Sichere Freigabe von Daten über Regionen und Cloud-Plattformen hinweg¶
Unter diesem Thema finden Sie eine Anleitung für die Verwendung der Replikation, mit der Datenanbieter Daten sicher für Datenverbraucher in verschiedenen Regionen und auf verschiedenen Cloudplattformen freigeben können.
Bemerkung
Wenn Sie Freigabeangebote verwenden, um Daten für bestimmte Verbraucherkonten freizugeben, oder wenn Sie die Snowflake Marketplace nutzen, können Sie Cloud-übergreifende automatische Ausführung verwenden, um Ihr Produkt automatisch in andere Regionen zu liefern.
Das regionsübergreifende Data Sharing wird bei Snowflake-Konten unterstützt, die auf einer der folgenden Cloudplattformen gehostet werden:
Amazon Web Services (AWS)
Google Cloud Platform (GCP)
Microsoft Azure (Azure)
Wichtig
Wenn Sie eine Primärdatenbank in Konten in einer geografische Region oder in einem Land replizieren, die/das sich von der Region/dem Land unterscheidet, in der/dem sich Ihr Snowflake-Quellkonto befindet, müssen Sie sicherstellen, dass Ihre Organisation keinen rechtlichen oder behördlichen Einschränkungen hinsichtlich des Speicherorts Ihrer Daten unterliegt.
Hinweise zum Data Sharing¶
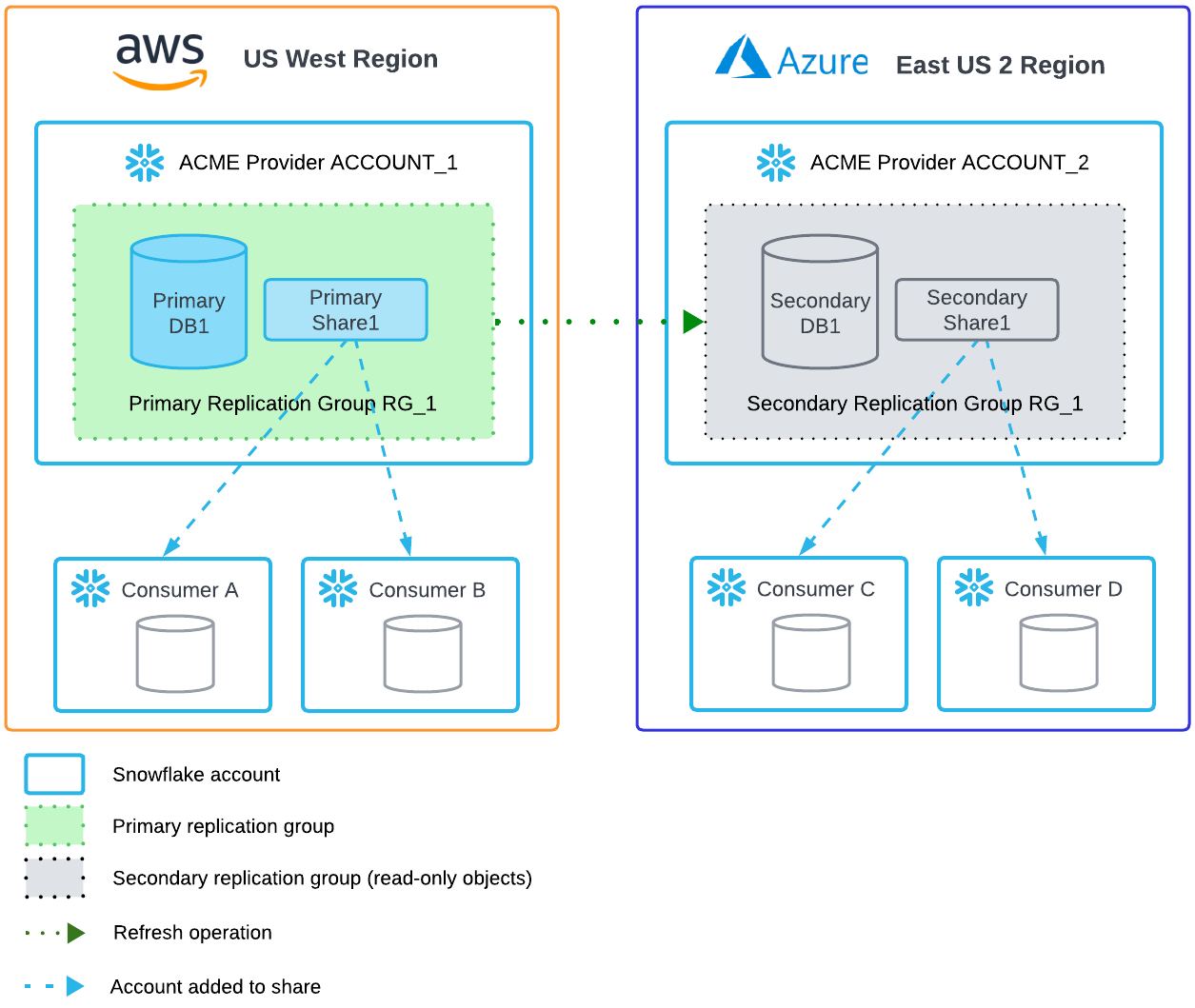
Da das regionsübergreifende Data Sharing die Snowflake-Datenreplikationsfunktion verwendet, müssen Sie verstehen, wie die Replikation in Snowflake als Teil Ihres Planungsprozesses funktioniert. Weitere Informationen dazu finden Sie unter:
Datenanbieter müssen nur eine Kopie des Datensatzes pro Region erstellen und keine Kopie pro Verbraucher.
Wenn Sie eine Ansicht freigeben, die auf Objekte in mehreren Datenbanken verweist, muss jede dieser anderen Datenbanken in der Replikationsgruppe enthalten sein. Das Freigeben von Daten aus mehr als einer Datenbank erfordert zusätzliche Schritte. Eine Anleitung dazu finden Sie unter Freigabe von Daten aus mehreren Datenbanken.
Informationen über die Verwendung von Virtual Private Snowflake (VPS) mit Datenfreigabe finden Sie unter Über die Zusammenarbeit in VPS-Umgebungen.
Beispiel 1: Daten freigeben¶
Ein Datenanbieter, Acme, möchte Daten mit Datenverbrauchern in einer anderen Region teilen.
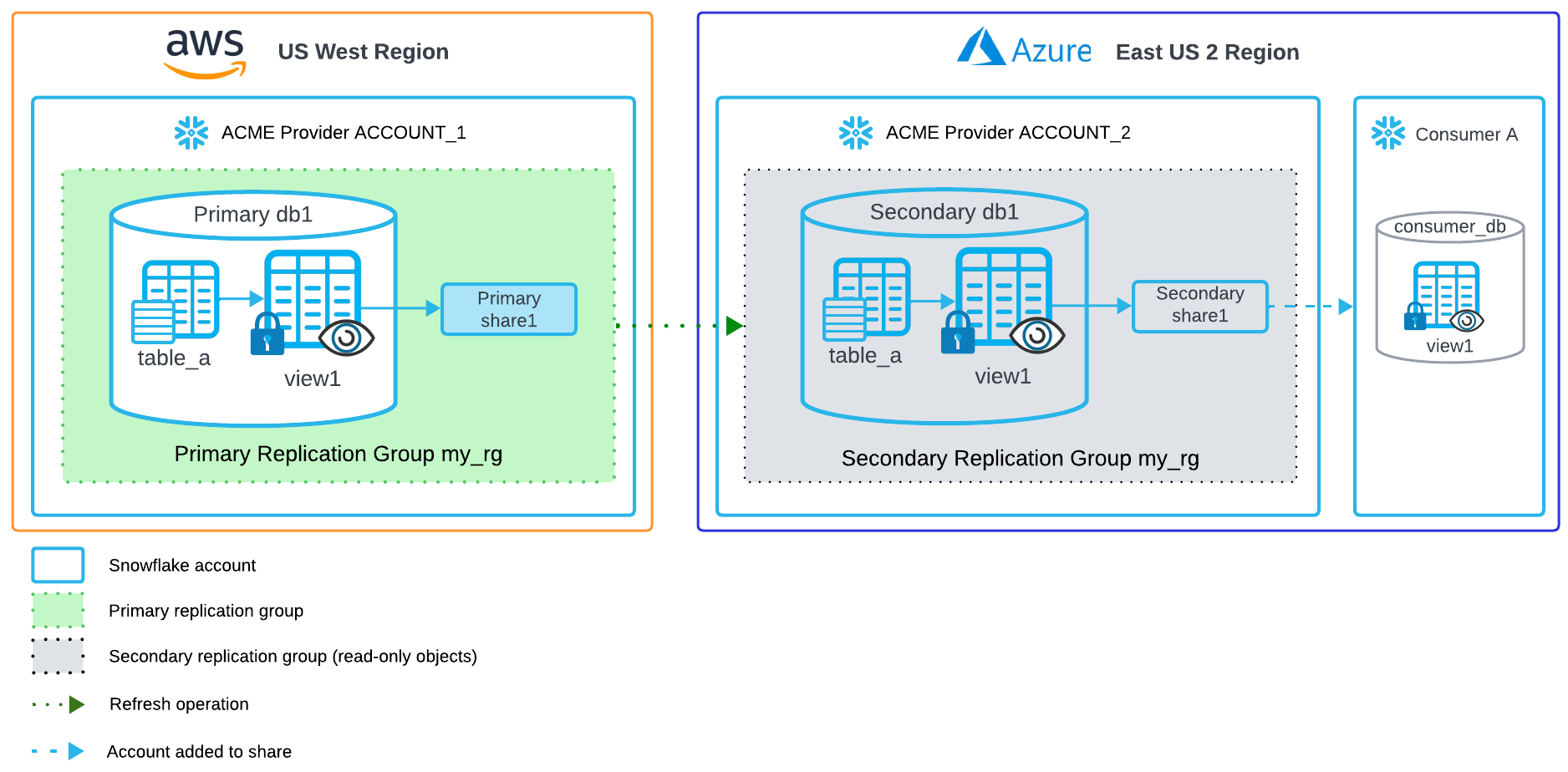
Von Quellkonto ausführen¶
Um eine Replikationsgruppe zu erstellen, die die Datenbanken und Freigaben für die Replikation in eine andere Region enthält, führen Sie die folgende SQL-Anweisung aus.
Bemerkung
Wenn Sie zuvor die Replikation für eine einzelne Datenbank aktiviert haben, müssen Sie die Datenbankreplikation für diese Datenbank deaktivieren, bevor Sie sie zu einer Replikationsgruppe hinzufügen. Weitere Details dazu finden Sie unter Umstellen von Datenbankreplikation auf gruppenbasierte Replikation.
Erstellen Sie eine Replikationsgruppe my_rg, die die Datenbank db1 und die Freigabe share1 für die Replikation in das Konto account_2 der Organisation acme enthält.
Von Zielkonto ausführen¶
Führen Sie die folgenden SQL-Anweisungen vom Zielkonto in der anderen Region aus. Jedes Konto, das Sie der Freigabe hinzufügen, sollte in der Region des Zielkontos liegen. Nachdem Sie die Freigabe geändert haben, um eine Liste der Konten (Ziele) festzulegen, werden Ihre hinzugefügten Konten bei der nächsten Aktualisierung nicht mehr überschrieben.
Erstellen Sie dann in
account_2eine sekundäre Replikationsgruppe:Aktualisieren Sie die Replikationsgruppe manuell, um die Datenbanken und Freigaben zu
account_2zu replizieren:Fügen Sie ein oder mehrere Verbraucherkonten zu
share1hinzu:
Sie können Aktualisierungsvorgänge automatisieren, indem Sie den Parameter REPLICATION_SCHEDULE für die primäre Replikationsgruppe mit dem Befehl ALTER REPLICATION GROUP im Quellkonto festlegen. Weitere Informationen dazu finden Sie unter Replikationsplan.
Beispiel 2: Teilmenge von Daten aus einer Datenbank freigeben¶
Ein Datenanbieter, Acme, möchte eine Teilmenge von Daten mit Datenverbrauchern in einer anderen Region teilen. Um die Replikationskosten zu senken, sollen nur die relevanten Zeilen aus der Mastertabelle repliziert werden. Da die Replikation auf Datenbankebene erfolgt, wird in diesem Beispiel beschrieben, wie Acme mithilfe von Streams und Aufgaben die gewünschten Zeilen aus der Hauptdatenbank in eine neue Datenbank kopiert, für die Ansicht eine Freigabe erstellt und Berechtigungen erteilt und dann beides in einer Replikationsgruppe in ein Konto in einer anderen Region für den Verbraucherzugriff repliziert. In diesem Szenario werden die neue Datenbank und die Freigabe als primäre Objekte für die Datenreplikation bezeichnet.
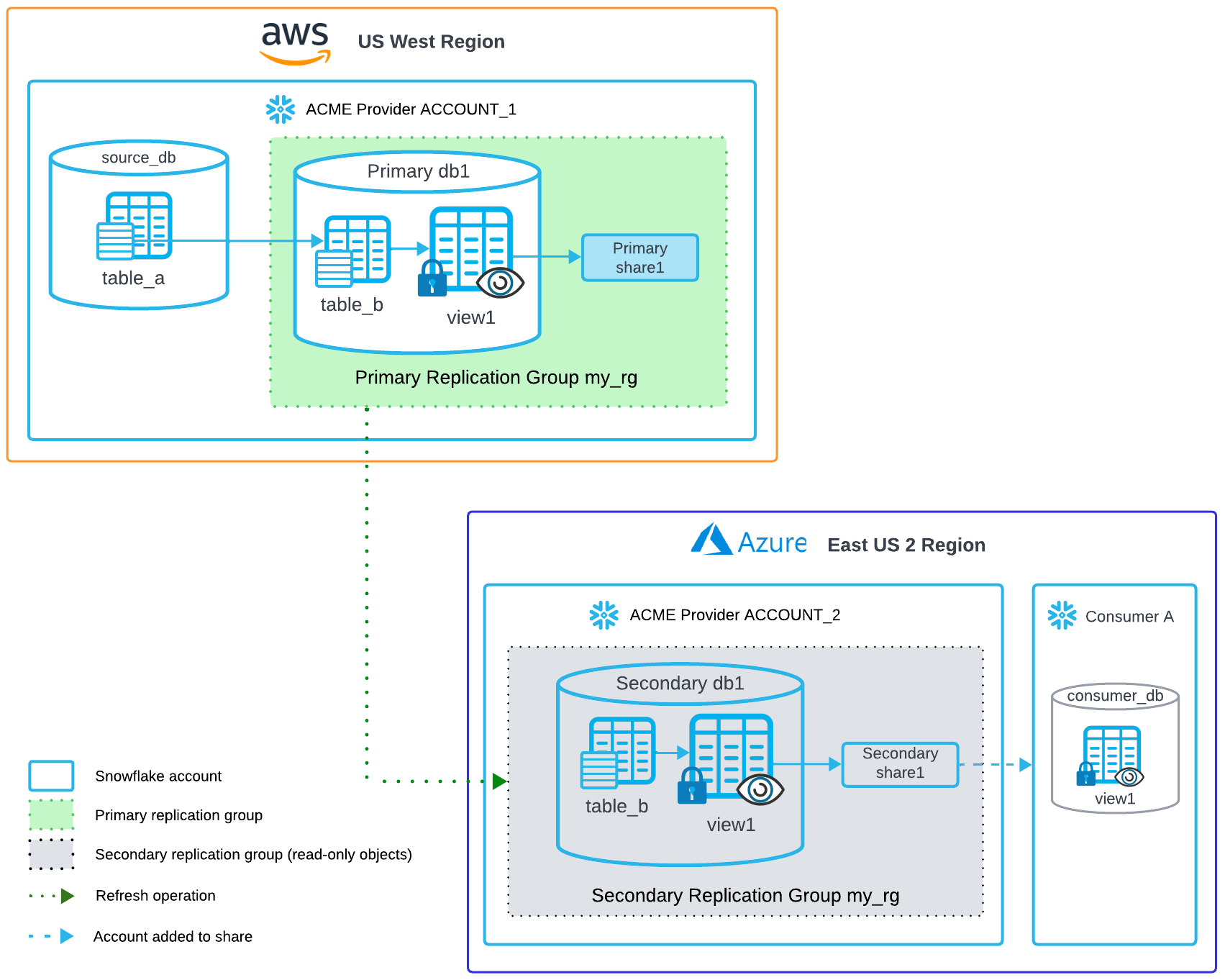
Von Quellkonto ausführen¶
Verwenden Sie die folgenden SQL-Befehle, um eine neue Datenbank im Quellkonto zu erstellen und die Replikation zu aktivieren.
Bemerkung
Wenn Sie zuvor die Replikation für eine einzelne Datenbank aktiviert haben, müssen Sie die Datenbankreplikation für diese Datenbank deaktivieren, bevor Sie sie zu einer Replikationsgruppe hinzufügen. Weitere Details dazu finden Sie unter Umstellen von Datenbankreplikation auf gruppenbasierte Replikation.
Erstellen Sie in Ihrem lokalen Konto eine Datenbank
db1mit einer Teilmenge von Daten aus der Datenbank mit den Quelldaten:Erstellen Sie eine sichere Ansicht mit den freizugebenden Daten:
Erstellen Sie einen Stream, um Änderungen an der Quelltabelle zu erfassen:
Erstellen Sie eine Aufgabe zum Einfügen von Daten in die Tabelle in
db1mit Änderungen aus den Quelldaten:Starten Sie die Aufgabe zum Aktualisieren der Daten:
Erstellen Sie eine Freigabe, und erteilen Sie der Freigabe die erforderlichen Berechtigungen:
Erstellen Sie eine primäre Replikationsgruppe mit der Datenbank und der Freigabe:
Von Zielkonto ausführen¶
Führen Sie die folgenden SQL-Befehle vom Zielkonto in der anderen Region aus.
Erstellen Sie eine sekundäre Replikationsgruppe, um die Datenbanken und Freigaben des Quellkontos zu replizieren:
Aktualisieren Sie die Gruppe manuell, um Objekte in das aktuelle Konto zu replizieren:
Fügen Sie mit ein oder mehrere Verbraucherkonten zur Freigabe hinzu:
Sie können Aktualisierungsvorgänge automatisieren, indem Sie den Parameter REPLICATION_SCHEDULE für die primäre Replikationsgruppe mit dem Befehl ALTER REPLICATION GROUP im Quellkonto festlegen. Weitere Informationen dazu finden Sie unter Replikationsplan.