Verwenden des JDBC-Treibers¶
Unter diesem Thema werden Informationen zur Verwendung des JDBC-Treibers bereitgestellt.
Snowflake-JDBC-API-Erweiterungen¶
Der Snowflake-JDBC-Treiber unterstützt zusätzliche Methoden, die über JDBC-die Standardspezifikation hinausgehen. In diesem Abschnitt wird beschrieben, wie Sie beim Entpacken den Zugriff auf die Snowflake-spezifischen Methoden bereitstellen. Anschließend werden drei Situationen beschrieben, in denen ein Entpacken möglicherweise erforderlich ist:
Hochladen von Datendateien direkt von einem Stream in einen internen Stagingbereich
Herunterladen von Datendateien direkt von einem internen Stagingbereich in einen Stream
Entpacken von Snowflake-spezifischen Klassen¶
Der Snowflake-JDBC-Treiber unterstützt Snowflake-spezifische Methoden. Folgende Methoden sind Snowflake-spezifische, in Java codierte Schnittstellen wie SnowflakeConnection, SnowflakeStatement und SnowflakeResultSet. Beispielsweise enthält die SnowflakeStatement-Schnittstelle eine getQueryID()-Methode, die in der JDBC-Statement-Schnittstelle nicht definiert ist.
Wenn der Snowflake-JDBC-Treiber aufgefordert wird, ein JDBC-Objekt zu erstellen (z. B. Erstellen eines JDBC-Statement-Objekts durch Aufrufen der createStatement()-Methode eines Connection-Objekts), erstellt der Snowflake-JDBC-Treiber tatsächlich Snowflake-spezifische Objekte, die nicht nur die Methoden des JDBC-Standards, sondern auch die zusätzlichen Methoden der Snowflake-Schnittstellen implementieren.
Um auf diese Snowflake-Methoden zuzugreifen, „entpacken“ Sie das Objekt (z. B. ein Statement-Objekt), sodass das Snowflake-Objekt und seine Methoden verfügbar sind. Sie können dann die zusätzlichen Methoden aufrufen.
Der folgende Code zeigt, wie Sie ein JDBC-Statement-Objekt entpacken, um die Methoden der SnowflakeStatement-Schnittstelle verfügbar zu machen, und dann eine dieser Methoden aufrufen, in diesem Fall setParameter:
Ausführen einer asynchronen Abfrage¶
Der Snowflake-JDBC-Treiber unterstützt asynchrone Abfragen (etwa Abfragen, die den Benutzenden vor dem Abschluss die Kontrolle zurückgeben). Sie können eine Abfrage starten und dann durch Abrufen feststellen, wann die Abfrage abgeschlossen ist. Wenn dies der Fall ist, können die Benutzenden das Resultset lesen.
Mit diesem Feature kann ein Clientprogramm mehrere Abfragen parallel ausführen, ohne dass das Clientprogramm selbst Multithreading verwendet.
Asynchrone Abfragen verwenden Methoden, die den Klassen SnowflakeConnection, SnowflakeStatement, SnowflakePreparedStatement und SnowflakeResultSet hinzugefügt wurden.
Bemerkung
Um asynchrone Abfragen auszuführen, müssen Sie sicherstellen, dass der Konfigurationsparameter ABORT_DETACHED_QUERY den Wert FALSE hat (Standardwert).
Wenn die Verbindung zum Client unterbrochen wird:
Bei synchronen Abfragen werden alle laufenden synchronen Abfragen unabhängig vom Wert des Parameters sofort abgebrochen.
Für asynchrone Abfragen:
Wenn ABORT_DETACHED_QUERY auf
FALSEeingestellt ist, werden laufende asynchrone Abfragen weiter ausgeführt, bis sie normal beendet werden.Wenn ABORT_DETACHED_QUERY auf
TRUEeingestellt ist, bricht Snowflake automatisch alle laufenden asynchronen Abfragen ab, wenn die Verbindung zum Client nach fünf Minuten nicht wiederhergestellt ist.Sie können verhindern, dass die asynchrone Abfrage an der Fünf-Minuten-Marke abgebrochen wird, indem Sie
cursor.query_result(queryId)aufrufen. Dieser Aufruf ruft zwar nicht das tatsächliche Abfrageergebnis ab, da die Abfrage noch läuft, verhindert jedoch, dass die Abfrage abgebrochen wird. Der Aufruf vonquery_resultist eine synchrone Operation, die für Ihren speziellen Anwendungsfall geeignet sein kann oder auch nicht.
Sie können in derselben Sitzung eine Mischung aus synchronen und asynchronen Abfragen ausführen.
Bemerkung
Asynchrone Abfragen unterstützen nicht PUT/GET-Anweisungen.
Wenn executeAsyncQuery(query) verwendet wird, verfolgt der Snowflake-JDBC-Treiber automatisch die asynchron übermittelten Abfragen. Wenn die Verbindung explizit mit connection.close() geschlossen wird, wird die Liste der asynchronen Abfragen geprüft. Wenn eine Abfrage noch ausgeführt wird, wird die Snowflake-seitige Sitzung nicht gelöscht.
Wenn innerhalb der gleichen Verbindung keine asynchronen Abfragen laufen, wird die zur Verbindung gehörende Snowflake-Sitzung abgemeldet, wenn connection.close() aufgerufen wird, wodurch implizit alle anderen Abfragen in derselben Sitzung abgebrochen werden.
Dieses Verhalten hängt auch vom Parameter SQL ABORT_DETACHED_QUERY ab. Weitere Informationen dazu finden Sie in der Dokumentation zum Parameter ABORT_DETACHED_QUERY.
Als bewährte Methode sollten Sie alle asynchronen Aufgaben mit langer Ausführungszeit (insbesondere solche, die nach dem Schließen der Verbindung fortgesetzt werden sollen) in einer separaten Verbindung isolieren.
Zum besseren Verständnis der Hierarchie der Geschäftslogik der Treiber und der Interaktion des Parameters ABORT_DETACHED_QUERY betrachten Sie das folgende Flussdiagramm:
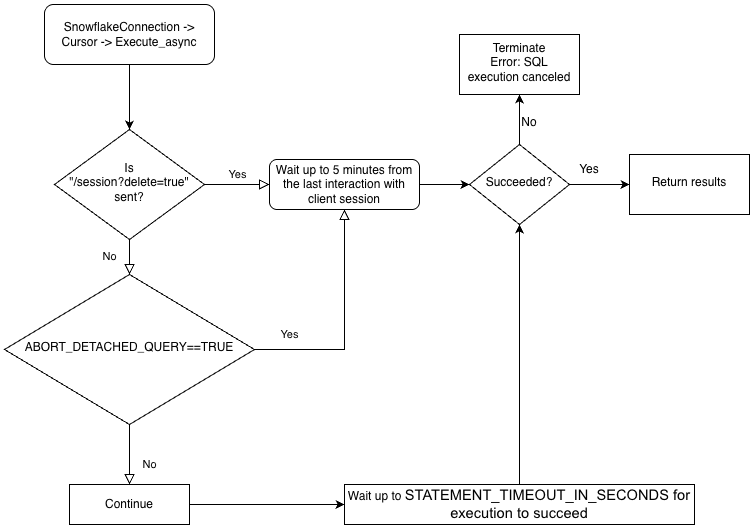
Best Practices für asynchrone Abfragen¶
Stellen Sie vor der parallelen Ausführung von Abfragen sicher, dass Sie die Abhängigkeiten der Abfragen von anderen Abfragen genau kennen. Abfragen, die voneinander und von der Ausführungsreihenfolge abhängig sind, eignen sich nicht für die Parallelisierung. Beispielsweise kann eine INSERT-Anweisung erst beginnen, nachdem die entsprechende CREATE TABLE-Anweisung abgeschlossen wurde.
Stellen Sie sicher, dass die Anzahl der gestarteten Abfragen auf den verfügbaren Arbeitsspeicher abgestimmt ist. Das parallele Ausführen mehrerer Abfragen beansprucht normalerweise mehr Speicher, insbesondere wenn mehr als ein ResultSet gleichzeitig im Arbeitsspeicher gespeichert ist.
Behandeln Sie beim Abrufen die seltenen Fälle, in denen eine Abfrage nicht erfolgreich ist. Vermeiden Sie beispielsweise die folgende potenzielle Endlosschleife:
Verwenden Sie stattdessen ungefähr folgenden Code:
Verwenden Sie stattdessen ungefähr folgenden Code:
Stellen Sie sicher, dass Anweisungen zur Transaktionssteuerung (BEGIN, COMMIT und ROLLBACK) nicht parallel zu anderen Anweisungen ausgeführt werden.
Beispiele für asynchrone Abfragen¶
In den meisten dieser Beispiele muss das Programm die folgenden Klassen importieren:
Dies ist ein sehr einfaches Beispiel:
In diesem Beispiel wird die Abfrage-ID gespeichert, die Verbindung geschlossen, die Verbindung erneut geöffnet und die Daten werden mithilfe der Abfrage-ID abgerufen:
Dies ist ein sehr einfaches Beispiel:
In diesem Beispiel wird die Abfrage-ID gespeichert, die Verbindung geschlossen, die Verbindung erneut geöffnet und die Daten werden mithilfe der Abfrage-ID abgerufen:
Datendateien direkt von einem Stream in einen internen Stagingbereich hochladen¶
Sie können Datendateien mit dem PUT-Befehl hochladen. Manchmal ist es jedoch sinnvoll, Daten direkt von einem Stream in einen internen (d. h. Snowflake) Stagingbereich als Datei zu übertragen. (Der Stagingbereich kann ein beliebiger interner Stagingbereich vom Typ Tabellen-, Benutzer- oder benannter Stagingbereich sein. Der JDBC-Treiber bietet keine Unterstützung für das Hochladen in einen externen Stagingbereich.) Folgende Methode wird in der Klasse SnowflakeConnection bereitgestellt:
Anwendung des Beispiels:
Anwendung des Beispiels:
Code, der für JDBC-Treiberversionen vor 3.9.2 geschrieben wurde, wird möglicherweise in SnowflakeConnectionV1 umgewandelt und nicht in SnowflakeConnection.class entpackt. Beispiel:
Bemerkung
Kunden, die neuere Versionen des Treibers verwenden, sollten ihren Code für die Verwendung von unwrap aktualisieren.
Datendateien direkt von einem internen Stagingbereich in einen Stream herunterladen¶
Sie können Datendateien mit dem GET-Befehl herunterladen. Manchmal ist es jedoch sinnvoll, Daten direkt aus einer Datei in einen internen (d. h. Snowflake) Stagingbereich für einen Stream zu übertragen. (Der Stagingbereich kann ein beliebiger interner Stagingbereich vom Typ Tabellen-, Benutzer- oder benannter Stagingbereich sein. Der JDBC-Treiber bietet keine Unterstützung für das Herunterladen in einen externen Stagingbereich.) Folgende Methode wird in der Klasse SnowflakeConnection bereitgestellt:
Anwendung des Beispiels:
Anwendung des Beispiels:
Code, der für JDBC-Treiberversionen vor 3.9.2 geschrieben wurde, wird möglicherweise in SnowflakeConnectionV1 umgewandelt und nicht in SnowflakeConnection.class entpackt. Beispiel:
Unterstützung für mehrere Anweisungen¶
In diesem Abschnitt wird beschrieben, wie Sie mit JDBC-Treiber mehrere Anweisungen in einer einzelnen Anforderung ausführen.
Bemerkung
Die Ausführung mehrerer Anweisungen in einer einzigen Abfrage setzt voraus, dass ein gültiges Warehouse in einer Sitzung verfügbar ist.
Standardmäßig gibt Snowflake bei Abfragen, die mehrere Anweisungen enthalten, einen Fehler zurück, um sich vor SQL-Einschleusungen zu schützen. Die Ausführung mehrerer Anweisungen in einer einzigen Abfrage erhöht das Risiko einer SQL-Einschleusung. Snowflake empfiehlt, es sparsam zu verwenden. Um das SQL-Einschleusungsrisiko zu verringern, verwenden Sie die
SnowflakeStatementclass’ssetParameter()-Methode, um die Anzahl der auszuführenden Anweisungen anzugeben. Dies erschwert das Einschleusen einer Anweisung durch Anhängen. Weitere Informationen zuSnowflakeStatementfinden Sie unter Schnittstelle: SnowflakeStatement.
Senden mehrerer Anweisungen und Verarbeiten der Ergebnisse¶
Abfragen, die mehrere Anweisungen enthalten, können auf dieselbe Weise wie Abfragen mit einer einzelnen Anweisung ausgeführt werden, mit der Ausnahme, dass die Abfragezeichenfolge mehrere durch Semikolons getrennte Anweisungen enthält.
Es gibt zwei Möglichkeiten, mehrere Anweisungen zuzulassen:
Rufen Sie Statement.setParameter („MULTI_STATEMENT_COUNT“, n) auf, um anzugeben, wie viele Anweisungen gleichzeitig ausgeführt werden dürfen. Weitere Details dazu finden Sie unten.
Legen Sie den Parameter MULTI_STATEMENT_COUNT auf Sitzungsebene oder Kontoebene fest, indem Sie einen der folgenden Befehle ausführen:
Oder:
Wenn Sie den Parameter auf 0 setzen, wird eine unbegrenzte Anzahl von Anweisungen zugelassen. Wenn Sie den Parameter auf 1 setzen, wird jeweils nur eine Anweisung zugelassen.
Um Angriffe durch Einschleusung von SQL-Befehlen zu erschweren, können Benutzer mithilfe der setParameter-Methode die Anzahl der Anweisungen angeben, die durch einen einzelnen Aufruf ausgeführt werden sollen (siehe unten). In diesem Beispiel beträgt die Anzahl der Anweisungen, die durch einen einzelnen Aufruf ausgeführt werden sollen, 3:
Die Standardanzahl der Anweisungen ist 1. Mit anderen Worten, der Mehrfachanweisungsmodus ist deaktiviert.
Übergeben Sie den Wert 0, um mehrere Anweisungen auszuführen, ohne die genaue Anzahl anzugeben.
Der Parameter MULTI_STATEMENT_COUNT ist nicht Teil des JDBC-Standards, sondern eine Snowflake-Erweiterung. Dieser Parameter betrifft mehr als einen Snowflake-Treiber oder -Konnektor.
Wenn in einer einzigen execute()-Anweisung mehrere Anweisungen ausgeführt werden, ist das Ergebnis der ersten Anweisung über die Standardmethoden getResultSet() und getUpdateCount() verfügbar. Verwenden Sie die Methode getMoreResults(), um auf die Ergebnisse der nachfolgenden Anweisungen zuzugreifen. Diese Methode gibt true zurück, wenn weitere Anweisungen für die Iteration verfügbar sind, und false falls nicht.
Im folgenden Beispiel wird der Parameter MULTI_STATEMENT_COUNT festgelegt, dann werden 3 Anweisungen ausgeführt und schließlich werden die Aktualisierungszähler und die Resultsets abgerufen:
Snowflake empfiehlt die Verwendung von execute() für Abfragen mit mehreren Anweisungen. Die Methoden executeQuery() und executeUpdate() unterstützen auch mehrere Anweisungen, lösen jedoch eine Ausnahme aus, wenn das erste Ergebnis nicht dem erwarteten Ergebnistyp entspricht (Resultset bzw. Aktualisierungsanzahl).
Fehlgeschlagene Anweisungen¶
Wenn eine der SQL-Anweisungen nicht kompiliert oder ausgeführt werden kann, wird die Ausführung abgebrochen. Alle vorherigen Anweisungen, die zuvor ausgeführt wurden, bleiben davon unberührt.
Im folgenden Beispiel werden Anweisungen als einzelne Abfrage mit mehreren Anweisungen ausgeführt. Dabei schlägt die Abfrage bei der dritten Anweisung fehl, und es wird eine Ausnahme ausgelöst.
Wenn Sie dann den Inhalt der Tabelle test abfragen würden, wären die Werte 1 und 2 vorhanden.
Nicht unterstützte Features¶
PUT- und GET-Anweisungen werden für Abfragen mit mehreren Anweisungen nicht unterstützt.
Das Vorbereiten von Anweisungen und die Verwendung von Bindungsvariablen werden für Abfragen mit mehreren Anweisungen ebenfalls nicht unterstützt.
Binden von Variablen an Anweisungen¶
Durch Binden können SQL-Anweisungen Werte verwenden, die in einer Java-Variablen gespeichert sind.
Einfaches Binden¶
Ohne Binden gibt eine SQL-Anweisung Werte an, indem sie Literale innerhalb der Anweisung angibt. Die folgende Anweisung verwendet z. B. den Literalwert 42 in einer UPDATE-Anweisung:
Durch Binden können Sie eine SQL-Anweisung ausführen, die einen Wert verwendet, der sich innerhalb einer Variablen befindet. Beispiel:
Das ? innerhalb der VALUES-Klausel gibt an, dass die SQL-Anweisung den Wert aus einer Variablen verwendet. Die Methode setInt() gibt an, dass das erste Fragezeichen in der SQL-Anweisung durch den Wert in der Variable mit dem Namen my_integer_variable ersetzt werden soll. Beachten Sie, dass setInt() 1-basierte und nicht 0-basierte Werte verwendet, d. h. das erste Fragezeichen von 1 und nicht von 0 referenziert wird.
Binden von Variablen an Zeitstempelspalten¶
Snowflake unterstützt drei verschiedene Varianten für Zeitstempel: TIMESTAMP_LTZ , TIMESTAMP_NTZ , TIMESTAMP_TZ. Wenn Sie PreparedStatement.setTimestamp aufrufen, um eine Variable an eine Zeitstempelspalte zu binden, wird der JDBC-Treiber den Zeitstempelwert in Bezug zur lokalen Zeitzone (TIMESTAMP_LTZ) interpretieren oder die Zeitzone des Calendar-Objekts wird als Argument übergeben:
Wenn Sie möchten, dass der Treiber den Zeitstempel anhand einer anderen Variante (z. B. TIMESTAMP_NTZ) interpretiert, verwenden Sie einen der folgenden Ansätze:
Setzen Sie den Sitzungsparameter CLIENT_TIMESTAMP_TYPE_MAPPING auf die Variante.
Beachten Sie, dass der Parameter alle Bindungsoperationen für die aktuelle Sitzung beeinflusst. Wenn Sie die Variante ändern müssen (z. B. zurück zu
TIMESTAMP_LTZ), müssen Sie diesen Sitzungsparameter erneut einstellen.(In JDBC-Treiber 3.13.3 und späteren Versionen) Rufen Sie die Methode
PreparedStatement.setObjectauf, und geben Sie mit dem ParametertargetSqlTypeeine der folgenden Snowflake-Zeitstempelvarianten an:SnowflakeType.EXTRA_TYPES_TIMESTAMP_LTZSnowflakeType.EXTRA_TYPES_TIMESTAMP_TZSnowflakeType.EXTRA_TYPES_TIMESTAMP_NTZSnowflakeType.EXTRA_TYPES_VECTORSnowflakeType.EXTRA_TYPES_DECFLOATSnowflakeType.EXTRA_TYPES_YEAR_MONTH_INTERVALSnowflakeType.EXTRA_TYPES_DAY_TIME_INTERVAL
Beispiel:
SnowflakeUtil.EXTRA_TYPES_TIMESTAMP_LTZSnowflakeUtil.EXTRA_TYPES_TIMESTAMP_TZSnowflakeUtil.EXTRA_TYPES_TIMESTAMP_NTZ
Beispiel:
Batcheinfügungen¶
In Ihrem Java-Anwendungscode können Sie mehrere Zeilen in einen einzelnen Batch einfügen, indem Sie Parameter in einer INSERT-Anweisung binden und dann addBatch() und executeBatch() aufrufen.
Der folgende Code fügt beispielsweise zwei Zeilen in eine Tabelle ein, die eine INTEGER-Spalte und eine VARCHAR-Spalte enthält. Im Beispiel werden Werte an die Parameter der INSERT-Anweisung gebunden und dann addBatch() und executeBatch() aufgerufen, um eine Batcheinfügung durchzuführen.
Wenn Sie dieses Verfahren verwenden, um eine große Anzahl von Werten einzufügen, kann die Treiberleistung verbessert werden, indem die Daten (ohne Erstellen von Dateien auf dem lokalen Computer) an einen temporären Stagingbereich gestreamt werden. Der Treiber führt dies automatisch durch, wenn die Anzahl der Werte einen Schwellenwert überschreitet.
Außerdem müssen die aktuelle Datenbank und das aktuelle Schema für die Sitzung festgelegt sein. Wenn diese nicht festgelegt sind, kann der vom Treiber ausgeführte CREATE TEMPORARY STAGE-Befehl folgenden Fehler generieren:
Bemerkung
Alternative Möglichkeiten zum Laden von Daten in die Snowflake-Datenbank (einschließlich Massenladen mit dem COPY-Befehl) finden Sie unter Daten in Snowflake laden.
Java-Beispielprogramm¶
Für ein in Java geschriebenes Beispiel klicken Sie mit der rechten Maustaste auf den Namen der Datei SnowflakeJDBCExample.java, und speichern Sie den Link bzw. die Datei in Ihrem lokalen Dateisystem.
Problembehandlung¶
E/A-Fehler: Verbindung zurückgesetzt¶
In einigen Fällen kann der JDBC-Treiber nach einer gewissen Zeit der Inaktivität möglicherweise mit der folgenden Fehlermeldung fehlschlagen:
Sie können das Problem umgehen, indem Sie eine bestimmte Lebensdauer („time to live“) für die Verbindungen einstellen. Wenn eine Verbindung länger als die Lebensdauer inaktiv ist, entfernt der JDBC-Treiber die Verbindung aus dem Verbindungspool und erstellt eine neue Verbindung.
Um die Lebensdauer einzustellen, setzen Sie die Java-Systemeigenschaft net.snowflake.jdbc.ttl auf die Anzahl der Sekunden, die die Verbindung bestehen bleiben soll:
Um diese Eigenschaft programmseitig festzulegen, rufen Sie
System.setPropertyauf:Um diese Eigenschaft beim Ausführen des Befehls
javafestzulegen, verwenden Sie das Flag-D:
Der Standardwert der Eigenschaft net.snowflake.jdbc.ttl ist -1, was bedeutet, dass inaktive Verbindungen nicht aus dem Verbindungspool entfernt werden.
Fehlerbehandlung¶
Bei der Behandlung von Fehlern und Ausnahmen für eine JDBC-Anwendung können Sie die Datei ErrorCode.java verwenden, die von Snowflake zur Verfügung gestellt wird, um die Ursache von Problemen zu ermitteln. Die für den JDBC-Treiber spezifischen Fehlercodes beginnen mit 2, in der Form: 2NNNNN.
Bemerkung
Der Link zu „ErrorCode.java“ im öffentlichen „snowflake-jdbc“-Git-Repository verweist auf die aktuelle Version der Datei, die sich von der Version des derzeit verwendeten JDBC-Treibers unterscheiden kann.