Considerações sobre a replicação¶
Este tópico descreve o comportamento de certos recursos do Snowflake em bancos de dados e objetos secundários quando replicados com grupos de replicação e failover ou replicação de banco de dados, e fornece orientação geral para trabalhar com objetos e dados replicados.
Se você tiver ativado anteriormente a replicação de banco de dados para bancos de dados individuais usando o comando ALTER DATABASE … ENABLE REPLICATION TO ACCOUNTS, consulte Considerações sobre a replicação de banco de dados para obter considerações adicionais específicas sobre a replicação de banco de dados.
Restrições do grupo de replicação e grupo de failover¶
As seções a seguir explicam as restrições em torno da adição de objetos de conta, bancos de dados e compartilhamentos a grupos de replicação e failover.
Objetos de conta¶
Uma conta só pode ter um grupo de failover ou replicação que contenha objetos diferentes de bancos de dados ou compartilhamentos.
Privilégios de replicação¶
Esta seção descreve os privilégios de replicação que estão disponíveis para serem concedidos a funções para especificar as operações que os usuários podem realizar nos objetos do grupo de replicação ou failover no sistema. Para a sintaxe do comando GRANT, consulte GRANT <privilégios> … TO ROLE.
Nota
Para a replicação de banco de dados, somente administradores de conta com a função ACCOUNTADMIN podem habilitar e gerenciar a replicação e o failover do banco de dados. Para obter informações adicionais sobre privilégios exigidos para replicação de banco de dados, consulte a tabela de privilégios exigidos em Etapa 6. Atualização de um banco de dados secundário em um cronograma.
Privilégio |
Objeto |
Uso |
Notas |
|---|---|---|---|
OWNERSHIP |
Grupo de replicação Grupo de failover |
Permite excluir, alterar e conceder ou revogar acesso a um objeto. |
Pode ser concedido por:
|
CREATE REPLICATION GROUP |
Conta |
Permite criar um grupo de replicação. |
Deve ser concedido pela função ACCOUNTADMIN. |
CREATE FAILOVER GROUP |
Conta |
Permite criar um grupo de failover. |
Deve ser concedido pela função ACCOUNTADMIN. |
FAILOVER |
Grupo de failover |
Permite promover um grupo secundário de failover para servir como grupo primário de failover. |
Pode ser concedido ou revogado por uma função com o privilégio OWNERSHIP sobre o grupo. |
REPLICATE |
Grupo de replicação Grupo de failover |
Permite atualizar um grupo secundário. |
Pode ser concedido ou revogado por uma função com o privilégio OWNERSHIP sobre o grupo. |
MODIFY |
Grupo de replicação Grupo de failover |
Concede a capacidade de alterar as configurações ou propriedades de um objeto. |
Pode ser concedido ou revogado por uma função com o privilégio OWNERSHIP sobre o grupo. |
MONITOR |
Grupo de replicação Grupo de failover |
Permite ver detalhes dentro de um objeto. |
Pode ser concedido ou revogado por uma função com o privilégio OWNERSHIP sobre o grupo. |
Para instruções sobre como criar uma função personalizada com um conjunto específico de privilégios, consulte Criação de funções personalizadas.
Para informações gerais sobre concessões de funções e privilégios para executar ações de SQL em objetos protegíveis, consulte Visão geral do controle de acesso.
Replicação e referências entre grupos de replicação¶
Objetos em um grupo de replicação (ou failover) que têm referências pendentes (ou seja, referências a objetos em outro grupo de replicação ou failover) podem ser replicados com sucesso para uma conta de destino em algumas circunstâncias. Se a operação de replicação resultar em um comportamento na conta de destino consistente com o comportamento que pode ocorrer na conta de origem, a replicação é bem-sucedida.
Por exemplo, se uma coluna em uma tabela em um grupo de failover fg_a faz referência a uma sequência em um grupo de failover fg_b, a replicação de ambos os grupos é bem-sucedida. Se fg_a for replicado antes de fg_b, inserir operações (após o failover) na tabela que faz referência à sequência apresenta falha se fg_b não for replicado. Esse comportamento pode ocorrer em uma conta de origem. Se uma sequência for descartada em uma conta de origem, inserir operações em uma tabela com uma coluna que faz referência à sequência descartada apresenta falha.
Quando a referência pendente é uma política de segurança que protege os dados, o grupo de replicação (ou failover) com a política de segurança deve ser replicado antes que qualquer grupo de replicação que contenha objetos que fazem referência à política seja replicado.
Atenção
Fazer atualizações nas políticas de segurança que protegem os dados em grupos de replicação ou failover separados pode resultar em inconsistências e deve ser feito com cuidado.
Para objetos de banco de dados, você pode visualizar as dependências de objetos no Account Usage Exibição OBJECT_DEPENDENCIES.
Referências pendentes e políticas de rede¶
Referências pendentes em políticas de redes podem fazer com que a replicação falhe com a seguinte mensagem de erro:
Para evitar referências pendentes, especifique os seguintes tipos de objetos na lista OBJECT_TYPES ao executar o comando CREATE ou ALTER para o grupo de replicação ou failover:
Se uma política de redes usar uma regra de rede, inclua o banco de dados que contém o esquema onde a regra de rede foi criada.
Se uma política de redes estiver associada à conta, inclua
NETWORK POLICIESeACCOUNT PARAMETERSna listaOBJECT_TYPES.Se uma política de redes estiver associada ao usuário, inclua
NETWORK POLICIESeUSERSna listaOBJECT_TYPES.
Para obter mais detalhes, consulte Replicação de políticas de redes.
Referências pendentes e políticas de pacotes¶
Se houver uma política de pacotes definida na conta, o seguinte erro de referências pendentes ocorrerá durante a operação de atualização para um grupo de replicação ou failover que contém objetos de conta:
Para evitar referências pendentes, replique o banco de dados que contém a política de pacotes para a conta de destino. O banco de dados que contém a política pode estar no mesmo ou em um grupo de replicação ou failover diferente.
Referências pendentes e segredos¶
Para obter mais detalhes, consulte Replicação e segredos.
Referências pendentes e fluxos¶
Referências pendentes para fluxos fazem com que a replicação falhe com a seguinte mensagem de erro:
Para evitar erros de referências pendentes:
O banco de dados primário deve incluir o fluxo e seu objeto base ou
O banco de dados que contém o fluxo e o banco de dados que contém o objeto base referenciado pelo fluxo devem ser incluídos no mesmo grupo de replicação ou failover.
Replicação e objetos secundários somente leitura¶
Todos os objetos secundários em uma conta de destino, incluindo compartilhamentos e bancos de dados secundários, são somente leitura. As alterações em objetos replicados ou tipos de objeto não podem ser feitas localmente em uma conta de destino. Por exemplo, se o tipo de objeto USERS for replicado de uma conta de origem para uma conta de destino, novos usuários não poderão ser criados ou modificados na conta de destino.
Novos bancos de dados e compartilhamentos locais podem ser criados e modificados em uma conta de destino. Se ROLES também forem replicadas para a conta de destino, novas funções não poderão ser criadas ou modificadas nessa conta de destino. Por isso, os privilégios não podem ser concedidos a uma função (ou revogados dela) em um objeto secundário na conta de destino. Entretanto, os privilégios podem ser concedidos a uma função secundária (ou revogados dela) em objetos locais (por exemplo, bancos de dados, compartilhamentos ou grupos de replicação ou failover) criados na conta de destino.
Replicação e objetos em contas de destino¶
Se você tiver criado objetos de conta, por exemplo, usuários e funções, em sua conta de destino por qualquer forma diferente de replicação (por exemplo, usando scripts), esses usuários e funções não terão um identificador global por padrão. Quando uma conta de destino é atualizada a partir da conta de origem, a operação de atualização descarta qualquer objeto de conta dos tipos na lista OBJECT_TYPES na conta de destino que não tenha um identificador global.
Nota
A operação de atualização inicial para replicar USERS ou ROLES pode resultar em erro. Isso ajuda a evitar a exclusão acidental de dados e metadados associados a usuários e funções. Para obter mais informações sobre as circunstâncias que determinam se esses tipos de objetos serão descartados ou se a operação de atualização falhará, consulte Replicação inicial de usuários e funções.
Para evitar descartar esses objetos, consulte Aplicação de IDs globais a objetos criados por scripts em contas de destino.
Objetos recriados em contas de destino¶
Se um objeto existente na conta de origem for substituído usando uma instrução CREATE OR REPLACE, o objeto existente será descartado e, em seguida, um novo objeto com o mesmo nome será criado em uma única transação. Por exemplo, se você executar uma instrução CREATE OR REPLACE para uma tabela existente t1, a tabela t1 será descartada e, em seguida, uma nova tabela t1 será criada. Para obter mais informações, consulte as notas de uso para CREATE TABLE para.
Quando os objetos são substituídos na conta de destino, as instruções DROP e CREATE não são executadas atomicamente durante uma operação de atualização. Isso significa que o objeto pode desaparecer brevemente da conta de destino enquanto está sendo recriado como um novo objeto.
Políticas de segurança e replicação¶
O banco de dados contendo uma política de segurança e as referências (ou seja, atribuições) pode ser replicado usando grupos de replicação e de failover. As políticas de segurança incluem:
Se você estiver usando replicação de banco de dados, consulte Objetos de segurança e replicação de banco de dados.
Políticas de sessão, senhas e autenticação¶
As referências da política de sessão, senha e autenticação para os usuários são replicadas ao especificar o banco de dados contendo a política (ALLOWED_DATABASES = policy_db) e USERS em um grupo de replicação ou grupo de failover.
Se os usuários ou banco de dados da política já tiverem sido replicados para uma conta de destino, atualize o grupo de replicação ou failover na conta de origem para incluir os bancos de dados e os tipos de objetos necessários para replicar com sucesso a política. Em seguida, execute uma operação de atualização para atualizar a conta de destino.
Se as políticas em nível de usuário não estiverem em uso, USERS não precisam ser incluídos no grupo de replicação ou failover.
Nota
A política deve estar na mesma conta que a atribuição da política em nível de conta e a atribuição da política em nível de usuário.
Se você tiver uma política de segurança definida na conta ou um usuário na conta e não atualizar o grupo de replicação ou failover para incluir o policy_db contendo a política e USERS, uma referência pendente ocorre na conta de destino. Neste caso, uma referência pendente significa que o Snowflake não consegue localizar a política na conta de destino porque o nome totalmente qualificado da política aponta para o banco de dados na conta de origem. Consequentemente, a conta ou usuários de destino na conta de destino não são obrigados a cumprir com a política de segurança.
Para replicar com sucesso uma política de segurança, verifique se o grupo de replicação ou failover inclui os tipos de objetos e bancos de dados necessários para evitar uma referência pendente.
Políticas de privacidade¶
Considere o seguinte ao replicar políticas de privacidade e tabelas e exibições protegidas por privacidade associadas à privacidade diferencial:
Se uma política de privacidade for atribuída a uma tabela ou exibição na conta de origem, a política precisará ser replicada na conta de destino.
A perda cumulativa de privacidade para um orçamento de privacidade não é replicada.
A perda cumulativa de privacidade nas contas de destino e de origem é rastreada separadamente.
Os administradores na conta de destino não podem ajustar o orçamento de privacidade replicado. O orçamento de privacidade é sincronizado com o da conta de origem.
Se um analista tiver acesso à tabela ou exibição protegida por privacidade na conta de origem e na conta de destino, ele poderá incorrer no dobro da perda de privacidade antes de atingir o limite do orçamento de privacidade.
Os domínios de privacidade definidos nas colunas também são replicados.
Políticas de sessão com funções secundárias¶
Se estiver usando políticas de sessão com funções secundárias, você deverá especificar o banco de dados da política no mesmo grupo de replicação que contém as funções. Por exemplo:
Se você especificar o banco de dados da política de sessão que faz referência a funções secundárias em um grupo de replicação ou failover diferente (rg2) do grupo de replicação ou failover que contém objetos em nível de conta (myrg) e você replicar ou fazer failover de rg2 primeiro, ocorrerá uma referência pendente. Uma mensagem de erro informa para você colocar o banco de dados da política de sessão no grupo de replicação ou grupo de failover que contém as funções. Esse comportamento ocorre quando a política de sessão é definida na conta ou nos usuários.
Se a política de sessão e os objetos no nível da conta estiverem em grupos de replicação diferentes e a política de sessão não estiver definida na conta ou nos usuários, você poderá replicar e atualizar a conta de destino. Certifique-se de atualizar primeiro o grupo de replicação que contém os objetos de nível de conta.
Se você atualizar a conta de destino após replicar ou executar failover da política de sessão com funções secundárias e objetos de função, a conta de destino refletirá o comportamento da política de sessão e das funções secundárias na conta de origem.
Além disso, quando você atualiza o banco de dados na conta de destino e o banco de dados contém uma política de sessão que faz referência a funções secundárias, ALLOWED_SECONDARY_ROLES sempre avalia como [ALL].
Replicação e segredos¶
Você só pode replicar o segredo usando um grupo de replicação ou failover. Especifique o banco de dados que contém o segredo, o banco de dados que contém UDFs ou procedimentos que fazem referência ao segredo e as integrações que fazem referência ao segredo em um único grupo de replicação ou failover.
Se você tiver o banco de dados que contém o segredo em um grupo de replicação ou failover e a integração que faz referência ao segredo em um grupo de replicação ou failover diferente:
Se você replicar primeiro a integração e depois o segredo, a operação será bem-sucedida: todos os objetos serão replicados e não haverá referências pendentes.
Se você replicar o segredo antes da integração e o segredo ainda não existir na conta de destino, um “espaço reservado de segredo” será adicionado na conta de destino para evitar uma referência pendente. Snowflake mapeia o espaço reservado do segredo para a integração.
Depois de replicar o grupo que contém a integração, na próxima operação de atualização do grupo que contém o segredo, o Snowflake atualiza a conta de destino para substituir o segredo do espaço reservado pelo segredo que é referenciado na integração.
Se você replicar o segredo e não replicar a integração de
account1paraaccount2, a integração não funcionará na conta de destino (account2) porque não há integração para usar o segredo. Além disso, se você fizer failover e a conta de destino for promovida para conta de origem, a integração não funcionará.Quando você decide fazer failover para tornar
account1a conta de origem, o segredo e as referências de integração correspondem e o segredo do espaço reservado não é usado. Isso permite que você use a integração de segurança e o segredo que contém as credenciais porque os objetos podem fazer referência uns aos outros.
Replicação e clonagem¶
Historicamente os objetos clonados eram replicados fisicamente, e não logicamente, para bancos de dados secundários. Ou seja, as tabelas clonadas em um banco de dados padrão não contribuem para o armazenamento geral de dados, a menos ou até que as operações da DML no clone adicionem ou modifiquem os dados existentes. Entretanto, quando uma tabela clonada é replicada para um banco de dados secundário, os dados físicos também são replicados, aumentando o uso do armazenamento de dados para sua conta.
Uma tabela clonada replicada logicamente compartilha as micropartições da tabela original da qual foi clonada, reduzindo o armazenamento físico da tabela secundária na conta de destino.
Se a tabela original e a tabela clonada estiverem inclusas no mesmo grupo de replicação ou failover, a tabela clonada poderá ser replicada logicamente para a conta de destino.
Replicação lógica de clones¶
Se a tabela original e a clonada estiverem inclusas no mesmo grupo de replicação ou failover, a tabela clonada poderá ser replicada logicamente para a conta de destino.
Por exemplo, se a tabela t2 no banco de dados db2 for um clone da tabela t1 no banco de dados db1 e ambos os bancos de dados estiverem inclusos no grupo de replicação rg1, a tabela t2 será criada como um clone lógico na conta de destino.
Um objeto clonado pode ser clonado para criar clones adicionais do objeto original. O objeto original e os objetos clonados fazem parte do mesmo grupo de clones. Por exemplo, se a tabela t3 no banco de dados db3 for criada como um clone de t2, ela estará no mesmo grupo de clones que a tabela original t1 e a tabela clonada t2.
Se o banco de dados db3 for adicionado posteriormente ao grupo de replicação rg1, a tabela t3 será criada na conta de destino como um clone lógico da tabela t1.
Considerações¶
As tabelas que estão no mesmo grupo de clones na conta de origem podem não estar no mesmo grupo de clones na conta de destino.
A tabela original e a tabela clonada devem estar no mesmo grupo de replicação ou failover.
Em alguns casos, nem todas as micropartições do grupo de clones podem ser compartilhadas com a tabela clonada. Isso pode resultar em uso adicional de armazenamento para a tabela clonada na conta de destino.
Exemplo¶
A tabela t2 no banco de dados db2 é um clone da tabela t1 no banco de dados db1. Inclua os dois bancos de dados no grupo de replicação myrg para replicar logicamente t2 para a conta de destino:
Replicação e clustering automático¶
Em um banco de dados primário, o Snowflake monitora tabelas clusterizadas usando Clustering automático e repete o clustering conforme necessário. Como parte de uma operação de atualização, tabelas clusterizadas são replicadas para um banco de dados secundário com a classificação atual de micropartições de tabela. Por isso, o reclustering não é executado novamente nas tabelas clusterizadas no banco de dados secundário, o que seria redundante.
Se um banco de dados secundário contém tabelas clusterizadas e o banco de dados é promovido para se tornar o banco de dados primário, o Snowflake inicia o clustering automático das tabelas neste banco de dados, suspendendo simultaneamente o monitoramento das tabelas clusterizadas no banco de dados primário anterior.
Consulte Replicação e exibições materializadas (neste tópico) para obter mais informações sobre clustering automático para exibições materializadas.
Replicação e tabelas grandes e de alta rotatividade¶
Quando uma ou mais linhas de uma tabela são atualizadas ou excluídas, todas as micropartições impactadas que armazenam esses dados em um banco de dados primário são recriadas e devem ser sincronizadas com bancos de dados secundários. Para tabelas grandes e de alta rotatividade, os custos de replicação podem ser significativos.
Para tabelas grandes, de alta rotatividade e com custos de replicação significativos, estão disponíveis as seguintes mitigações:
Replicar quaisquer bancos de dados primários que armazenem tais tabelas em uma frequência menor.
Mudar seu modelo de dados para reduzir a rotatividade.
Para obter mais informações, consulte Gerenciamento de custos para tabelas grandes e de alta rotatividade.
Replicação e Time Travel¶
Dados do Time Travel e Fail-safe são mantidos independentemente para um banco de dados secundário e não são replicados a partir de um banco de dados primário. Consultar tabelas e exibições em um banco de dados secundário usando o Time Travel pode produzir resultados diferentes dos obtidos ao executar a mesma consulta no banco de dados primário.
- Dados históricos:
Os dados históricos disponíveis para consulta em um banco de dados primário usando Time Travel não são replicados para bancos de dados secundários.
Por exemplo, suponha que dados sejam carregados continuamente em uma tabela a cada 10 minutos usando o Snowpipe, e um banco de dados secundário é atualizado a cada hora. A operação de atualização replica apenas a última versão da tabela. Embora cada versão horária da tabela dentro da janela de retenção esteja disponível para consulta usando o Time Travel, nenhuma das versões iterativas dentro de cada hora (as cargas individuais do Snowpipe) está disponível.
- Período de retenção de dados:
O período de retenção de dados para tabelas em um banco de dados secundário começa quando o banco de dados secundário é atualizado com as operações DML (ou seja, alteração ou exclusão de dados) gravadas em tabelas no banco de dados primário.
Nota
O parâmetro do período de retenção de dados, DATA_RETENTION_TIME_IN_DAYS, só é replicado para objetos do banco de dados secundário, não para o próprio banco de dados. Para obter mais detalhes sobre a replicação de parâmetros, consulte Parâmetros.
Replicação e exibições materializadas¶
Em um banco de dados primário, o Snowflake realiza a manutenção automática em segundo plano de exibições materializadas. Quando uma tabela base muda, todas as exibições materializadas definidas na tabela são atualizadas por um serviço de fundo que utiliza recursos de computação fornecidos pelo Snowflake. Além disso, se o clustering automático estiver habilitado para uma exibição materializada, então a exibição é monitorada e reclusterizada conforme necessário em um banco de dados primário.
Uma operação de atualização replica as definições da exibição materializada para um banco de dados secundário; os dados da exibição materializada não são replicados. A manutenção automática em segundo plano de exibições materializadas em um banco de dados secundário está habilitada por padrão. Se o clustering automático estiver habilitado para uma exibição materializada em um banco de dados primário, o monitoramento automático e o reclustering da exibição materializada no banco de dados secundário também estarão habilitados.
Nota
Os encargos da sincronização automatizada em segundo plano de exibições materializadas são faturados para cada conta que contém um banco de dados secundário.
Replicação e tabelas Apache Iceberg™¶
Considere os seguintes pontos ao usar a replicação para tabelas Iceberg:
Snowflake currently supports replication of Snowflake-managed tables only.
Não há suporte para replicação de tabelas Iceberg convertidas. O Snowflake ignora tabelas convertidas durante as operações de atualização.
Para tabelas replicadas, você deve configurar o acesso a um local de armazenamento na mesma região da conta de destino.
Se você descartar ou alterar um local de armazenamento usado para replicação no volume externo primário, as operações de atualização poderão falhar.
As tabelas secundárias na conta de destino são somente leitura até que você promova a conta de destino para atuar como conta de origem.
O Snowflake mantém a hierarquia de diretórios da tabela Iceberg primária na tabela secundária.
Para esse recurso, há custos de replicação. Para obter mais informações, consulte Explicação dos custos de replicação.
Para considerações sobre os objetos da conta para grupos de replicação e de failover, consulte Objetos de conta.
Replicating dynamic Iceberg tables isn’t supported. Snowflake skips converted tables during refresh operations.
Replicação e tabelas dinâmicas¶
O comportamento da replicação de tabelas dinâmicas varia de acordo com o fato de o banco de dados primário que contém a tabela dinâmica fazer parte de um grupo de replicação ou de um grupo de failover.
Tabelas dinâmicas e grupos de replicação¶
Um banco de dados que contém uma tabela dinâmica pode ser replicado usando um grupo de replicação. Não é necessário que o(s) objeto(s) de origem do qual ele depende estejam no mesmo grupo de replicação.
Os objetos replicados em cada conta de destino são chamados de objetos secundários e são réplicas dos objetos primários na conta de origem. Os objetos secundários são somente leitura na conta de destino. Se um grupo de replicação secundário for descartado em uma conta de destino, os bancos de dados que estavam inclusos no grupo se tornarão de leitura/gravação. No entanto, quaisquer tabelas dinâmicas incluídas em um grupo de replicação permanecem somente leitura mesmo depois que o grupo secundário é descartado na conta de destino. Nenhuma atualização de DML ou tabela dinâmica pode ocorrer nessas tabelas dinâmicas somente leitura.
Tabelas dinâmicas e grupos de failover¶
Um banco de dados que contém uma tabela dinâmica pode ser replicado usando um grupo de failover. Se uma tabela dinâmica fizer referência a objetos de origem fora do grupo de failover ou da replicação do banco de dados, ela ainda poderá ser replicada. Após um failover, a tabela dinâmica resolve os objetos de origem usando a resolução de nomes durante a atualização. A atualização pode ser bem-sucedida ou falhar, dependendo do estado dos objetos de origem. Se for bem-sucedida, a tabela dinâmica será reinicializada com os dados mais recentes dos objetos de origem.
As tabelas dinâmicas secundárias são somente leitura e não são atualizadas. Após ocorrer um failover e uma tabela dinâmica secundária ser promovida a tabela dinâmica primária, a primeira atualização será uma reinicialização seguida por atualizações incrementais se a tabela dinâmica estiver configurada para atualização incremental de dados.
Nota
A tabela dinâmica reinicializada pode ser diferente da réplica original porque não há garantia que os objetos de origem e a tabela dinâmica compartilharão o mesmo instantâneo de replicação.
Exemplo: falha na atualização devido à falta de objetos de origem
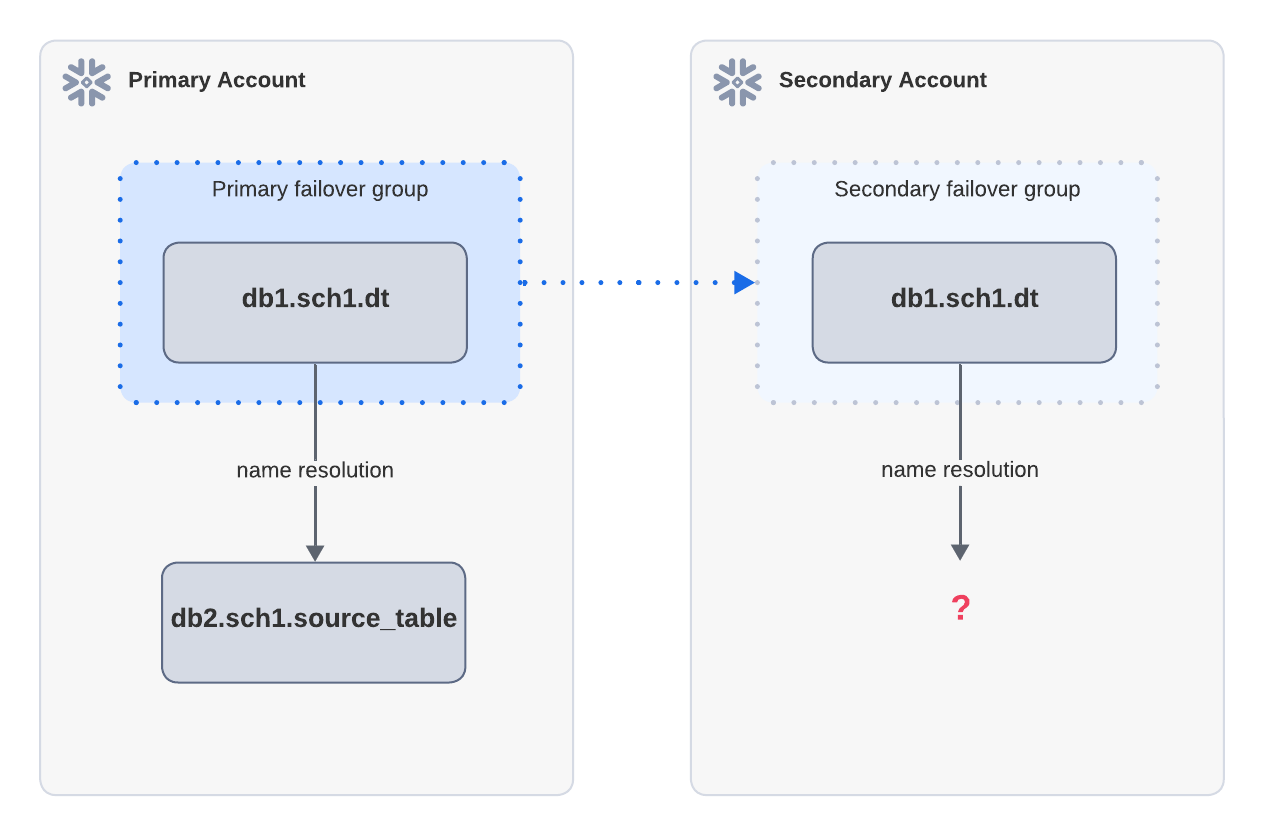
Se uma tabela dinâmica depender de uma tabela de origem fora do grupo de failover, ela não poderá ser atualizada após um failover. No diagrama acima, a tabela dinâmica dt na conta primária é replicada para a conta secundária. dt depende de source_table, que não está inclusa no mesmo grupo de failover que a conta primária. Após o failover, a atualização na conta secundária falha porque source_table não pode ser resolvida.
Exemplo: atualização bem-sucedida quando os objetos de origem existem na conta secundária por meio de replicação separada
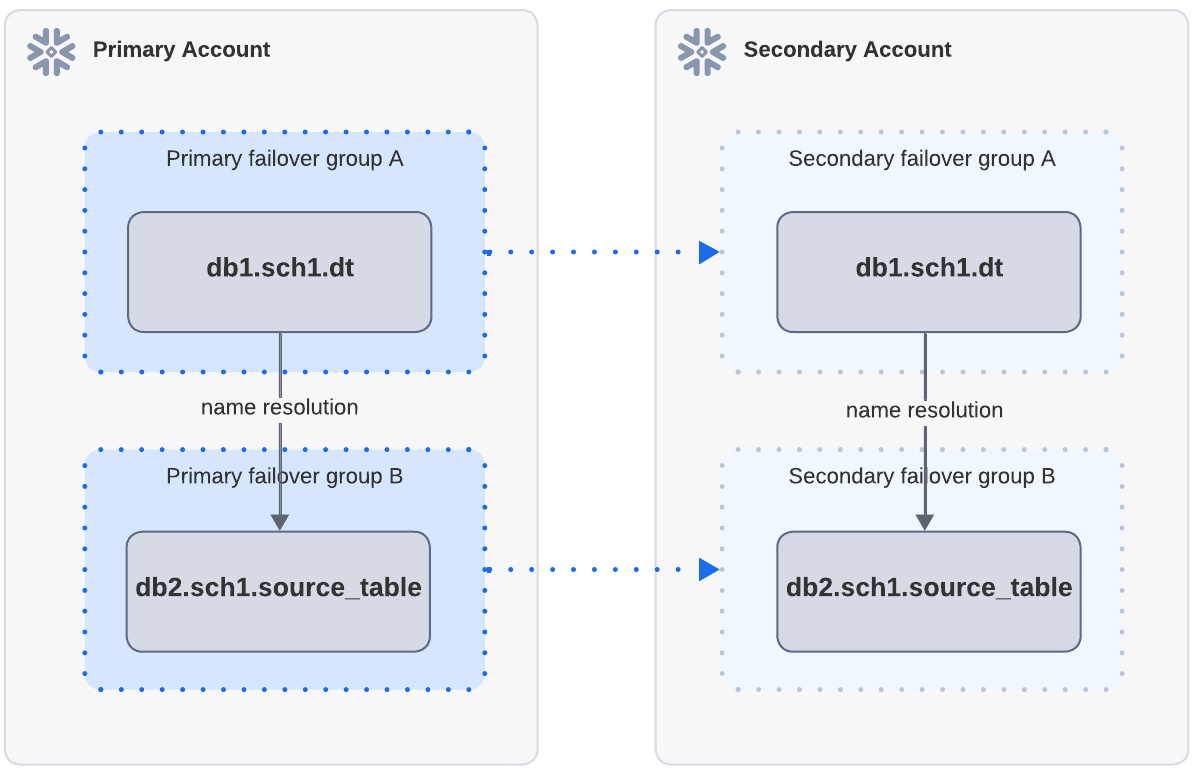
No diagrama acima, a tabela dinâmica dt depende de source_table. Tanto a dt quanto a source_table na conta primária são replicadas para a conta secundária por meio de grupos de failover independentes. Após a replicação e o failover, quando a dt é atualizada na conta secundária, a atualização é bem-sucedida porque a source_table pode ser encontrada por meio da resolução de nomes.
Exemplo: atualização bem-sucedida quando os objetos de origem existem localmente na conta secundária
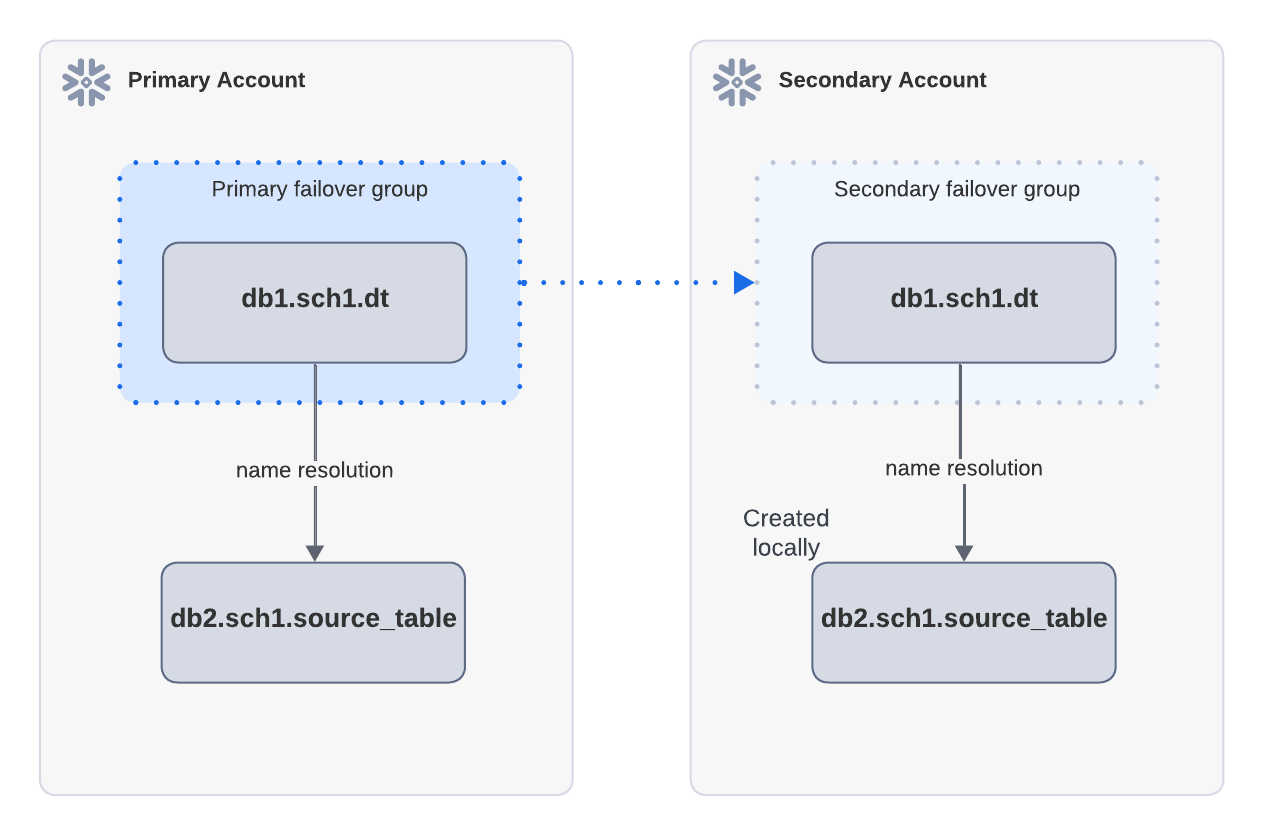
No diagrama acima, a tabela dinâmica dt depende da source_table e é replicada por meio de um grupo de failover da conta primária para a conta secundária. Uma source_table é criada localmente na conta secundária. Após o failover, quando a dt1 é atualizada na conta secundária, a atualização pode ser bem-sucedida porque a source_table pode ser encontrada por meio da resolução de nomes.
Replicação e Snowpipe Streaming¶
Uma tabela preenchida pelo Snowpipe Streaming em um banco de dados primário é replicada para o banco de dados secundário em uma conta de destino.
No banco de dados primário, as tabelas são criadas e as linhas são inseridas por meio de canais. Tokens offset rastreiam o progresso da ingestão. Uma operação de atualização replica o objeto de tabela, os dados da tabela e os offsets do canal associados à tabela do banco de dados primário para o banco de dados secundário.
Arquiteturas do Snowpipe Streaming¶
O Snowflake oferece suporte a duas arquiteturas subjacentes para o Snowpipe Streaming, que determinam as APIs de cliente disponíveis e as características de desempenho.
Snowpipe Streaming com arquitetura clássica¶
Operações somente leitura (disponíveis nas contas de origem e destino):
AAPI
getLatestCommittedOffsetTokendo canalComando
SHOW CHANNELS
Operações de gravação (disponíveis somente na conta de origem):
A API openChannel
O canal insertRow API
O canal insertRows API
Snowpipe Streaming com arquitetura de alto desempenho¶
Essa arquitetura oferece recursos otimizados, incluindo operações em massa e verificações de status aprimoradas, cruciais para o gerenciamento de ambientes replicados de alto volume.
Todas as funções descritas abaixo são acessíveis tanto pelos SDKs do Snowpipe Streaming quanto pela API REST do Snowpipe Streaming, permitindo uma integração flexível com base nas suas necessidades de infraestrutura.
Operações de gravação e gerenciamento (disponíveis somente na conta de origem):
Gerenciamento do ciclo de vida do canal Abra e gerencie os canais de ingestão necessários para estabelecer um fluxo de dados. Por exemplo, o método openChannel no SDK Java.
Ingestão transacional consistente: a função principal para anexar linhas. Os dados inseridos aqui têm garantia de serem incluídos no instantâneo de replicação, depois de confirmados. Por exemplo, o método appendRows no SDK Java.
Rastreamento de tokens de deslocamento: recupere os últimos tokens de deslocamento confirmados para garantir a integridade dos dados e impedir a duplicação durante a ingestão. Por exemplo, o método getLatestCommittedOffsetToken no SDK Java.
Monitoramento de status em massa: monitore com eficiência as métricas de integridade e atraso em vários canais. Isso é essencial para verificar se a latência dos dados é aceitável antes que ocorra a replicação. Por exemplo, o método getChannelStatus no SDK Java.
Operações somente leitura (disponíveis em ambas as contas de origem e destino):
Inspeção de canal: use comandos de metadados, como
SHOW CHANNELS, para visualizar detalhes de configuração, status e propriedades dos canais de ingestão existentes no ambiente replicado.
Evitar perda de dados¶
Para evitar a perda de dados em caso de failover, o tempo de retenção de dados para linhas inseridas com sucesso em sua fonte de dados upstream deve ser maior que o cronograma de replicação configurado. Se os dados forem inseridos em uma tabela em um banco de dados primário e o failover ocorrer antes que os dados possam ser replicados para o banco de dados secundário, os mesmos dados precisarão ser inseridos na tabela no banco de dados primário recém-promovido. O exemplo seguinte mostra um cenário de failover:
A tabela
t1no banco de dados primáriorepl_dbé preenchida com dados com Snowpipe Streaming e o conector Kafka.O
offsetTokené 100 para o canal 1 e 100 para o canal 2 parat1no banco de dados primário.Uma operação de atualização é concluída com êxito na conta de destino.
O
offsetTokené 100 para o canal 1 e 100 para o canal 2 parat1no banco de dados secundário.Mais linhas são inseridas em
t1no banco de dados primário.O
offsetTokenagora é 200 para o canal 1 e 200 para o canal 2 parat1no banco de dados primário.Um failover ocorre antes que as linhas adicionais e os novos offsets de canal possam ser replicados para o banco de dados secundário.
Neste caso, faltam 100 offsets em cada canal para tabela t1 no banco de dados primário recém-promovido. Para inserir os dados que faltam, consulte Reabertura de canais ativos para Snowpipe Streaming na conta de origem recém-promovida.
Requisitos de suporte para replicação¶
Snowpipe Streaming com arquitetura clássica¶
O suporte para replicação do Snowpipe Streaming na arquitetura clássica requer as seguintes versões mínimas:
SDK do Snowflake Ingest versão 1.1.1 ou mais recente
Se você usa o conector Kafka: conector Kafka versão 1.9.3 ou posterior.
Snowpipe Streaming com arquitetura de alto desempenho¶
O suporte para replicação do Snowpipe Streaming na arquitetura de alto desempenho requer as seguintes versões mínimas:
SDK do Snowpipe Streaming versão 1.1.0 ou mais recente.
Requisito de retenção de dados para ambas as arquiteturas¶
O tempo de retenção de dados para linhas inseridas com êxito em sua fonte de dados upstream deve ser maior que o cronograma de replicação configurado. Se você usa o conector Kafka, certifique-se de que a configuração de log.retention esteja definida com buffer suficiente.
Replicação e estágios¶
As seguintes restrições se aplicam a objetos de preparação:
Atualmente, o Snowflake oferece suporte à replicação de estágio como parte da replicação baseada em grupo (grupos de replicação e failover). A replicação de estágio não é suportada para replicação de banco de dados.
Você pode replicar um estágio externo. Entretanto, os arquivos em um estágio externo não são replicados.
Você pode replicar um estágio interno. Para replicar os arquivos em um estágio interno, você deve ativar uma tabela de diretórios no estágio. O Snowflake replica apenas os arquivos mapeados pela tabela de diretórios.
Ao replicar um estágio interno com uma tabela de diretórios, não é possível desativar a tabela de diretórios no estágio primário ou secundário. A tabela de diretórios contém informações críticas sobre arquivos replicados e arquivos carregados usando uma instrução COPY.
Uma operação de atualização falhará se a tabela de diretórios em um estágio interno contiver um arquivo maior que 5GB. Para contornar essa limitação, mova todos os arquivos maiores que 5GB para um estágio diferente.
Não é possível desativar a tabela de diretórios em um estágio primário ou secundário ou em qualquer estágio que tenha sido replicado anteriormente. Siga estas etapas antes de adicionar o banco de dados que contém o estágio a um grupo de replicação ou failover.
Desative a tabela de diretórios no estágio primário.
Mova os arquivos maiores que 5GB para outro estágio que não tenha uma tabela de diretórios ativada.
Depois de mover os arquivos para outro estágio, reative a tabela de diretórios no estágio primário.
Os arquivos nos estágios de usuário e de tabela não são replicados.
Para estágios externos nomeados que usam uma integração de armazenamento, você deve configurar a relação de confiança para integrações de armazenamento secundário em suas contas de destino antes do failover. Para obter mais informações, consulte Configuração do acesso ao armazenamento em nuvem para integrações de armazenamento secundárias.
Se você replicar um estágio externo com uma tabela de diretórios e tiver configurado a atualização automática para a tabela de diretórios de origem, deverá configurar a atualização automática para a tabela de diretórios secundária antes do failover. Para obter mais informações, consulte Configuração de atualização automatizada para tabelas de diretório em estágios secundários.
Um comando de cópia poderá demorar mais que o esperado se a tabela de diretórios em um estágio replicado não for consistente com os arquivos replicados no estágio. Para tornar uma tabela de diretórios consistente, atualize-a com uma instrução ALTER STAGE … REFRESH. Para verificar o status de consistência de uma tabela de diretórios, use a função SYSTEM$GET_DIRECTORY_TABLE_STATUS.
Replicação e canais¶
As seguintes restrições se aplicam a objetos de canal:
Atualmente, o Snowflake oferece suporte à replicação de canal como parte da replicação baseada em grupo (grupos de replicação e failover). A replicação de canal não é suportada para replicação de banco de dados.
O Snowflake replica o histórico de cópias de um canal somente quando o canal pertence ao mesmo grupo de replicação que sua tabela de destino.
A replicação de integrações de notificação não é suportada.
O Snowflake apenas replica o histórico de carregamento após o último truncamento da tabela.
Para receber notificações, você deve configurar um canal secundário de ingestão automática em uma conta de destino antes do failover. Para obter mais informações, consulte Configuração de notificações para canais de ingestão automática secundária.
Use a função SYSTEM$PIPE_STATUS para resolver quaisquer canais que não estejam no estado de execução esperado após o failover.
O Snowflake não oferece suporte à replicação e ao failover para o Snowpipe com o conector Kafka, mas o Snowflake oferece suporte à replicação e ao failover para o Snowpipe Streaming com o conector Kafka. Para obter mais informações, consulte Snowpipe Streaming e o conector Kafka.
Replicação de funções de métricas de dados (DMFs)¶
Os seguintes comportamentos se aplicam a replicação DMF:
- Tabelas de eventos
A tabela de eventos que armazena os resultados de chamadas manuais ou o agendamento de execução de um DMF não é replicada porque a tabela de eventos é local em sua conta Snowflake, e o Snowflake não oferece suporte à replicação de tabelas de eventos.
- Grupos de replicação
Quando você adiciona o(s) banco(s) de dados com seus DMFs a um grupo de replicação, ocorre o seguinte na conta de destino:
Os DMFs são replicados da conta de origem.
As tabelas ou visualizações que a definição do DMF especifica, como com uma referência de chave estrangeira :ref:` <label-create_data_metric_function_foreign_key>` são replicadas da conta de origem, a menos que a tabela ou exibição esteja associada ao preenchimento automático entre nuvens.
Os DMFs agendados na conta de destino são suspensos. Os DMFs secundários retomarão seu cronograma quando você promover a conta de destino para a conta de origem e as DMFs secundárias se tornarem DMFs primárias.
- Grupos de failover
Quando você replica o(s) banco(s) de dados que contém seus DMFs usando um grupo de failover, ocorre o seguinte no caso de failover:
O cronograma de DMFs suspensas é retomado quando você promove a conta de destino para conta de origem.
Os DMFs agendados na conta de destino são suspensos após a promoção de uma conta diferente para conta de origem.
Se você não replicar o banco de dados que contém a DMF para uma conta de destino, as associações de DMF a uma tabela ou exibição serão descartadas quando a conta de destino for promovida a conta de origem por não estarem disponíveis na conta de origem recém-promovida.
Dica
Antes de fazer failover de sua conta, verifique as referências do DMF chamando a função de tabela Information Schema DATA_METRIC_FUNCTION_REFERENCES para determinar os objetos de tabela associados a um DMF antes das operações de promoção e atualização.
Replicação de procedimentos armazenados e funções definidas pelo usuário (UDFs)¶
Os procedimentos armazenados e UDFs são replicados de um banco de dados primário para bancos de dados secundários.
Procedimentos armazenados e UDFs e estágios¶
Se um procedimento armazenado ou UDF depender de arquivos em um estágio (por exemplo, se o procedimento armazenado for definido no código Python que é carregado de um estágio), você deverá replicar manualmente o estágio e seus arquivos para o banco de dados secundário. Para obter mais informações sobre replicação de estágios, consulte Replicação de histórico de carregamento, canal e estágio.
Por exemplo, se um banco de dados primário tiver uma UDF de Python inline que importe qualquer código armazenado em um estágio, a UDF não funcionará a menos que o estágio e seu código importado sejam replicados no banco de dados secundário.
Procedimentos armazenados e UDFs e acesso à rede externa¶
Se um procedimento armazenado ou UDF depender do acesso a um local de rede externo, você deverá replicar os seguintes objetos:
EXTERNALACCESSINTEGRATIONS devem ser incluídos na lista
allowed_integration_typespara o grupo de replicação ou failover.O banco de dados que contém a regra de rede.
O banco de dados que contém o segredo que armazena as credenciais para autenticação no local de rede externo.
Se o objeto secreto fizer referência a uma integração de segurança, você deverá incluir SECURITY INTEGRATIONS na lista
allowed_integration_typesdo grupo de replicação ou failover.
Replicação e políticas de ciclo de vida de armazenamento¶
O Snowflake replica as políticas de ciclo de vida de armazenamento e as associações com tabelas para as contas de destino, mas não executa as políticas. O Snowflake não replica dados arquivados nas camadas COOL ou COLD. Os dados arquivados na sua conta de origem não estarão disponíveis na conta de destino.
Após o failover para uma conta de destino, o Snowflake pausa a execução da política de ciclo de vida de armazenamento na conta de origem. Após o failback para a conta de origem, o Snowflake retoma a execução da política.
O Snowflake nunca executa automaticamente políticas de ciclo de vida de armazenamento secundárias em tabelas secundárias, mesmo após um failover. No entanto, você pode usar políticas secundárias em uma conta de destino anexando-as a novas tabelas. Para essas novas tabelas, o Snowflake executa as políticas.
Replicação e fluxos¶
Esta seção descreve práticas recomendadas e áreas potenciais de preocupação ao replicar fluxos em Replicação de bancos de dados em várias contas ou Replicação de contas e Failover/Failback.
Objetos de origem compatíveis com fluxos¶
Os fluxos replicados podem rastrear com sucesso os dados de alteração para tabelas e exibições no mesmo banco de dados.
Atualmente, os seguintes tipos de objetos de origem não têm suporte:
Tabelas externas
Tabelas ou exibições nos bancos de dados separados dos banco de dados do fluxo, a menos que ambos os bancos de dados de fluxo e o banco de dados que armazena o objeto de origem estejam incluídos no mesmo grupo de replicação ou failover.
Tabelas ou exibições em bancos de dados compartilhados (ou seja, bancos de dados compartilhados a partir das contas de provedor para sua conta)
A replicação de fluxos em tabelas de diretório é suportada quando você ativa Replicação de histórico de carregamento, canal e estágio.
Uma operação de atualização ou replicação de banco de dados falha se o banco de dados primário incluir um fluxo com um objeto de origem incompatível. A operação também falha se o objeto de origem para qualquer fluxo tiver sido descartado.
Os fluxos somente de anexação não são suportados em objetos de origem replicados.
Como evitar a duplicação de dados¶
Nota
Além do cenário descrito nesta seção, os fluxos em um banco de dados secundário podem retornar linhas duplicadas na primeira vez em que são incluídos em uma operação de atualização. Nesse caso, linhas duplicadas referem-se a uma única linha com vários valores de coluna METADATA$ACTION.
Após a operação inicial de atualização, é improvável você encontrar esse problema específico em um banco de dados secundário.
A duplicação de dados ocorre quando operações DML gravam os mesmos dados de alteração de um fluxo várias vezes sem uma verificação de exclusividade. Isso pode ocorrer se um fluxo e uma tabela de destino para os dados de alteração de fluxo forem armazenados em bancos de dados separados, e esses bancos de dados não passarem por uma replicação e failover no mesmo grupo.
Por exemplo, suponha que você insira regularmente dados de alteração de fluxo s na tabela dt. (Para este exemplo, o objeto de origem do fluxo não importa). Bancos de dados separados armazenam o fluxo e a tabela de destino.
No carimbo de data/hora
t1, uma linha é inserida na tabela de origem para o fluxos, criando uma nova versão da tabela. O fluxo armazena o offset para essa versão de tabela.No carimbo de data/hora
t2, o banco de dados secundário que armazena o fluxo é atualizado. O fluxo replicadosagora armazena o offset.No carimbo de data/hora
t3, os dados de alteração do fluxossão inseridos na tabeladt.No carimbo de data/hora
t4, o banco de dados secundário que armazena o fluxospassa por um failover.No carimbo de data/hora
t5, os dados de alteração do fluxossão inseridos novamente na tabeladt.
Para evitar essa situação, faça a replicação e o failover, juntos, dos bancos de dados que armazenam os fluxos e suas tabelas de destino.
Referências de fluxo na cláusula WHEN da tarefa¶
Para evitar um comportamento inesperado ao executar tarefas replicadas que se referem a fluxos na cláusula WHEN boolean_expr, recomendamos que você:
Crie as tarefas e fluxos no mesmo banco de dados, ou
Se os fluxos forem armazenados em um banco de dados diferente das tarefas que os referenciam, inclua ambos os bancos de dados no mesmo grupo de failover.
Se uma tarefa faz referência a um fluxo em um banco de dados separado, e ambos os bancos de dados não estão incluídos no mesmo grupo de failover, então o banco de dados que contém a tarefa pode passar por um failover sem o banco de dados que contém o fluxo. Nesse cenário, quando a tarefa é retomada no banco de dados com failover, ela registra um erro quando tenta executar e não consegue encontrar o fluxo referenciado. Esse problema pode ser resolvido com o failover do banco de dados que contém o fluxo ou com a recriação do banco de dados e do fluxo na mesma conta que o banco de dados com failover que contém a tarefa.
Desatualização de fluxo¶
Se um fluxo no banco de dados primário se tornou desatualizado, o fluxo replicado em um banco de dados secundário também está desatualizado e não pode ser consultado nem seus dados de alteração consumidos. Para resolver isso, recrie o fluxo no banco de dados primário (usando CREATE OR REPLACE STREAM). Quando o banco de dados secundário é atualizado, o fluxo replicado fica legível novamente.
Observe que o offset para um fluxo recriado é a versão atual da tabela por padrão. Você pode recriar um fluxo que aponta para uma versão anterior da tabela usando o Time Travel; no entanto, o fluxo replicado permaneceria ilegível. Para obter mais informações, consulte Replicação de fluxo e Time Travel (neste tópico).
Replicação de fluxo e Time Travel¶
Após o failover de um banco de dados primário, se um fluxo no banco de dados usar o Time Travel para ler uma versão de tabela para o objeto de origem a partir de um ponto no tempo antes do último carimbo de data/hora da atualização, o fluxo replicado não pode ser consultado nem os dados de alteração consumidos. Da mesma forma, consultar os dados de alteração de um objeto de origem a partir de um ponto no tempo antes do último carimbo de data/hora da atualização usando a cláusula CHANGES para as instruções SELECT apresenta falha com um erro.
Isso porque uma operação de atualização reúne o histórico da tabela em uma única versão de tabela. As versões de tabelas iterativas criadas antes do carimbo de data/hora da atualização não são preservadas no histórico da tabela para os objetos de origem replicados.
Considere o seguinte exemplo:
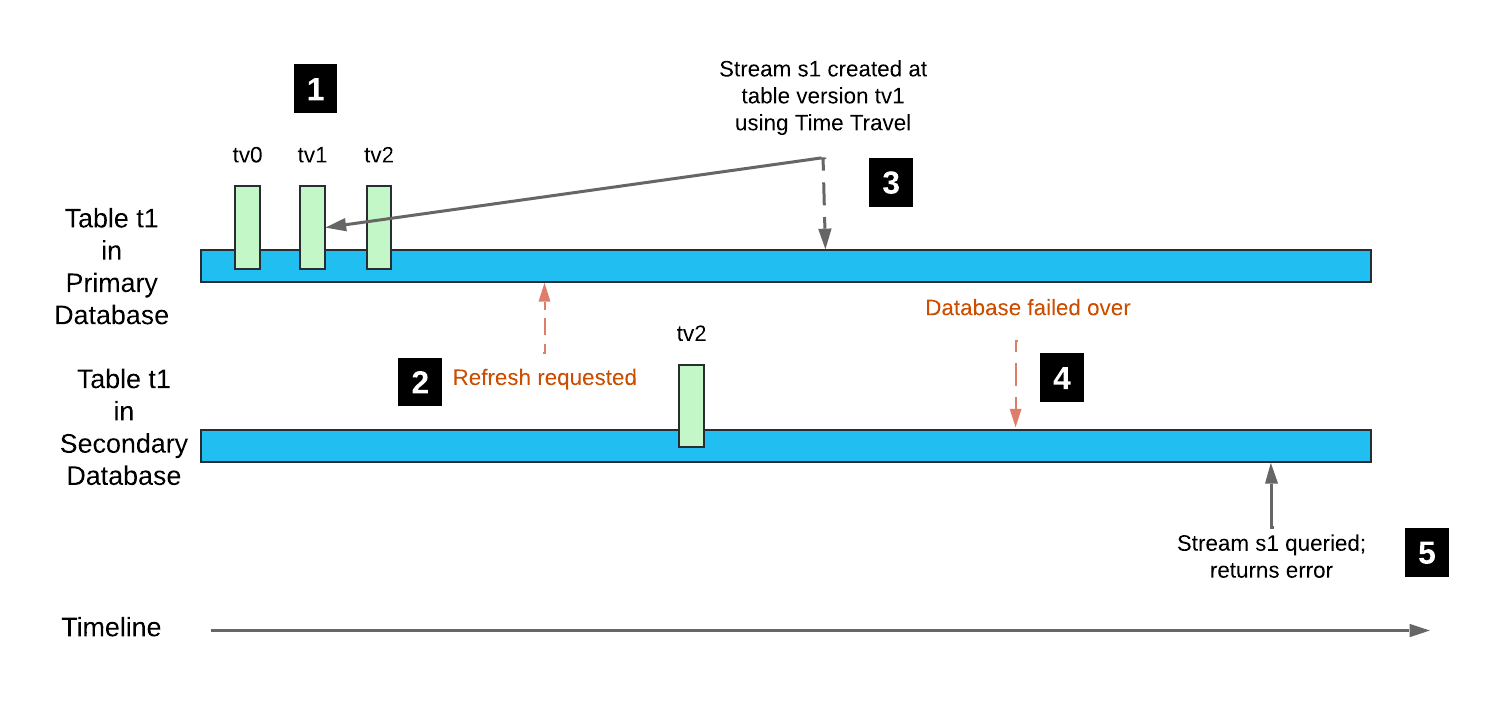
A tabela
t1é criada no banco de dados primário com o rastreamento de alterações ativado (versão da tabelatv0). As transações DML subsequentes criam as versões de tabelatv1etv2.Um banco de dados secundário que contém a tabela
t1é atualizado. A versão de tabela para essa tabela replicada étv2; entretanto, o histórico da tabela não é replicado.Um fluxo é criado no banco de dados primário com seu offset definido para a versão de tabela
tv1usando o Time Travel.O banco de dados secundário passa por um failover, tornando-se o banco de dados primário.
A consulta do fluxo
s1retorna um erro, porque a versão de tabelatv1não está no histórico da tabela.
Observe que quando uma transação DML subsequente na tabela t1 itera a versão da tabela para tv3, o offset para o fluxo s1 é avançado. O fluxo fica legível novamente.
Como evitar a perda de dados¶
A perda de dados pode ocorrer quando a mais recente operação de atualização de um banco de dados secundário não é concluída antes da operação de failover. Recomendamos atualizar frequentemente seus bancos de dados secundários para minimizar o risco.
Replicação e tarefas¶
Esta seção descreve a replicação de tarefas em Replicação de bancos de dados em várias contas ou Replicação de contas e Failover/Failback.
Nota
A replicação de banco de dados não funciona para gráficos de tarefa se o gráfico for de propriedade de uma função diferente da que executa a replicação.
Cenários de replicação¶
A tabela a seguir descreve diferentes cenários de tarefas e especifica se as tarefas são replicadas ou não. Exceto quando indicado, os cenários dizem respeito tanto a tarefas autônomas quanto a tarefas em um gráfico de tarefas:
Cenário |
Replicado |
Notas |
|---|---|---|
A tarefa foi criada e retomada ou executada manualmente (usando EXECUTE TASK). A retomada ou execução de uma tarefa cria uma versão inicial da tarefa. |
✔ |
|
A tarefa foi criada, mas nunca foi retomada ou executada. |
❌ |
|
A tarefa foi recriada (usando CREATE OR REPLACE TASK, mas nunca foi retomada ou executada). |
✔ |
A última versão antes de a tarefa ter sido recriada é replicada. Retomar ou executar manualmente a tarefa confirma uma nova versão. Quando o banco de dados é replicado novamente, a nova versão, ou a mais recente, é replicada para o banco de dados secundário. |
A tarefa foi criada e retomada ou executada, mas subsequentemente abandonada. |
❌ |
|
O gráfico de tarefa foi criado e retomado ou executado. Subsequentemente, uma tarefa no gráfico de tarefa foi modificada, mas a tarefa raiz do gráfico de tarefas não foi retomada ou executada novamente. Exemplos de modificações incluem o seguinte:
|
✔ |
A última versão do gráfico de tarefa antes de a tarefa ter sido modificada é replicada. A retomada ou execução manual de uma tarefa confirma uma nova versão que inclui quaisquer alterações nos parâmetros das tarefas dentro do gráfico de tarefa. Como as novas alterações nunca foram confirmadas, apenas a versão anterior do gráfico de tarefas é replicada. Observe que se o gráfico da tarefa modificada não for retomado dentro de um período de retenção (atualmente 30 dias), a versão mais recente da tarefa será descartada. Após esse período, a tarefa não é replicada em um banco de dados secundário, a menos que seja retomada novamente. |
A tarefa raiz em um gráfico da tarefa foi criada e retomada ou executada, mas foi posteriormente suspensa e descartada. |
❌ |
O gráfico da tarefa inteiro não é replicado para um banco de dados secundário. |
A tarefa secundária em um gráfico da tarefa é criada e retomada ou executada, mas é subsequentemente suspensa e descartada. |
✔ |
A última versão do gráfico da tarefa (antes que a tarefa fosse suspensa e descartada) é replicada para um banco de dados secundário. |
Estado retomado ou suspenso das tarefas replicadas¶
Se todas as condições seguintes forem cumpridas, uma tarefa é replicada para um banco de dados secundário em estado retomado:
Uma tarefa independente ou tarefa raiz está em um estado retomado no banco de dados primário quando a operação de replicação ou de atualização começa até que a operação seja concluída. Se uma tarefa estiver em um estado retomado durante apenas parte desse período, ela ainda poderá ser replicada em um estado retomado.
Uma tarefa secundária está em um estado retomado na última versão da tarefa.
O banco de dados primário foi replicado para a conta de destino juntamente com objetos de função no mesmo, ou em um diferente, grupo de replicação ou failover.
Após as funções e o banco de dados serem replicados, você deve atualizar os objetos na conta de destino, executando ALTER REPLICATION GROUP … REFRESH or ALTER FAILOVER GROUP … REFRESH, respectivamente. Se você atualizar o banco de dados executando ALTER DATABASE … REFRESH, o estado das tarefas no banco de dados é alterado para suspenso.
Uma operação de replicação ou atualização inclui a concessão de privilégios para uma tarefa que era atual quando a última versão da tabela foi confirmada. Para obter mais informações, consulte Tarefas replicadas e concessões de privilégios (neste tópico).
Se essas condições não forem cumpridas, a tarefa é replicada para um banco de dados secundário em estado suspenso.
Nota
As tarefas secundárias não são agendadas até o término de um failover, independentemente de seu state. Para obter mais detalhes, consulte Execuções de tarefas após um failover
Tarefas replicadas e concessões de privilégios¶
Se o banco de dados primário foi replicado para uma conta de destino juntamente com objetos de função no mesmo grupo de replicação ou failover, ou em um grupo diferente, os privilégios concedidos sobre as tarefas no banco de dados também são replicados.
A lógica a seguir determina quais privilégios de tarefa são replicados em uma operação de replicação ou de atualização:
Se o proprietário da tarefa atual (ou seja, a função que tem o privilégio OWNERSHIP em uma tarefa) for a mesma função de quando a tarefa foi retomada pela última vez, todas as concessões atuais da tarefa serão replicadas no banco de dados secundário.
Se o atual proprietário da tarefa não tem a mesma função de quando a tarefa foi retomada por último, então apenas o privilégio OWNERSHIP concedido à função do proprietário na versão da tarefa é replicado para o banco de dados secundário.
Se a função atual do proprietário da tarefa não estiver disponível (por exemplo, uma tarefa secundária é descartada, mas uma nova versão do gráfico da tarefa ainda não está confirmada), então apenas o privilégio OWNERSHIP concedido à função do proprietário na versão da tarefa é replicado para o banco de dados secundário.
Execuções de tarefas após um failover¶
Depois que um grupo secundário de failover é promovido para servir como grupo primário, as tarefas retomadas em bancos de dados dentro do grupo de failover são programadas gradualmente. O tempo necessário para restaurar a programação normal de todas as tarefas independentes e gráficos da tarefa retomados depende do número de tarefas retomadas em um banco de dados.
Replicação e projetos dbt¶
Os objetos de projeto dbt são replicados de um banco de dados primário para bancos de dados secundários.
Todos os objetos secundários em uma conta de destino, incluindo bancos de dados secundários, são somente leitura. Não é possível executar um projeto dbt secundário.
Todos os objetos que um projeto dbt referencie, como tabelas e exibições de origem, devem ser replicados com o projeto dbt para que as execuções dele sejam bem-sucedidas após um failover.
Projetos dbt e acesso à rede externa¶
Se um projeto dbt depender do acesso a um local de rede externa, você deverá replicar os seguintes objetos:
EXTERNALACCESSINTEGRATIONS devem ser incluídos na lista
allowed_integration_typespara o grupo de replicação ou failover.O banco de dados que contém a regra de rede.
O banco de dados que contém o segredo que armazena as credenciais para autenticação no local de rede externo.
Se o objeto secreto fizer referência a uma integração de segurança, você deverá incluir SECURITY INTEGRATIONS na lista
allowed_integration_typesdo grupo de replicação ou failover.
Um projeto dbt não armazena as integrações de acesso à rede externa às quais está associado. As integrações de acesso à rede externa são especificadas quando o usuário executa o comando EXECUTE DBT PROJECT. Isso torna mais evidente a necessidade de replicar as integrações de acesso externo separadamente.
Replicação e instâncias de classes Snowflake¶
Uma instância da classe CUSTOM_CLASSIFIER é replicada quando o banco de dados que contém a instância é replicado. A replicação de instâncias de outras classes Snowflake não é aceita.
Dados de uso histórico¶
Os dados de uso histórico para a atividade em um banco de dados primário não são replicados para bancos de dados secundários. Cada conta tem seu próprio histórico de consultas, histórico de login, etc.
Os dados de uso histórico incluem os dados de consulta retornados pelas seguintes funções de tabela do Snowflake Information Schema ou exibições de Account Usage:
COPY_HISTORY
LOGIN_HISTORY
QUERY_HISTORY
etc.