Replizieren von Datenbanken und Kontoobjekten über mehrere Konten hinweg¶
Unter diesem Thema werden die Schritte beschrieben, die zum Replizieren von Kontoobjekten und Daten über mehrere Snowflake-Konten derselben Organisation hinweg und zum Synchronisieren der Objekte und Daten erforderlich sind. Die Kontoreplikation kann über Snowflake-Konten in verschiedenen Regionen und auf verschiedenen Cloudplattformen hinweg erfolgen.
Bemerkung
Wenn Sie ein Konto auf die Business Critical Edition (oder höher) aktualisieren, kann es bis zu 12 Stunden dauern, bis die Failover-Funktionen zur Verfügung stehen.
Unterstützung von Replikation und Failover/Failback in den Regionen¶
Kunden können die Replikation über alle Region innerhalb einer Regionsgruppe hinweg ausführen. Wenn Sie die Replikation zwischen Regionen in verschiedenen Regionsgruppen ausführen möchten (z. B. von einer kommerziellen Snowflake-Region zu einer Snowflake-Region für Regierungsbehörden), wenden Sie sich an den Snowflake-Support, um den Zugriff zu aktivieren.
Umstellen von Datenbankreplikation auf gruppenbasierte Replikation¶
Bei Datenbanken, bei denen die Replikation mit ALTER DATABASE aktiviert worden war, muss die Replikation erst wieder deaktiviert werden, bevor die Datenbanken zu einer Replikations- oder Failover-Gruppe hinzugefügt werden können.
Bemerkung
Führen Sie die SQL-Anweisungen in diesem Abschnitt mit der Rolle ACCOUNTADMIN aus.
Schritt 1: Replikation bei einer replikationsfähigen Datenbank deaktivieren¶
Führen Sie die Funktion SYSTEM$DISABLE_DATABASE_REPLICATION aus, um die Replikation bei einer Primärdatenbank und bei allen mit ihr verknüpften Sekundärdatenbanken zu deaktivieren, um sie zu einer Replikations- oder Failover-Gruppe hinzufügen zu können.
Führen Sie die folgende SQL-Anweisung von dem Quellkonto aus, das die Primärdatenbank enthält:
Schritt 2: Datenbank zu primärer Failover-Gruppe hinzufügen und sekundäre Failover-Gruppe erstellen¶
Nachdem Sie die Replikation für eine Datenbank erfolgreich deaktiviert haben, können Sie die Primärdatenbank nun zu einer Failover-Gruppe im Quellkonto hinzufügen.
Erstellen Sie dann eine sekundäre Failover-Gruppe im Zielkonto. Wenn die sekundäre Failover-Gruppe im Zielkonto aktualisiert wird, werden alle bisherigen Sekundärdatenbanken automatisch als Mitglieder der sekundären Failover-Gruppe hinzugefügt und mit den Änderungen der Primärdatenbank aktualisiert.
Weitere Informationen zum Erstellen von primären und sekundären Failover-Gruppen finden Sie unter Workflow.
Bemerkung
Wenn Sie eine zuvor replizierte Datenbank zu einer Failover-Gruppe hinzufügen, führt Snowflake keine erneute Replikation der Daten durch, die bereits für diese Datenbank repliziert wurden. Beim Aktualisieren der Gruppe werden nur die Änderungen seit der letzten Aktualisierung repliziert.
Workflow¶
Die folgenden SQL-Anweisungen demonstrieren den Ablauf für das Aktivieren der Replikation von Konto- und Datenbankobjekten und das Aktualisieren der Objekte. Jeder Schritt wird im Folgenden ausführlich erläutert.
Bemerkung
Für die folgenden Beispiele muss die Replikation für das Quell- und das Zielkonto aktiviert sein. Weitere Details dazu finden Sie unter Voraussetzung: Aktivieren Sie die Replikation für Konten der Organisation.
Beispiele¶
Führen Sie die folgenden SQL-Anweisungen in Ihrem bevorzugten Snowflake-Client aus, um Replikation und Failover der Konto- und Datenbankobjekte zu aktivieren und die Objekte zu aktualisieren.
Von Quellkonto ausführen¶
Erstellen Sie eine Rolle, und erteilen Sie dieser Rolle die Berechtigung CREATE FAILOVER GROUP. Der folgende Schritt ist optional:
Erstellen Sie eine Failover-Gruppe im Quellkonto, und aktivieren Sie die Replikation in bestimmte Zielkonten:
Bemerkung
Wenn Sie einer Replikations- oder Failover-Gruppe Datenbanken hinzufügen möchten, bei denen Datenbankreplikation und Failover zuvor mit ALTER DATABASE aktiviert worden war, befolgen Sie vor dem Hinzufügen der Datenbanken zu einer Gruppe die Anleitung unter Umstellen von Datenbankreplikation auf gruppenbasierte Replikation (unter diesem Thema).
Um eine Datenbank zu einer Failover-Gruppe hinzuzufügen, muss die aktive Rolle über die MONITOR-Berechtigung für die Datenbank verfügen. Weitere Informationen zu Berechtigungen für Datenbanken finden Sie unter Berechtigungen von Datenbanken (untere einem anderen Thema).
Von Zielkonto ausführen¶
Erstellen Sie eine Rolle im Zielkonto, und erteilen Sie dieser Rolle die Berechtigung CREATE FAILOVER GROUP. Der folgende Schritt ist optional:
Erstellen Sie eine Failover-Gruppe im Zielkonto als Replikat der Failover-Gruppe im Quellkonto:
Bemerkung
Wenn im Zielkonto Kontoobjekte (z. B. Benutzer oder Rollen) vorhanden sind, die es im Quellkonto nicht gibt, lesen Sie bitte Erstmalige Replikation von Benutzern und Rollen, bevor Sie eine sekundäre Gruppe erstellen.
Aktualisieren Sie die sekundäre Failover-Gruppe manuell. Dies ist ein optionaler Schritt. Wenn die primäre Failover-Gruppe mit einem Replikationsplan erstellt wird, wird beim Erstellen der sekundären Failover-Gruppe eine erste Aktualisierung der sekundären Failover-Gruppe automatisch ausgeführt.
Erstellen Sie eine Rolle mit REPLICATE-Berechtigung für die Failover-Gruppe. Dieser Schritt ist optional.
Führen Sie im Zielkonto unter Verwendung einer Rolle mit der Berechtigung OWNERSHIP für die Failover-Gruppe Folgendes aus:
Führen Sie die Aktualisierungsanweisung unter Verwendung einer Rolle mit der Berechtigung REPLICATE aus:
Erstellen Sie eine Rolle mit FAILOVER-Berechtigung für die Failover-Gruppe. Dieser Schritt ist optional.
Führen Sie im Zielkonto unter Verwendung einer Rolle mit der Berechtigung OWNERSHIP für die Failover-Gruppe Folgendes aus:
Replizieren von Kontoobjekten und Datenbanken¶
In den Anweisungen in diesem Abschnitt wird erläutert, wie Sie Ihre Konten für die Replikation vorbereiten, die Replikation bestimmter Objekte vom Quellkonto in das Zielkonto aktivieren und die Objekte im Zielkonto synchronisieren.
Wichtig
Bei Zielkonten ist standardmäßig weder Tri-Secret Secure noch private Konnektivität zum Snowflake-Dienst, z. B. zu AWS PrivateLink, aktiviert. Wenn Sie Tri-Secret Secure oder private Konnektivität zum Snowflake-Dienst aus Compliance-, Sicherheits- oder anderen Gründen benötigen, liegt es in Ihrer Verantwortung, diese Features im Zielkonto zu konfigurieren und zu aktivieren.
Voraussetzung: Aktivieren Sie die Replikation für Konten der Organisation¶
Der Administrator der Organisation muss die Replikation für die Quell- und Zielkonten aktivieren.
Um die Replikation für Konten zu aktivieren, verwendet ein Organisationsadministrator die Funktion SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER und setzt den Parameter ENABLE_ACCOUNT_DATABASE_REPLICATION auf true.
Als Organisationsadministrator aktivieren Sie die Replikation für jedes Quell- und Zielkonto in Ihrer Organisation.
Obwohl die Funktion SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER den alten Konto-Locator als Bezeichner unterstützt, kann dies zu unerwarteten Ergebnissen führen, wenn eine Organisation mehrere Konten mit demselben Konto-Locator (in verschiedenen Regionen) verwendet.
Schritt 1: Rolle mit CREATE FAILOVER GROUP-Berechtigung im Quellkonto erstellen – Optional¶
Erstellen Sie eine Rolle, und erteilen Sie dieser Rolle die Berechtigung CREATE FAILOVER GROUP. Dieser Schritt ist optional. Wenn Sie diese Rolle bereits erstellt haben, fahren Sie mit Schritt 3: Eine primäre Failover-Gruppe in einem Quellkonto erstellen fort.
Schritt 2: Konten, die für die Replikation aktiviert sind, und Gruppenmitgliedschaft identifizieren¶
Bevor Sie eine primäre Failover-Gruppe erstellen, identifizieren Sie die für die Replikation aktivierten Konten und die bestehenden Failover- und Replikationsgruppen.
Alle für Replikation aktivierten Konten anzeigen¶
Um die Liste der Konten in Ihrer Organisation abzurufen, die für die Replikation aktiviert sind, verwenden Sie SHOW REPLICATION ACCOUNTS.
Führen Sie die folgende SQL-Anweisung mit der Rolle ACCOUNTADMIN aus:
Rückgabewerte:
Verwenden Sie auch die vollständige Liste der Regions-IDs.
Mitgliedschaft von Failover- und Replikationsgruppen anzeigen¶
Für Konto-, Datenbank- und Freigabeobjekte gibt es Einschränkungen hinsichtlich der Gruppenmitgliedschaft. Bevor Sie neue Gruppen erstellen oder Objekte zu bestehenden Gruppen hinzufügen, können Sie die Liste der bestehenden Failover-Gruppe und der Objekte in jeder Gruppe überprüfen.
Bemerkung
Nur ein Kontoadministrator (Benutzer mit der Rolle ACCOUNTADMIN) oder der Gruppeneigentümer (Rolle mit OWNERSHIP-Berechtigung für die Gruppe) kann die SQL-Anweisungen in diesem Abschnitt ausführen.
Anzeigen aller Failover-Gruppen, die mit dem aktuellen Konto verknüpft sind, sowie die Objekttypen in jeder Gruppe:
Anzeigen aller Datenbanken in der Failover-Gruppe myfg:
Anzeigen aller Freigaben in der Failover-Gruppe myfg:
Schritt 3: Eine primäre Failover-Gruppe in einem Quellkonto erstellen¶
Erstellen Sie eine primäre Failover-Gruppe, und aktivieren Sie die Replikation und das Failover der angegebenen Objekte vom aktuellen (Quell-)Konto in ein oder mehrere Zielkonten derselben Organisation.
Sie können eine Replikations- oder Failover-Gruppe mit Snowsight oder SQL erstellen.
Bemerkung
Wenn Sie einer Replikations- oder Failover-Gruppe Datenbanken hinzufügen möchten, bei denen die Datenbankreplikation zuvor mit ALTER DATABASE aktiviert worden war, befolgen Sie vor dem Hinzufügen der Datenbanken zu einer Gruppe die Anleitung unter Umstellen von Datenbankreplikation auf gruppenbasierte Replikation (unter diesem Thema).
Replikations- oder Failover-Gruppe mit Snowsight erstellen¶
Bemerkung
Nur Kontoadministratoren können mit Snowsight eine Replikations- oder Failover-Gruppe erstellen (siehe Einschränkungen bei der Verwendung von Snowsight für die Replikationskonfiguration).
Sie müssen beim Zielkonto als Benutzer mit der Rolle ACCOUNTADMIN angemeldet sein. Wenn Sie dies nicht sind, werden Sie aufgefordert, sich anzumelden.
Sowohl das Quellkonto als auch das Zielkonto müssen denselben Verbindungstyp (öffentliches Internet) verwenden. Andernfalls schlägt die Anmeldung bei dem Zielkonto fehl.
Führen Sie die folgenden Schritte aus, um eine neue Replikations- oder Failover-Gruppe zu erstellen:
Melden Sie sich bei Snowsight an.
Wählen Sie im Navigationsmenü die Option Admin » Accounts aus.
Wählen Sie Replication und führen Sie dann eine der folgenden Aktionen auf der Registerkarte Groups aus:
Für Konten der Business Critical Edition (oder höher) führen Sie eine der folgenden Aktionen durch:
Wenn es keine Replikationsgruppen oder Verbindungen gibt, wählen Sie Get started, um eine Replikationsgruppe und eine Verbindung zu konfigurieren. Der Assistent Setup business continuity wird angezeigt.
Wählen Sie + Group, um eine Replikationsgruppe zu konfigurieren, ohne eine Verbindung einzurichten. Der Assistent Create a group wird angezeigt.
Für Konten der Standard Edition und der Enterprise Edition führen Sie eine der folgenden Aktionen durch:
Wenn es keine Replikationsgruppen oder Verbindungen gibt, wählen Sie Get started, um eine Replikationsgruppe zu konfigurieren. Der Assistent Setup replication wird angezeigt.
Wenn eine oder mehrere Replikationsgruppen existieren, wählen Sie + Group, um eine Replikationsgruppe zu konfigurieren. Der Assistent Create a group wird angezeigt.
Wählen Sie auf der Seite Select a target account ein Zielkonto aus und melden Sie sich dort an. Wählen Sie dann Next.
Geben Sie auf der Seite Create a group im Feld Group name einen Namen für die Gruppe ein, der die folgenden Anforderungen erfüllt:
Muss mit einem Buchstaben beginnen und darf keine Leer- oder Sonderzeichen enthalten, es sei denn, der Bezeichner ist in doppelte Anführungszeichen eingeschlossen (z. B. „Mein Objekt“). Bei Bezeichnern, die in doppelte Anführungszeichen eingeschlossen sind, ist auch die Groß-/Kleinschreibung zu beachten.
Weitere Informationen dazu finden Sie unter Anforderungen an Bezeichner.
Der Bezeichner muss für alle Failover- und Replikationsgruppen in einem Konto eindeutig sein.
Wählen Sie Edit objects aus, um Freigabe- und Kontoobjekte zu Ihrer Gruppe hinzuzufügen.
Bemerkung
Kontoobjekte können nur zu einer einzigen Replikations- oder Failover-Gruppe hinzugefügt werden. Wenn in Ihrem Konto bereits eine Replikations- oder Failover-Gruppe mit Kontoobjekten vorhanden ist, können Sie diese Objekte nicht auswählen.
Wählen Sie Select databases aus, um Datenbankobjekte zu Ihrer Gruppe hinzuzufügen.
Wählen Sie die Replication frequency aus.
Wenn es sich bei dem Konto um die Business Critical Edition oder höher handelt, wird eine Failover-Gruppe standardmäßig erstellt. Sie können aber auch entscheiden, eine Replikationsgruppe zu erstellen. Um eine Replikationsgruppe zu erstellen, wählen Sie Advanced options aus und deaktivieren dann die Option Enable failover.
Führen Sie eine der folgenden Aktionen durch:
Für Konten der Business Critical Edition (oder höher) wählen Sie Next.
Für Konten der Standard Edition und Enterprise Edition wählen Sie Start replication, um die Replikationsgruppe zu erstellen.
Für Konten der Business Critical Edition (oder höher) geben Sie auf der Seite Create connection einen Verbindungsnamen in das Feld Connection name ein und wählen dann Start replication.
Wenn das Erstellen der Replikationsgruppe nicht erfolgreich war, finden Sie unter Probleme beim Erstellen und Bearbeiten von Replikationsgruppen in Snowsight beheben Informationen zu häufigen Fehlern und deren Behebung.
Failover-Gruppe mit SQL erstellen¶
Erstellen Sie eine Failover-Gruppe mit den angegebenen Konto- und Datenbankobjekten im Quellkonto, und aktivieren Sie Replikation und Failover für eine Liste von Zielkonten. Weitere Informationen zur Syntax finden Sie unter CREATE FAILOVER GROUP.
Aktivieren Sie beispielsweise die Replikation von Benutzern, Rollen, Warehouses, Ressourcenmonitoren und der Datenbanken db1 und db2 vom Quellkonto in das Konto myaccount2 derselben Organisation. Konfigurieren den Replikationsplan so, dass myaccount2 alle 10 Minuten automatisch aktualisiert wird.
Führen Sie die folgende Anweisung auf dem Quellkonto aus:
Schritt 4: Rolle mit der Berechtigung CREATE FAILOVER GROUP im Zielkonto erstellen - Optional¶
Erstellen Sie eine Rolle im Zielkonto, und erteilen Sie dieser Rolle die Berechtigung CREATE FAILOVER GROUP. Dieser Schritt ist optional. Wenn Sie diese Rolle bereits erstellt haben, fahren Sie mit Schritt 5: Eine sekundäre Failover-Gruppe im Zielkonto erstellen fort.
Schritt 5: Eine sekundäre Failover-Gruppe im Zielkonto erstellen¶
Bemerkung
Wenn im Zielkonto Kontoobjekte (z. B. Benutzer oder Rollen) vorhanden sind, die es im Quellkonto nicht gibt, lesen Sie bitte Erstmalige Replikation von Benutzern und Rollen, bevor Sie eine sekundäre Gruppe erstellen.
Erstellen Sie eine sekundäre Failover-Gruppe im Zielkonto als Replikat der primären Failover-Gruppe aus dem Quellkonto.
Führen Sie eine CREATE FAILOVER GROUP … AS REPLICA OF-Anweisung in jedem Zielkonto aus, für das Sie die Replikation in Schritt 3: Eine primäre Failover-Gruppe in einem Quellkonto erstellen (unter diesem Thema) aktiviert haben.
Von jedem Zielkonto ausführen:
Schritt 6: Eine sekundäre Failover-Gruppe manuell im Zielkonto aktualisieren — Optional¶
Um die Objekte in einem Zielkonto manuell zu aktualisieren, führen Sie den Befehl ALTER FAILOVER GROUP … REFRESH aus.
Als bewährte Methode empfehlen wir, die sekundären Aktualisierungen durch Einstellen des REPLICATION_SCHEDULE-Parameters mit CREATE FAILOVER GROUP oder ALTER FAILOVER GROUP zu planen.
Bemerkung
Wenn der Benutzer, der die Funktion im Zielkonto aufruft, im Quellkonto gelöscht wurde, schlägt die Aktualisierungsoperation fehl.
Rolle REPLICATE-Berechtigung für Failover-Gruppe erteilen – Optional¶
Um den Befehl zum Aktualisieren einer sekundären Replikations- oder Failover-Gruppe im Zielkonto auszuführen, müssen Sie eine Rolle mit REPLICATE-Berechtigung für die Failover-Gruppe verwenden. Die REPLICATE-Berechtigung wird derzeit nicht repliziert und muss für eine Failover-Gruppe (oder eine Replikationsgruppe) sowohl im Quell- als auch im Zielkonto erteilt werden.
Führen Sie die folgende Anweisung vom Quellkonto aus unter Verwendung einer Rolle mit der Berechtigung OWNERSHIP für die Gruppe aus:
Führen Sie die folgende Anweisung vom Zielkonto aus unter Verwendung einer Rolle mit der Berechtigung OWNERSHIP für die Gruppe aus:
Sekundäre Failover-Gruppe manuell aktualisieren¶
Um beispielsweise die Objekte in der Failover-Gruppe myfg zu aktualisieren, führen Sie die folgende Anweisung über das Zielkonto aus:
Schritt 7: Rolle FAILOVER-Berechtigung für Failover-Gruppe erteilen - Optional¶
Um den Failover-Befehl für eine sekundäre Replikations- oder Failover-Gruppe im Zielkonto auszuführen, müssen Sie eine Rolle mit FAILOVER-Berechtigung für die Failover-Gruppe verwenden. Die Berechtigung FAILOVER wird derzeit nicht repliziert und muss in jedem Quell- und Zielkonto zugewiesen werden.
Weitere Informationen dazu finden Sie unter Replikation von Rollen und Berechtigungszuweisungen.
Um beispielsweise der Rolle my_failover_role die Berechtigung FAILOVER für die Failover-Gruppe my_fg zu erteilen, führen Sie die folgende Anweisung im Zielkonto mit einer Rolle aus, die über OWNERSHIP-Berechtigung für die Gruppe verfügt:
Eine Anleitung zum Erstellen einer kundenspezifischen Rolle mit einer bestimmten Gruppe von Berechtigungen finden Sie unter Erstellen von kundenspezifischen Rollen.
Allgemeine Informationen zu Rollen und Berechtigungen zur Durchführung von SQL-Aktionen auf sicherungsfähigen Objekten finden Sie unter Übersicht zur Zugriffssteuerung.
Replikation auf Schemaebene für Failover-Gruppen¶
Für Datenbanken in Failover-Gruppen können Sie optional den Parameter REPLICABLE_WITH_FAILOVER_GROUPS für die Datenbank und/oder einzelne Schemas in der Datenbank konfigurieren, um eine Teilmenge von Schemas für die Replikation anzugeben.
Mit diesem Feature können Sie steuern, welche Schemas in einer Failover-Gruppe repliziert werden. Dies ist nützlich, wenn nur eine Teilmenge der Daten in einer Datenbank den zusätzlichen Notfallwiederherstellungsschutz durch Failover benötigt.
Da dieser Parameter standardmäßig für alle Datenbanken und die darin enthaltenen Schemas aktiviert ist, können Sie die Granularität der Replikation anpassen, indem Sie auswählen, welche Datenbanken und/oder Schemas von der Replikation ausgenommen werden sollen. Sie können die Replikationseinstellungen weiter verfeinern, indem Sie zulassen, dass bestimmte Schemas repliziert werden, obwohl die Datenbank, die sie enthält, nicht repliziert wird.
Schemas angeben, die repliziert oder übersprungen werden sollen¶
Sie können explizit Schemas angeben, die in einer Datenbank in einer Failover-Gruppe repliziert oder übersprungen werden sollen, indem Sie den optionalen Parameter REPLICABLE_WITH_FAILOVER_GROUPS verwenden.
Parameter REPLICABLE_WITH_FAILOVER_GROUPS¶
Der Parameter REPLICABLE_WITH_FAILOVER_GROUPS gibt an, ob ein Schema, das zu einer Datenbank in einer Failover-Gruppe gehört, repliziert wird. Dieser Parameter kann für eine Datenbank und beliebige/alle Schemas in der Datenbank festgelegt werden. Wenn der Parameter für eine Datenbank festgelegt wird, erben alle Schemas in der Datenbank den Wert, es sei denn, für ein bestimmtes Schema wird ausdrücklich ein anderer Wert festgelegt.
Der Parameter akzeptiert zwei Werte, 'YES' oder 'NO' (Groß- und Kleinschreibung wird nicht berücksichtigt), und ist optional:
Wenn REPLICABLE_WITH_FAILOVER_GROUPS in einer Datenbank nicht explizit gesetzt (oder explizit nicht gesetzt) ist, folgt die Datenbank der Standardreplikations-Verhaltensweise, was dem Setzen des Parameters auf
'YES'entspricht.Wenn REPLICABLE_WITH_FAILOVER_GROUPS nicht explizit für ein Schema gesetzt (oder explizit nicht gesetzt) ist, wird die Replikations-Verhaltensweise von der übergeordneten Datenbank übernommen.
Sicherheitsanforderungen¶
Um diesen Parameter für eine Datenbank oder ein Schema zu setzen oder die Auswahl aufzuheben, benötigen Sie die folgenden Berechtigungen:
REPLICATE (Berechtigung auf Kontoebene). Vor dem Replikations-Feature auf Schemaebene war diese Berechtigung nur eine Berechtigung auf Objektebene für Replikationsgruppen und Failover-Gruppen. Benutzer mit der Rolle ACCOUNTADMIN können diese Berechtigung an andere Rollen weitergeben.
USAGE (Berechtigung für Datenbank und Schema) oder eine ähnliche Berechtigung, die es Ihnen ermöglicht, auf die Datenbank und das Schema einzuwirken.
Beispiele¶
Erteilen Sie die erforderlichen Berechtigungen für eine bereits existierende Rolle, replicationadmin:
Replizieren Sie nur ein Schema, sch1, in der Datenbank db1:
Replizieren Sie alle Schemas außer einem Schema, sch2, in der Datenbank db2:
Schemas aktualisieren, wenn REPLICABLE_WITH_FAILOVER_GROUPS in Zielkonten eingestellt ist¶
Während einer Datenbankaktualisierung:
Schemas, bei denen REPLICABLE_WITH_FAILOVER_GROUPS auf
'YES'eingestellt ist, werden vom Quellkonto in das Zielkonto repliziert.Schemas, bei denen REPLICABLE_WITH_FAILOVER_GROUPS auf
'NO'gesetzt ist, werden nicht repliziert, außer in den folgenden beiden Szenarien:Das Zielschema ist ein Replikat des Quellkontoschemas. In diesem Fall wird das Zielschema immer mit seinem Quellschema synchronisiert.
Das Zielschema hat einen Namenskonflikt mit dem Quellkontenschema. In dieser Situation schlägt der Replikationsjob aufgrund des Namenskonflikts fehl.
Liste der Datenbanken und Schemata in Ihrem Konto, bei denen REPLICABLE_WITH_FAILOVER_GROUPS festgelegt ist¶
Sie können die Werte auflisten, die für den Parameter REPLICABLE_WITH_FAILOVER_GROUPS im aktuellen Konto festgelegt wurden, indem Sie die Ansichten ACCOUNT_USAGE und INFORMATION_SCHEMA abfragen.
Tipp
Wenn Sie nicht wissen, warum Sie die Ansichten ACCOUNT_USAGE oder INFORMATION_SCHEMA verwenden sollten, lesen Sie Unterschiede zwischen Account Usage und Information Schema.
Beispiele¶
Für diese Beispiele verwenden wir die INFORMATION_SCHEMA-Ansichten. Auf diese Weise können Sie die Einstellungen sofort nach der Änderung sehen.
Geben Sie mithilfe der bereits vorhandenen Rolle replicationadmin alle Parameterwerte für das Konto zurück, das über zwei Datenbanken verfügt:
db1-Datenbank, die explizit aufNOgesetzt ist, undsch1-Schema in der Datenbank, das explizit aufYESgesetzt ist. Nur dieses eine Schema in der Datenbank ist für die Replikation geeignet.db2-Datenbank, die explizit aufYESgesetzt ist, undsch2-Schema in der Datenbank, das explizit aufNOgesetzt ist. Alle Schemas in der Datenbank kommen für die Replikation in Frage, mit Ausnahme dieses einen Schemas.
Globale IDs auf Objekte anwenden, die von Skripten in Zielkonten erstellt wurden¶
Wenn Sie Kontoobjekte, z. B. Benutzer und Rollen, in Ihrem Zielkonto auf andere Weise als über die Replikation (z. B. mithilfe von Skripten) erstellt haben, haben diese Benutzer und Rollen standardmäßig keinen globalen Bezeichner. Bei der Aktualisierungsoperation werden globale Bezeichner verwendet, um diese Objekte mit denselben Objekten im Quellkonto zu synchronisieren.
Wenn ein Zielkonto vom Quellkonto aus aktualisiert wird, führt die Aktualisierungsoperation zum Löschen aller Kontoobjekte der Typen in der OBJECT_TYPES-Liste des Zielkontos, die keine globale ID haben. Die erstmalige Replikation von Benutzern und Rollen auf ein Zielkonto kann jedoch dazu führen, dass die erste Aktualisierungsoperation fehlschlägt. Weitere Informationen zu diesem Verhalten finden Sie unter Erstmalige Replikation von Benutzern und Rollen.
SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME() zum Anwenden von globalen IDs verwenden¶
Sie können den Verlust einiger Objekttypen verhindern, indem Sie übereinstimmende Objekte mit demselben Namen in Quell- und Zielkonto verknüpfen. Die Funktion SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME fügt den Kontoobjekten des Zielkontos eine globale ID hinzu.
Bemerkung
Globale Bezeichner werden nur zu Kontoobjekten hinzugefügt, die in einer Replikations- oder Failover-Gruppe für die folgenden Objekttypen enthalten sind:
RESOURCE_MONITORROLEUSERWAREHOUSE
Wenden Sie globale Bezeichner auf Kontoobjekte im Zielkonto an, die in der Liste object_types für die Failover-Gruppe myfg enthalten sind:
Führen Sie die folgende SQL-Anweisung mit der Rolle ACCOUNTADMIN aus:
Erstmalige Replikation von Benutzern und Rollen¶
Das Verhalten bei der erstmaligen Aktualisierungsoperation der Objekttypen USERS und ROLES kann variieren, je nachdem, ob es im Zielkonto übereinstimmende Objekte mit demselben Namen gibt oder nicht.
Bemerkung
Das in diesem Abschnitt beschriebene Verhalten gilt nur, wenn diese Objekttypen das erste Mal in das Zielkonto repliziert werden.
Die folgenden Szenarios beschreiben die Replikation von USERS. Dieselbe Vorgehensweise gilt auch für die Replikation von ROLES.
Wenn es im Zielkonto bereits Benutzer mit demselben Namen wie im Quellkonto gibt, schlägt die erste Aktualisierungsoperation fehl. Es gibt nun zwei Optionen um fortzufahren:
Die Aktualisierungsoperation wird erzwungen, und es wird zugelassen, dass alle vorhandenen Benutzer und/oder Rollen im Zielkonto gelöscht werden. Die Benutzer des Quellkontos werden in das Zielkonto repliziert.
Um eine Aktualisierung für eine Gruppe zu erzwingen, verwenden Sie im REFRESH-Befehl den Parameter FORCE. Um beispielsweise die Aktualisierung einer Failover-Gruppe zu erzwingen, führen Sie den folgenden Befehl aus:
Die Kontoobjekte werden nach Namen verknüpft. Die Funktion SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME verknüpft Benutzer, die im Zielkonto und im Quellkonto denselben Namen haben. Im Zielkonto verknüpfte Benutzer werden nicht gelöscht.
Um Kontoobjekte über ihren Namen zu verknüpfen, führen Sie den folgenden Befehl aus:
Bemerkung
Jeder Benutzer im Zielkonto, für den es im Quellkonto keinen übereinstimmenden Benutzer mit demselben Namen gibt, wird gelöscht.
Wenn es im Zielkonto keine Benutzer gibt, deren Namen mit denen der Benutzer im Quellkonto übereinstimmen, werden bei der ersten Aktualisierungsoperation alle Benutzer im Zielkonto gelöscht. Dies kann zu folgenden Verlusten von Daten und Metadaten führen:
Wenn USERS in der Liste OBJECT_TYPES einer Replikations- oder Failover-Gruppe enthalten ist, passiert Folgendes:
Arbeitsblätter gehen verloren
Abfrageverlauf geht verloren
Wenn USERS in der Liste OBJECT_TYPES enthalten ist, ROLES aber nicht, passiert Folgendes:
Berechtigungen für Benutzer gehen verloren
Wenn ROLES in der Liste OBJECT_TYPES enthalten ist, passiert Folgendes:
Berechtigungen zur Freigabe von Objekten gehen verloren
So verhindern Sie, dass Benutzer oder Rollen im Zielkonto gelöscht werden:
Erstellen Sie vor der ersten Replikation im Quellkonto manuell alle Benutzer oder Rollen neu, die nur im Zielkonto vorhanden sind.
Verknüpfen Sie im Zielkonto übereinstimmende Objekte mit dem gleichen Namen in beiden Konten mit der Funktion SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME.
Cloudspeicherzugriff für sekundäre Speicherintegrationen konfigurieren¶
Wenn Sie die Replikation der Speicherintegration aktivieren, müssen Sie nach der Replikation der Speicherintegration auf die Zielkonten zusätzliche Schritte ausführen. Die replizierte Integration hat eine eigene Entität für die Identitäts- und Zugriffsverwaltung (IAM), die sich von der Identitäts- und IAM-Entität der primären Integration unterscheidet. Daher müssen Sie die Berechtigungen Ihres Cloudanbieters aktualisieren, um der replizierten Integration Zugriff auf Ihren Cloudspeicher zu gewähren.
Sie müssen diese Vertrauensstellung für Zielkonten nur einmal konfigurieren.
Der Prozess ist ähnlich wie bei der Gewährung des Zugriffs im Quellkonto. Weitere Informationen dazu finden Sie auf den folgende Seiten:
Konfigurieren der automatischen Aktualisierung von Verzeichnistabellen in sekundären Stagingbereichen¶
Wenn Sie einen externen Stagingbereich mit Verzeichnistabelle replizieren und die automatische Aktualisierung für die primäre Verzeichnistabelle konfiguriert haben, müssen Sie die automatische Aktualisierung für die sekundäre Verzeichnistabelle konfigurieren.
Der Prozess ist ähnlich wie bei der Einrichtung der automatischen Aktualisierung in Ihrem Quellkonto. Weitere Informationen dazu finden Sie unter:
Amazon S3: Der Konfigurationsprozess hängt davon ab, wie Sie die Ereignisbenachrichtigungen einrichten.
Wenn Sie Amazon S3-Ereignisbenachrichtigungen mit Amazon Simple Queue Service (SQS) verwenden, folgen Sie den Anweisungen unter Schritt 2: Ereignisbenachrichtigungen konfigurieren. Sie können auch von SQS nach SNS migrieren. Weitere Informationen dazu finden Sie unter Migration zu Amazon Simple Notification Service (SNS).
Wenn Sie Amazon Simple Notification Service (SNS) verwenden, finden Sie weitere Informationen unter Abonnieren der Snowflake-SQS-Warteschlange zu Ihrem SNS-Thema.
Google Cloud Storage: Erstellen Sie ein neues Abonnement für Ihr Pub/Sub-Thema und eine neue Benachrichtigungsintegration in Ihrem Zielkonto. Gewähren Sie dann Snowflake Zugriff auf das Pub/Sub-Abonnement. Eine Anleitung dazu finden Sie unter Configure automation using GCS Pub/Sub.
Azure Blob Storage: Erstellen Sie ein neues Event Grid-Abonnement und eine Speicherwarteschlange. Erstellen Sie dann eine neue Benachrichtigungsintegration im Zielkonto und gewähren Sie Snowflake Zugriff auf Ihre Speicherwarteschlange. Eine Anleitung dazu finden Sie unter Konfigurieren der Automatisierung mit Azure Event Grid.
Wichtig
Nachdem Sie diese Konfigurationsschritte in Ihrem Zielkonto abgeschlossen haben, sollten Sie eine vollständige Aktualisierung Ihrer Verzeichnistabelle ausführen, um sicherzustellen, dass keine Benachrichtigungen übersehen wurden.
Bei Google Cloud Storage und Azure Blob Storage muss der Name der Benachrichtigungsintegration in jedem Zielkonto mit dem Namen der Benachrichtigungsintegration im Quellkonto übereinstimmen.
Konfigurieren von Benachrichtigungen für sekundäre Auto-Erfassungs-Pipes¶
Sie müssen zusätzliche Schritte ausführen, um vor dem Failover Cloudbenachrichtigungen für sekundäre Pipes zur automatischen Datenerfassung zu konfigurieren. In diesem Abschnitt wird erläutert, warum diese zusätzliche Konfiguration erforderlich ist und wie sie für jeden unterstützten Cloudanbieter ausgeführt werden kann.
Amazon S3¶
Der Konfigurationsprozess hängt davon ab, wie Sie die Ereignisbenachrichtigungen einrichten. Angenommen, Sie haben eine Auto-Erfassungs-Pipe, die auf ein Amazon Simple Notification Service (SNS)-Thema angewiesen ist, um Meldungen zum Standort des Snowflake-Stagingbereichs zu veröffentlichen.
Wenn Sie die Pipe auf ein Zielkonto replizieren, erstellt Snowflake automatisch eine neue Amazon Simple Queue Service (SQS)-Warteschlange. Sie müssen diese SQS-Warteschlange für Ihr Zielkonto beim SNS-Thema abonnieren, um Benachrichtigungen zum Speicherort des Stagingbereichs zu erhalten.
Wenn Sie Amazon S3-Ereignisbenachrichtigungen mit Amazon Simple Queue Service (SQS) verwenden, folgen Sie den Anweisungen unter Schritt 4: Ereignisbenachrichtigungen konfigurieren.
Wichtig
Um sicherzustellen, dass die Pipe keine Benachrichtigungen verpasst hat, müssen Sie die Pipe nach dem Wechsel zur neuen SQS-Warteschlange aktualisieren.
Sie können auch von SQS nach SNS migrieren. Weitere Informationen dazu finden Sie unter Migration zu Amazon Simple Notification Service (SNS).
Wenn Sie Amazon Simple Notification Service (SNS) verwenden, finden Sie weitere Informationen unter Abonnieren der Snowflake-SQS-Warteschlange zu Ihrem SNS-Thema.
Wenn Sie Amazon EventBridge verwenden, finden Sie weitere Informationen unter Option 3: Einrichten von Amazon EventBridge zum Automatisieren von Snowpipe.
Microsoft Azure Blob Storage¶
Eine Pipe, die automatisch Daten aus Dateien lädt, die sich in einem Stagingbereich in Microsoft Azure Blob Storage befinden, erfordert ein Event Grid-Abonnement, eine Speicherwarteschlange und eine an die Speicherwarteschlange gebundene Benachrichtigungsintegration. Eine sekundäre Pipe in einem Zielkonto benötigt ein separates Event Grid, eine Speicherwarteschlange und eine an die Speicherwarteschlange gebundene Benachrichtigungsintegration. Das Event Grid in Quell- und Zielkonten muss als Endpunkte für dieselbe Azure Storage-Quelle konfiguriert sein.
Weitere Informationen zur Konfiguration finden Sie im nachstehenden Diagramm:
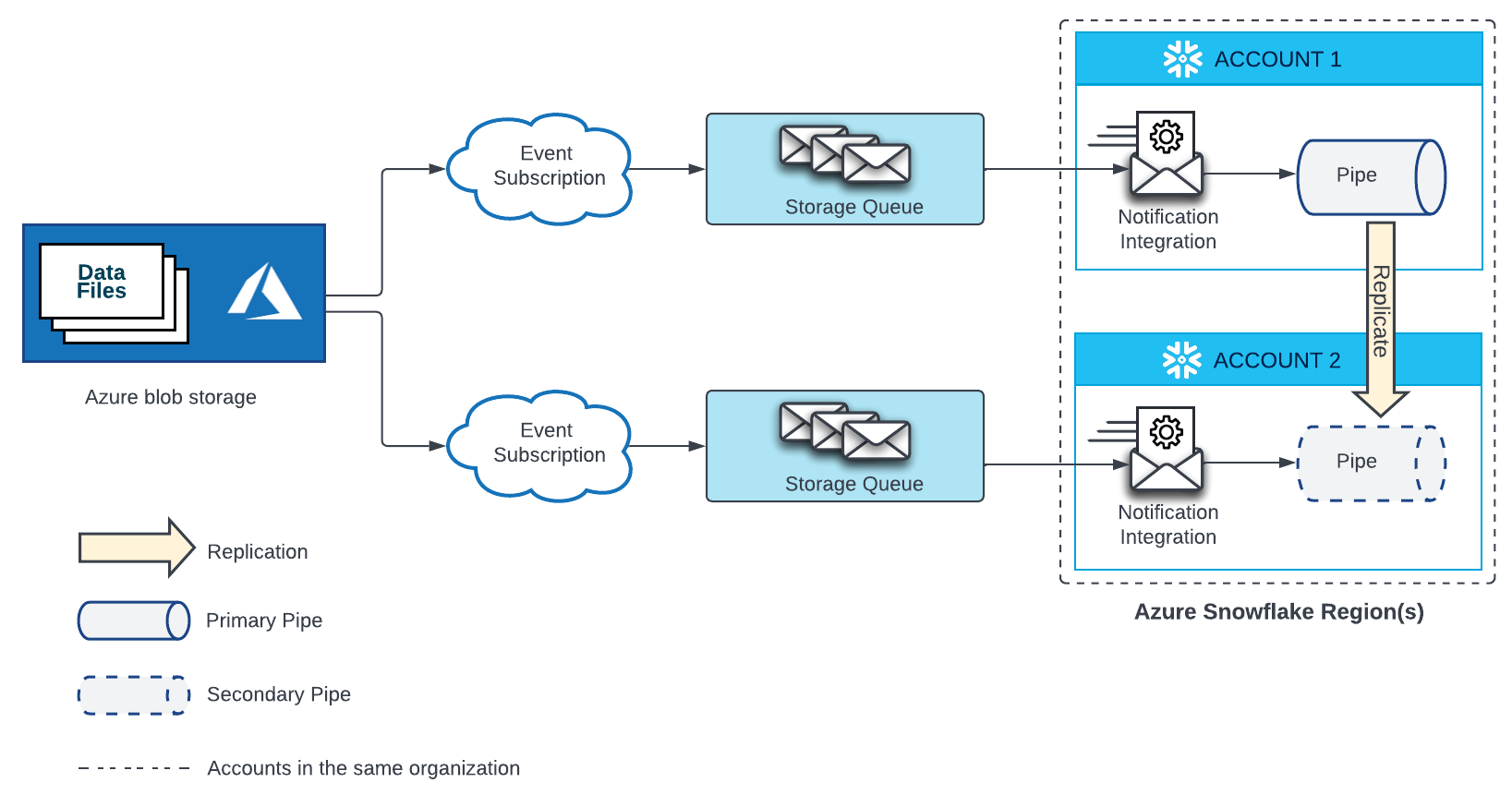
Erstellen Sie ein neues Event Grid-Abonnement und eine Speicherwarteschlange. Erstellen Sie dann eine neue Benachrichtigungsintegration im Zielkonto und gewähren Sie Snowflake Zugriff auf Ihre Speicherwarteschlange. Eine Anleitung dazu finden Sie unter Konfigurieren der Automatisierung mit Azure Event Grid.
Wichtig
Der Name der Benachrichtigungsintegration in jedem Zielkonto muss mit dem Namen der Benachrichtigungsintegration im Quellkonto übereinstimmen.
Externer Stagingbereich für Google Cloud Storage¶
Eine Pipe, die automatisch Daten aus Dateien in Google Cloud Storage lädt, erfordert ein Google Pub/Sub-Abonnement und eine Benachrichtigungsintegration, die auf dieses Abonnement verweist. Jede replizierte Pipe in einem Zielkonto erfordert außerdem ein Google Pub/Sub-Abonnement und eine Benachrichtigungsintegration, die auf dieses Abonnement verweist. Das Pub/Sub-Abonnement in jedem Quell- und Zielkonto muss auf dasselbe Pub/Sub-Thema abonniert sein, das Benachrichtigungen von der Google Cloud Storage-Quelle erhält.
Weitere Informationen zur Konfiguration finden Sie im nachstehenden Diagramm:
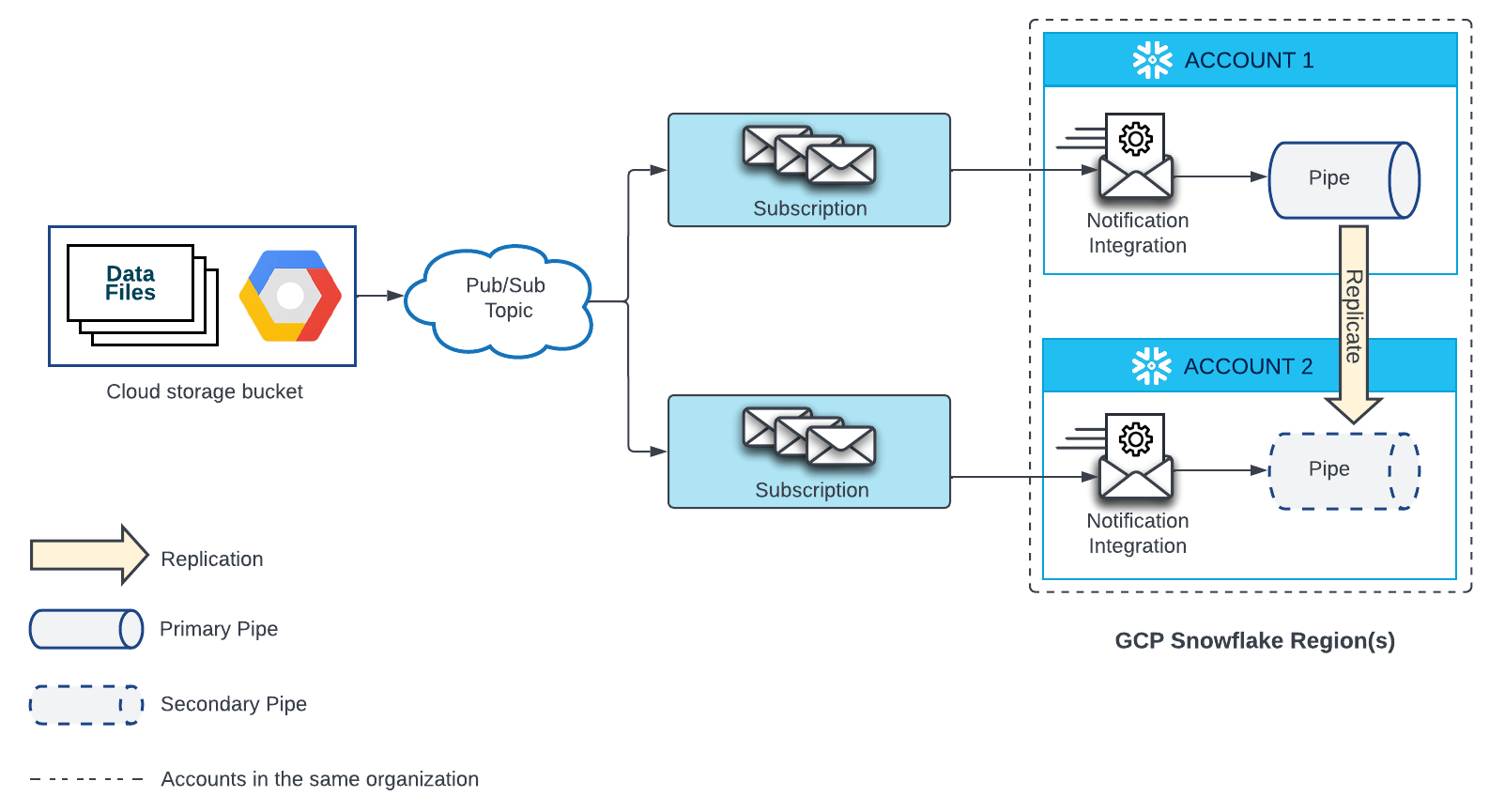
- Erstellen Sie ein neues Abonnement für Ihr Pub/Sub-Thema und eine neue Benachrichtigungsintegration in Ihrem Zielkonto.
Gewähren Sie dann Snowflake Zugriff auf das Pub/Sub-Abonnement. Eine Anleitung dazu finden Sie unter Konfigurieren von automatischem Snowpipe mit GCS Pub/Sub.
Wichtig
Der Name der Benachrichtigungsintegration in jedem Zielkonto muss mit dem Namen der Benachrichtigungsintegration im Quellkonto übereinstimmen.
Aktualisieren des Remotedienstes für API-Integrationen¶
Wenn Sie die Replikation von API-Integrationen aktiviert haben, sind zusätzliche Schritte erforderlich, nachdem die API-Integration in das Zielkonto repliziert wurde. Die replizierte Integration hat eine eigene Entität für die Identitäts- und Zugriffsverwaltung (IAM), die sich von der Identitäts- und IAM-Entität der primären Integration unterscheidet. Daher müssen Sie die Berechtigungen für den Remotedienst aktualisieren, um den Zugriff auf replizierte Funktionen zu gewähren. Der Prozess ist ähnlich wie das Gewährung des Zugriffs auf die Funktionen des Primärkontos. Weitere Informationen dazu finden Sie unter:
Amazon Web Services Vertrauensstellungen zwischen Snowflake und der neuen IAM-Rolle einrichten
Google Cloud Platform: GCP-Sicherheitsrichtlinie für Proxydienst erstellen
Microsoft Azure:
Schritt 1. API-Integration für Azure verknüpfen
Schritt 2. validate-JWT-Richtlinie erstellen
Vergleichen von Datensets in Primär- und Sekundärdatenbanken¶
Snowflake führt im Rahmen jedes Aktualisierungsvorgang der Replikation automatische Überprüfungen durch. Wenn ein Überprüfungsfehler auftritt, schlägt die Aktualisierung fehl. Daher müssen Sie die replizierten Daten nicht manuell verifizieren. Wenn Sie aus Gründen der Compliance eine zusätzliche Überprüfung benötigen, können Sie nach Abschluss des Aktualisierungsvorgangs manuelle Überprüfungsschritte durchführen.
Automatische Überprüfung durch Snowflake¶
Snowflake führt derzeit nach jedem Aktualisierungsvorgang die folgenden Überprüfungen zwischen dem primären und dem sekundären Konto durch:
Snowflake vergleicht die Hash-Werte zwischen dem primären und dem sekundären Konto für alle Dateien, die repliziert wurden.
Für jede Tabelle vergleicht Snowflake die folgenden Werte zwischen dem primären und dem sekundären Konto:
Anzahl der Dateien.
Anzahl der Zeilen.
Anzahl der Byte.
Manuelle Überprüfung¶
Wenn Datenbankobjekte in einer Replikations- oder Failover-Gruppe repliziert werden, kann die Funktion HASH_AGG verwendet werden, um die Zeilen in einigen oder allen Tabellen einer Primär- und Sekundärdatenbank zu vergleichen und so die Datenkonsistenz zu überprüfen. Die HASH_AGG-Funktion gibt einen aggregierten, signierten 64-Bit-Hash-Wert für die Menge von Eingabezeilen zurück. Der Hashwert ist unabhängig von der Reihenfolge der Eingabezeilen derselbe.
Fragen Sie diese Funktion für alle Tabellen oder eine zufällige Teilmenge von Tabellen sowohl im sekundären als auch im primären Konto ab. Verwenden Sie für das primäre Konto eine AT | BEFORE-Klausel, um den Zeitpunkt der letzten Aktualisierung für die zugehörige Datenbank anzugeben. Vergleichen Sie die Ausgabe zwischen den Abfragen für beide Konten.
Beispiel für die manuelle Überprüfung von Daten nach einer Aktualisierung¶
In den folgenden Beispielen ist die Datenbank mydb in der Failover-Gruppe myfg enthalten. Die Datenbank mydb enthält die Tabelle myschema.mytable.
Befehle zur Ausführung für das Zielkonto¶
Fragen Sie die Tabellenfunktion REPLICATION_GROUP_REFRESH_PROGRESS ab (in Snowflake Information Schema). Beachten Sie den
primarySnapshotTimestampin der SpalteDETAILSfür die PhasePRIMARY_UPLOADING_METADATA. Dies ist der Zeitstempel für die letzte Aktualisierung dieser Datenbank auf dem primären Konto.Fragen Sie die Funktion HASH_AGG für eine angegebene Tabelle der Sekundärdatenbank ab. Die folgende Abfrage gibt einen Hashwert für alle Zeilen der Tabelle
myschema.mytablezurück:
Befehle zur Ausführung für das Quellkonto¶
Fragen Sie die Funktion HASH_AGG für dieselbe Tabelle der Primärdatenbank ab. Geben Sie mithilfe von Time Travel den Zeitstempel an, zu dem die letzte Aktualisierung der sekundären Datenbank durchgeführt wurde:
Vergleichen Sie die Ergebnisse der beiden Abfragen. Die Ausgabe sollte identisch sein.
Ändern einer Replikations- oder Failover-Gruppe in einem Quellkonto¶
Sie können den Namen, die enthaltenen Objekte und den Replikationsplan einer Replikations- oder Failover-Gruppe in einem Quellkonto mit Snowsight oder SQL bearbeiten.
Bemerkung
Replikationsgruppen können nicht in Failover-Gruppen umgewandelt werden und umgekehrt. Um das Failover zu aktivieren oder zu deaktivieren, löschen Sie die Gruppe und erstellen Sie sie erneut mit der richtigen Failover-Einstellung.
Ändern einer Replikations- oder Failover-Gruppe in einem Konto mit Snowsight¶
Bemerkung
Nur Kontoadministratoren können eine Replikations- oder Failover-Gruppe mit Snowsight bearbeiten (siehe Einschränkungen bei der Verwendung von Snowsight für die Replikationskonfiguration).
Um diese Aktionen durchführen zu können, müssen Sie bei dem Quellkonto angemeldet sein. Wenn Sie nicht angemeldet sind, wird in der Spalte Status anstelle des Aktualisierungsstatus eine Anmeldemeldung angezeigt.
Melden Sie sich bei Snowsight an.
Wählen Sie im Navigationsmenü die Option Admin » Accounts aus.
Wählen Sie Replication und dann Groups aus.
Suchen Sie die Replikations- oder Failover-Gruppe, die Sie bearbeiten möchten, und wählen Sie das Menü More (…) in der letzten Spalte der Zeile.
Wählen Sie Edit aus.
Um den Gruppennamen zu ändern, geben Sie in das Feld Group name einen neuen Namen ein, der die folgenden Anforderungen erfüllt:
Muss mit einem Buchstaben beginnen und darf keine Leer- oder Sonderzeichen enthalten, es sei denn, der Bezeichner ist in doppelte Anführungszeichen eingeschlossen (z. B. „Mein Objekt“). Bei Bezeichnern, die in doppelte Anführungszeichen eingeschlossen sind, ist auch die Groß-/Kleinschreibung zu beachten.
Weitere Informationen dazu finden Sie unter Anforderungen an Bezeichner.
Bezeichner von Failover-Gruppen und Replikationsgruppen in einem Konto müssen eindeutig sein.
Wählen Sie Edit objects aus, um Freigabe- und Kontoobjekte hinzuzufügen oder zu entfernen.
Bemerkung
Kontoobjekte können nur zu einer einzigen Replikations- oder Failover-Gruppe hinzugefügt werden. Wenn in Ihrem Konto bereits eine Replikations- oder Failover-Gruppe mit Kontoobjekten vorhanden ist, können Sie diese Objekte nicht auswählen.
Wählen Sie Select databases aus, um Datenbankobjekte hinzuzufügen oder zu entfernen.
Wählen Sie die Replication frequency aus, um den Replikationsplan einer Gruppe zu ändern.
Wählen Sie Save aus, um die Gruppe zu aktualisieren.
Wenn das Speichern der Änderungen an der Gruppe nicht erfolgreich war, finden Sie unter Probleme beim Erstellen und Bearbeiten von Replikationsgruppen in Snowsight beheben Informationen zu häufigen Fehlern und deren Behebung.
Ändern Sie eine Replikations- oder Failover-Gruppe in einem Quellkonto mit SQL¶
Sie können die Eigenschaften einer Replikations- oder Failover-Gruppe mit dem Befehl ALTER REPLICATION GROUP oder ALTER FAILOVER GROUP ändern.
Einen Replikationsplan in einem Zielkonto anhalten oder fortsetzen¶
Sie können einen Replikationsplan in einem Zielkonto mit Snowsight oder SQL anhalten (aussetzen) oder fortsetzen.
Anhalten oder Fortsetzen eines Replikationsplans in einem Zielkonto mit Snowsight¶
Bemerkung
Nur Kontoadministratoren können eine Replikations- oder Failover-Gruppe mit Snowsight bearbeiten (siehe Einschränkungen bei der Verwendung von Snowsight für die Replikationskonfiguration).
Um einen Replikationsplan anzuhalten oder fortzusetzen, müssen Sie bei dem Zielkonto angemeldet sein.
Melden Sie sich bei Snowsight an.
Wählen Sie im Navigationsmenü die Option Admin » Accounts aus.
Wählen Sie Replication und dann Groups aus.
Suchen Sie die Replikations- oder Failover-Gruppe, die Sie bearbeiten möchten, und wählen Sie das Menü More (…) in der letzten Spalte der Zeile.
Wählen Sie Pause oder Resume aus.
Anhalten oder Fortsetzen eines Replikationsplans in einem Zielkonto mit SQL¶
Sie können einen Replikationsplan in einem Zielkonto mit dem Befehl ALTER REPLICATION GROUP oder ALTER FAILOVER GROUP anhalten oder fortsetzen. Um zu pausieren, geben Sie den Parameter SUSPEND an. Um fortzufahren, geben Sie den Parameter RESUME an.
Löschen einer sekundären Replikations- oder Failover-Gruppe¶
Sie können eine sekundäre Replikations- oder Failover-Gruppe mit den Befehlen DROP REPLICATION GROUP bzw. DROP FAILOVER GROUP löschen. Nur der Eigentümer der Replikations- oder Failover-Gruppe (d. h. die Rolle mit der Berechtigung OWNERSHIP für die Gruppe) kann die Gruppe löschen.
Um eine sekundäre Replikations- oder Failover-Gruppe mit Snowsight zu löschen, müssen Sie die Gruppe im Quellkonto löschen. Siehe Replikations- oder Failover-Gruppe mit Snowsight löschen.
Löschen einer primären Replikations- oder Failover-Gruppe¶
Sie können eine primäre Replikations- oder Failover-Gruppe mit Snowsight oder SQLlöschen. Wenn Sie eine primäre Gruppe mit SQL löschen möchten, müssen Sie zuerst alle sekundären Gruppen löschen. Siehe Löschen einer sekundären Replikations- oder Failover-Gruppe.
Primäre Replikations- oder Failover-Gruppe mit SQL löschen¶
Eine primäre Replikations- oder Failover-Gruppe kann erst gelöscht werden, nachdem alle Replikate der Gruppe (d. h. die sekundären Replikations- oder Failover-Gruppen) gelöscht wurden. Alternativ können Sie eine sekundäre Failover-Gruppe zur primären Failover-Gruppe heraufstufen und dann die bisherige primäre Failover-Gruppe löschen.
Beachten Sie, dass die Gruppe nur vom Eigentümer der Gruppe gelöscht werden kann.
Replikations- oder Failover-Gruppe mit Snowsight löschen¶
Bemerkung
Nur Kontoadministratoren können eine Replikations- oder Failover-Gruppe mit Snowsight löschen (siehe Einschränkungen bei der Verwendung von Snowsight für die Replikationskonfiguration).
Sie können eine primäre Replikations- oder Failover-Gruppe und alle damit verknüpften sekundären Gruppen löschen.
Melden Sie sich bei Snowsight an.
Wählen Sie im Navigationsmenü die Option Admin » Accounts aus.
Wählen Sie Replication und dann Groups aus.
Suchen Sie die Replikations- oder Failover-Gruppe, die Sie löschen möchten. Wählen Sie in der letzten Spalte der Zeile das Menü More (…) aus.
Wählen Sie Drop und dann Drop group aus.
Probleme beim Erstellen und Bearbeiten von Replikationsgruppen in Snowsight beheben¶
Die folgenden Szenarios können Ihnen helfen, Probleme zu beheben, die beim Erstellen oder Bearbeiten von Replikations- oder Failover-Gruppen in Snowsight auftreten können.
Eine Datenbank kann nicht zu einer Gruppe hinzugefügt werden¶
Fehler |
|
|---|---|
Ursache |
Eine Datenbank kann nur in einer einzigen Replikations- oder Failover-Gruppe sein. Eine der Datenbanken, die Sie für die Gruppe ausgewählt haben, ist bereits in einer anderen Replikations- oder Failover-Gruppe enthalten. |
Lösung |
Wählen Sie Select Databases aus, und heben Sie die Markierung aller Datenbanken auf, die bereits in einer anderen Gruppe enthalten sind. |
Fehler |
|
|---|---|
Ursache |
Die Datenbank, die Sie zu einer Replikations- oder Failover-Gruppe hinzufügen möchten, war zuvor für die Datenbankreplikation konfiguriert. |
Lösung |
Deaktivieren Sie die Datenbankreplikation für die Datenbank. Siehe Umstellen von Datenbankreplikation auf gruppenbasierte Replikation. |
Einschränkungen bei der Verwendung von Snowsight für die Replikationskonfiguration¶
Nur ein Benutzer mit der Rolle ACCOUNTADMIN kann in Snowsight eine Replikations- oder Failover-Gruppe erstellen. Benutzer mit einer Rolle, der die Berechtigung CREATE REPLICATION GROUP oder CREATE FAILOVER GROUP zugewiesen ist, kann mit den entsprechenden SQL-Befehlen eine Gruppe erstellen.
Nur ein Benutzer mit der Rolle ACCOUNTADMIN kann eine Replikations- oder Failover-Gruppe in Snowsight bearbeiten oder löschen. Ein Benutzer mit einer Rolle, der die Berechtigung OWNERSHIP für eine Replikations- oder Failover-Gruppe zugewiesen ist, kann Gruppen mit den entsprechenden SQL-Befehlen bearbeiten und löschen.
Wenn Ihr Konto eine private Konnektivität verwendet, können Sie Snowsight nicht verwenden, um Gruppen zu erstellen, zu ändern oder zu löschen. Sie können SQL verwenden, um diese Aktionen durchzuführen.