Concepts clés et architecture de Snowflake¶
Snowflake est alimenté par une plateforme de données avancée qui vous est fournie sous forme de service autogéré. La plateforme de données Snowflake rassemble des solutions de stockage, de traitement et d’analyse des données qui sont plus rapides, plus faciles à utiliser et bien plus flexibles que les offres traditionnelles.
Snowflake combine un tout nouveau moteur d’interrogation SQL avec une architecture novatrice, conçue spécialement pour le cloud. La plateforme offre une fonctionnalité de base de données analytique d’entreprise complète, ainsi que des fonctionnalités et capacités uniques.
Plateforme de données en tant que service autogéré¶
En tant que service autogéré, Snowflake présente les avantages suivants :
Il n’y a aucun matériel (virtuel ou physique) à sélectionner, installer, configurer ou gérer.
Vous n’avez pratiquement aucun logiciel à installer, à configurer ou à gérer.
La maintenance, la gestion, les mises à jour et les réglages sont assurés par Snowflake.
Snowflake utilise une infrastructure cloud publique pour héberger des instances de calcul virtuelles et le stockage de données persistants. Snowflake gère les mises à jour logicielles et l’infrastructure pour que vous n’ayez pas à le faire. Vous ne pouvez pas installer et exécuter Snowflake localement ou sur des infrastructures cloud privées, que ce soit sur site ou hébergées.
Architecture Snowflake¶
L’architecture de Snowflake est un mélange d’architectures de bases de données classique à disque partagé, et d’architectures de bases de données sans partage. Comme pour les architectures à disque partagé, Snowflake utilise un entrepôt de données central pour les données persistantes accessibles depuis tous les nœuds de calcul de la plateforme. Mais à l’instar des architectures sans partage, Snowflake traite les requêtes à l’aide de clusters de calcul à traitement massivement parallèle (MPP) où chaque nœud du cluster stocke localement une partie de l’ensemble des données. Cette architecture hybride, qui est illustrée dans le schéma suivant, offre la simplicité de gestion des données d’une architecture à disque partagé, mais avec les avantages en termes de performance et de mise à l’échelle d’une architecture sans partage :
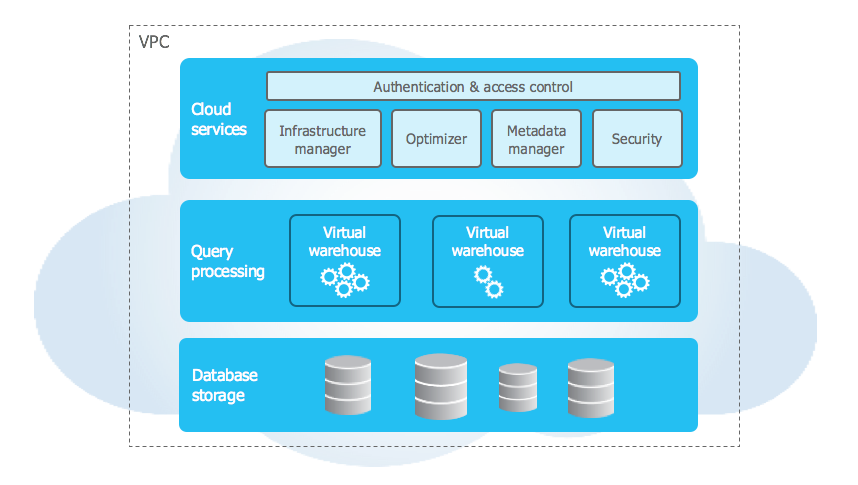
L’architecture unique de Snowflake est dotée des couches clés suivantes :
Stockage de bases de données¶
Snowflake prend en charge les types de données suivants :
Données structurées — telles que les lignes et les colonnes d’une table — suivent un schéma tabulaire strict.
Données semi-structurées — telles qu’un fichier JSON ou un fichier XML — disposent d’un schéma flexible.
Données non structurées — telles qu’un document, une image ou un fichier audio — ne disposent pas de schéma inhérent.
Snowflake prend en charge plusieurs types de tables pour le stockage de données, dont les types de tables suivants :
Tables Snowflake¶
Lorsque les données sont chargées dans une table Snowflake, Snowflake réorganise ces données dans son format interne optimisé, compressé et en colonnes. Snowflake stocke ces données optimisées dans le cloud. Les tables Snowflake sont idéales pour les entrepôts de données.
Snowflake gère tous les aspects du stockage de ces données, y compris l’organisation, la taille des fichiers, la structure, la compression, les métadonnées et les statistiques. Toutes les données des tables Snowflake sont automatiquement divisées en micro-partitions qui sont des unités de stockage contiguës. Les micro-partitions améliorent l’efficacité et offrent d’autres avantages.
Vous pouvez utiliser des tables Snowflake pour stocker des données structurées et des données semi-structurées. Vous pouvez également utiliser Type de données FILE pour les données non structurées.
Pour plus d’informations sur les tables Snowflake, voir Fonctionnement des structures de table dans Snowflake.
Tables Apache Iceberg™¶
Les tables Apache Iceberg™ pour Snowflake combinent les performances et la sémantique de requête des tables Snowflake typiques avec le stockage cloud externe que vous gérez. Elles sont idéales pour les data lakes et les data lakehouses existants que vous ne pouvez pas, ou choisissez de ne pas, stocker dans Snowflake.
Les tables Iceberg stockent leurs fichiers de données et de métadonnées dans un emplacement de stockage cloud externe ; par exemple, Amazon S3, Google Cloud Storage ou Microsoft Azure Storage. Le stockage externe ne fait pas partie de Snowflake.
Vous pouvez utiliser des tables Iceberg pour stocker des données structurées et des données semi-structurées.
Pour plus d’informations, voir Tables Apache Iceberg™.
Tables hybrides¶
Les tables hybrides sont optimisées pour une faible latence et un débit élevé en utilisant des lectures et écritures aléatoires basées sur l’index. Les tables hybrides prennent en charge le verrouillage des lignes et appliquent des contraintes d’intégrité uniques et référentielles, qui sont essentielles pour les charges de travail transactionnelles. Vous pouvez utiliser une table hybride avec d’autres tables et fonctionnalités Snowflake pour les charges de travail Unistore qui rassemblent les données transactionnelles et analytiques en une seule plateforme.
Vous pouvez utiliser des tables hybrides pour stocker des données structurées et des données semi-structurées.
Pour plus d’informations, voir Tables hybrides.
Calcul¶
Un entrepôt virtuel est un cluster de ressources de calcul dans Snowflake. Les entrepôts virtuels traitent les instructions SQL et, à l’aide de Snowpark, exécutent du code dans des langages tels que Java, Python et Scala. Avec Snowpark Connect pour Spark, vous pouvez également exécuter des charges de travail Apache Spark™ sur des entrepôts virtuels.
Chaque entrepôt virtuel est une grappe de calcul indépendante qui ne partage aucune ressource de calcul avec d’autres entrepôts virtuels. Par conséquent, chaque entrepôt virtuel n’a aucun effet sur les performances des autres entrepôts virtuels.
Pour plus d’informations, voir Entrepôts virtuels.
Services cloud¶
La couche de services Cloud constitue un ensemble de services qui coordonnent les activités dans Snowflake. Ces services relient tous les différents composants de Snowflake afin de traiter les demandes des utilisateurs, de la connexion à l’envoi des requêtes. La couche de services cloud s’exécute également sur des instances de calcul fournies par Snowflake à partir du fournisseur cloud.
Les services gérés dans cette couche comprennent les éléments suivants :
Fonctionnalités intégrées pour vos charges de travail¶
Au lieu de déplacer des données vers différents systèmes afin que différentes équipes puissent effectuer des opérations et des tâches spécifiques, vous pouvez amener toutes vos charges de travail directement à leurs données grâce à un ensemble intégré de fonctionnalités.
Ces fonctionnalités prennent en charge les grands domaines d’intégration et de développement de données suivants :
Ingénierie des données¶
Snowflake sépare le stockage et le calcul, ce qui simplifie certains défis traditionnels de l’ingénierie des données, tels que la gestion de l’infrastructure et le réglage des performances. Les ingénieurs des données peuvent se concentrer sur la mise en œuvre de pipelines qui ingèrent, transforment et fournissent des données.
Snowflake propose plusieurs moyens d’ingérer des données, dont les options suivantes :
Commande COPY INTO <table> — Charge les données des fichiers dans une table.
Snowpipe — Charge les données des fichiers dès qu’elles sont disponibles dans une zone de préparation.
Snowpipe Streaming — Charge les données au niveau des lignes de manière continue et avec une faible latence, en utilisant les SDKs Snowflake ou une API REST, directement dans les tables Snowflake et les tables Iceberg gérées par Snowflake, au lieu de charger des données à partir de fichiers.
Connecteurs Openflow — Ingère des données provenant de sources spécifiques à l’aide de connecteurs conçus sur Apache NiFi, comme Microsoft Sharepoint et Google Drive.
Connecteurs Snowflake — Connectez-vous à partir d’applications et de systèmes externes et transférez des données vers Snowflake.
Snowflake propose également plusieurs moyens de transformer les données, dont les options suivantes :
Tables dynamiques — Définissez des tables qui s’actualisent automatiquement en fonction du niveau d’actualisation cible et d’une requête qui effectue des transformations de données.
Flux et tâches — Capturez les modifications apportées aux objets de base avec des flux et définissez les tâches pour effectuer des transformations de données.
</developer-guide/snowpark/index> Snowpark — Effectuez des transformations plus complexes à l’aide de langages de programmation tels que Python, Java et Scala.
</user-guide/data-engineering/dbt-projects-on-snowflake> dbt — Utilisez un outil et un framework de transformation de données open source pour définir, tester et déployer les transformations SQL.
En outre, SnowConvert AI peut ingérer et transformer des données, et l’accélérateur de migration Snowpark peut convertir le code de diverses plateformes vers Snowflake.
Pour plus d’informations, voir Vue d’ensemble du chargement de données.
Analyses¶
Avec Snowflake, vous pouvez faire évoluer dynamiquement les charges de travail en fonction de la demande, accéder à différents types de données (y compris structurées, semi-structurées et non structurées) et partager facilement des données. Ces fonctionnalités vous permettent d’analyser les données stockées dans Snowflake afin d’en extraire des informations, des modèles et des tendances significatifs à des fins d’analyse, telles que la veille économique ou la modélisation prédictive.
Snowflake propose plusieurs méthodes d’analyse des données, dont les options suivantes :
Fonctions système et constructions SQL — Effectuez des calculs et des analyses statistiques à l’aide des fonctions système Snowflake et des constructions SQL :
Fonctions d’agrégation — Résumez les données en effectuant des calculs sur un ensemble de lignes liées et en renvoyant une valeur unique.
Fonctions de fenêtre — Effectuez des calculs sur un ensemble de lignes liées dans des partitions pour des opérations de glissement sur des sous-ensembles de lignes de chaque partition, comme le calcul de totaux continus ou de moyennes mobiles.
Expressions de table communes (CTEs) — Améliorez la lisibilité et la réutilisation des requêtes complexes, qui peuvent effectuer plusieurs étapes de transformation de données.
Cortex AI Functions — Run unstructured analytics on text and images with large language models (LLMs) from OpenAI, Anthropic, Meta, Mistral AI, and DeepSeek.
Vues sémantiques — Stockez les concepts métier sémantiques directement dans la base de données afin de définir des métriques métier et de modéliser les entités métier et leurs relations.
AI et ML¶
Snowflake simplifie l’utilisation des capacités d’intelligence artificielle (AI) et de machine learning (ML) afin que vous puissiez effectuer l’ingénierie, l’entraînement et l’inférence des fonctionnalités AI et ML avec vos données Snowflake. Les modèles peuvent accéder à vos données les plus récentes dans un environnement sécurisé. Avec Snowflake, vous pouvez éviter le coût et la complexité du déplacement de vos données vers une plateforme distincte pour les tâches AI et ML.
Snowflake offre des capacités AI et ML dans deux grandes suites de fonctionnalités :
Snowflake Cortex — Fonctionnalités AI qui utilisent des LLMs pour comprendre les données non structurées, répondre aux questions libres et fournir une assistance intelligente. Fonctions Cortex AI peut automatiser des tâches de routine, telles que des résumés simples et des traductions rapides.
Snowflake ML — Fonctionnalités que vous pouvez utiliser pour construire vos propres modèles. Les fonctions ML offrent des prédictions automatisées et des aperçus de vos données grâce au ML. Snowflake ML est un environnement unifié pour le développement ML.
Pour plus d’informations, voir Snowflake AI et ML.
Applications et collaboration¶
Snowflake offre de nombreuses façons de créer des applications et de les partager avec vos équipes, partenaires et clients. Lorsque vous utilisez Snowflake pour partager des données, vous contrôlez l’accès aux données et évitez les difficultés liées à la synchronisation à différents endroits.
La liste suivante présente certains des outils et des services que vous pouvez utiliser pour créer, déployer et gérer des applications dans Snowflake :
Streamlit — Utilisez une bibliothèque Python open source pour créer et partager des applications Web personnalisées avec une interface utilisateur (UI) interactive pour le ML et la science des données.
Snowpark Container Services — Déployez, gérez et mettez à l’échelle des applications conteneurisées directement depuis Snowflake.
Framework des applications natives Snowflake — Créer des applications qui étendent les capacités d’autres fonctionnalités Snowflake en partageant des données et la logique métier associée avec d’autres comptes Snowflake. La logique métier d’une application peut inclure une application Streamlit, des procédures stockées et des fonctions écrites à l’aide de l’API Snowpark, de JavaScript et de SQL. Une application native Snowflake peut également exécuter des charges de travail de conteneurs avec Snowpark Container Services.
Snowflake prend en charge les types de collaboration suivants :
Secure Data Sharing — Partagez des objets sélectionnés dans une base de données de votre compte avec d’autres comptes Snowflake.
Annonces — Fournissez des données et d’autres informations à d’autres utilisateurs de Snowflake, et accédez aux données et autres informations partagées par les fournisseurs de Snowflake. Vous pouvez explorer, consulter et fournir des annonces en privé aux consommateurs et sur la Snowflake Marketplace.
Data Clean Rooms — Define what analyses can be run against the shared data, which allows the consumer to gather insights from the data without having unrestricted access to it.
Snowgrid¶
Snowgrid est la couche technologique inter-régionale et inter-cloud de Snowflake. Avec Snowgrid, vous pouvez atteindre les objectifs suivants :
Connecter un écosystème de données entre différentes régions et différents fournisseurs cloud — comme, Amazon Web Services (AWS), Microsoft Azure et Google Cloud — en utilisant les annonces et d’autres fonctionnalités de collaboration.
Appliquer des politiques de sécurité et de gouvernance cohérentes sur les clouds et les régions.
Activer les capacités de reprise après sinistre et de continuité des activités dans les régions en utilisant la réplication.
Pour plus d’informations, voir Snowgrid.
Connexion à Snowflake¶
Snowflake prend en charge plusieurs méthodes de connexion au service :
Snowsight, une UI Web que vous pouvez utiliser pour accéder à tous les aspects de la gestion et de l’utilisation de Snowflake.
Clients de ligne de commande que vous pouvez également utiliser pour accéder à tous les aspects de la gestion et de l’utilisation de Snowflake ; par exemple, Snowflake CLI.
APIs natives que vous pouvez utiliser pour créer et gérer des ressources Snowflake par programmation ; par exemple, APIs Python Snowflake et APIs REST Snowflake.
Pilotes que d’autres applications peuvent utiliser pour se connecter à Snowflake ; par exemple, JDBC et ODBC.
Connecteurs natifs que vous pouvez utiliser pour développer des applications de connexion à Snowflake ; par exemple, Apache Kafka et Apache Spark.
Technologies tierces que vous pouvez utiliser pour connecter des applications à Snowflake ; par exemple, des outils d’extraction, de transformation et de chargement (ETL) tels que Informatica et de veille stratégique (BI) tels que ThoughtSpot.
Pour plus d’informations, voir Se connecter à Snowflake.