Conector Snowflake para Kafka com Snowpipe Streaming clássico¶
Importante
Aviso prévio: Esta página documenta o uso do Snowpipe Streaming clássico com o conector Kafka (v3 e anterior). Para novas implementações, a Snowflake recomenda o Conector Snowflake para Kafka (v4), que usa nativamente a arquitetura de alto desempenho.
nenhuma alteração imediata é necessária. Suas cargas de trabalho atuais continuam sendo totalmente compatíveis.
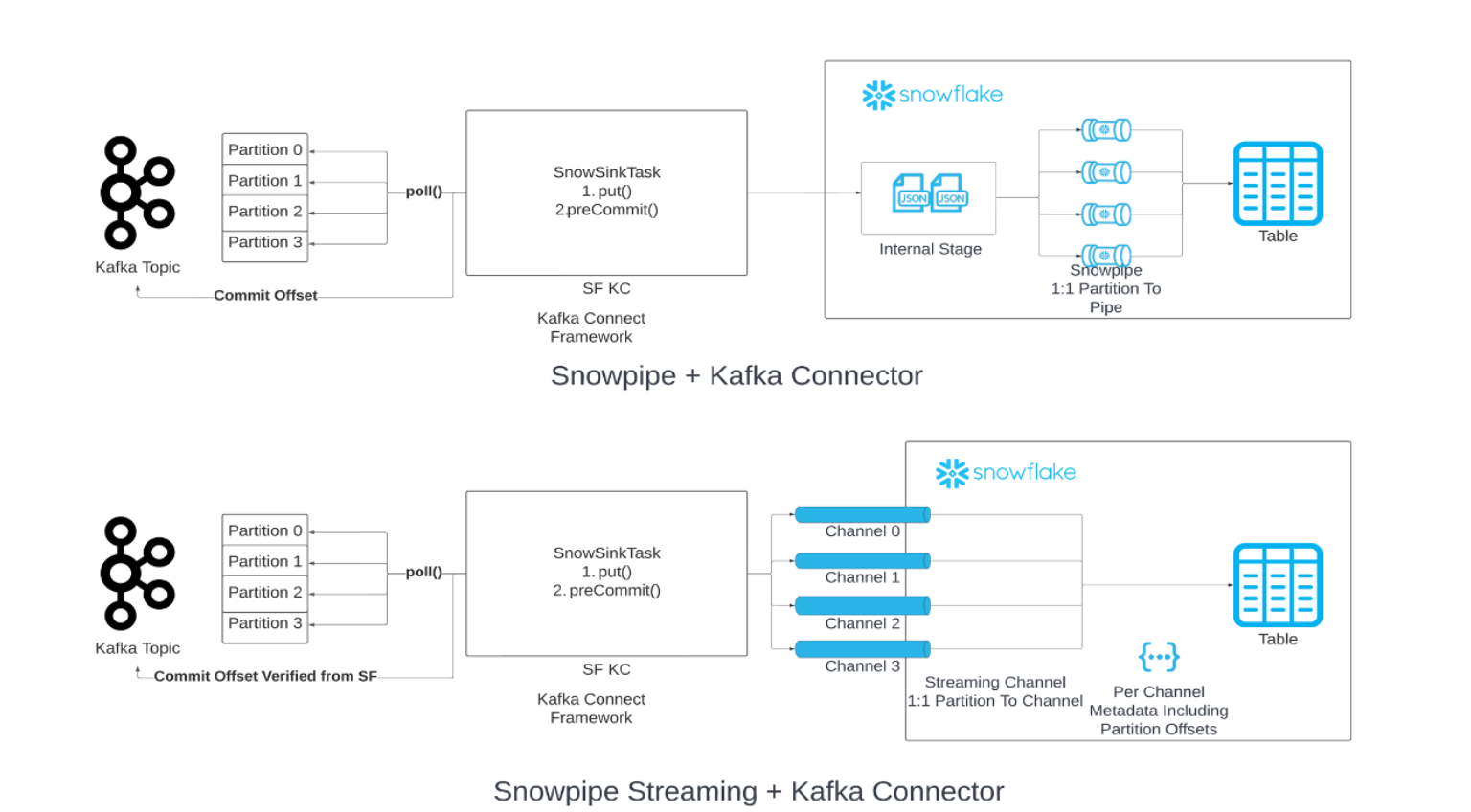
Você pode substituir o Snowpipe por Snowpipe Streaming em sua cadeia de carregamento de dados de Kafka. Quando o limite de buffer de liberação especificado (tempo, memória ou número de mensagens) é atingido, o conector chama a API do Snowpipe Streaming (“API“) para gravar linhas de dados nas tabelas do Snowflake. Esta arquitetura resulta em latências de carga mais baixas, com custos correspondentes mais baixos para carregar volumes de dados similares.
A versão 2.0.0 (ou posterior) do conector Kafka é necessária para uso com o Snowpipe Streaming Classic. O conector Kafka com o Snowpipe Streaming Classic inclui o Snowflake Ingest SDK e oferece suporte a linhas de fluxo de tópicos do Apache Kafka diretamente nas tabelas de destino.
Versão mínima exigida¶
A versão mínima necessária do conector Kafka compatível com Snowpipe Streaming é 2.0.0.
Propriedades de configuração do Kafka¶
Salve suas configurações de conexão no arquivo de propriedades do conector Kafka. Para obter mais informações, consulte Configuração do conector Kafka.
Propriedades obrigatórias¶
Adicione ou edite suas configurações de conexão no arquivo de propriedades do conector Kafka. Para obter mais informações, consulte Configuração do conector Kafka.
snowflake.ingestion.methodNecessário somente se o conector Kafka for utilizado como o cliente que ingere o streaming. Especifica se deve usar o Snowpipe Streaming ou Snowpipe padrão para carregar seus dados de tópico Kafka. Os valores suportados são:
SNOWPIPE_STREAMINGSNOWPIPE(padrão)
Nenhuma configuração adicional é necessária para escolher o serviço de back-end para enfileirar e carregar os dados de tópico. Configure propriedades adicionais em seu arquivo de propriedades do conector Kafka como de costume.
snowflake.role.nameFunção de controle de acesso a ser usada ao inserir as linhas na tabela.
Propriedades de otimização do cliente¶
enable.streaming.client.optimizationEspecifica se a otimização de um cliente deve ser ativada. Esta propriedade é suportada pela versão do conector Kafka 2.1.2 e posterior. Ela está ativada por padrão.
Com a otimização de um cliente, apenas um cliente é criado para diversas partições de tópico por conector Kafka. Esse recurso pode reduzir o tempo de execução do cliente e diminuir o custo de migração criando arquivos maiores.
- Valores:
truefalse
- Padrão:
true
Observe que em um cenário de alto rendimento (por exemplo, 50 MB/s por conector), a ativação desta propriedade pode resultar em latência ou custo mais alto. Recomendamos que você desative essa propriedade para cenários de alto rendimento.
Propriedades de buffer e sondagem¶
buffer.flush.timeNúmero de segundos entre as liberações do buffer, com cada liberação resultando em operações de inserção para registros em buffer. O conector Kafka chama o API do Snowpipe Streaming uma vez após cada liberação.
O valor mínimo suportado para a propriedade
buffer.flush.timeé1(em segundos). Para taxas médias de fluxo de dados mais altas, sugerimos que você diminua o valor padrão para melhorar a latência. Se o custo for uma preocupação maior do que a latência, você poderia aumentar o tempo de liberação do buffer. Tenha cuidado para liberar o buffer de memória Kafka antes que ele fique cheio para evitar exceções fora da memória.- Valores:
Mínimo:
1Máximo: sem limite superior
- Padrão:
10
Observe que o Snowpipe Streaming libera dados automaticamente a cada segundo, o que é diferente do tempo de liberação do buffer para o conector Kafka. Depois que o tempo de liberação do buffer Kafka for atingido, os dados serão enviados com um segundo de latência para o Snowflake por meio do Snowpipe Streaming. Para obter mais informações, consulte Latência do Snowpipe Streaming.
buffer.count.recordsNúmero de registros armazenados em buffer por partição Kafka antes da ingestão no Snowflake.
- Valores:
Mínimo:
1Máximo: sem limite superior
- Padrão:
10000
buffer.size.bytesTamanho cumulativo em bytes dos registros armazenados em buffer por partição Kafka antes de serem ingeridos no Snowflake como arquivos de dados.
Os registros são compactados quando gravados em arquivos de dados. Como resultado, o tamanho dos registros no buffer pode ser maior do que o tamanho dos arquivos de dados criados a partir dos registros.
- Valores:
Mínimo:
1Máximo: sem limite superior
- Padrão:
20000000(20 MB)
snowflake.streaming.max.client.lagEspecifica a frequência com que o Snowflake Ingest Java libera os dados para o Snowflake, em segundos.
Um valor baixo mantém a latência baixa, mas pode resultar em um desempenho de consulta pior, especialmente quando
snowflake.streaming.enable.single.bufferestá ativado. Para obter mais informações, consulte as configurações de latência recomendadas para o Snowpipe Streaming.- Valores:
Mínimo:
1segundoMáximo:
600segundos
- Padrão:
30segundos para a versão 3.1.1 e posteriores,120segundos para as versões 3.0.0 e 3.1.0,1nos demais casos
snowflake.streaming.enable.single.bufferEspecifica se deve habilitar o buffer único para o Snowpipe Streaming e ignorar o buffer de dados no buffer interno do conector.
Essa propriedade é compatível com o conector Kafka versão 2.3.1 e posteriores.
O conector de streaming usa buffer interno junto com o fornecido pelo Snowflake Ingest Java. Definir essa propriedade como
truefaz com que o conector Kafka ignore o buffer interno para obter menor latência.Observe que configurar essa propriedade como
truetornabuffer.flush.timeebuffer.count.recordsirrelevantes.- Valores:
truefalse
- Padrão:
truepara a versão 3.0.0 e posterior, caso contráriofalse
Além das propriedades do conector Kafka, observe a propriedade max.poll.records do consumidor Kafka, que controla o número máximo de registros devolvidos por Kafka para Kafka Connect em uma única pesquisa. O valor padrão de 500 pode ser aumentado, mas tenha em mente as restrições de memória. Para obter mais informações sobre esta propriedade, consulte a documentação de seu pacote Kafka:
Tratamento de erros e propriedades DLQ¶
errors.toleranceEspecifica como tratar os erros encontrados pelo conector Kafka:
Esta propriedade suporta os seguintes valores:
- Valores:
NONE: parar o carregamento de dados quando o primeiro erro for encontrado.ALL: ignorar todos os erros e continuar a carregar os dados.
- Padrão:
NONE
errors.log.enableEspecifica se deve escrever mensagens de erro no arquivo de log Kafka Connect.
Esta propriedade suporta os seguintes valores:
- Valores:
TRUE: escrever mensagens de erro.FALSE: não escrever mensagens de erro.
- Padrão:
FALSE
errors.deadletterqueue.topic.nameEspecifica o nome do tópico DLQ (fila de mensagens mortas) em Kafka para entregar mensagens ao Kafka que não puderam ser ingeridas nas tabelas do Snowflake. Para obter mais informações, consulte Filas de mensagens mortas (neste tópico).
- Valores:
Cadeia de caracteres de texto personalizada
- Padrão:
Nenhum
Semântica exatamente um¶
A semântica exatamente um garante a entrega de mensagens Kafka sem duplicação ou perda de dados. Esta garantia de entrega é definida por padrão para o conector Kafka com Snowpipe Streaming.
O conector Kafka adota um mapeamento de um para um entre a partição e o canal e usa dois deslocamentos distintos:
Offset do consumidor: rastreia o offset mais recente consumido pelo consumidor e é gerenciado pelo Kafka.
Token de offset: rastreia o offset confirmado mais recente no Snowflake e é gerenciado pelo Snowflake.
Observe que o conector Kafka nem sempre lida com deslocamentos ausentes. Snowflake espera que todos os registros tenham offsets crescentes sequencialmente. Os offsets ausentes destruirão o conector Kafka em casos de uso específicos. É recomendável usar registros de marca de exclusão em vez de registros NULL.
O conector Kafka consegue uma entrega exatamente única implementando as seguintes práticas recomendadas:
Abertura/reabertura de um canal:
Ao abrir ou reabrir um canal para uma determinada partição, o conector Kafka usa o último token de offset confirmado recuperado do Snowflake por meio da
getLatestCommittedOffsetTokenAPI como a fonte da verdade e redefine o offset do consumidor no Kafka de forma correspondente.Se o offset do consumidor não estiver mais dentro do período de retenção de dados, uma exceção será lançada e você poderá determinar a medida apropriada a ser tomada.
O único cenário em que o conector Kafka não redefine o offset do consumidor no Kafka e o usa como a fonte da verdade é quando o token de offset do Snowflake é NULL. Nesse caso, o conector aceita o offset enviado pelo Kafka, e o token de offset é atualizado posteriormente.
Processamento de registros:
Para garantir uma camada adicional de segurança contra offsets não contínuos que poderiam surgir de possíveis bugs no Kafka, o Snowflake mantém uma variável na memória que rastreia o último offset processado. O Snowflake só aceita linhas se o offset da linha atual for igual ao último offset processado mais um, adicionando assim uma camada extra de proteção para garantir que o processo de ingestão seja contínuo e preciso.
Tratamento de exceções, falhas e recuperação de falhas:
Como parte do processo de recuperação, o Snowflake adere consistentemente à lógica de abertura/reabertura do canal descrita anteriormente, reabrindo o canal e redefinindo o offset do consumidor com o último token de offset confirmado. Ao fazer isso, o Snowflake sinaliza ao Kafka para enviar os dados do valor de offset que é um valor maior do que o último token de offset confirmado, o que permite a retomada da ingestão a partir do ponto de falha sem perda de dados.
Implementação de um mecanismo de repetição:
Para levar em conta possíveis problemas transitórios, o Snowflake incorpora um mecanismo de repetição nas chamadas de API. O Snowflake tenta novamente essas chamadas de API várias vezes para aumentar as chances de sucesso e reduzir o risco de falhas intermitentes que afetam o processo de ingestão.
Avanço do offset do consumidor:
Em intervalos regulares, o Snowflake avança o offset do consumidor usando o último token de offset confirmado para garantir que o processo de ingestão esteja continuamente alinhado com o estado mais recente dos dados no Snowflake.
Conversores¶
O Snowpipe Streaming oferece suporte a muitos conversores com base na comunidade, como os seguintes:
io.confluent.connect.avro.AvroConverterorg.apache.kafka.connect.json.JsonConverterio.confluent.connect.protobuf.ProtobufConverterio.confluent.connect.json.JsonSchemaConverterorg.apache.kafka.connect.converters.ByteArrayConverterorg.apache.kafka.connect.storage.StringConverter
Outros conversores baseados na comunidade podem compatíveis, mas não foram validados. Os conversores Snowflake não são compatíveis com o Snowpipe Streaming.
Filas de mensagens mortas¶
O conector Kafka com Snowpipe Streaming suporta filas de mensagens mortas (DLQ) para registros quebrados ou registros que não podem ser processados com sucesso devido a uma falha.
Para obter mais informações sobre o monitoramento, consulte a documentação do Apache Kafka.
Detecção de esquema e evolução de esquema¶
O conector Kafka com Snowpipe Streaming oferece suporte à detecção e evolução de esquema. A estrutura das tabelas no Snowflake pode ser definida e evoluída automaticamente para oferecer suporte à estrutura dos novos dados do Snowpipe Streaming carregados pelo conector Kafka. Para habilitar a detecção e evolução de esquema para o conector Kafka com Snowpipe Streaming, configure as seguintes propriedades do Kafka:
snowflake.ingestion.methodsnowflake.enable.schematizationschema.registry.url
Para obter mais informações, consulte Schema detection and evolution for Kafka connector with Snowpipe Streaming classic.
Estimativa da latência de ingestão¶
Para estimar a latência de ingestão, use o campo SnowflakeConnectorPushTime em RECORD_METADATA. Este carimbo de data/hora representa um momento em que um registro foi enviado para um buffer SDK do Ingest.
Para obter mais informações sobre o formato RECORD_METADATA, consulte Esquema de tabelas para tópicos do Kafka.
Nota
Esse campo não representa quando um registro se tornou visível em uma tabela do Snowflake, porque não leva em conta a latência do Snowpipe Streaming configurada.
Faturamento e uso¶
Para obter informações de faturamento do Snowpipe Streaming, consulte Custos para o Snowpipe Streaming Classic.
Limitações¶
Limitações do Snowpipe Streaming¶
Consulte Limitações do Snowpipe Streaming.
Limitações de failover¶
Quando um grupo de failover secundário é promovido a primário, o conector do Kafka com o Snowpipe Streaming requer interação manual. A semântica de «exatamente uma vez» ainda é preservada.
Se a propriedade enable.streaming.client.optimization estiver definida como false, o conector do Kafka deverá ser reiniciado. Após você reiniciar o conector, ele será direcionado a uma nova implantação primária.
Se a propriedade enable.streaming.client.optimization estiver definida como true, o host JVM no qual o conector está sendo executado deverá ser desligado e reiniciado. Depois que você reiniciar o host JVM, um conector Kafka recém-iniciado terá como alvo uma nova implantação primária.