Utilisation du pilote JDBC¶
Ce chapitre fournit des informations sur l’utilisation du pilote JDBC.
Extensions des API JDBC Snowflake¶
Le pilote Snowflake JDBC prend en charge des méthodes supplémentaires allant au-delà de la spécification standard JDBC. Cette section explique comment utiliser le désencapsulage pour accéder aux méthodes spécifiques à Snowflake, puis décrit trois des situations dans lesquelles vous devrez peut-être effectuer un désencapsulage :
Désencapsulage de classes spécifiques à Snowflake¶
Le pilote Snowflake JDBC prend en charge des méthodes spécifiques à Snowflake. Ces méthodes sont définies dans des interfaces de langage Java spécifiques à Snowflake, telles que SnowflakeConnection, SnowflakeStatement et SnowflakeResultSet. Par exemple, l’interface SnowflakeStatement contient une méthode getQueryID() qui ne figure pas dans l’interface d’instruction JDBC.
Lorsque le pilote Snowflake JDBC est invité à créer un objet JDBC (par exemple, créer un objet JDBC Statement en appelant une méthode createStatement() de l’objet Connection), le pilote JDBC Snowflake génère en réalité des objets spécifiques à Snowflake qui implémentent non seulement les méthodes de la norme JDBC, mais également les méthodes supplémentaires des interfaces Snowflake.
Pour accéder à ces méthodes Snowflake, vous « désencapsulez » un objet (tel qu’un objet Statement) afin d’exposer l’objet Snowflake et ses méthodes. Vous pouvez ensuite appeler les méthodes supplémentaires.
Le code suivant montre comment désencapsuler un objet JDBC Statement pour exposer les méthodes de l’interface SnowflakeStatement, puis appeler l’une de ces méthodes, dans ce cas setParameter :
Exécution d’une requête asynchrone¶
Le pilote Snowflake JDBC prend en charge les requêtes asynchrones (c’est-à-dire les requêtes qui renvoient le contrôle à l’utilisateur avant la fin de la requête). Vous pouvez démarrer une requête, puis utiliser l’interrogation pour déterminer quand la requête est terminée. Lorsque c’est le cas, l’utilisateur peut lire le jeu de résultats.
Cette fonctionnalité permet à un programme client d’exécuter plusieurs requêtes en parallèle sans que le programme client lui-même utilise le multithread.
Les requêtes asynchrones utilisent des méthodes ajoutées aux classes SnowflakeConnection, SnowflakeStatement, SnowflakePreparedStatement et SnowflakeResultSet.
Note
Pour effectuer des requêtes asynchrones, vous devez vous assurer que le paramètre de configuration ABORT_DETACHED_QUERY est FALSE (valeur par défaut).
Si la connexion au client est perdue :
Pour les requêtes synchrones, toutes les requêtes synchrones en cours sont immédiatement abandonnées, quelle que soit la valeur du paramètre.
Pour les requêtes asynchrones :
Si ABORT_DETACHED_QUERY est réglé sur
FALSE, les requêtes asynchrones en cours continuent de s’exécuter jusqu’à ce qu’elles se terminent normalement.Si ABORT_DETACHED_QUERY est réglé sur
TRUE, Snowflake interrompt automatiquement toutes les requêtes asynchrones en cours lorsqu’une connexion client n’est pas rétablie après cinq minutes.Vous pouvez empêcher l’interruption de la requête asynchrone au bout de cinq minutes en appelant
cursor.query_result(queryId). Bien que cet appel ne permette pas de récupérer le résultat de la requête, puisque celle-ci est toujours en cours d’exécution, il empêche l’annulation de la requête. L’invocation dequery_resultest une opération synchrone, qui peut ou non convenir à votre cas d’utilisation particulier.
Vous pouvez exécuter un mélange de requêtes synchrones et asynchrones dans la même session.
Note
Les requêtes asynchrones ne prennent pas en charge les instructions PUT/GET.
Lorsque executeAsyncQuery(requête) est utilisé, le pilote Snowflake JDBC conserve automatiquement le suivi des requêtes soumises de manière asynchrone. Lorsque la connexion est explicitement fermée avec connection.close(), la liste des requêtes asynchrones est examinée et, si l’une d’entre elles est toujours en cours d’exécution, la session côté Snowflake n’est pas supprimée.
Si aucune requête asynchrone ne s’exécute dans la même connexion, la session Snowflake appartenant à la connexion est déconnectée lorsque connecton.close() est appelé, ce qui annule implicitement toutes les autres requêtes exécutées dans la même session.
Ce comportement dépend également du paramètre SQL ABORT_DETACHED_QUERY. Pour plus d’informations, voir la documentation sur le paramètre ABORT_DETACHED_QUERY
La meilleure pratique consiste à isoler toutes les tâches asynchrones de longue durée (en particulier celles destinées à se poursuivre après la fermeture de la connexion) dans une connexion séparée.
Pour mieux comprendre la hiérarchie de la logique métier des pilotes et l’interaction du paramètre ABORT_DETACHED_QUERY, voir l’organigramme suivant :
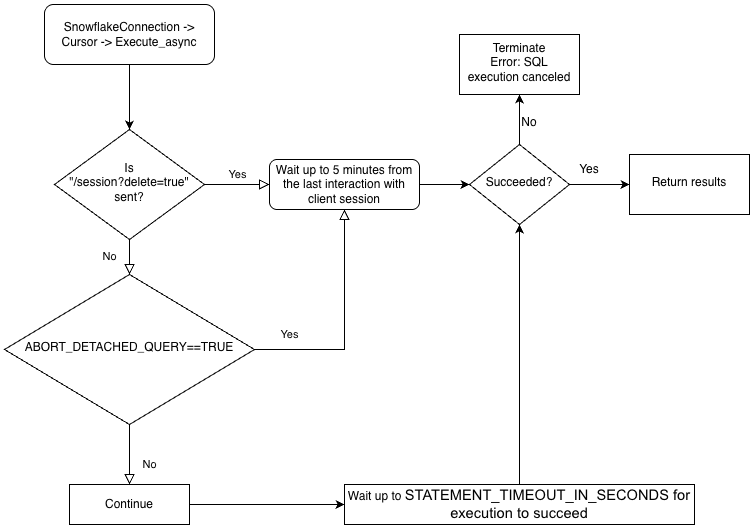
Meilleures pratiques pour les requêtes asynchrones¶
Assurez-vous de savoir quelles requêtes dépendent d’autres requêtes avant d’exécuter des requêtes en parallèle. Les requêtes interdépendantes et sensibles à l’ordre ne conviennent pas à la parallélisation. Par exemple, une instruction INSERT ne doit pas démarrer avant la fin de l’instruction CREATE TABLE correspondante.
Assurez-vous de ne pas exécuter trop de requêtes par rapport à la mémoire dont vous disposez. L’exécution de plusieurs requêtes en parallèle consomme généralement plus de mémoire, en particulier si plusieurs ResultSet sont stockés en mémoire en même temps.
Lors de l’interrogation, gérez les rares cas où une requête échoue. Par exemple, évitez la boucle infinie potentielle suivante :
Utilisez plutôt un code similaire au suivant :
Utilisez plutôt un code similaire au suivant :
Assurez-vous que les instructions de contrôle des transactions (BEGIN, COMMIT et ROLLBACK) ne sont pas exécutées en parallèle avec d’autres instructions.
Exemples de requêtes asynchrones¶
La plupart de ces exemples nécessitent que le programme importe des classes comme illustré ci-dessous :
Voici un exemple très simple :
Cet exemple stocke l’ID de requête, ferme la connexion, rouvre la connexion et utilise l’ID de requête pour récupérer les données :
Voici un exemple très simple :
Cet exemple stocke l’ID de requête, ferme la connexion, rouvre la connexion et utilise l’ID de requête pour récupérer les données :
Charger des fichiers de données directement depuis un flux vers une zone de préparation interne¶
Vous pouvez charger des fichiers de données à l’aide de la commande PUT. Cependant, il est parfois utile de transférer des données directement depuis un flux vers une zone de préparation interne (c.-à-d. Snowflake) en fichier. (La zone de préparation peut être n’importe quel type de zone de préparation interne : zone de préparation de table, zone de préparation d’utilisateur ou zone de préparation nommée. Le pilote JDBC ne prend pas en charge le chargement vers une zone de préparation externe). Voici la méthode exposée dans la classe SnowflakeConnection :
Exemple d’utilisation :
Exemple d’utilisation :
Le code écrit pour les versions de pilote JDBC antérieures à 3.9.2 peut convertir SnowflakeConnectionV1 plutôt que désencapsuler SnowflakeConnection.class. Par exemple :
Note
Les clients utilisant des versions plus récentes du pilote doivent mettre à jour leur code pour utiliser unwrap.
Télécharger des fichiers de données directement depuis une zone de préparation interne vers un flux¶
Vous pouvez télécharger des fichiers de données à l’aide de la commande GET. Cependant, il est parfois utile de transférer des données directement depuis un fichier dans une zone de préparation interne (c.-à-d. Snowflake) vers un flux. (La zone de préparation peut être n’importe quel type de zone de préparation interne : zone de préparation de table, zone de préparation d’utilisateur ou zone de préparation nommée. Le pilote JDBC ne prend pas en charge le téléchargement vers une zone de préparation externe). Voici la méthode exposée dans la classe SnowflakeConnection :
Exemple d’utilisation :
Exemple d’utilisation :
Le code écrit pour les versions de pilote JDBC antérieures à 3.9.2 peut convertir SnowflakeConnectionV1 plutôt que désencapsuler SnowflakeConnection.class. Par exemple :
Prise en charge des multi-instructions¶
Cette section explique comment exécuter plusieurs instructions en une seule requête à l’aide de Pilote JDBC.
Note
L’exécution de plusieurs instructions dans une seule requête nécessite qu’un entrepôt valide soit disponible dans une session.
Par défaut, Snowflake renvoie une erreur pour les requêtes émises avec plusieurs instructions en vue d’apporter une protection contre les attaques par injection SQL. L’exécution de plusieurs instructions dans une seule requête augmente le risque d’injection SQL. Snowflake recommande de l’utiliser avec parcimonie. Vous pouvez réduire le risque d’injection SQL en utilisant la méthode
SnowflakeStatementclass’ssetParameter()pour spécifier le nombre d’instructions à exécuter, ce qui rend plus difficile l’injection d’une instruction en l’ajoutant. Pour plus d’informations surSnowflakeStatement, voir Interface : SnowflakeStatement.
Envoi de plusieurs instructions et traitement des résultats¶
Les requêtes contenant plusieurs instructions peuvent être exécutées de la même manière que les requêtes avec une seule instruction, à la différence que la chaîne de requête contient plusieurs instructions séparées par des points-virgules.
Il existe deux façons d’autoriser plusieurs instructions :
Appelez Call Statement.setParameter(« MULTI_STATEMENT_COUNT », n) pour spécifier combien d’instructions à la fois cette instruction doit être autorisée à exécuter. Voir ci-dessous pour plus de détails.
Définissez le paramètre MULTI_STATEMENT_COUNT au niveau de la session ou au niveau du compte en exécutant une des commandes suivantes :
Ou :
La définition du paramètre sur 0 permet un nombre illimité d’instructions. La définition du paramètre sur 1 n’autorise qu’une seule instruction à la fois.
Afin de rendre les attaques par injection SQL plus difficiles, les utilisateurs peuvent appeler la méthode setParameter pour spécifier le nombre d’instructions à exécuter dans un seul appel, comme indiqué ci-dessous. Dans cet exemple, le nombre d’instructions à exécuter dans un seul appel est 3 :
Le nombre d’instructions par défaut est 1 ; en d’autres termes, le mode multi-instructions est désactivé.
Pour exécuter plusieurs instructions sans spécifier le nombre exact, transmettez une valeur 0.
Le paramètre MULTI_STATEMENT_COUNT ne fait pas partie de la norme JDBC ; il s’agit d’une extension Snowflake. Ce paramètre affecte plusieurs pilotes/connecteurs Snowflake.
Lorsque plusieurs instructions sont exécutées dans un seul appel execute(), le résultat de la première instruction est disponible via les méthodes standard getResultSet() et getUpdateCount(). Pour accéder aux résultats des instructions suivantes, utilisez la méthode getMoreResults(). Cette méthode renvoie true lorsque plus d’instructions sont disponibles pour l’itération, et false dans le cas contraire.
L’exemple ci-dessous définit le paramètre MULTI_STATEMENT_COUNT, exécute les trois instructions et récupère le nombre de mises à jour et les jeux de résultats :
Snowflake recommande d’utiliser execute() pour les requêtes à instructions multiples. Les méthodes executeQuery() et executeUpdate() prennent également en charge plusieurs instructions, mais émettent une exception si le premier résultat n’est pas le type de résultat attendu (jeu de résultats et nombre de mises à jour, respectivement).
Échecs d’instructions¶
Si l’une des instructions SQL échoue lors de la compilation ou de l’exécution, l’exécution est interrompue. Toutes les instructions précédentes exécutées auparavant ne sont pas affectées.
Par exemple, si les instructions ci-dessous sont exécutées sous la forme d’une requête à plusieurs instructions, la requête échouera sur la troisième instruction et une exception sera levée.
Si vous interrogiez ensuite le contenu de la table test, les valeurs 1 et 2 seraient présentes.
Fonctionnalités non prises en charge¶
Les instructions PUT et GET ne sont pas prises en charge pour les requêtes multi-instructions.
La préparation d’instructions et l’utilisation de variables de liaison ne sont également pas prises en charge pour les requêtes multi-instructions.
Liaison de variables à des instructions¶
La liaison permet à une instruction SQL d’utiliser une valeur stockée dans une variable Java.
Liaison simple¶
Sans liaison, une instruction SQL spécifie des valeurs en spécifiant des littéraux à l’intérieur de l’instruction. Par exemple, l’instruction suivante utilise la valeur littérale 42 dans une instruction UPDATE :
Avec la liaison, vous pouvez exécuter une instruction SQL qui utilise une valeur qui se trouve dans une variable. Par exemple :
Le ? à l’intérieur de la clause VALUES spécifie que l’instruction SQL utilise la valeur d’une variable. La méthode setInt() spécifie que le premier point d’interrogation de l’instruction SQL doit être remplacé par la valeur de la variable nommée my_integer_variable. Notez que setInt() utilise des valeurs basées sur 1, plutôt que sur 0 (c’est-à-dire que le premier point d’interrogation est référencé par 1, et non par 0).
Liaison de variables à des colonnes d’horodatage¶
Snowflake prend en charge trois variations différentes pour les horodatages : TIMESTAMP_LTZ , TIMESTAMP_NTZ , TIMESTAMP_TZ. Lorsque vous appelez PreparedStatement.setTimestamp pour lier une variable à une colonne d’horodatage, le pilote JDBC interprète la valeur de l’horodatage en fonction du fuseau horaire local (TIMESTAMP_LTZ) ou du fuseau horaire de l’objet Calendar passé en argument :
Si vous voulez que le pilote interprète l’horodatage en utilisant une variation différente (par exemple, TIMESTAMP_NTZ), utilisez l’une des approches suivantes :
Définissez le paramètre de session CLIENT_TIMESTAMP_TYPE_MAPPING à la variation.
Notez que le paramètre affecte toutes les opérations de liaison pour la session en cours. Si vous devez modifier la variation (par exemple, revenir à
TIMESTAMP_LTZ), vous devez à nouveau définir ce paramètre de session.(Dans le pilote JDBC 3.13.3 et les versions ultérieures) Appelez la méthode
PreparedStatement.setObjectet utilisez le paramètretargetSqlTypepour spécifier l’une des variations d’horodatage Snowflake suivantes :SnowflakeType.EXTRA_TYPES_TIMESTAMP_LTZSnowflakeType.EXTRA_TYPES_TIMESTAMP_TZSnowflakeType.EXTRA_TYPES_TIMESTAMP_NTZSnowflakeType.EXTRA_TYPES_VECTORSnowflakeType.EXTRA_TYPES_DECFLOATSnowflakeType.EXTRA_TYPES_YEAR_MONTH_INTERVALSnowflakeType.EXTRA_TYPES_DAY_TIME_INTERVAL
Par exemple :
SnowflakeUtil.EXTRA_TYPES_TIMESTAMP_LTZSnowflakeUtil.EXTRA_TYPES_TIMESTAMP_TZSnowflakeUtil.EXTRA_TYPES_TIMESTAMP_NTZ
Par exemple :
Insertions par lots¶
Dans le code de votre application Java, vous pouvez insérer plusieurs lignes dans un même lot en liant des paramètres dans une instruction INSERT et en appelant addBatch() et executeBatch().
À titre d’exemple, le code suivant insère deux lignes dans une table qui contient une colonne INTEGER et une colonne VARCHAR. L’exemple lie les valeurs aux paramètres dans l’instruction INSERT et appelle addBatch() et executeBatch() pour effectuer une insertion par lots.
Lorsque vous utilisez cette technique pour insérer un grand nombre de valeurs, le pilote peut améliorer les performances en diffusant les données (sans créer de fichiers sur la machine locale) vers une zone de préparation temporaire pour l’acquisition. Le pilote le fait automatiquement lorsque le nombre de valeurs dépasse un seuil.
En outre, la base de données et le schéma actuels de la session doivent être définis. Si ceux-ci ne sont pas définis, la commande CREATE TEMPORARY STAGE exécutée par le pilote peut échouer avec l’erreur suivante :
Note
Pour découvrir d’autres moyens de charger des données dans la base de données Snowflake (y compris le chargement en masse à l’aide de la commande COPY), consultez Charger des données dans Snowflake.
Exemple de programme Java¶
Pour un exemple concret écrit dans Java, faites un clic droit sur le nom du fichier, SnowflakeJDBCExample.java, et enregistrez le lien/fichier sur votre système de fichiers local.
Résolution des problèmes¶
Erreur E/S : réinitialisation de la connexion¶
Dans certains cas, le pilote JDBC peut échouer avec le message d’erreur suivant après une période d’inactivité :
Vous pouvez contourner le problème en fixant une « durée de vie » spécifique pour les connexions. Si une connexion reste inactive plus longtemps que la « durée de vie », le pilote JDBC retire la connexion du pool de connexion et en crée une nouvelle.
Pour fixer la durée de vie, définissez la propriété système Java nommée net.snowflake.jdbc.ttl sur le nombre de secondes que la connexion doit vivre :
Pour définir cette propriété de manière programmatique, appelez
System.setProperty:Pour définir cette propriété lors de l’exécution de la commande
javautilisez l’indicateur-D:
La valeur par défaut de la propriété net.snowflake.jdbc.ttl est -1, ce qui signifie que les connexions inactives ne sont pas supprimées du pool de connexions.
Gestion des erreurs¶
Lorsque vous traitez les erreurs et les exceptions d’une application JDBC, vous pouvez utiliser le fichier ErrorCode.java que Snowflake fournit pour déterminer la cause des problèmes. Les codes d’erreur spécifiques au pilote JDBC commencent par 2, sous la forme : 2NNNNN.
Note
Le lien vers le fichier ErrorCode.java dans le dépôt git public de snowflake-jdbc pointe vers la dernière version du fichier, qui peut être différente de la version du pilote JDBC que vous utilisez actuellement.