Automatisation de Snowpipe pour Amazon S3¶
Ce sujet fournit des instructions pour déclencher automatiquement des chargements de données Snowpipe depuis des zones de préparation externes sur S3 en utilisant les notifications Amazon SQS (Simple Queue Service) pour un compartiment S3.
Snowflake recommande de n’envoyer que des événements pris en charge par Snowpipe afin de réduire les coûts, le bruit des événements et la latence.
Prise en charge de la plateforme Cloud¶
Le déclenchement de chargements de données Snowpipe automatisés à l’aide de messages d’événements S3 est pris en charge par les comptes Snowflake hébergés sur toutes les plateformes Cloud prises en charge.
Trafic réseau¶
Remarque aux clients de Virtual Private Snowflake (VPS) et AWS PrivateLink :
L’automatisation de Snowpipe à l’aide des notifications SQS d’Amazon fonctionne bien. Cependant, bien que le stockage dans le cloud AWS dans un VPC (y compris VPS) puisse communiquer avec ses propres services de messagerie (Amazon SQS, Amazon Simple Notification Service), ce trafic circule entre les serveurs sur le réseau sécurisé d’Amazon en dehors du VPC ; par conséquent, ce trafic n’est pas protégé par le VPC.
Configuration de l’accès sécurisé au stockage Cloud¶
Note
Si vous avez déjà configuré un accès sécurisé au compartiment S3 qui stocke vos fichiers de données, vous pouvez ignorer cette section.
Cette section explique comment utiliser des intégrations de stockage pour permettre à Snowflake de lire et d’écrire des données dans un compartiment Amazon S3 référencé dans une zone de préparation externe (c’est-à-dire S3). Les intégrations sont des objets Snowflake de première classe nommés, qui évitent de transmettre des informations d’identification explicites de fournisseur Cloud, telles que des clés secrètes ou des jetons d’accès. Les objets d’intégration stockent un ID d’utilisateur de gestion des identités et des accès (IAM) AWS. Un administrateur de votre organisation accorde les autorisations utilisateur IAM de l’intégration dans le compte AWS.
Une intégration peut également répertorier des compartiments (et des chemins facultatifs) qui limitent les emplacements que les utilisateurs peuvent spécifier lors de la création de zones de préparation externes utilisant l’intégration.
Note
Pour terminer les instructions de cette section, des autorisations sont nécessaires dans AWS pour créer et gérer des stratégies et des rôles IAM. Si vous n’êtes pas un administrateur AWS, demandez à votre administrateur AWS d’effectuer ces tâches.
Notez qu’actuellement, l’accès au stockage S3 dans les régions gouvernementales à l’aide d’une intégration de stockage est limité aux comptes Snowflake hébergés sur AWS dans la même région gouvernementale. L’accès à votre stockage S3 à partir d’un compte hébergé en dehors de la région gouvernementale à l’aide d’identifiants directs est pris en charge.
Le diagramme suivant illustre le flux d’intégration d’une zone de préparation S3 :
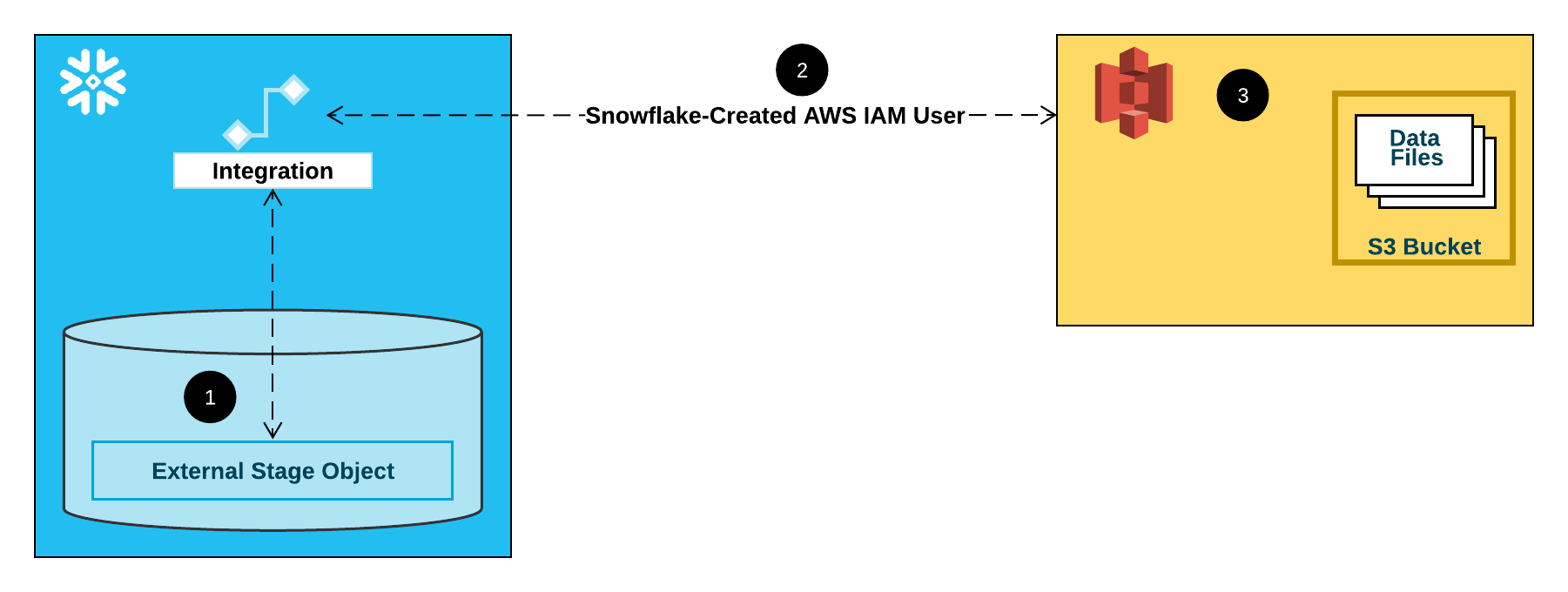
Une zone de préparation externe (c.-à-d S3) fait référence à un objet d’intégration de stockage dans sa définition.
Snowflake associe automatiquement l’intégration de stockage à un utilisateur IAM S3 créé pour votre compte. Snowflake crée un seul utilisateur IAM référencé par toutes les intégrations de stockage S3 de votre compte Snowflake.
Un administrateur AWS de votre organisation accorde des autorisations à l’utilisateur IAM pour accéder au compartiment référencé dans la définition de la zone de préparation. Notez que de nombreux objets de zones de préparation externes peuvent référencer différents compartiments et chemins et utiliser la même intégration de stockage pour l’authentification.
Lorsqu’un utilisateur charge ou décharge des données depuis ou vers une zone de préparation, Snowflake vérifie les autorisations accordées à l’utilisateur IAM sur le compartiment avant d’autoriser ou de refuser l’accès.
Note
Nous vous recommandons vivement cette option, qui vous évite de fournir des informations d’identification IAM lors de l’accès à un stockage dans le Cloud. Voir Configuration de l’accès sécurisé à Amazon S3 pour des options d’accès au stockage supplémentaires.
Étape 1 : Configurer des autorisations d’accès pour le compartiment S3¶
Conditions de contrôle d’accès AWS¶
Snowflake requiert les autorisations suivantes sur un compartiment S3 et un dossier pour accéder aux fichiers dans le dossier (et tout sous-dossier) :
s3:GetBucketLocations3:GetObjects3:GetObjectVersions3:ListBucket
Comme bonne pratique, Snowflake recommande la création d’une politique IAM pour l’accès de Snowflake au compartiment S3. Vous pouvez alors joindre la politique au rôle, et utiliser les identifiants de sécurité générés par AWS pour que le rôle puisse accéder aux fichiers dans le compartiment.
Création d’une politique IAM¶
Les instructions pas-à-pas suivantes décrivent comment configurer les autorisations d’accès pour Snowflake dans votre console de gestion AWS Management Console pour accéder à votre compartiment S3.
Connectez-vous à la console de gestion AWS.
Depuis le tableau de bord d’accueil, recherchez et sélectionnez IAM.
Dans le volet de navigation de gauche, sélectionnez Account settings.
Dans Security Token Service (STS), dans la liste Endpoints, recherchez la région Snowflake dans laquelle se trouve votre compte. Si STS status est inactif, placez la bascule sur Active.
Dans le volet de navigation de gauche, sélectionnez Policies.
Sélectionnez Create Policy.
Pour Policy editor, sélectionnez JSON.
Ajoutez le document de politique qui permettra à Snowflake d’accéder au compartiment et au dossier S3.
La politique suivante (au format JSON) fournit à Snowflake les autorisations requises pour charger ou décharger des données à l’aide d’un seul chemin de dossier et de compartiment.
Copiez et collez le texte dans l’éditeur de politiques :
Note
Assurez-vous de remplacer le
bucketet leprefixpar votre nom de compartiment actuel et le préfixe du chemin du dossier.Les Amazon Resource Names (ARN) pour les compartiments dans des régions gouvernementales ont un préfixe
arn:aws-us-gov:s3:::.
Note
La définition de la condition
"s3:prefix":sur["*"]ou["<chemin>/*"]donne accès à tous les préfixes dans le compartiment spécifié ou le chemin dans le compartiment, respectivement.Notez que les politiques AWS prennent en charge une variété de cas d’utilisation de sécurité différents.
Sélectionnez Next.
Saisissez un Policy name (par exemple,
snowflake_access) et une Description facultative.Sélectionnez Create policy.
Étape 2 : Créer le rôle IAM dans AWS¶
Pour configurer les autorisations d’accès à Snowflake dans la Console de gestion AWS, procédez comme suit :
Dans le volet de navigation gauche du tableau de bord de la gestion des identités et des accès (IAM), sélectionnez Roles.
Sélectionnez Create role.
Sélectionnez AWS account comme type d’entité de confiance.
Sélectionnez Another AWS account
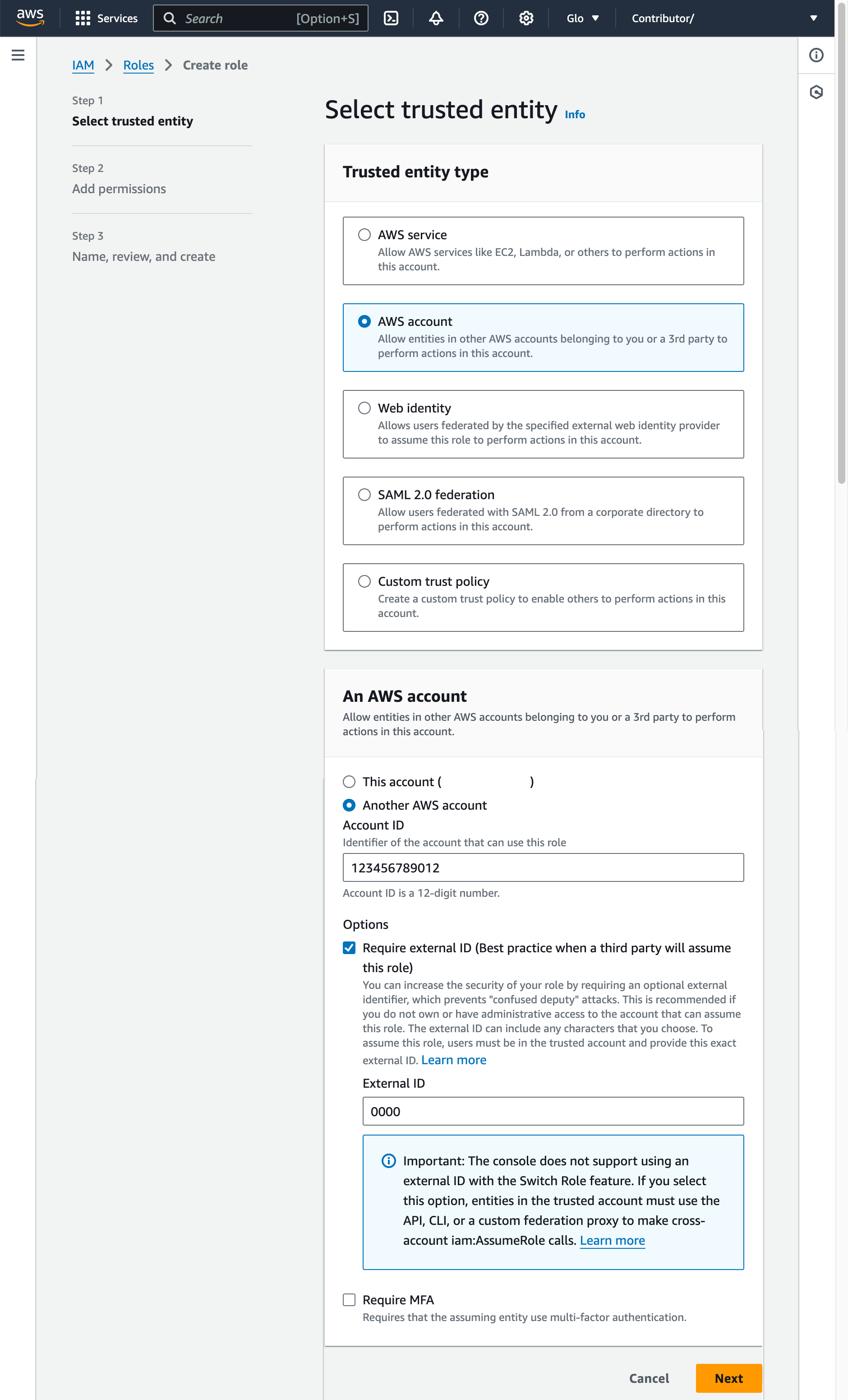
Dans le champ Account ID saisissez votre propre ID de compte AWS temporaire. Plus tard, vous modifierez la relation de confiance et accorderez l’accès à Snowflake.
Sélectionnez l’option Require external ID. Un ID externe est utilisé pour accorder l’accès à vos ressources AWS (telles que des compartiments S3) à un tiers comme Snowflake.
Saisissez un ID de type caractère générique tel que
0000. À une étape ultérieure, vous modifierez la relation de confiance de votre rôle IAM et spécifierez l’ID externe de votre intégration de stockage.Sélectionnez Next.
Sélectionnez la politique que vous avez créée dans Étape 1 : Configuration des autorisations d’accès au compartiment S3 (dans ce sujet).
Sélectionnez Next.
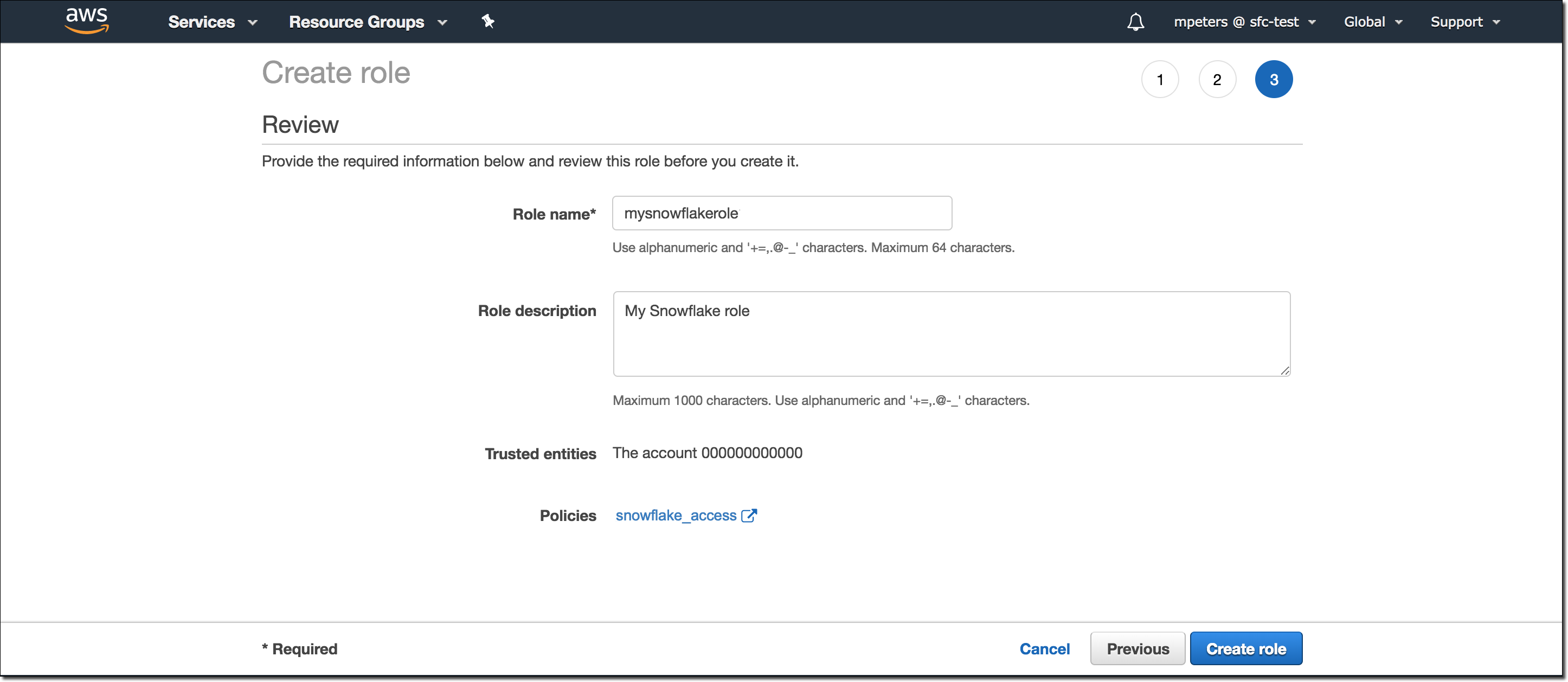
Saisissez un nom et une description pour le rôle, puis sélectionnez Create role.
Vous avez maintenant créé une stratégie IAM pour un compartiment, créé un rôle IAM et associé la stratégie au rôle.
Sur la page de synthèse du rôle, recherchez et enregistrez la valeur Role ARN. Dans l’étape suivante, vous créerez une intégration Snowflake qui fait référence à ce rôle.
Note
Snowflake met en cache les identifiants temporaires pour une période qui ne peut excéder le délai d’expiration de 60 minutes. Si vous révoquez l’accès à partir de Snowflake, les utilisateurs pourraient être en mesure de répertorier les fichiers et d’accéder à des données à partir de l’emplacement de stockage dans le Cloud jusqu’à l’expiration du cache.
Étape 3 : Création d’une intégration de stockage Coud dans Snowflake¶
Créez une intégration de stockage à l’aide de la commande CREATE STORAGE INTEGRATION. Une intégration de stockage est un objet Snowflake qui stocke un utilisateur généré pour la gestion de l’identité et de l’accès (IAM) pour votre stockage Cloud S3, ainsi qu’un ensemble facultatif d’emplacements de stockage autorisés ou bloqués (c’est-à-dire des compartiments). Les administrateurs de fournisseur de Cloud de votre entreprise accordent des autorisations sur les emplacements de stockage à l’utilisateur généré. Cette option permet aux utilisateurs d’éviter de fournir des informations d’identification lors de la création de zones de préparation ou du chargement de données.
Une seule intégration de stockage peut prendre en charge plusieurs zones de préparation externe (c’est-à-dire S3). L’URL dans la définition de zone de préparation doit correspondre aux compartiments S3 (et aux chemins facultatifs) spécifiés pour le paramètre STORAGE_ALLOWED_LOCATIONS.
Note
Seuls les administrateurs de compte (utilisateurs dotés du rôle ACCOUNTADMIN) ou un rôle disposant du privilège global CREATE INTEGRATION peuvent exécuter cette commande SQL.
Où :
integration_nameest le nom de la nouvelle intégration.iam_roleest le nom Amazon Resource Name (ARN) du rôle que vous avez créé à Étape 2 : Création du rôle IAM dans AWS (dans ce sujet).protocolest l’un des éléments suivants :s3fait référence au stockage S3 dans les régions AWS publiques hors de Chine.s3chinafait référence au stockage S3 dans les régions AWS publiques en Chine.s3govfait référence au stockage S3 dans les régions gouvernementales.
bucketest le nom d’un compartiment S3 qui stocke vos fichiers de données (par exemple,mybucket). Les paramètres STORAGE_ALLOWED_LOCATIONS requis et STORAGE_BLOCKED_LOCATIONS facultatif limitent ou bloquent l’accès à ces compartiments, respectivement, lors de la création ou de la modification de zones de préparation faisant référence à cette intégration.pathest un chemin facultatif qui peut être utilisé pour fournir un contrôle granulaire sur les objets du compartiment.
L’exemple suivant crée une intégration qui autorise l’accès à tous les compartiments du compte, mais bloque l’accès aux dossiers sensitivedata définis.
Les zones de préparation externes supplémentaires qui utilisent également cette intégration peuvent faire référence aux compartiments et aux chemins autorisés :
Note
En option, utilisez le paramètre STORAGE_AWS_EXTERNAL_ID pour spécifier votre propre ID externe. Vous pouvez sélectionner cette option pour utiliser le même ID externe sur plusieurs volumes externes et/ou intégrations de stockage.
Étape 4 : Récupérer l’utilisateur AWSIAM de votre compte Snowflake¶
Pour récupérer l’ARN de l’utilisateur IAM automatiquement créé pour votre compte Snowflake, utilisez DESCRIBE INTEGRATION.
Où :
integration_nameest le nom de l’intégration créée à l”étape 3 : Création d’une intégration Cloud Storage dans Snowflake (ce chapitre).
Par exemple :
Enregistrez les valeurs des propriétés suivantes :
Propriété
Description
STORAGE_AWS_IAM_USER_ARNUtilisateur IAM AWS créé pour votre compte Snowflake, par exemple,
arn:aws:iam::123456789001:user/abc1-b-self1234. Snowflake provisionne un seul utilisateur IAM pour l’intégralité de votre compte Snowflake. Toutes les intégrations de stockage S3 de votre compte utilisent cet utilisateur IAM.STORAGE_AWS_EXTERNAL_IDID externe que Snowflake utilise pour établir une relation de confiance avec AWS. Si vous n’avez pas spécifié d’ID externe (
STORAGE_AWS_EXTERNAL_ID) lorsque vous avez créé l’intégration de stockage, Snowflake génère un ID à utiliser.Vous fournirez ces valeurs à la section suivante.
Étape 5 : octroyer à l’utilisateur IAM des autorisations pour accéder à des objets de compartiment¶
Les instructions étape par étape suivantes décrivent comment configurer les permissions d’accès IAM pour Snowflake dans votre console de gestion AWS de sorte que vous puissiez utiliser un compartiment S3 pour charger et décharger les données :
Connectez-vous à la console de gestion AWS.
Sélectionnez IAM.
Dans le volet de navigation de gauche, sélectionnez Roles.
Sélectionnez le rôle que vous avez créé dans l’étape 2 : Création du rôle IAM dans AWS (dans ce sujet).
Sélectionnez l’onglet Trust relationships.
Sélectionnez Edit trust policy.
Modifiez le document de politique avec les valeurs de sortie DESCSTORAGEINTEGRATION que vous avez enregistrées dans Étape 4 : Récupération de l’utilisateur AWSIAM de votre compte Snowflake (dans ce sujet) :
Document de politique pour le rôle IAM
Où :
snowflake_user_arnest la valeur STORAGE_AWS_IAM_USER_ARN que vous avez enregistrée.snowflake_external_idest la valeur STORAGE_AWS_EXTERNAL_ID que vous avez enregistrée.Dans cet exemple, la valeur
snowflake_external_idestMYACCOUNT_SFCRole=2_a123456/s0aBCDEfGHIJklmNoPq=.Note
Pour des raisons de sécurité, si vous créez une nouvelle intégration de stockage (ou si vous recréez une intégration de stockage existante à l’aide de la syntaxe CREATE OR REPLACE STORAGE INTEGRATION) sans spécifier d’ID externe, la nouvelle intégration a un ID externe différent et ne peut donc résoudre la relation de confiance, sauf si vous mettez à jour la politique de confiance.
Sélectionnez Update policy pour enregistrer vos modifications.
Note
Snowflake met en cache les identifiants temporaires pour une période qui ne peut excéder le délai d’expiration de 60 minutes. Si vous révoquez l’accès à partir de Snowflake, les utilisateurs pourraient être en mesure de répertorier les fichiers et de charger des données à partir de l’emplacement de stockage dans le Cloud jusqu’à l’expiration du cache.
Note
Vous pouvez utiliser la fonction SYSTEM$VALIDATE_STORAGE_INTEGRATION pour valider la configuration de votre intégration de stockage.
Détermination de l’option correcte¶
Avant de poursuivre, déterminez si une notification d’événement S3 existe pour le chemin cible (ou le « préfixe » dans la terminologie AWS) dans votre compartiment S3 où se trouvent vos fichiers de données. Les règles d’AWS interdisent la création de notifications conflictuelles pour le même chemin.
Les options suivantes pour automatiser Snowpipe à l’aide d’Amazon SQS sont prises en charge :
Option 1. Nouvelle notification d’événement S3 : Créez une notification d’événement pour le chemin cible dans votre compartiment S3. La notification d’événement informe Snowpipe via une file d’attente SQS lorsque les fichiers sont prêts à être chargés.
Important
S’il existe une notification d’événement en conflit pour votre compartiment S3, utilisez l’option 2 à la place.
Option 2. Notification d’événement existante : Configurez Amazon Simple Notification Service (SNS) en tant que diffuseur pour partager les notifications d’un chemin donné avec plusieurs points de terminaison (ou « abonnés », par exemple files d’attente SQS ou charges de travail AWS Lambda), y compris la file d’attente SQS de Snowflake pour l’automatisation de Snowpipe. Une notification d’événement S3 publiée par SNS informe Snowpipe via une file d’attente SQS lorsque les fichiers sont prêts à être chargés.
Note
Nous recommandons cette option si vous prévoyez d’utiliser Réplication des zones de préparation, des canaux et de l’historique des chargements. Vous pouvez également migrer de l’option 1 vers l’option 2 après avoir créé un groupe de réplication ou de basculement. Pour plus d’informations, voir Migration vers Amazon Simple Notification Service (SNS).
Option 3. Configurer Amazon EventBridge pour automatiser Snowpipe : Comme pour l’option 2, vous pouvez également activer Amazon EventBridge pour les compartiments S3 et créer des règles pour envoyer des notifications aux sujets SNS.
Option 1 : Création d’une nouvelle notification d’événement S3 pour automatiser Snowpipe¶
Cette section décrit l’option la plus courante pour déclencher automatiquement les chargements de données Snowpipe à l’aide de notifications Amazon SQS (Simple Queue Service) pour un compartiment S3. Les étapes expliquent comment créer une notification d’événement pour le chemin cible (ou « préfixe » dans la terminologie AWS) dans votre compartiment S3 dans lequel vos fichiers de données sont stockés.
Important
S’il existe une notification d’événement en conflit pour votre compartiment S3, utilisez plutôt Option 2 : Configuration d’Amazon SNS pour automatiser Snowpipe à l’aide de notifications SQS (dans cette rubrique). Les règles AWS interdisent la création de notifications en conflit pour le même chemin cible.
Le diagramme suivant montre le déroulement du processus d’intégration automatique Snowpipe :
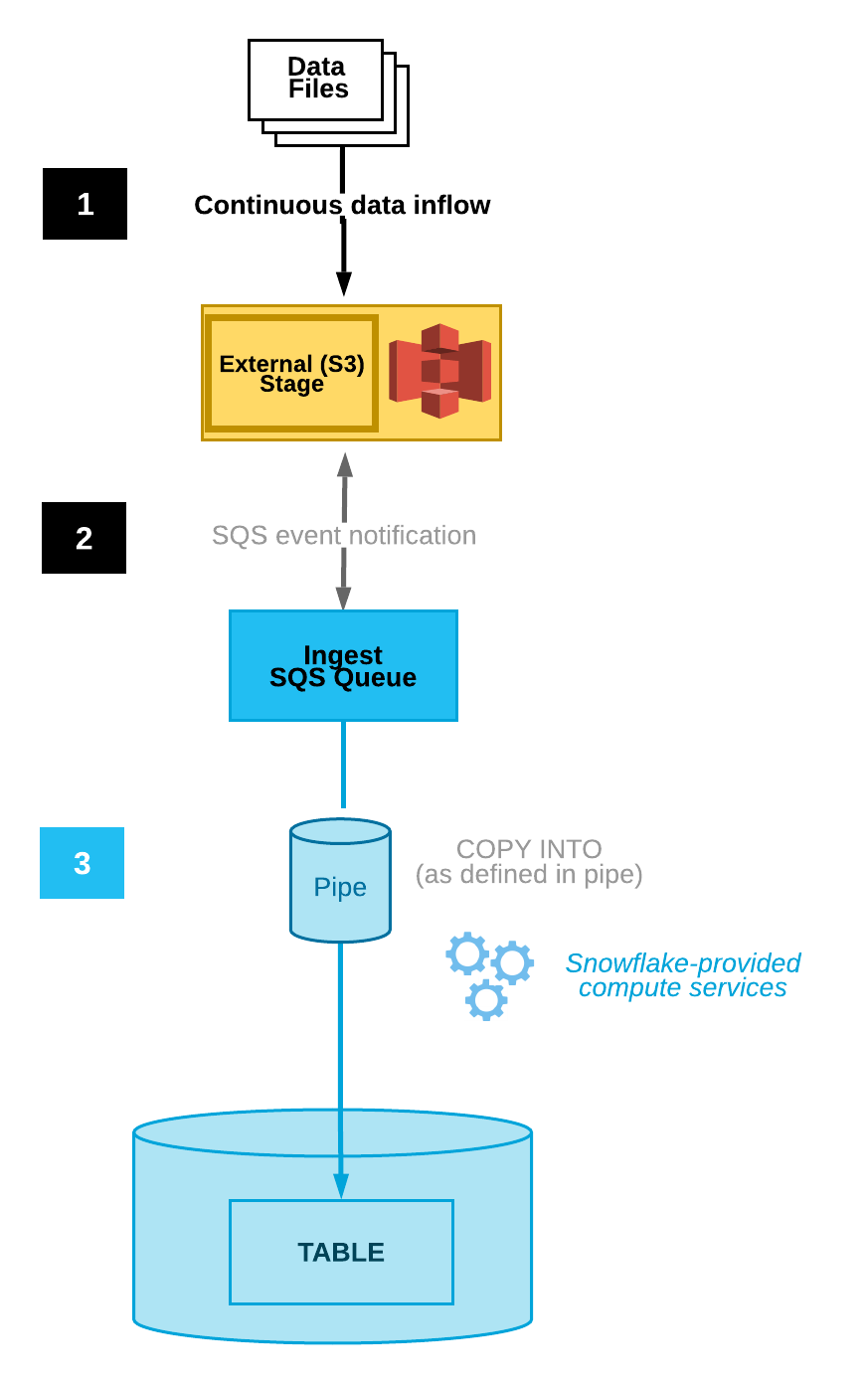
Les fichiers de données sont chargés dans une zone de préparation.
Une notification d’événement S3 informe Snowpipe via une file d’attente SQS que les fichiers sont prêts à être chargés. Snowpipe copie les fichiers dans une file d’attente.
Un entrepôt virtuel fourni par Snowflake charge les données des fichiers en file d’attente dans la table cible en fonction des paramètres définis dans le canal spécifié.
Note
Les instructions de cette rubrique supposent qu’une table cible existe déjà dans la base de données Snowflake où vos données seront chargées.
Étape 1 : Création d’une zone de préparation (si nécessaire)¶
Créez une zone de préparation externe qui fait référence à votre compartiment S3 à l’aide de la commande CREATE STAGE. Snowpipe va chercher vos fichiers de données dans la zone de préparation et les mettre temporairement en file d’attente avant de les charger dans votre table cible. Vous pouvez aussi utiliser une zone de préparation externe.
Note
Pour configurer un accès sécurisé à l’emplacement de stockage Cloud, voir Configuration de l’accès sécurisé au stockage Cloud (dans cette rubrique).
Pour faire référence à une intégration de stockage dans l’instruction CREATE STAGE, le rôle doit avoir le privilège USAGE sur l’objet d’intégration de stockage.
L’exemple suivant crée une zone de préparation nommée mystage dans le schéma actif de la session utilisateur. L’URL de stockage Cloud inclut le chemin files. La zone de préparation fait référence à une intégration de stockage nommée my_storage_int :
Étape 2 : Création d’un canal avec l’intégration automatique activée¶
Créez un canal à l’aide de la commande CREATE PIPE. Le canal définit l’instruction COPY INTO <table> utilisée par Snowpipe pour charger les données de la file d’attente d’acquisition dans la table cible.
L’exemple suivant crée un canal nommé mypipe dans le schéma actif de la session utilisateur. Le canal charge toutes les données des fichiers mis dans la zone de préparation mystage dans la table mytable :
Le paramètre AUTO_INGEST = TRUE spécifie qu’il faut lire les notifications d’événements envoyées d’un compartiment S3 à une file d’attente SQS lorsque de nouvelles données sont prêtes à être chargées.
Important
Comparez la référence de la zone de préparation dans la définition de canal avec les canaux existants. Vérifiez que les chemins de répertoire du même compartiment S3 ne se chevauchent pas. Sinon, plusieurs canaux pourraient charger le même ensemble de fichiers de données plusieurs fois dans une ou plusieurs tables cibles. Cela peut se produire, par exemple, lorsque plusieurs zones de préparation font référence au même compartiment S3 avec différents niveaux de granularité, tels que s3://mybucket/path1 et s3://mybucket/path1/path2. Dans ce cas d’utilisation, si les fichiers sont stockés dans s3://mybucket/path1/path2, les canaux pour les deux zones de préparation chargeraient une copie des fichiers.
Cela diffère de la configuration manuelle de Snowpipe (avec l’intégration automatique désactivée), qui oblige les utilisateurs à soumettre un ensemble de fichiers nommé à une API REST pour mettre en file d’attente les fichiers à charger. Lorsque l’intégration automatique est activée, chaque canal reçoit une liste de fichiers générée à partir des notifications d’événement S3. Des précautions supplémentaires sont nécessaires pour éviter la duplication des données.
Étape 3 : Configuration de la sécurité¶
Pour chaque utilisateur qui exécutera des chargements de données continus avec Snowpipe, accordez suffisamment de privilèges aux objets pour la charge de données (c’est-à-dire la base de données, le schéma et la table cibles).
Note
Pour suivre le principe général du moindre privilège, nous recommandons de créer un utilisateur et un rôle séparés à utiliser pour l’intégration de fichiers à l’aide d’un canal. L’utilisateur doit être créé avec ce rôle comme rôle par défaut.
L’utilisation de Snowpipe nécessite un rôle avec les privilèges suivants :
Objet |
Privilège |
Remarques |
|---|---|---|
Canal nommé |
OWNERSHIP |
|
Zone de préparation nommée |
USAGE , READ |
|
Format de fichier nommé |
USAGE |
Facultatif ; nécessaire uniquement si la zone de préparation que vous avez créée dans Étape 1 : Étape 1 : Créer une zone de préparation (si nécessaire) fait référence à un format de fichier nommé. |
Base de données cible |
USAGE |
|
Schéma cible |
USAGE |
|
Table cible |
INSERT , SELECT |
Utilisez la commande GRANT <privilèges> … TO ROLE pour accorder ces privilèges au rôle.
Note
Seuls les administrateurs de sécurité (c.-à-d. les utilisateurs dotés du rôle SECURITYADMIN) ou un rôle supérieur, ou un autre rôle doté du privilège CREATE ROLE sur le compte et du privilège global MANAGE GRANTS, peuvent créer des rôles et octroyer des privilèges.
Par exemple, créez un rôle nommé snowpipe_role qui peut accéder à un ensemble d”snowpipe_db.public objets de base de données ainsi qu’à un canal nommé mypipe ; puis, accordez le rôle à un utilisateur :
Étape 4 : Configuration des notifications d’événement¶
Configurez les notifications d’événement pour votre compartiment S3 afin d’avertir Snowpipe lorsque de nouvelles données sont disponibles au chargement. La fonction d’intégration automatique repose sur des files d’attente SQS pour transmettre des notifications d’événement de S3 à Snowpipe.
Pour faciliter les choses, les files d’attente SQS de Snowpipe sont créées et gérées par Snowflake. Le résultat de la commande SHOW PIPES affiche le nom de ressource Amazon (ARN) de votre file d’attente SQS.
Exécutez la commande SHOW PIPES :
Notez l’ARN de la file d’attente SQS pour la zone de préparation de la colonne
notification_channel. Copiez l’ARN dans un emplacement approprié.Note
Conformément aux directives AWS, Snowflake ne désigne pas plus d’une file d’attente SQS par région S3 AWS. Une file d’attente SQS peut être partagée entre plusieurs compartiments dans la même région à partir du même compte AWS. La file d’attente SQS coordonne les notifications pour tous les canaux connectant les zones de préparation externes des compartiments S3 aux tables cibles. Lorsqu’un fichier de données est chargé dans le compartiment, tous les canaux correspondant au chemin du répertoire de la zone de préparation effectuent un chargement unique du fichier dans les tables cibles correspondantes.
Connectez-vous à la console Amazon S3.
Configurez une notification d’événement pour votre compartiment S3 à l’aide des instructions fournies dans la documentation Amazon S3. Remplissez les champs comme suit :
Name : nom de la notification d’événement (par exemple
Auto-ingest Snowflake).Events : sélectionnez l’option ObjectCreate (All).
Send to : sélectionnez SQS Queue dans la liste déroulante.
SQS : sélectionnez Add SQS queue ARN dans la liste déroulante.
SQS queue ARN : collez le nom de la file d’attente SQS à partir de la sortie SHOW PIPES.
Note
Ces instructions créent une notification d’événement unique qui surveille l’activité de l’ensemble du compartiment S3. C’est l’approche la plus simple. Cette notification traite tous les canaux configurés à un niveau plus granulaire dans le répertoire de compartiment S3. Snowpipe charge uniquement les fichiers de données comme spécifié dans les définitions de canaux. Notez cependant qu’un nombre élevé de notifications d’activité en dehors d’une définition de canal pourrait avoir un impact négatif sur la vitesse à laquelle Snowpipe filtre les notifications et se met en marche.
Dans les étapes ci-dessus, vous pouvez également configurer un ou plusieurs chemins et/ou extensions de fichiers (ou préfixes et suffixes, dans la terminologie AWS) pour filtrer l’activité des événements. Pour obtenir des instructions, voir les informations de filtrage du nom de la clé d’objet dans la rubrique concernée de la documentation AWS. Répétez ces étapes pour chaque chemin ou extension de fichier supplémentaire que vous souhaitez que la notification surveille.
Notez que AWS limite le nombre de ces configurations de file d’attente de notification à un maximum de 100 par compartiment S3.
Notez également que AWS n’autorise pas les configurations de file d’attente qui se chevauchent (entre les notifications d’événement) pour le même compartiment S3. Par exemple, si une notification existante est configurée pour s3://mybucket/load/path1, vous ne pouvez pas en créer une autre à un niveau supérieur, tel que s3://mybucket/load, ou inversement.
Snowpipe avec l’intégration automatique est maintenant configuré !
Lorsque de nouveaux fichiers de données sont ajoutés au compartiment S3, la notification d’événement indique à Snowpipe de les charger dans la table cible définie dans le canal.
Étape 5 : Chargement de fichiers historiques¶
Pour charger les retards de traitement des fichiers de données qui existaient dans la zone de préparation externe avant que les notifications SQS aient été configurées, voir Chargement de données historiques.
Étape 6 : Suppression de fichiers en zone de préparation¶
Supprimez les fichiers en zone de préparation après avoir chargé avec succès les données et lorsque vous n’avez plus besoin des fichiers. Pour obtenir des instructions, voir Suppression de fichiers en zone de préparation après le chargement des données par Snowpipe.
Option 2 : Configuration d’Amazon SNS pour automatiser Snowpipe à l’aide de notifications SQS¶
Cette section explique comment déclencher automatiquement les chargements de données Snowpipe à l’aide de notifications Amazon SQS (Simple Queue Service) pour un compartiment S3. Les étapes expliquent comment configurer Amazon Simple Notification Service (SNS) en tant que diffuseur afin de publier des notifications d’événement pour votre compartiment S3 à plusieurs abonnés (par exemple, files d’attente SQS ou charges de travail AWS Lambda), y compris la file d’attente SQS de Snowflake pour l’automatisation de Snowpipe.
Note
Ces instructions supposent qu’une notification d’événement existe pour le chemin cible dans votre compartiment S3 où se trouvent vos fichiers de données. Si aucune notification d’événement n’existe, vous avez deux possibilités :
Suivez plutôt Option 1 : Création d’une nouvelle notification d’événement S3 pour automatiser Snowpipe (dans cette rubrique).
Créez une notification d’événement pour votre compartiment S3, puis suivez les instructions de cette rubrique. Pour plus d’informations, voir la documentation Amazon S3.
Le diagramme suivant illustre le flux de processus pour l’intégration automatique de Snowpipe avec Amazon SNS :
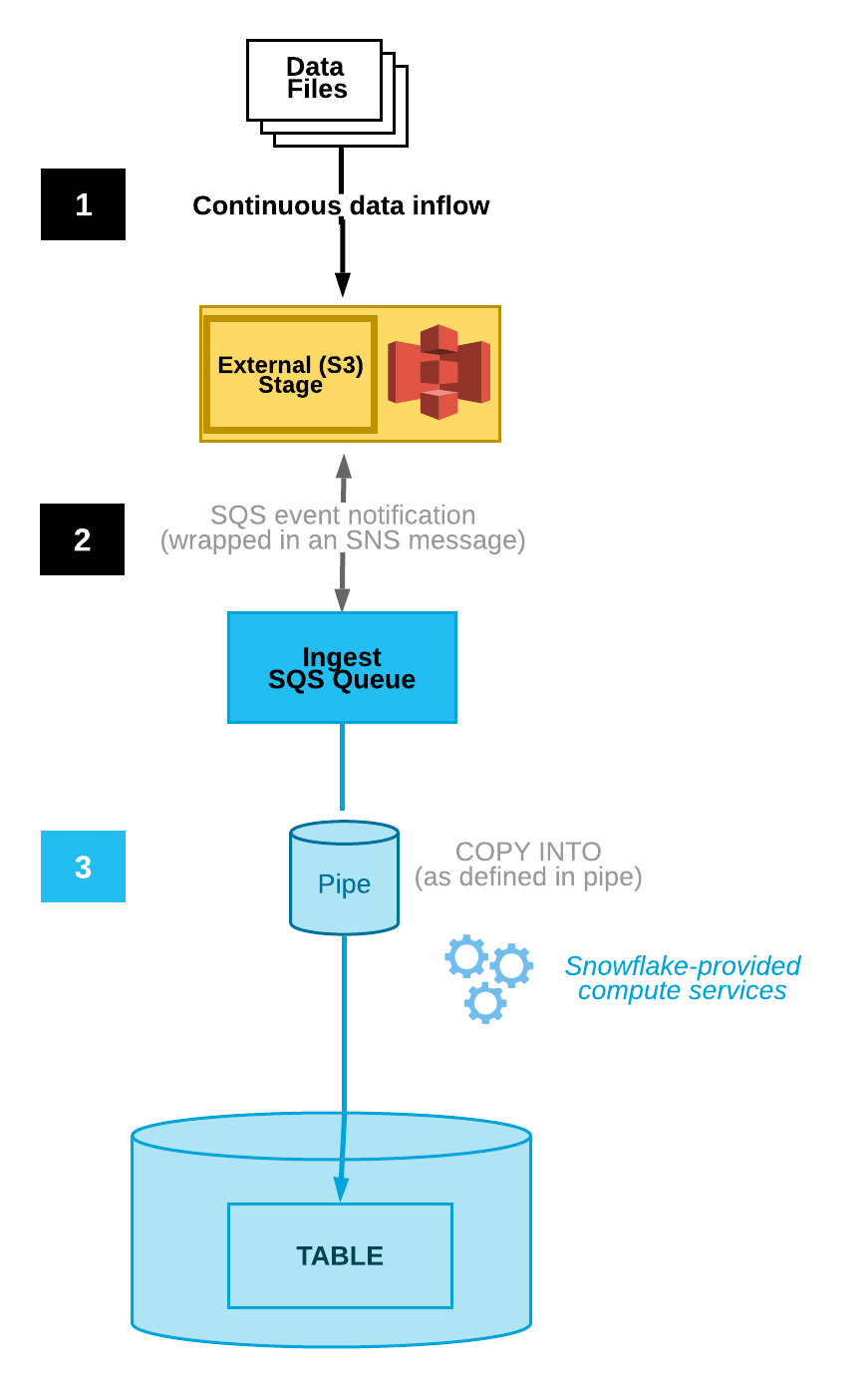
Les fichiers de données sont chargés dans une zone de préparation.
Une notification d’événement S3 publiée par SNS informe Snowpipe via une file d’attente SQS que les fichiers sont prêts à être chargés. Snowpipe copie les fichiers dans une file d’attente.
Un entrepôt virtuel fourni par Snowflake charge les données des fichiers en file d’attente dans la table cible en fonction des paramètres définis dans le canal spécifié.
Note
Les instructions supposent qu’une table cible existe déjà dans la base de données Snowflake où vos données seront chargées.
L’ingestion automatique de Snowpipe prend en charge les sujets SNS AWS chiffrés avec KMS. Pour plus d’informations, reportez-vous à Chiffrement au repos.
Conditions préalables : Créer un sujet et un abonnement Amazon SNS¶
Créez un sujet SNS dans votre compte AWS pour gérer tous les messages de l’emplacement de zone de préparation Snowflake sur votre compartiment S3.
Créez un abonnement pour vos destinations cibles afin de recevoir les notifications d’événements S3 (par exemple, d’autres files d’attente SQS ou des charges de travail Lambda AWS) en lien avec ce sujet. SNS publie des notifications d’événement pour votre compartiment à tous les abonnés du sujet.
Pour obtenir des instructions, reportez-vous à la documentation SNS.
Étape 1 : S’abonner à la file d’attente SQS de Snowflake dans le sujet SNS¶
Connectez-vous à la console de gestion AWS.
Dans le tableau de bord d’accueil, sélectionnez Simple Notification Service (SNS).
Cliquez sur Topics dans le volet de navigation de gauche.
Recherchez le sujet de votre compartiment S3. Notez le sujet ARN.
À l’aide d’un client Snowflake, interrogez la fonction système SYSTEM$GET_AWS_SNS_IAM_POLICY avec l’ARN de votre sujet SNS :
La fonction renvoie une stratégie IAM accordant à la file d’attente SQS de Snowflake l’autorisation de s’abonner au sujet SNS.
Par exemple :
Revenez à la console de gestion AWS. Cliquez sur Topics dans le volet de navigation de gauche.
Sélectionnez le sujet de votre compartiment S3 et cliquez sur le bouton Edit. La page Edit s’ouvre.
Cliquez sur Access policy - Optional pour développer cette zone de la page.
Fusionnez l’ajout de stratégie IAM des résultats de la fonction SYSTEM$GET_AWS_SNS_IAM_POLICY dans le document JSON.
Par exemple :
Politique IAM originale (abrégée) :
Politique IAM fusionnée :
Ajoutez une autorisation de politique supplémentaire pour permettre à S3 de publier des notifications d’événement pour le compartiment dans le sujet SNS.
Par exemple (en utilisant le sujet ARN SNS et le compartiment S3 utilisés dans ces instructions) :
Politique IAM fusionnée :
Cliquez sur Save changes.
Étape 2 : Création d’une zone de préparation (si nécessaire)¶
Créez une zone de préparation externe qui fait référence à votre compartiment S3 à l’aide de la commande CREATE STAGE. Snowpipe va chercher vos fichiers de données dans la zone de préparation et les mettre temporairement en file d’attente avant de les charger dans votre table cible.
Vous pouvez aussi utiliser une zone de préparation externe.
Note
Pour configurer un accès sécurisé à l’emplacement de stockage Cloud, voir Configuration de l’accès sécurisé au stockage Cloud (dans cette rubrique).
L’exemple suivant crée une zone de préparation nommée mystage dans le schéma actif de la session utilisateur. L’URL de stockage Cloud inclut le chemin files. La zone de préparation fait référence à une intégration de stockage nommée my_storage_int :
Étape 3 : Création d’un canal avec l’intégration automatique activée¶
Créez un canal à l’aide de la commande CREATE PIPE. Le canal définit l’instruction COPY INTO <table> utilisée par Snowpipe pour charger les données de la file d’attente d’acquisition dans la table cible. Dans l’instruction COPY, identifiez l’ARN du sujet SNS depuis Conditions préalables : Créer un sujet et un abonnement Amazon SNS.
L’exemple suivant crée un canal nommé mypipe dans le schéma actif de la session utilisateur. Le canal charge toutes les données des fichiers mis dans la zone de préparation mystage dans la table mytable :
Où :
AUTO_INGEST = TRUESpécifie de lire les notifications d’événements envoyées d’un compartiment S3 à une file d’attente SQS lorsque de nouvelles données sont prêtes à être chargées.
AWS_SNS_TOPIC = '<sns_topic_arn>'Spécifie l’ARN du sujet SNS de votre compartiment S3, par exemple
arn:aws:sns:us-west-2:001234567890:s3_mybucketdans l’exemple actuel. L’instruction CREATE PIPE souscrit la file d’attente Snowflake SQS à la rubrique SNS spécifiée. Notez que le canal ne copiera que les fichiers dans la file d’attente d’intégration déclenchée par des notifications d’événement via le sujet SNS.
Pour supprimer l’un des paramètres d’un canal, il est actuellement nécessaire de recréer le canal à l’aide de la syntaxe CREATE OR REPLACE PIPE.
Important
Vérifiez que la référence de l’emplacement de stockage dans l’instruction COPY INTO <table> ne chevauche pas la référence dans les canaux existants du compte. Sinon, plusieurs canaux pourraient charger le même ensemble de fichiers de données dans les tables cibles. Par exemple, cette situation peut se produire lorsque plusieurs définitions de canaux font référence au même emplacement de stockage avec différents niveaux de granularité, tels que <storage_location>/path1/ et <storage_location>/path1/path2/. Dans cet exemple, si les fichiers sont en zone de préparation dans <storage_locationstorage_location>/path1/path2/, les deux canaux chargeront une copie des fichiers.
Visualisez les instructions COPY INTO <table> dans les définitions de tous les canaux du compte en exécutant SHOW PIPES ou en interrogeant la vue PIPES dans Account Usage ou la vue PIPES dans Information Schema.
Étape 4 : Configuration de la sécurité¶
Pour chaque utilisateur qui exécutera des chargements de données continus avec Snowpipe, accordez suffisamment de privilèges aux objets pour la charge de données (c’est-à-dire la base de données, le schéma et la table cibles).
Note
Pour suivre le principe général du moindre privilège, nous recommandons de créer un utilisateur et un rôle séparés à utiliser pour l’intégration de fichiers à l’aide d’un canal. L’utilisateur doit être créé avec ce rôle comme rôle par défaut.
L’utilisation de Snowpipe nécessite un rôle avec les privilèges suivants :
Objet |
Privilège |
Remarques |
|---|---|---|
Canal nommé |
OWNERSHIP |
|
Intégration de stockage nommée |
USAGE |
Nécessaire si la zone de préparation que vous avez créée dans Étape 2 : Créer une zone de préparation (si nécessaire) fait référence à une intégration de stockage. |
Zone de préparation nommée |
USAGE , READ |
|
Format de fichier nommé |
USAGE |
Facultatif ; nécessaire uniquement si la zone de préparation que vous avez créée dans Étape 2 : Créer une zone de préparation (si nécessaire) fait référence à un format de fichier nommé. |
Base de données cible |
USAGE |
|
Schéma cible |
USAGE |
|
Table cible |
INSERT , SELECT |
Utilisez la commande GRANT <privilèges> … TO ROLE pour accorder ces privilèges au rôle.
Note
Seuls les administrateurs de sécurité (c’est-à-dire les utilisateurs ayant le rôle SECURITYADMIN) ou ayant un rôle supérieur peuvent créer des rôles.
Par exemple, créez un rôle nommé snowpipe_role qui peut accéder à un ensemble d”snowpipe_db.public objets de base de données ainsi qu’à un canal nommé mypipe ; puis, accordez le rôle à un utilisateur :
Snowpipe avec l’intégration automatique est maintenant configuré !
Lorsque de nouveaux fichiers de données sont ajoutés au compartiment S3, la notification d’événement indique à Snowpipe de les charger dans la table cible définie dans le canal.
Étape 5 : Chargement de fichiers historiques¶
Pour charger les retards de traitement des fichiers de données qui existaient dans la zone de préparation externe avant que les notifications SQS aient été configurées, voir Chargement de données historiques.
Étape 6 : Suppression de fichiers en zone de préparation¶
Supprimez les fichiers en zone de préparation après avoir chargé avec succès les données et lorsque vous n’avez plus besoin des fichiers. Pour obtenir des instructions, voir Suppression de fichiers en zone de préparation après le chargement des données par Snowpipe.
Option 3 : Configuration d’Amazon EventBridge pour automatiser Snowpipe¶
Comme pour l’option 2, vous pouvez également configurer Amazon EventBridge pour automatiser Snowpipe.
Étape 1 : Créer un sujet SNS Amazon¶
Suivez Conditions préalables : Créer un sujet et un abonnement Amazon SNS (dans cette rubrique).
Étape 2 : Créer une règle EventBridge pour vous abonner à des compartiments S3 et envoyer des notifications au sujet SNS¶
Activer Amazon EventBridge pour les compartiments S3.
Créez des règles EventBridge pour envoyer des notifications au sujet SNS créé à l’étape 1.
Étape 3 : Configuration d’Amazon SNS pour automatiser Snowpipe à l’aide de notifications SQS¶
Suivez Option 2 : Configuration d’Amazon SNS pour automatiser Snowpipe à l’aide de notifications SQS (dans cette rubrique).
Sortie SYSTEM$PIPE_STATUS¶
La fonction SYSTEM$PIPE_STATUS récupère une représentation JSON du statut actuel d’un canal.
Pour les canaux avec AUTO_INGEST défini sur TRUE, la fonction renvoie un objet JSON contenant les paires nom/valeur suivantes (si applicable au statut actuel du canal) :
{« executionState »: »<valeur> », »oldestFileTimestamp »:<valeur>, »pendingFileCount »:<valeur>, »notificationChannelName »: »<valeur> », »numOutstandingMessagesOnChannel »:<valeur>, »lastReceivedMessageTimestamp »: »<valeur> », »lastForwardedMessageTimestamp »: »<valeur> », »error »:<valeur>, »fault »:<valeur>}
Pour la description des valeurs de sortie, consultez la rubrique de référence de la fonction SQL.