in Snowflake abgeglichen wird.
Konverter¶
Snowpipe Streaming unterstützt viele Community-basierte Konverter wie die folgenden:
io.confluent.connect.avro.AvroConverterorg.apache.kafka.connect.json.JsonConverterio.confluent.connect.protobuf.ProtobufConverterio.confluent.connect.json.JsonSchemaConverterorg.apache.kafka.connect.converters.ByteArrayConverterorg.apache.kafka.connect.storage.StringConverter
Andere Community-basierte Konverter können möglicherweise unterstützt werden, wurden aber nicht validiert. Snowflake-Konverter werden von Snowpipe Streaming nicht unterstützt.
DLQs – Warteschlangen für nicht zustellbare Meldungen¶
Der Kafka-Konnektor mit Snowpipe Streaming unterstützt Warteschlangen für nicht zustellbare Meldungen (DLQ, Dead-letter Queue) für defekte Datensätze oder Datensätze, die aufgrund eines Fehlers nicht erfolgreich verarbeitet werden können.
Weitere Informationen zur Überwachung finden Sie in der Dokumentation zu Apache Kafka.
Schemaerkennung und Schemaentwicklung¶
Der Kafka-Konnektor mit Snowpipe Streaming unterstützt Schemaerkennung und Schemaentwicklung. Die Struktur von Tabellen in Snowflake kann automatisch definiert und weiterentwickelt werden, um die Struktur neuer Snowpipe Streaming-Daten zu unterstützen, die vom Kafka-Konnektor geladen werden. Um Schemaerkennung und Schemaentwicklung für den Kafka-Konnektor mit Snowpipe Streaming zu aktivieren, konfigurieren Sie die folgenden Kafka-Eigenschaften:
snowflake.ingestion.methodsnowflake.enable.schematizationschema.registry.url
Weitere Informationen dazu finden Sie unter Schema detection and evolution for Kafka connector with Snowpipe Streaming classic.
Abschätzen der Datenaufnahme-Latenz¶
Um die Datenaufnahmelatenz abzuschätzen, verwenden Sie das Feld SnowflakeConnectorPushTime in RECORD_METADATA. Dieser Zeitstempel stellt den Zeitpunkt dar, zu dem ein Datensatz in einen Ingest-SDK-Puffer verschoben wurde.
Weitere Informationen zum RECORD_METADATA-Format finden Sie unter Schema von Tabellen für Kafka-Themen.
Bemerkung
Dieses Feld stellt nicht dar, wann ein Datensatz in einer Snowflake-Tabelle sichtbar wurde, da es Ihre konfigurierte Snowpipe Streaming-Latenz nicht berücksichtigt.
Abrechnung und Verbrauch¶
Informationen zur Abrechnung von Snowpipe Streaming finden Sie unter Kosten für Snowpipe Streaming Classic.
Einschränkungen¶
Einschränkungen für Snowpipe Streaming¶
Failover-Einschränkungen¶
Wenn eine sekundäre Failover-Gruppe zur primären Gruppe heraufgestuft wird, erfordert der Kafka-Konnektor mit Snowpipe Streaming eine manuelle Interaktion. Die „Exactly-once“-Semantik bleibt erhalten.
Wenn die Eigenschaft enable.streaming.client.optimization auf false festgelegt ist, sollte der Kafka-Konnektor neu gestartet werden. Nachdem Sie den Konnektor neu gestartet haben, zielt er auf eine neue primäre Bereitstellung ab.
Wenn die Eigenschaft enable.streaming.client.optimization auf true festgelegt ist, sollte der JVM-Host, auf dem der Konnektor läuft, heruntergefahren und neu gestartet werden. Nachdem Sie den JVM-Host neu gestartet haben, zielt ein neu gestarteter Kafka-Konnektor auf eine neue primäre Bereitstellung ab.