JDBC 드라이버 사용하기¶
이 항목에서는 JDBC 드라이버의 사용 방법에 대한 정보를 제공합니다.
Snowflake JDBC API 확장¶
Snowflake JDBC 드라이버는 표준 JDBC 사양을 초과하는 추가 메서드를 지원합니다. 이 섹션에서는 래핑 해제를 사용하여 Snowflake 관련 메서드에 액세스하는 방법을 설명한 후 래핑 해제가 필요할 수 있는 3가지 상황에 대해 설명합니다.
Snowflake 고유 클래스의 래핑 해제하기¶
Snowflake JDBC 드라이버는 Snowflake의 고유 메서드를 지원합니다. 이러한 메서드는 SnowflakeConnection, SnowflakeStatement 및 SnowflakeResultSet 등 Snowflake의 고유 Java 언어 인터페이스에 정의되어 있습니다. 예를 들어, SnowflakeStatement 인터페이스에는 JDBC 문 인터페이스에 없는 getQueryID() 메서드가 포함되어 있습니다.
Snowflake JDBC 드라이버에 JDBC 오브젝트 생성 요청(예: Connection 오브젝트의 createStatement() 메서드를 호출하여 JDBC Statement 오브젝트 생성)이 제공되면, Snowflake JDBC 드라이버는 실제로 JDBC 표준의 메서드뿐만 아니라 Snowflake 인터페이스의 추가 메서드도 구현하는 Snowflake 고유 오브젝트를 생성합니다.
이러한 Snowflake 메서드에 액세스하려면, 오브젝트(예: Statement 오브젝트)의 “래핑을 해제”하여 Snowflake 오브젝트와 해당 메서드를 노출합니다. 그러면 추가 메서드를 호출할 수 있습니다.
다음 코드는 JDBC Statement 오브젝트의 래핑을 해제하여 SnowflakeStatement 인터페이스의 메서드를 노출한 후, 이 경우 setParameter 에서 이러한 메서드 중 1개를 호출하는 방법을 보여줍니다.
비동기 쿼리 수행하기¶
Snowflake JDBC 드라이버는 완료되기 전에 사용자에게 제어를 반환하는 쿼리와 같은 비동기 쿼리를 지원합니다. 쿼리를 시작한 다음 폴링을 사용하여 쿼리가 완료된 시점을 확인할 수 있습니다. 이때 사용자는 결과 세트를 읽을 수 있습니다.
이 기능을 사용하면 클라이언트 프로그램이 자체적으로 다중 스레딩을 사용하지 않고 여러 쿼리를 병렬로 실행할 수 있습니다.
비동기 쿼리는 SnowflakeConnection, SnowflakeStatement, SnowflakePreparedStatement 및 SnowflakeResultSet 클래스에 추가된 메서드를 사용합니다.
참고
비동기 쿼리를 수행하려면 ABORT_DETACHED_QUERY 구성 매개 변수가 FALSE (기본값)인지 확인해야 합니다.
클라이언트와의 연결이 끊어진 경우:
동기식 쿼리의 경우 진행 중인 모든 동기식 쿼리는 매개 변수 값에 관계없이 즉시 중단됩니다.
비동기 쿼리의 경우:
ABORT_DETACHED_QUERY가
FALSE로 설정된 경우 진행 중인 비동기 쿼리가 정상적으로 종료될 때까지 계속 실행됩니다.ABORT_DETACHED_QUERY가
TRUE로 설정된 경우 5분 후에도 클라이언트 연결이 다시 설정되지 않으면 Snowflake는 진행 중인 모든 비동기 쿼리를 자동으로 중단합니다.cursor.query_result(queryId)를 호출하여 5분이 지나면 비동기 쿼리가 중단되는 것을 방지할 수 있습니다. 이 호출은 쿼리가 아직 실행 중이므로 실제 쿼리 결과를 검색하지는 않지만 쿼리가 취소되는 것을 방지합니다.query_result호출은 동기 작업이므로 특정 사용 사례에 적합할 수도 있고 적합하지 않을 수도 있습니다.
사용자는 동일한 세션에서 동기 및 비동기 쿼리를 혼합하여 실행할 수 있습니다.
참고
비동기 쿼리는 PUT/GET 문을 지원하지 않습니다.
:codenowrap:`executeAsyncQuery(query)`가 사용되는 경우 Snowflake JDBC 드라이버는 비동기적으로 제출된 쿼리를 자동으로 추적합니다. 연결이 :codenowrap:`connection.close()`로 명시적으로 종료되는 경우, 비동기 쿼리 목록을 검사하고 그중 하나라도 여전히 실행 중이면 Snowflake 측 세션이 삭제되지 않습니다.
동일한 연결 내에서 실행 중인 비동기 쿼리가 없는 경우 연결에 속한 Snowflake 세션은 :codenowrap:`connection.close()`가 호출될 때 로그아웃되며, 이는 동일한 세션에서 실행 중인 다른 모든 쿼리를 암시적으로 취소합니다.
이 동작은 SQL ABORT_DETACHED_QUERY 매개 변수에 따라 달라집니다. 자세한 내용은 ABORT_DETACHED_QUERY 매개 변수 설명서를 참조하세요.
가장 좋은 방법은 장기 실행 중인 모든 비동기 작업(특히 연결이 닫힌 후에도 계속되도록 의도된 작업)을 별도의 연결로 분리하는 것입니다.
드라이버의 비즈니스 논리 계층 구조 및 ABORT_DETACHED_QUERY 매개 변수의 상호 작용에 대해 더 잘 이해하려면 다음 순서도를 참조하세요.
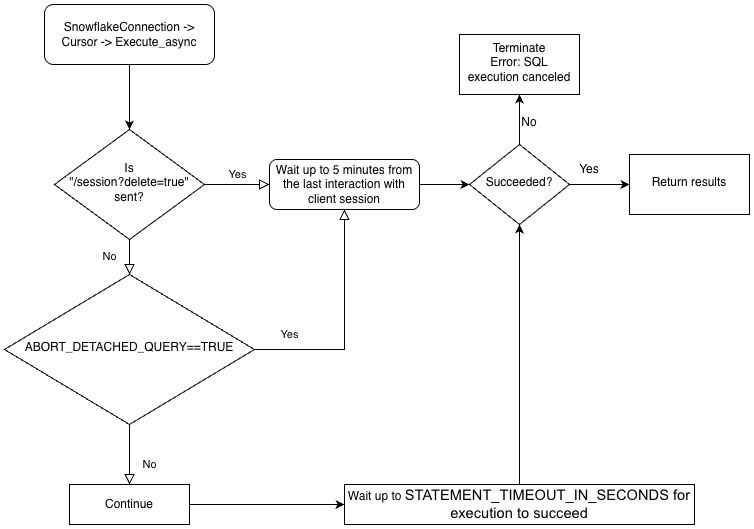
비동기 쿼리의 모범 사례¶
다른 쿼리에 종속된 쿼리를 확인한 후 쿼리를 병렬로 실행합니다. 쿼리는 상호 의존적이고 순서가 중요하므로, 병렬 실행에 적합하지 않습니다. 예를 들어, INSERT 문은 해당 CREATE TABLE 문이 종료될 때까지 시작되지 않아야 합니다.
사용 가능한 메모리에 대해 너무 많은 쿼리를 실행하지 않아야 합니다. 여러 쿼리를 병렬로 실행하면 일반적으로 메모리 사용량이 증가하게 됩니다. 특히, 메모리에 2개 이상의 ResultSet가 메모리에 동시에 저장되어 있는 경우에는 사용량이 크게 증가합니다.
폴링 중에 쿼리가 실패하는 드문 경우를 처리해야 합니다. 예를 들어, 다음은 무한 루프를 유발할 수 있으므로 사용하지 않아야 합니다.
대신, 다음과 유사한 코드를 사용하십시오.
대신, 다음과 유사한 코드를 사용하십시오.
트랜잭션 제어 문(BEGIN, COMMIT 및 ROLLBACK)은 다른 문과 병렬로 실행되지 않아야 합니다.
비동기 쿼리의 예¶
이러한 대부분의 예시에서는 아래와 같이 프로그램이 클래스를 가져오도록 요청합니다.
매우 단순한 예시는 다음과 같습니다.
이 예시에서는 쿼리 ID를 저장하고 연결을 닫은 후 연결을 다시 열고 쿼리 ID를 사용하여 데이터를 검색합니다.
매우 단순한 예시는 다음과 같습니다.
이 예시에서는 쿼리 ID를 저장하고 연결을 닫은 후 연결을 다시 열고 쿼리 ID를 사용하여 데이터를 검색합니다.
스트림에서 내부 스테이지로 직접 데이터 파일 업로드¶
PUT 명령을 사용하여 데이터 파일을 업로드할 수 있습니다. 그러나 일부 경우에는 데이터를 스트림에서 내부(즉, Snowflake) 스테이지로 파일로 직접 전송하는 것이 합리적입니다. (스테이지 의 타입은 테이블 스테이지, 사용자 스테이지 또는 명명된 스테이지와 같은 모든 내부 스테이지 타입이 될 수 있습니다. JDBC 드라이버는 외부 스테이지로의 업로드를 지원하지 않습니다.) SnowflakeConnection 클래스에서 노출된 메서드는 다음과 같습니다.
단순한 사용법:
단순한 사용법:
3.9.2 이전의 JDBC 드라이버 버전용으로 작성된 코드는 SnowflakeConnection.class 의 래핑을 해제하지 않고 SnowflakeConnectionV1 을 캐스트할 수 있습니다. 예:
참고
최신 버전의 드라이버를 사용하는 고객은 unwrap 을 사용하도록 코드를 업데이트해야 합니다.
내부 스테이지에서 스트림으로 직접 데이터 파일 다운로드¶
GET 명령을 사용하여 데이터 파일을 다운로드할 수 있습니다. 그러나 일부 경우에는 내부(즉, Snowflake) 스테이지의 파일에서 스트림으로 데이터를 직접 전송하는 것이 합리적입니다. (스테이지 의 타입은 테이블 스테이지, 사용자 스테이지 또는 명명된 스테이지와 같은 모든 내부 스테이지 타입이 될 수 있습니다. JDBC 드라이버는 외부 스테이지로의 다운로드를 지원하지 않습니다.) SnowflakeConnection 클래스에서 노출된 메서드는 다음과 같습니다.
단순한 사용법:
단순한 사용법:
3.9.2 이전의 JDBC 드라이버 버전용으로 작성된 코드는 SnowflakeConnection.class 의 래핑을 해제하지 않고 SnowflakeConnectionV1 을 캐스트할 수 있습니다. 예:
다중 문 지원¶
이 섹션에서는 JDBC 드라이버 를 사용하여 단일 요청에서 다중 명령을 실행하는 방법에 대해 설명합니다.
참고
단일 쿼리에서 여러 개의 문을 실행하려면 세션에서 유효한 웨어하우스를 사용할 수 있어야 합니다.
기본적으로 Snowflake는 다중 문으로 실행된 쿼리에 대한 오류를 반환하여 SQL 삽입 으로부터 보호합니다. 단일 쿼리에서 여러 문을 실행하면 SQL 삽입의 위험이 높아집니다. Snowflake는 가급적 적게 사용할 것을 권장합니다. SQL 삽입 위험을 줄이려면
SnowflakeStatement클래스의setParameter()메서드를 사용하여 실행할 문 수를 지정하면 문을 추가하여 삽입하는 것이 더욱 어려워집니다.SnowflakeStatement에 대한 자세한 내용은 인터페이스: SnowflakeStatement 섹션을 참조하십시오.
다중 문 전송 및 결과 처리하기¶
여러 명령문이 포함된 쿼리는 단일 명령문이 포함된 쿼리와 동일한 방식으로 실행할 수 있지만, 쿼리 문자열에 세미콜론으로 구분된 여러 명령문이 포함된다는 점이 다릅니다.
다중 문은 다음의 2가지 방법으로 사용할 수 있습니다.
Statement.setParameter(“MULTI_STATEMENT_COUNT”, n)를 호출하여 한 번에 이 문을 실행할 수 있는 문의 수를 지정합니다. 자세한 내용은 아래를 참조하십시오.
다음 명령 중 하나를 실행하여 세션 수준 또는 계정 수준에서 MULTI_STATEMENT_COUNT 매개 변수를 설정합니다.
또는:
매개 변수를 0으로 설정하면 무제한 수의 문이 허용됩니다. 매개 변수를 1로 설정하면 한 번에 1개의 문만 허용됩니다.
SQL 삽입 공격을 어렵게 하려면, 사용자는 아래와 같이 setParameter 메서드를 호출하여 1회의 호출에서 실행할 문의 수를 지정할 수 있습니다. 이 예에서 단일 호출에서 실행할 문의 수는 3개입니다.
문의 기본 수는 1입니다. 즉, 다중 문 모드가 꺼져 있습니다.
정확한 수를 지정하지 않고 다중 문을 실행하려면 0의 값을 전달합니다.
MULTI_STATEMENT_COUNT 매개 변수는 JDBC 표준의 일부가 아니며, Snowflake 확장입니다. 이 매개 변수는 2개 이상의 Snowflake 드라이버/커넥터에 영향을 줍니다.
단일 execute() 호출에서 여러 문이 실행될 때 첫 번째 문의 결과는 표준 getResultSet() 및 getUpdateCount() 메서드를 통해 사용할 수 있습니다. 다음 문의 결과에 액세스하려면 getMoreResults() 메서드를 사용합니다. 이 메서드는 반복에 사용할 수 있는 문이 더 많이 있을 때 true 를 반환하고, 그렇지 않으면 false 를 반환합니다.
아래 예시에서는 MULTI_STATEMENT_COUNT 매개 변수를 설정하고 3개의 문을 실행한 후 업데이트 횟수와 결과 세트를 검색합니다.
Snowflake는 다중 문 쿼리에서 execute() 를 사용하는 것을 권장합니다. executeQuery() 및 executeUpdate() 메서드도 다중 문을 지원하지만 첫 번째 결과가 예상되는 결과 타입(각각 결과 세트 및 업데이트 개수)이 아니면 예외가 발생합니다.
실패한 문¶
SQL 문에서 1개 이상이 컴파일 또는 실행에 실패하면 실행이 중단됩니다. 이전에 실행된 모든 이전 문은 영향을 받지 않습니다.
예를 들어, 아래 문이 단일의 다중 문 쿼리로 실행되는 경우 해당 쿼리는 세 번째 문에서 실패하고 예외가 throw됩니다.
그리고 test 테이블의 내용을 쿼리하면, 1 및 2 값이 제공됩니다.
지원되지 않는 기능¶
다중 문 쿼리에서는 PUT 및 GET 문이 지원되지 않습니다.
문을 준비하고 바인드 변수를 사용하는 것도 다중 문 쿼리에서는 지원되지 않습니다.
변수를 문에 바인딩하기¶
바인딩 을 사용하면 Java 변수에 저장된 값을 SQL 문에서 사용할 수 있습니다.
샘플 바인딩¶
바인딩을 사용하지 않고 SQL 문은 문 내부에 리터럴을 지정하여 값을 지정합니다. 예를 들어, 다음 문은 UPDATE 문에서 리터럴 값 42 를 사용합니다.
바인딩을 사용하면 변수 내부에 있는 값을 사용하는 SQL 문을 실행할 수 있습니다. 예:
VALUES 절 내부의 ? 는 SQL 문이 변수의 값을 사용하도록 지정합니다. setInt() 메서드는 SQL 문의 첫 번째 물음표가 이름이 my_integer_variable 인 변수의 값으로 대체되도록 지정합니다. setInt() 에서는 0부터 시작하는 값이 아닌 1부터 시작하는 값을 사용합니다(즉, 첫 번째 물음표는 0이 아닌 1로 참조됨).
변수를 타임스탬프 열에 바인딩하기¶
Snowflake는 타임스탬프에 3가지 변경인 TIMESTAMP_LTZ , TIMESTAMP_NTZ , TIMESTAMP_TZ 를 지원합니다. 변수를 타임스탬프 열에 바인딩하기 위해 PreparedStatement.setTimestamp 를 호출하면 JDBC 드라이버는 타임스탬프 값을 Calendar 오브젝트의 현지 타임존(TIMESTAMP_LTZ) 또는 인자로 전달된 타임존을 기준으로 해석합니다.
드라이버가 다른 변형(예: TIMESTAMP_NTZ)을 사용하여 타임스탬프를 해석하도록 하려면 다음 중 하나를 사용합니다.
세션 매개 변수 CLIENT_TIMESTAMP_TYPE_MAPPING 을 변형에 설정합니다.
이 매개 변수는 현재 세션의 모든 바인딩 작업에 영향을 준다는 점에 유의하십시오. 변형을 변경(예:
TIMESTAMP_LTZ로 되돌리기)해야 하는 경우에는 이 세션 매개 변수를 다시 설정해야 합니다.(JDBC 드라이버 3.13.3 이상 버전)
PreparedStatement.setObject메서드를 호출하고targetSqlType매개 변수를 사용하여 다음 Snowflake 타임스탬프 변형 중 하나를 지정합니다.SnowflakeType.EXTRA_TYPES_TIMESTAMP_LTZSnowflakeType.EXTRA_TYPES_TIMESTAMP_TZSnowflakeType.EXTRA_TYPES_TIMESTAMP_NTZSnowflakeType.EXTRA_TYPES_VECTORSnowflakeType.EXTRA_TYPES_DECFLOATSnowflakeType.EXTRA_TYPES_YEAR_MONTH_INTERVALSnowflakeType.EXTRA_TYPES_DAY_TIME_INTERVAL
예:
SnowflakeUtil.EXTRA_TYPES_TIMESTAMP_LTZSnowflakeUtil.EXTRA_TYPES_TIMESTAMP_TZSnowflakeUtil.EXTRA_TYPES_TIMESTAMP_NTZ
예:
일괄 삽입¶
Java 애플리케이션 코드에서 INSERT 문에 매개 변수를 바인딩하고 addBatch() 및 executeBatch() 를 호출하여 단일 일괄 처리에 여러 행을 삽입할 수 있습니다.
예를 들어, 다음 코드에서는 INTEGER 열 및 VARCHAR 열이 포함된 테이블에 행 2개를 삽입합니다. 이 예시에서는 INSERT 문의 매개 변수에 값을 바인딩하고 addBatch() 및 executeBatch() 를 호출하여 일괄 삽입을 수행합니다.
이러한 방식을 사용하여 값을 대량으로 삽입하는 경우 드라이버는 수집을 위한 임시 스테이지로 데이터를 스트리밍하여(로컬 시스템에 파일을 생성하지 않음) 성능을 향상할 수 있습니다. 값의 개수가 임계값을 초과하는 경우 드라이버는 자동으로 이 작업을 수행합니다.
또한, 세션의 현재 데이터베이스 및 스키마를 설정해야 합니다. 이러한 값이 설정되지 않은 경우에는 드라이버가 실행하는 CREATE TEMPORARY STAGE 명령에서 다음 오류가 발생하며 실패할 수 있습니다.
참고
Snowflake 데이터베이스에 데이터를 로드하는 대체 방법(COPY 명령을 사용한 대량 로드 등)과 관련해서는 Snowflake에 데이터 로드하기 를 참조하십시오.
Java 샘플 프로그램¶
Java로 작성된 작업 샘플의 경우 파일 이름 SnowflakeJDBCExample.java 를 마우스 오른쪽 버튼으로 클릭하고 링크/파일을 로컬 파일 시스템에 저장합니다.
문제 해결하기¶
I/O 오류: 연결 재설정¶
일부 경우, 일정 시간 동안 사용자의 작업이 없으면 JDBC 드라이버가 실패하고 다음 오류 메시지가 표시될 수 있습니다.
이러한 문제는 연결에 대한 특정 “TTL(Time to Live)”을 설정하여 해결할 수 있습니다. “TTL”을 초과하여 연결이 유휴 상태인 경우 JDBC 드라이버는 연결 풀에서 해당 연결을 제거하고 새 연결을 생성합니다.
TTL을 설정하려면, 이름이 net.snowflake.jdbc.ttl 인 Java 시스템 속성을 연결이 유지될 시간(초)으로 설정합니다.
이 속성을 프로그래밍 방식으로 설정하려면
System.setProperty를 호출합니다.java명령을 실행하는 동안 이 속성을 설정하려면-D플래그를 사용합니다.
net.snowflake.jdbc.ttl 속성의 기본값은 -1 이며, 이는 연결 풀에서 유휴 연결을 제거하지 않음을 의미합니다.
오류 처리¶
JDBC 애플리케이션에 대한 오류와 예외를 처리할 때 Snowflake가 제공하는 ErrorCode.java 파일을 사용하여 문제의 원인을 확인할 수 있습니다. JDBC 드라이버와 관련된 오류 코드는 2 로 시작하며 2NNNNN 의 형식을 띱니다.
참고
공용 snowflake-jdbc git 리포지토리의 ErrorCode.java 에 대한 링크는 최신 버전의 파일을 가리키며, 현재 사용하는 JDBC 드라이버 버전과 다를 수 있습니다.