Snowflake Connector pour Kafka avec Snowpipe Streaming Classic¶
Important
Avis préalable : Cette page décrit l’utilisation de Snowpipe Streaming Classic avec le connecteur Kafka (v3 et versions antérieures). Pour les nouvelles implémentations, Snowflake recommande le Snowflake Connector pour Kafka (v4), qui utilise l’architecture hautes performances de manière native.
Aucun changement immédiat n’est requis. Vos charges de travail actuelles continuent d’être entièrement prises en charge.
Vous pouvez remplacer Snowpipe par Snowpipe Streaming dans votre chaîne de chargement de données depuis Kafka. Lorsque le seuil spécifié pour le vidage de la mémoire tampon (temps, mémoire ou nombre de messages) est atteint, le connecteur appelle l’API Snowpipe Streaming (« API ») pour écrire des lignes de données dans les tables Snowflake. Cette architecture permet de réduire les latences de chargement et, par conséquent, les coûts de chargement de volumes de données similaires.
La version 2.0.0 (ou plus récente) du connecteur Kafka est une exigence pour l’utilisation de Snowpipe Streaming Classic. Le connecteur Kafka avec Snowpipe Streaming Classic inclut le Snowflake Ingest SDK et supporte la diffusion en continu de lignes des sujets Apache Kafka directement dans les tables cibles.
Version minimale requise¶
La version minimale requise du connecteur Kafka qui prend en charge Snowpipe Streaming est 2.0.0.
Propriétés de configuration de Kafka¶
Enregistrez vos paramètres de connexion dans le fichier de propriétés du connecteur Kafka. Pour plus d’informations, voir Configuration du connecteur Kafka.
Propriétés requises¶
Ajoutez ou modifiez vos paramètres de connexion dans le fichier de propriétés du connecteur Kafka. Pour plus d’informations, voir Configuration du connecteur Kafka.
snowflake.ingestion.methodNécessaire uniquement si vous utilisez le connecteur Kafka comme client d’ingestion en continu. Indique s’il faut utiliser Snowpipe Streaming ou Snowpipe standard pour charger les données de votre sujet Kafka. Les valeurs prises en charge sont les suivantes :
SNOWPIPE_STREAMINGSNOWPIPE(par défaut)
Aucun paramètre supplémentaire n’est requis pour choisir le service backend afin de mettre en file d’attente et charger les données des sujets. Configurez les propriétés supplémentaires dans le fichier de propriétés de votre connecteur Kafka comme d’habitude.
snowflake.role.nameRôle de contrôle d’accès à utiliser lors de l’insertion des lignes dans la table.
Propriétés d’optimisation du client¶
enable.streaming.client.optimizationIndique si l’optimisation pour un seul client doit être activée. Cette propriété est prise en charge par la version 2.1.2 du connecteur Kafka et les versions ultérieures. Elle est activée par défaut.
Avec l’optimisation pour un seul client, un seul client est créé pour plusieurs partitions de sujets par connecteur Kafka. Cette fonction permet de réduire la durée d’exécution du client et de diminuer le coût de la migration en créant des fichiers plus volumineux.
- Valeurs:
truefalse
- Par défaut:
true
Notez que dans un scénario de débit élevé (par exemple, 50 MB/s par connecteur), l’activation de cette propriété peut entraîner une latence ou un coût plus élevé. Nous vous recommandons de désactiver cette propriété pour les scénarios à haut débit.
Propriétés de la mémoire tampon et de requête¶
buffer.flush.timeNombre de secondes entre les vidages de la mémoire tampon ; chaque vidage entraîne des opérations d’insertion pour les enregistrements mis en mémoire tampon. Le connecteur Kafka appelle Snowpipe Streaming API une fois après chaque vidage.
La valeur minimale prise en charge pour la propriété
buffer.flush.timeest1(en secondes). Pour des débits de données moyens plus élevés, nous vous suggérons de diminuer la valeur par défaut afin d’améliorer la latence. Si le coût est plus important que la latence, vous pouvez augmenter le temps de vidage du tampon. Veillez à vider la mémoire tampon de Kafka avant qu’elle ne soit pleine afin d’éviter les exceptions liées à l’absence de mémoire.- Valeurs:
Minimum :
1Maximum : Pas de limite supérieure
- Par défaut:
10
Notez que Snowpipe Streaming vide automatiquement les données toutes les secondes, ce qui est différent du temps de vidage de tampon du connecteur Kafka. Une fois que le temps de vidage de tampon Kafka est atteint, les données seront envoyées avec une seconde de latence à Snowflake par le biais de Snowpipe Streaming. Pour plus d’informations, voir Latence de Snowpipe Streaming.
buffer.count.recordsNombre d’enregistrements mis en mémoire tampon par partition Kafka avant leur acquisition dans Snowflake.
- Valeurs:
Minimum :
1Maximum : Pas de limite supérieure
- Par défaut:
10000
buffer.size.bytesTaille cumulée en octets des enregistrements mis en mémoire tampon par partition Kafka avant d’être ingérés dans Snowflake en tant que fichiers de données.
Les enregistrements sont compressés lorsqu’ils sont écrits dans des fichiers de données. Par conséquent, la taille des enregistrements dans la mémoire tampon peut être supérieure à la taille des fichiers de données créés à partir des enregistrements.
- Valeurs:
Minimum :
1Maximum : Pas de limite supérieure
- Par défaut:
20000000(20 MB)
snowflake.streaming.max.client.lagSpécifie la fréquence à laquelle Snowflake Ingest Java nettoie les données vers Snowflake, en secondes.
Une valeur faible maintient la latence à un niveau bas, mais peut baisser la performance des résultats de requête, en particulier lorsque
snowflake.streaming.enable.single.bufferest activé. Pour plus d’informations, voir les configurations de latence recommandées pour Snowpipe Streaming.- Valeurs:
Minimum :
1secondeMaximum :
600secondes
- Par défaut:
30secondes pour les versions 3.1.1 et ultérieures,120secondes pour les versions 3.0.0 et 3.1.0, autrement1seconde
snowflake.streaming.enable.single.bufferSpécifie s’il faut activer la mémoire tampon unique pour Snowpipe Streaming et ignorer la mise en mémoire tampon des données dans la mémoire tampon interne du connecteur.
Cette propriété est prise en charge par le connecteur Kafka version 2.3.1 et ultérieure.
Le connecteur Streaming utilise une mémoire tampon interne en plus de celle fournie par Snowflake Ingest Java. En définissant cette propriété sur
true, le connecteur Kafka ignore la mémoire tampon interne afin d’obtenir une latence plus faible.Notez que la définition de cette propriété sur
truerendbuffer.flush.timeetbuffer.count.recordsnon pertinents.- Valeurs:
truefalse
- Par défaut:
truepour la version 3.0.0 et ultérieure,falsesinon
En plus des propriétés du connecteur Kafka, notez la propriété max.poll.records du consommateur Kafka, qui contrôle le nombre maximum d’enregistrements renvoyés par Kafka à Kafka Connect en une seule requête. La valeur par défaut de 500 peut être augmentée, mais il faut tenir compte des contraintes de mémoire. Pour plus d’informations sur cette propriété, voir la documentation de votre package Kafka :
Gestion des erreurs et propriétés DLQ¶
errors.toleranceSpécifie comment gérer les erreurs rencontrées par le connecteur Kafka :
Cette propriété prend en charge les valeurs suivantes :
- Valeurs:
NONE: Arrêter le chargement des données à la première erreur rencontrée.ALL: Ignorer toutes les erreurs et continuez à charger les données.
- Par défaut:
NONE
errors.log.enableSpécifie s’il faut écrire les messages d’erreur dans le fichier journal de Kafka Connect.
Cette propriété prend en charge les valeurs suivantes :
- Valeurs:
TRUE: Écrire des messages d’erreur.FALSE: Ne pas écrire de messages d’erreur.
- Par défaut:
FALSE
errors.deadletterqueue.topic.nameSpécifie le nom du sujet DLQ (file d’attente de lettres mortes) dans Kafka pour la livraison de messages à Kafka qui n’ont pas pu être intégrés dans les tables Snowflake. Pour plus d’informations, voir Files d’attente de lettres mortes dans cette rubrique.
- Valeurs:
Chaîne de texte personnalisée
- Par défaut:
Aucun(e)
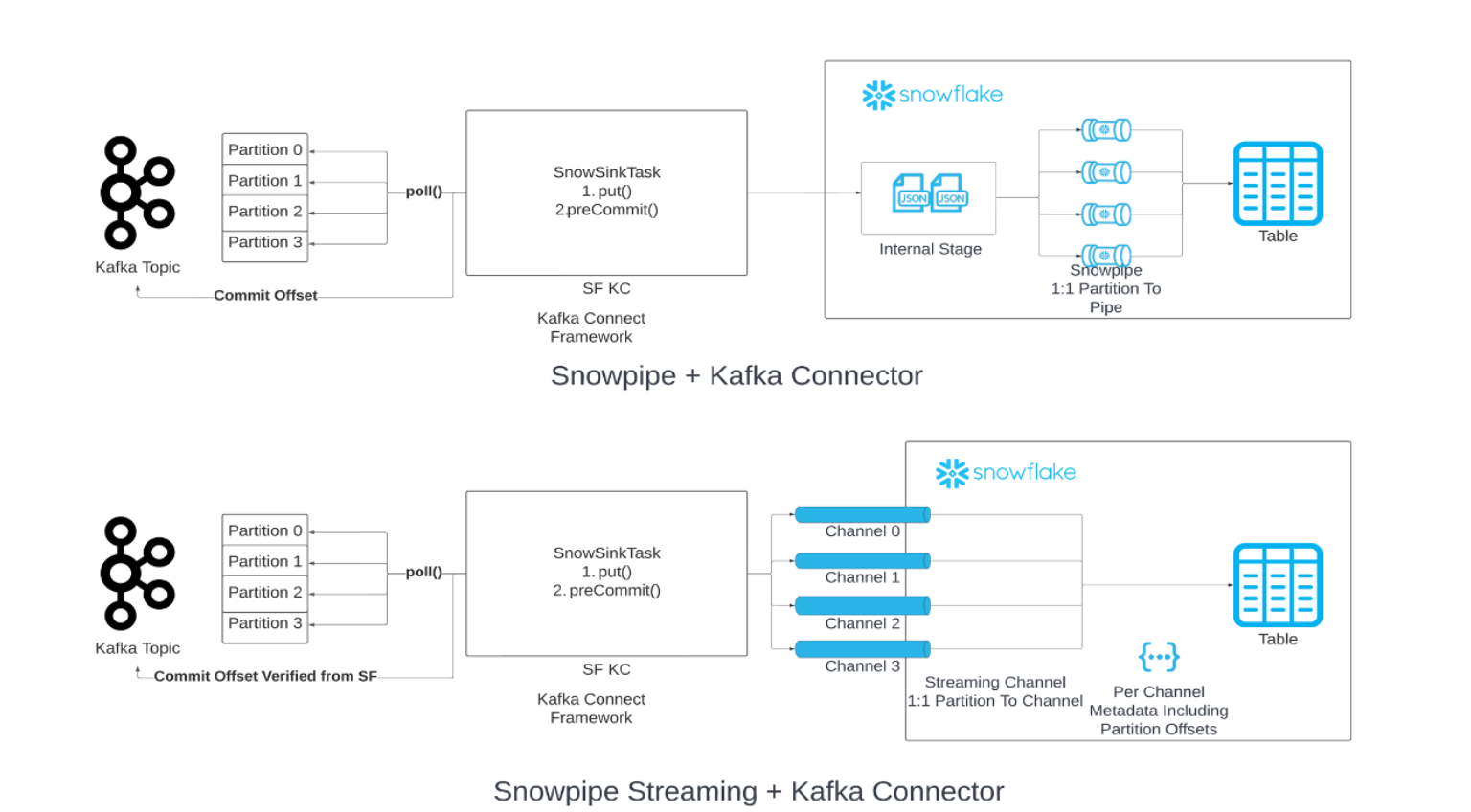
Sémantique unique et exacte¶
La sémantique unique et exacte garantit la livraison des messages Kafka sans duplication ni perte de données. Cette garantie de livraison est définie par défaut pour le connecteur Kafka avec Snowpipe Streaming.
Le connecteur Kafka adopte un mappage univoque entre la partition et le canal et utilise deux décalages distincts :
Décalage du consommateur : il s’agit du décalage le plus récent consommé par le consommateur et géré par Kafka.
Jeton de compensation : ce jeton suit le décalage le plus récent dans Snowflake et est géré par Snowflake.
Notez que le connecteur Kafka ne gère pas toujours les décalages manquants. Snowflake s’attend à ce que tous les enregistrements aient des décalages séquentiels croissants. Les décalages manquants interrompront le connecteur Kafka dans des cas d’utilisation spécifiques. Il est recommandé d’utiliser les enregistrements tombstone plutôt que les enregistrements NULL.
Le connecteur Kafka assure une livraison « exactly-once » en mettant en œuvre les meilleures pratiques suivantes :
Ouverture/réouverture d’un canal :
Lors de l’ouverture ou de la réouverture d’un canal pour une partition donnée, le connecteur Kafka utilise le dernier jeton de décalage engagé récupéré de Snowflake via l’API
getLatestCommittedOffsetTokencomme source de vérité et réinitialise le décalage du consommateur dans Kafka en conséquence.Si le décalage du consommateur n’est plus dans la période de conservation des données, une exception est lancée et vous pouvez déterminer de l’action appropriée à prendre.
Le seul scénario dans lequel le connecteur Kafka ne réinitialise pas le décalage du consommateur dans Kafka et l’utilise comme source de vérité est lorsque le jeton de décalage de Snowflake est NULL. Dans ce cas, le connecteur accepte le décalage envoyé par Kafka et le jeton de décalage est ensuite mis à jour.
Traitement des enregistrements :
Pour garantir une couche supplémentaire de sécurité contre les décalages non continus qui pourraient résulter de bogues potentiels dans Kafka, Snowflake maintient une variable en mémoire qui suit le dernier décalage traité. Snowflake n’accepte les lignes que si le décalage de la ligne actuelle est égal au dernier décalage traité plus un, ajoutant ainsi une couche de protection supplémentaire pour garantir que le processus d’ingestion est continu et précis.
Gestion des exceptions, des défaillances, des accidents et des reprises après sinistre :
Dans le cadre du processus de récupération, Snowflake respecte systématiquement la logique d’ouverture/réouverture du canal décrite précédemment en rouvrant le canal et en réinitialisant le décalage du consommateur avec le dernier jeton de décalage engagé. Ce faisant, Snowflake signale à Kafka d’envoyer les données à partir de la valeur de décalage qui est supérieure d’une unité au dernier jeton de décalage engagé, ce qui permet de reprendre l’ingestion à partir du point de défaillance sans perte de données.
Mise en œuvre d’un mécanisme de relance :
Pour tenir compte des problèmes transitoires potentiels, Snowflake incorpore un mécanisme de relance dans les appels API. Snowflake tente plusieurs fois ces appels API afin d’augmenter les chances de succès et d’atténuer le risque d’échecs intermittents affectant le processus d’ingestion.
Faire progresser le décalage des consommateurs :
À intervalles réguliers, Snowflake fait progresser le décalage du consommateur en utilisant le dernier jeton de décalage engagé pour s’assurer que le processus d’ingestion est continuellement aligné sur le dernier état des données dans Snowflake.
Convertisseurs¶
Snowpipe Streaming prend en charge de nombreux convertisseurs communautaires tels que les suivants :
io.confluent.connect.avro.AvroConverterorg.apache.kafka.connect.json.JsonConverterio.confluent.connect.protobuf.ProtobufConverterio.confluent.connect.json.JsonSchemaConverterorg.apache.kafka.connect.converters.ByteArrayConverterorg.apache.kafka.connect.storage.StringConverter
D’autres convertisseurs communautaires peuvent être pris en charge, mais n’ont pas été validés. Les convertisseurs Snowflake ne sont pas pris en charge avec Snowpipe Streaming.
Files d’attente de lettres mortes¶
Le connecteur Kafka avec Snowpipe Streaming prend en charge les files d’attente de lettres mortes (DLQ) pour les enregistrements interrompus ou les enregistrements qui ne peuvent être traités avec succès en raison d’une défaillance.
Pour plus d’informations sur la surveillance, voir la documentation d’Apache Kafka.
Détection et évolution des schémas¶
Le connecteur Kafka avec Snowpipe Streaming prend en charge la détection et l’évolution de schémas. La structure des tables dans Snowflake peut être définie et peut évoluer automatiquement pour prendre en charge la structure des nouvelles données Snowpipe Streaming chargée par le connecteur Kafka. Pour activer la détection et l’évolution des schémas pour le connecteur Kafka avec Snowpipe Streaming, configurez les propriétés Kafka suivantes :
snowflake.ingestion.methodsnowflake.enable.schematizationschema.registry.url
Pour plus d’informations, voir Détection de schémas et évolution du connecteur Kafka avec Snowpipe Streaming Classic.
Estimation de la latence d’ingestion¶
Pour estimer la latence d’ingestion, utilisez le champ SnowflakeConnectorPushTime dans RECORD_METADATA. Cet horodatage représente un moment précis où un enregistrement a été transféré dans une mémoire tampon SDK d’ingestion.
Pour plus d’informations sur le format RECORD_METADATA, voir Schéma de tables pour les rubriques Kafka.
Note
Ce champ ne représente pas le moment où un enregistrement est devenu visible dans une table Snowflake, car il ne prend pas en compte la configuration de la Latence de Snowpipe Streaming.
Facturation et utilisation¶
Pour des informations sur la facturation de Snowpipe Streaming, voir Coûts pour Snowpipe Streaming Classic.
Limitations¶
Limitations de Snowpipe Streaming¶
Limitations du basculement¶
Lorsqu’un groupe de basculement secondaire est promu en principal, le connecteur Kafka avec Snowpipe Streaming nécessite une interaction manuelle. La sémantique unique et exacte est toujours préservée.
Si la propriété enable.streaming.client.optimization est définie sur false, le connecteur Kafka doit être redémarré. Une fois que vous avez redémarré le connecteur, il ciblera un nouveau déploiement primaire.
Si la propriété`enable.streaming.client.optimization` est définie sur true, la JVM hôte sur laquelle le connecteur fonctionne doit être éteinte et redémarrée. Après le redémarrage de la JVM hôte, un connecteur Kafka nouvellement démarré ciblera un nouveau déploiement primaire.