JDBC ドライバーの使用¶
このトピックでは、 JDBC ドライバーの使用方法に関する情報を提供します。
Snowflake JDBC API 拡張機能¶
Snowflake JDBC ドライバーは、標準の JDBC 仕様を超える追加のメソッドをサポートしています。このセクションでは、ラップ解除を使用してSnowflake固有のメソッドにアクセスする方法を説明し、ラップ解除する必要がある状況の内の3つについて説明します。
Snowflake固有のクラスのラップ解除¶
Snowflake JDBCドライバーは、Snowflake固有のメソッドをサポートしています。これらのメソッドは、 SnowflakeConnection、 SnowflakeStatement、 SnowflakeResultSet などのSnowflake固有のJava言語インターフェイスで定義されています。たとえば、 SnowflakeStatement インターフェイスには、 JDBC ステートメントインターフェイスにはない getQueryID() メソッドが含まれています。
Snowflake JDBC ドライバーが JDBC オブジェクトを作成するように要求されると(例: Connection オブジェクトの createStatement() メソッドを呼び出して JDBC Statement オブジェクトを作成)、Snowflake JDBC ドライバーは、 JDBC 標準のメソッドだけでなく、Snowflakeインターフェイスの追加メソッドも実装するSnowflake固有のオブジェクトを実際に作成します。
これらのSnowflakeメソッドにアクセスするには、オブジェクト( Statement オブジェクトなど)を「ラップ解除」して、Snowflakeオブジェクトとそのメソッドを公開します。その後、追加のメソッドを呼び出すことができます。
次のコードは、 JDBC Statement オブジェクトをラップ解除して SnowflakeStatement インターフェイスのメソッドを公開し、これらのメソッドの1つ(この場合は setParameter)を呼び出す方法を示しています。
非同期クエリの実行¶
Snowflake JDBCドライバーは、クエリが完了する前にユーザーに制御を返すものなどの非同期クエリをサポートしています。ユーザーはクエリを開始し、ポーリングを使用してクエリがいつ完了したかを判断できます。そうすると、ユーザーは結果セットを読み取ることができます。
この機能により、クライアントプログラム自体はマルチスレッドを使用せずに、複数のクエリを並行して実行できます。
非同期クエリは、 SnowflakeConnection、 SnowflakeStatement、 SnowflakePreparedStatement、および SnowflakeResultSet クラスに追加されたメソッドを使用します。
注釈
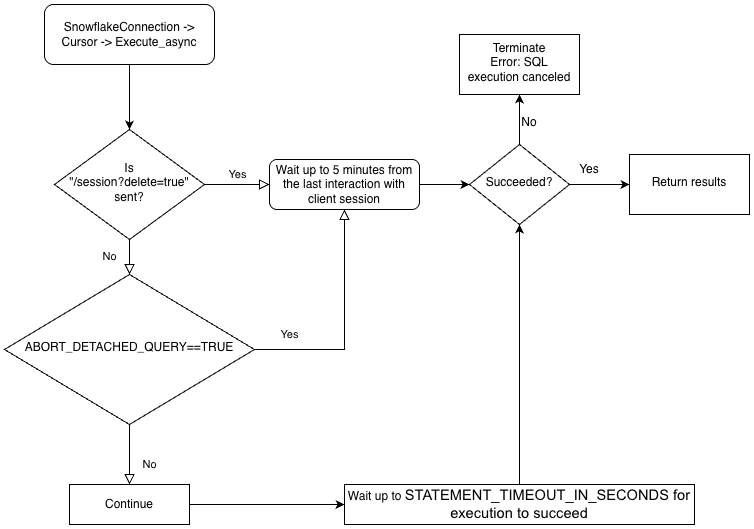
非同期クエリを実行するには、 ABORT_DETACHED_QUERY 構成パラメーターが FALSE (デフォルト値)であることを確認する必要があります。
クライアントとの接続が切れた場合:
進行中のすべての同期クエリは、パラメーター値に関係なくすぐに中止されます。
非同期クエリの場合:
ABORT_DETACHED_QUERY が
FALSEに設定されている場合、進行中の非同期クエリは、正常に終了するまで実行され続けます。ABORT_DETACHED_QUERY が
TRUEに設定されている場合、5 分経過してもクライアント接続が再確立されないと、Snowflake は進行中のすべての非同期クエリーを自動的に中止します。cursor.query_result(queryId)を呼び出すことで、非同期クエリを5分経過時に中止されることを防ぐことができます。クエリはまだ実行中なので、この呼び出しは実際のクエリ結果を取得しませんが、クエリがキャンセルされるのを防ぎます。query_resultの呼び出しは同期操作であり、特定のユースケースに適している場合とそうでない場合があります。
同じセッションで同期クエリと非同期クエリを組み合わせて実行できます。
注釈
非同期クエリはPUT/GETステートメントをサポートしていません。
executeAsyncQuery(クエリ) が使用されている場合、Snowflake JDBCドライバーは自動的に非同期で送信されたクエリを追跡します。接続が connection.close() で明示的に閉じられた場合、非同期クエリのリストが検査され、まだ実行中の場合、Snowflake側のセッションは削除されません。
同じ接続内で非同期クエリが実行されていない場合、その接続に属するSnowflakeセッションは connection.close() が呼び出されたときにログアウトします。これは、同じセッションで実行されている他のすべてのクエリが暗黙的にキャンセルされます。
この動作は、SQL ABORT_DETACHED_QUERYパラメーターにも依存します。詳細については、 ABORT_DETACHED_QUERY パラメーター のドキュメントをご参照ください。
ベストプラクティスとして、実行時間の長いすべての非同期タスク(特に接続の終了後も継続することを意図したもの)を別の接続に分離します。
ドライバーのビジネスロジックの階層とABORT_DETACHED_QUERYパラメーターの相互作用については、次のフローチャートをご参照ください。
非同期クエリのベストプラクティス¶
クエリを並行して実行する前に、どのクエリが他のクエリに依存しているかを確認してください。相互依存し、順序に依存するクエリは、並列化には適していません。たとえば、INSERTステートメントは、対応するCREATE TABLEステートメントが終了するまで開始するべきではありません。
使用可能なメモリに対して、実行するクエリが多すぎないことを確認してください。特に複数の ResultSet が同時にメモリに保存されている場合、複数のクエリを並行して実行すると通常は、より多くのメモリが消費されます。
ポーリング時に、クエリが成功しないまれなケースを処理します。たとえば、次の潜在的な無限ループを回避します。
代わりに、次のようなコードを使用します。
代わりに、次のようなコードを使用します。
トランザクション制御ステートメント(BEGIN、COMMIT、およびROLLBACK)が他のステートメントと並行して実行されないようにします。
非同期クエリの例¶
これらの例のほとんどでは、プログラムが以下に示すようにクラスをインポートする必要があります。
これは非常に単純な例です。
この例では、クエリ ID を保存し、接続を閉じ、接続を再度開き、クエリ ID を使用してデータを取得します。
これは非常に単純な例です。
この例では、クエリ ID を保存し、接続を閉じ、接続を再度開き、クエリ ID を使用してデータを取得します。
データファイルをストリームから内部ステージに直接アップロードする¶
PUT コマンドを使用してデータファイルをアップロードできます。ただし、データをストリームから内部(つまり、Snowflake)ステージにファイルとして直接転送することが理にかなっている場合があります。(ステージ は、テーブルステージ、ユーザーステージ、名前付きステージなど、任意の内部ステージ型にできます。JDBC ドライバーは、外部ステージへのアップロードをサポートしていません。) SnowflakeConnection クラスで公開されているメソッドは次のとおりです。
サンプル使用法:
サンプル使用法:
3.9.2より前の JDBC ドライバーバージョン用に記述されたコードは、 SnowflakeConnection.class をラップ解除するのではなく、 SnowflakeConnectionV1 をキャストする場合があります。例:
注釈
新しいバージョンのドライバーを使用しているお客様は、 unwrap を使用するようにコードを更新する必要があります。
内部ステージからストリームにデータファイルを直接ダウンロードする¶
GET コマンドを使用してデータファイルをダウンロードできます。ただし、内部(つまり、Snowflake)ステージのファイルからストリームにデータを直接転送することが理にかなっている場合があります。(ステージ は、テーブルステージ、ユーザーステージ、名前付きステージなど、任意の内部ステージ型にできます。JDBC ドライバーは、外部ステージへのダウンロードをサポートしていません。) SnowflakeConnection クラスで公開されているメソッドは次のとおりです。
サンプル使用法:
サンプル使用法:
3.9.2より前の JDBC ドライバーバージョン用に記述されたコードは、 SnowflakeConnection.class をラップ解除するのではなく、 SnowflakeConnectionV1 をキャストする場合があります。例:
複数ステートメントのサポート¶
このセクションでは、 JDBCドライバー を使用して、単一のリクエストで複数のステートメントを実行する方法について説明します。
注釈
1つのクエリで複数のステートメントを実行するには、有効なウェアハウスがセッションで利用可能である必要があります。
デフォルトでは、Snowflakeは SQL インジェクション から保護するために複数のステートメントで発行されたクエリに対してエラーを返します。1つのクエリで複数のステートメントを実行すると、 SQL インジェクションのリスクが高まります。Snowflakeはこれを控えめに使うことを推奨しています。
SnowflakeStatementの:codenowrap:setParameter()メソッドを使用して実行するステートメントの数を指定すると、ステートメントを追加して注入することがより困難になるため、 SQL インジェクション リスクを軽減できます。SnowflakeStatementについては、 インターフェイス: SnowflakeStatement をご参照ください。
複数ステートメントの送信と結果の処理¶
複数のステートメントを含むクエリは、クエリ文字列にセミコロンで区切られた複数のステートメントが含まれていることを除いて、単一ステートメントのクエリと同じ方法で実行できます。
複数のステートメントを許可するには、次の2つの方法があります。
Statement.setParameter(「MULTI_STATEMENT_COUNT」、n)を呼び出して、このStatementの実行を一度に許可するステートメントの数を指定します。詳細については、以下をご参照ください。
次のコマンドの1つを実行して、セッションレベルまたはアカウントレベルで MULTI_STATEMENT_COUNT パラメーターを設定します。
または、
パラメーターを0に設定すると、ステートメントの数に制限がなくなります。パラメーターを1に設定すると、一度に1つのステートメントのみが許可されます。
SQL インジェクション攻撃をより困難にするために、ユーザーは setParameter メソッドを呼び出して、以下に示すように、1回の呼び出しで実行されるステートメントの数を指定できます。この例では、1回の呼び出しで実行するステートメントの数は3です。
ステートメントのデフォルトの数は1です。つまり、複数ステートメントモードはオフです。
正確な数を指定せずに複数のステートメントを実行するには、値0を渡します。
MULTI_STATEMENT_COUNT パラメーターは JDBC 標準の一部ではありません。これはSnowflake拡張機能です。このパラメーターは、複数のSnowflakeドライバー/コネクタに影響します。
単一の execute() 呼び出しで複数のステートメントが実行される場合、最初のステートメントの結果は、標準の getResultSet() および getUpdateCount() メソッドを介して利用可能です。続くステートメントの結果にアクセスするには、 getMoreResults() メソッドを使用します。このメソッドは、反復できるステートメントが他にもある場合は true を返し、それ以外の場合は false を返します。
以下の例では、 MULTI_STATEMENT_COUNT パラメーターを設定し、3つのステートメントを実行し、更新カウントと結果セットを取得します。
Snowflakeは、複数ステートメントのクエリには execute() を使用することをお勧めします。メソッド executeQuery() および executeUpdate() も複数のステートメントをサポートしますが、最初の結果が予期される結果タイプ(それぞれ結果セットと更新カウント)でない場合、例外をスローします。
失敗したステートメント¶
SQL ステートメントのいずれかがコンパイルまたは実行に失敗すると、実行は中止されます。以前に実行された以前のステートメントは影響を受けません。
例えば、以下のステートメントが単一の複数ステートメントクエリとして実行される場合、クエリは3番目のステートメントで失敗し、例外がスローされます。
その後、テーブル test のコンテンツをクエリすると、値 1 および 2 が表示されます。
サポートされていない機能¶
PUT および GET ステートメントは複数ステートメントクエリではサポートされていません。
複数ステートメントクエリでは、ステートメントの準備とバインド変数の使用もサポートされていません。
ステートメントへの変数のバインド¶
バインド により、 SQL ステートメントはJava変数に格納されている値を使用できます。
簡単なバインド¶
SQL ステートメントは、バインドせず、ステートメント内のリテラルを指定することによって値を指定します。たとえば、次のステートメントは、 UPDATE ステートメントでリテラル値 42 を使用します。
バインドを使用すると、変数内の値を使用する SQL ステートメントを実行できます。例:
VALUES 句内の ? は、 SQL ステートメントが変数からの値を使用することを指定します。setInt() メソッドは、 SQL ステートメントにある最初の疑問符が、 my_integer_variable という名前の変数にある値に置き換えられる必要があることを指定します。setInt() は0ベースの値ではなく、1ベースの値を使用することに注意してください(つまり、最初の疑問符は0ではなく1によって参照されます)。
タイムスタンプ列への変数のバインド¶
Snowflakeは、タイムスタンプ TIMESTAMP_LTZ , TIMESTAMP_NTZ , TIMESTAMP_TZ の3つの異なるバリエーションをサポートしています。PreparedStatement.setTimestamp を呼び出して変数をタイムスタンプ列にバインドすると、 JDBC ドライバーはタイムスタンプ値をローカルタイムゾーン(TIMESTAMP_LTZ)、または引数として渡された Calendar オブジェクトのタイムゾーンの観点から解釈します。
ドライバーに別のバリエーション(例: TIMESTAMP_NTZ)を使用してタイムスタンプを解釈させたい場合は、次のいずれかの方法を使用します。
セッションパラメーター CLIENT_TIMESTAMP_TYPE_MAPPING をバリエーションに設定します。
このパラメーターは、現在のセッションのバインディング操作すべてに影響することに注意してください。バリエーションを変更する必要がある場合(例:
TIMESTAMP_LTZに戻す場合)は、このセッションパラメーターを再度設定する必要があります。(JDBC ドライバー3.13.3以降のバージョン)
PreparedStatement.setObjectメソッドを呼び出し、targetSqlTypeパラメーターを使用して次のSnowflakeタイムスタンプバリエーションのいずれかを指定します。SnowflakeType.EXTRA_TYPES_TIMESTAMP_LTZSnowflakeType.EXTRA_TYPES_TIMESTAMP_TZSnowflakeType.EXTRA_TYPES_TIMESTAMP_NTZSnowflakeType.EXTRA_TYPES_VECTORSnowflakeType.EXTRA_TYPES_DECFLOATSnowflakeType.EXTRA_TYPES_YEAR_MONTH_INTERVALSnowflakeType.EXTRA_TYPES_DAY_TIME_INTERVAL
例:
SnowflakeUtil.EXTRA_TYPES_TIMESTAMP_LTZSnowflakeUtil.EXTRA_TYPES_TIMESTAMP_TZSnowflakeUtil.EXTRA_TYPES_TIMESTAMP_NTZ
例:
バッチ挿入¶
Javaアプリケーションコードでは、 INSERT ステートメントでパラメーターをバインドし、 addBatch() および executeBatch() を呼び出すことにより、単一のバッチに複数の行を挿入できます。
例として、次のコードは、 INTEGER 列と VARCHAR 列を含むテーブルに2つの行を挿入します。この例では、値を INSERT ステートメントのパラメーターにバインドし、 addBatch() および executeBatch() を呼び出してバッチ挿入を実行します。
この手法を使用して多数の値を挿入する場合は、インジェストのためにデータを(ローカルマシン上でファイルを作成することなく)仮ステージにストリーミングすると、ドライバーのパフォーマンスを向上させることができます。値の数がしきい値を超えると、ドライバーはこれを自動的に実行します。
さらに、セッションの現在のデータベースとスキーマを設定する必要があります。これらが設定されていない場合、ドライバーによって実行される CREATE TEMPORARY STAGE コマンドは、次のエラーにより失敗する可能性があります。
注釈
データをSnowflakeデータベースにロードする別の方法(COPY コマンドを使用した一括ロードを含む)については、 Snowflakeにデータをロード をご参照ください。
Javaサンプルプログラム¶
Javaで記述された作業サンプルの場合は、ファイルの名前、 SnowflakeJDBCExample.java を右クリックし、ローカルファイルシステムにリンク/ファイルを保存します。
トラブルシューティング¶
I/Oエラー: 接続のリセット¶
場合によっては、 JDBC ドライバーが失敗し、一定期間非アクティブになると次のエラーメッセージが表示されることがあります。
接続に特定の「存続時間」を設定すると、問題を回避できます。接続が「存続時間」より長くアイドル状態の場合、 JDBC ドライバーは接続プールから接続を削除し、新しい接続を作成します。
存続時間を設定するには、 net.snowflake.jdbc.ttl という名前のJavaシステムプロパティに、接続が存続する秒数を設定します。
このプロパティをプログラムで設定するには、
System.setPropertyを呼び出します。javaコマンドの実行時にこのプロパティを設定するには、-Dフラグを使用します。
net.snowflake.jdbc.ttl プロパティのデフォルト値は -1 です。これは、アイドル状態の接続が接続プールから削除されないことを意味します。
エラーの処理¶
JDBCアプリケーションのエラーと例外を処理する場合、Snowflakeが提供する ErrorCode.java ファイルを使用して、問題の原因を特定できます。JDBCドライバーに固有のエラーコードは 2 で始まり、2NNNNN の形式になります。
注釈
パブリックsnowflake-jdbc gitリポジトリの ErrorCode.java へのリンクは、ファイルの最新バージョンを指しています。これは、現在使用しているJDBCドライバーのバージョンとは異なる場合があります。