SnowConvert : migration de données¶
Avertissement
Pour migrer les données de vos tables, votre compartiment S3 doit se trouver dans la même région que votre cluster Redshift. La migration des données avec des compartiments S3 dans des régions autres que les clusters Redshift fournis sera ajoutée à l’avenir.
Description¶
SnowConvert migre les données de vos tables Redshift en les déchargeant vers des fichiers PARQUET dans un compartiment S3 que vous devez fournir. Une fois les fichiers créés, l’application copiera les données directement depuis ces fichiers vers les tables déployées dans Snowflake.
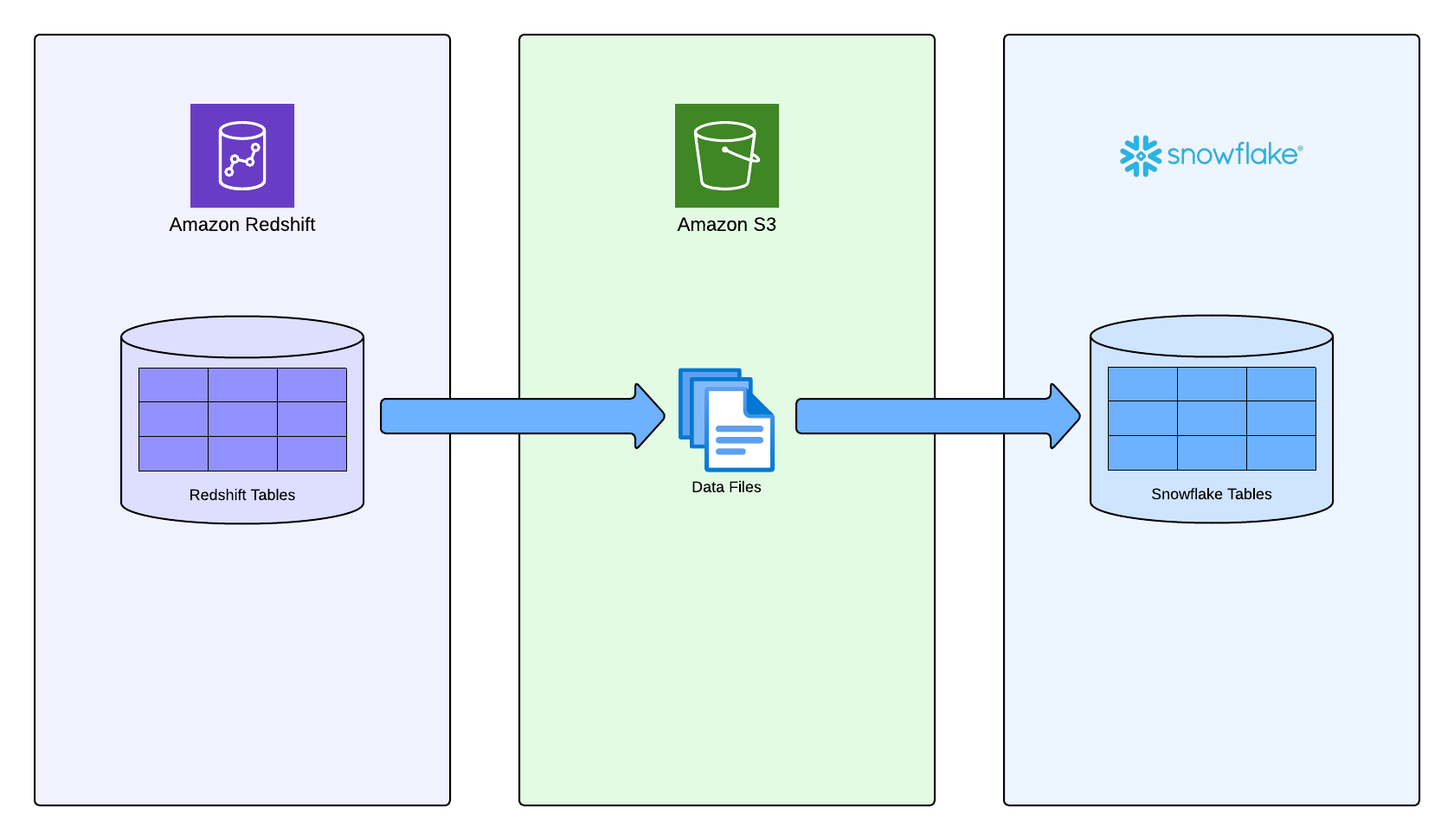
Conditions préalables¶
Avant d’exécuter la migration de vos données, vous devez remplir les conditions préalables suivantes :
Disposez d’un compartiment S3 sur AWS dans la même région que votre cluster Redshift.
Vous devez créer un rôle IAM associé à votre cluster Redshift qui peut décharger les données de vos tables Redshift dans votre compartiment S3. Le rôle IAM doit avoir la configuration de politique suivante (la configuration suivante peut être utilisée par n’importe quel utilisateur de la base de données, pour restreindre l’accès à ce rôle vous pouvez lire ce guide :)
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<your_bucket_name>/*",
"arn:aws:s3:::<your_bucket_name>"
]
}
]
}
Ayez un utilisateur IAM qui peut lire et supprimer des objets de votre compartiment S3, ceci est nécessaire pour lire les données des fichiers qui ont été créés dans le S3 vers les tables Snowflake. Voici un exemple de politique IAM qui peut être utilisée pour charger les données des fichiers S3 dans les tables cibles Snowflake :
Avertissement
Si vous ne donnez pas les autorisations du s3 :DeleteObject et du s3 :DeleteObectVersion à votre utilisateur IAM, le processus de migration des données n’échouera pas, mais les fichiers de données créés par l’outil ne seront pas supprimés du compartiment S3.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:GetObjectVersion",
"s3:DeleteObject", // DeleteObject and DeleteObjectVersion permissions are necessary to purge the data files once they are loaded.
"s3:DeleteObjectVersion",
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": [
"arn:aws:s3:::<your_bucket_name>/*",
"arn:aws:s3:::<your_bucket_name>"
]
}
]
}
Soyez connecté au cluster Redshift et au compte Snowflake où le code DDL a été déployé.
Exécution¶
Note
Assurez-vous que le chemin du compartiment S3 que vous entrez ne contient pas de fichiers, le processus échouera s’il y a des fichiers dans le chemin donné.
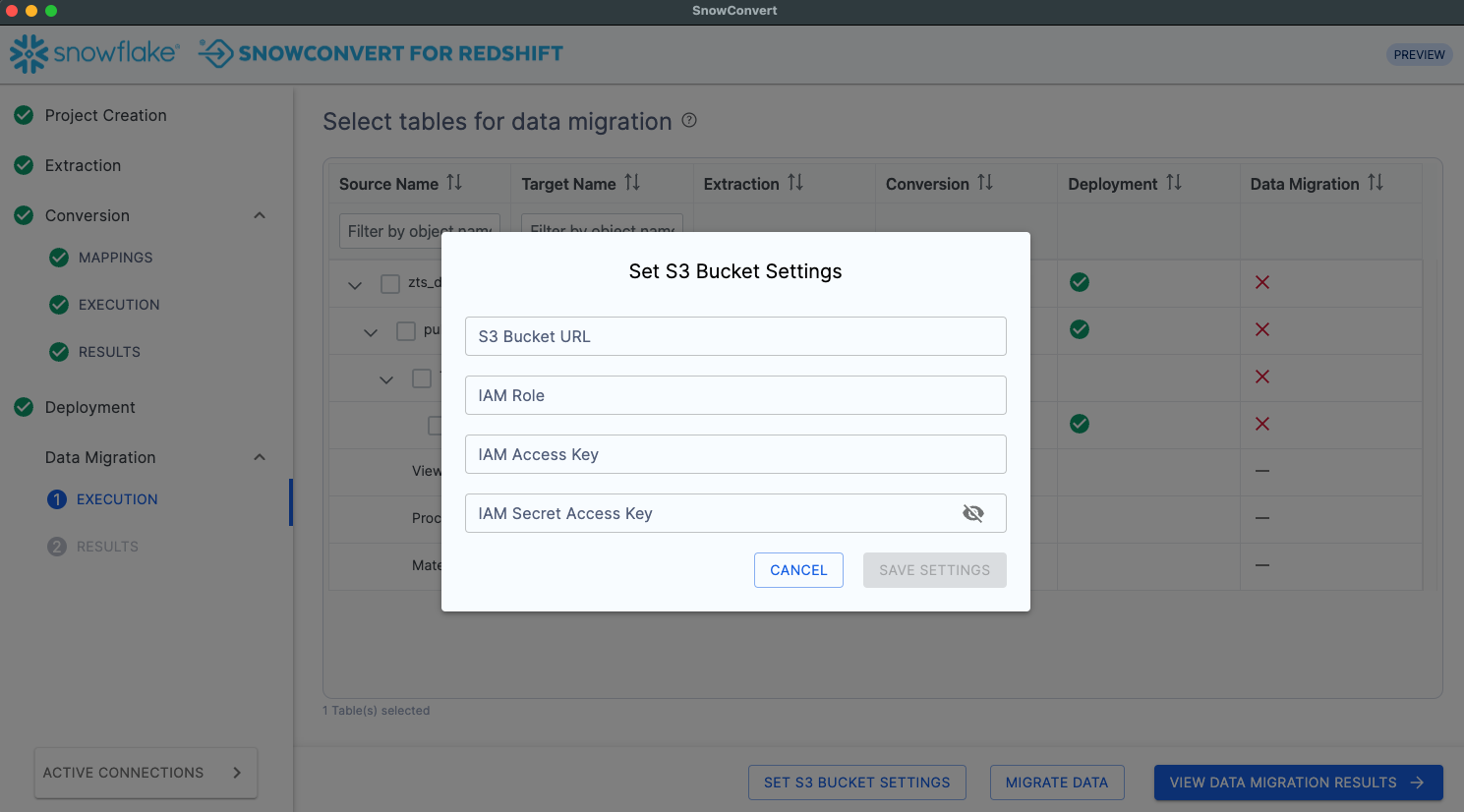
Cliquez sur Définir les paramètres du compartiment S3 pour ajouter les informations suivantes :
L’URL du compartiment S3 (Assurez-vous que l’URL que vous avez saisie se termine par un « / »).
L’ARN du rôle IAM pour décharger les données des tables dans des fichiers PARQUET dans le compartiment S3 URL que vous avez fourni.
La clé d’accès de l’utilisateur IAM qui a l’autorisation de lire et de supprimer des objets dans les objets du compartiment S3.
La clé d’accès secrète de l’utilisateur IAM qui a l’autorisation de lire et de supprimer des objets dans les objets du compartiment S3.
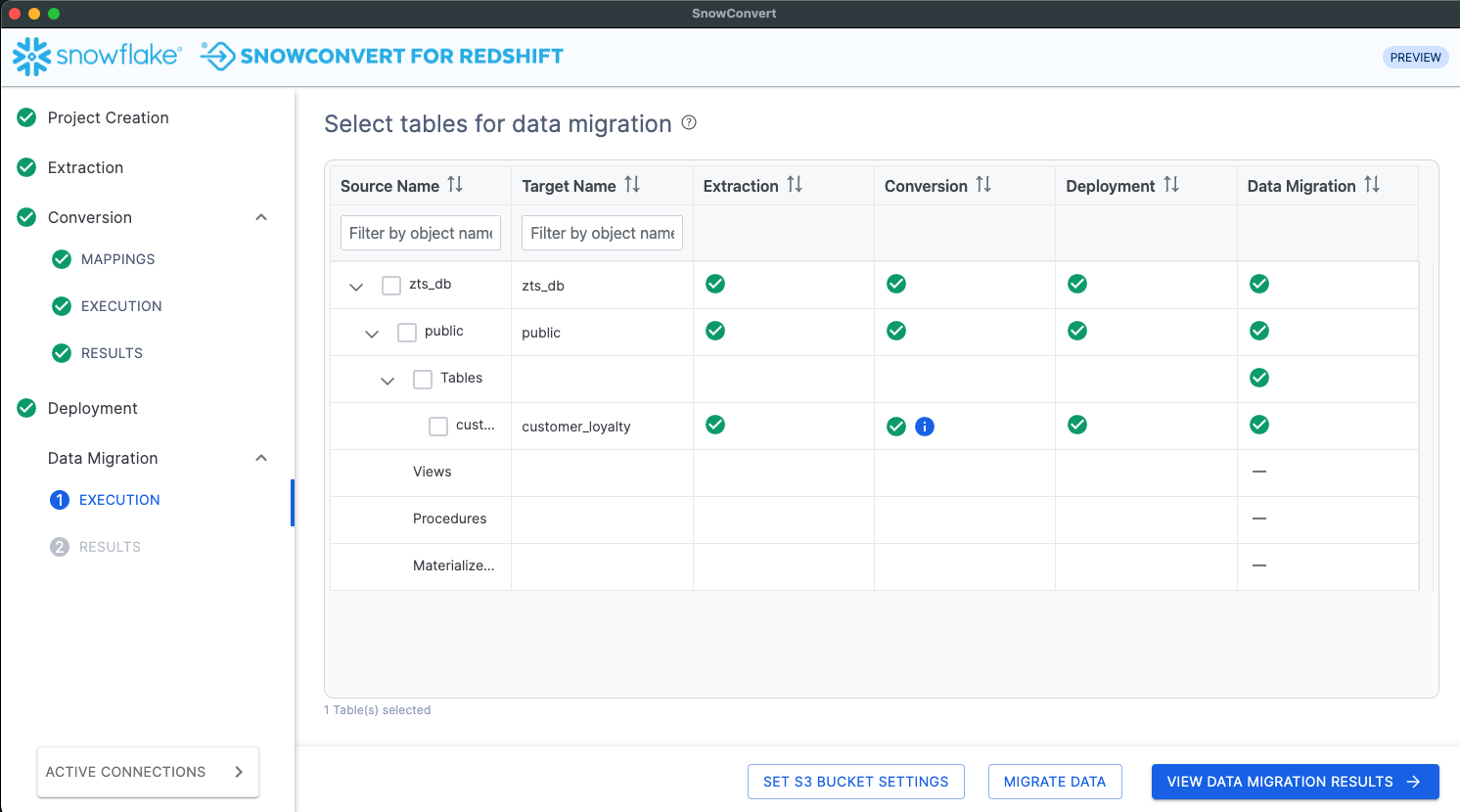
Sélectionnez les tables dont vous souhaitez que les données soient migrées vers Snowflake.
Cliquez sur Migrer les données, cela lancera le processus de migration des données en déchargeant les données dans le compartiment S3, puis en copiant les données de ces fichiers vers les tables cibles dans Snowflake.
La colonne de migration des données sera mise à jour et indiquera si les données de chaque table ont été migrées avec succès ou non.
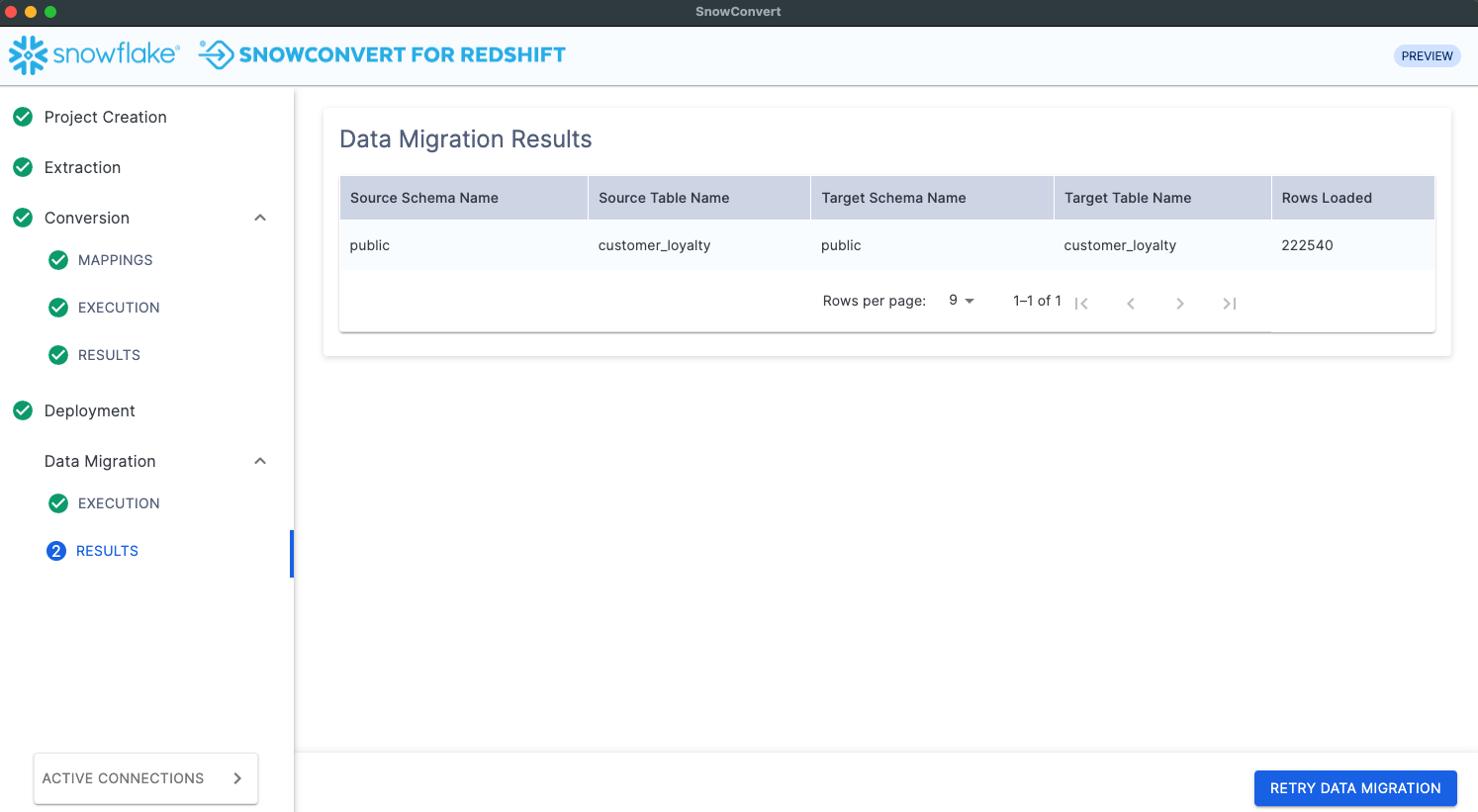
Résultats¶
Cette page valide le nombre de lignes déplacées des tables sources vers les tables cibles.
Chaque ligne contient les informations suivantes sur la table migrée : le schéma source et le nom de la table, le schéma cible et le nom de la table, ainsi que le nombre de lignes chargées.
Si vous souhaitez exécuter un autre processus de migration de données pour d’autres tables, vous pouvez cliquer sur Retourner à la migration des données.