Principais conceitos e arquitetura do Snowflake¶
O Snowflake conta com uma avançada plataforma de dados fornecida como serviço autogerenciado. A plataforma de dados do Snowflake combina soluções de armazenamento, processamento e análise de dados que são mais rápidas, fáceis de usar e muito mais flexíveis do que as ofertas tradicionais.
O Snowflake une um mecanismo de consulta SQL totalmente novo a uma arquitetura inovadora projetada de forma nativa para a nuvem. Ele oferece uma funcionalidade completa de banco de dados analítico empresarial, além de recursos e funções exclusivos.
Plataforma de dados como serviço autogerenciado¶
Como serviço autogerenciado, o Snowflake oferece as seguintes vantagens:
Não há hardware (virtual ou físico) para selecionar, instalar, configurar ou gerenciar.
Praticamente nenhum software para instalar, configurar ou gerenciar.
A manutenção, o gerenciamento, as atualizações e os ajustes contínuos são feitos pelo Snowflake.
O Snowflake usa uma infraestrutura de nuvem pública para hospedar instâncias virtuais de computação e armazenamento de dados persistente. O Snowflake gerencia as atualizações e a infraestrutura de software para você. Não é possível instalar e executar o Snowflake localmente ou em infraestruturas de nuvem privada, seja no local ou hospedado.
Arquitetura do Snowflake¶
A arquitetura do Snowflake é um híbrido de arquiteturas tradicionais de banco de dados com disco compartilhado e de banco de dados sem compartilhamento. De forma similar às arquiteturas de disco compartilhado, o Snowflake usa um repositório central para dados persistentes que pode ser acessado a partir de todos os nós de computação da plataforma. No entanto, assim como nas arquiteturas sem compartilhamento, o Snowflake processa as consultas usando clusters de computação de processamento paralelo massivo (Massively Parallel Processing, MPP), em que cada nó no cluster armazena localmente uma parte do conjunto de dados inteiro. Essa arquitetura híbrida (apresentada no diagrama a seguir) oferece a simplicidade do gerenciamento de dados de uma arquitetura de disco compartilhado, mas com os benefícios de desempenho e escalabilidade horizontal de uma arquitetura sem compartilhamento:
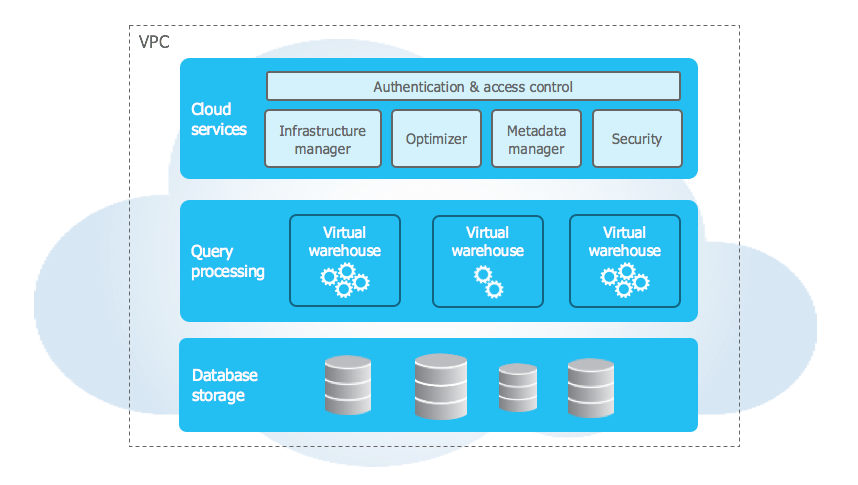
A arquitetura exclusiva do Snowflake tem as seguintes camadas principais:
Armazenamento de banco de dados¶
O Snowflake é compatível com os seguintes tipos de dados:
Dados estruturados (como linhas e colunas em uma tabela): seguem um esquema tabular rigoroso.
Dados semiestruturados (como um arquivo JSON ou XML): têm um esquema flexível.
Dados não estruturados (como documento, imagem ou arquivo de áudio): não têm um esquema inerente.
O Snowflake é compatível com vários tipos de tabelas para armazenamento de dados, incluindo:
Tabelas do Snowflake¶
Quando os dados são carregados em uma tabela do Snowflake, ele os reorganiza em seu formato de coluna internamente otimizado e compactado. O Snowflake salva os dados otimizados no armazenamento em nuvem. As tabelas do Snowflake são ideais para data warehouses.
O Snowflake gerencia todos os aspectos de armazenamento desses dados, incluindo organização, tamanho de arquivo, estrutura, compactação, metadados e estatísticas. Todos os dados nas tabelas do Snowflake são automaticamente divididos em micropartições, que são unidades de armazenamento contíguas. As micropartições melhoram a eficiência e oferecem outros benefícios.
Você pode usar as tabelas do Snowflake para armazenar dados estruturados e semiestruturados. Você também pode usar o Tipo de dados FILE para dados não estruturados.
Para obter mais informações sobre as tabelas do Snowflake, consulte Explicação das estruturas de tabela do Snowflake.
Tabelas Apache Iceberg™¶
As tabelas Apache Iceberg™ do Snowflake combinam o desempenho e a semântica de consulta das tabelas típicas do Snowflake com o armazenamento em nuvem externo que você gerencia. Elas são ideais para data lakes e data lakehouses existentes que você não pode ou optou por não armazenar no Snowflake.
As tabelas Iceberg armazenam os arquivos de dados e de metadados em um local de armazenamento em nuvem externo; por exemplo, Amazon S3, Google Cloud Storage ou Armazenamento do Microsoft Azure. O armazenamento externo não faz parte do Snowflake.
Você pode usar as tabelas Iceberg para armazenar dados estruturados e semiestruturados.
Para obter mais informações, consulte Tabelas Apache Iceberg™.
Tabelas híbridas¶
As tabelas híbridas são otimizadas para baixa latência e alta taxa de transferência, pois usam leituras e gravações aleatórias baseadas em índice. As tabelas híbridas permitem bloqueio de linhas e impõem restrições de integridade exclusivas e referenciais, que são essenciais para cargas de trabalho transacionais. Você pode usar uma tabela híbrida junto com outras tabelas e recursos do Snowflake para cargas de trabalho Unistore, que reúnem dados transacionais e analíticos em uma única plataforma.
Você pode usar as tabelas híbridas para armazenar dados estruturados e semiestruturados.
Para obter mais informações, consulte Tabelas híbridas.
Computação¶
O warehouse virtual é um cluster de recursos de computação no Snowflake. Os warehouses virtuais processam instruções SQL e, por meio do Snowpark, executam código em linguagens como Java, Python e Scala. Com o Snowpark Connect para Spark, você também pode executar cargas de trabalho do Apache Spark™ em warehouses virtuais.
Cada warehouse virtual é um cluster de computação independente que não compartilha recursos de computação com outros warehouses virtuais. Como resultado, um warehouse virtual não tem impacto sobre o desempenho dos outros warehouses virtuais.
Para obter mais informações, consulte Warehouses virtuais.
Serviços de nuvem¶
A camada de serviços de nuvem é um conjunto de serviços que coordena atividades em todo o Snowflake. Esses serviços unem todos os componentes diferentes do Snowflake para processar as solicitações dos usuários, do login ao envio da consulta. A camada de serviços de nuvem também é executada em instâncias de computação do provedor de nuvem provisionadas pelo Snowflake.
Veja a seguir alguns dos serviços gerenciados nessa camada:
Recursos integrados para cargas de trabalho¶
Em vez de mover os dados para outros sistemas de modo que equipes diferentes possam concluir operações e tarefas específicas, você pode levar todas as suas cargas de trabalho diretamente para os dados deles com um conjunto integrado de recursos.
Esses recursos oferecem suporte às seguintes áreas amplas de integração e desenvolvimento de dados:
Engenharia de dados¶
O Snowflake separa armazenamento e computação, o que simplifica alguns desafios comuns da engenharia de dados, como gerenciamento de infraestrutura e ajuste de desempenho. Os engenheiros de dados podem se dedicar à implementação de pipelines que ingerem, transformam e entregam os dados.
O Snowflake oferece várias maneiras de ingerir dados, incluindo as seguintes opções:
Comando COPY INTO <tabela>: carrega dados de arquivos em uma tabela.
Snowpipe: carrega dados de arquivos assim que ficam disponíveis em uma área de preparação.
Snowpipe Streaming: carrega dados no nível da linha de forma contínua e com baixa latência, usando os SDKs ou uma API REST do Snowflake, diretamente nas tabelas do Snowflake e nas tabelas Iceberg gerenciadas pelo Snowflake, em vez de carregar dados de arquivos.
Conectores Openflow: ingere dados de fontes específicas usando conectores desenvolvidos com base no Apache NiFi, como Microsoft Sharepoint e Google Drive.
Conectores Snowflake: conexão de aplicativos e sistemas externos e transmissão de dados ao Snowflake.
O Snowflake também oferece várias maneiras de transformar dados, incluindo as seguintes opções:
Tabelas dinâmicas: defina tabelas que são atualizadas automaticamente com base na atualização de destino e uma consulta que realiza transformações de dados.
Fluxos e tarefas: capture alterações feitas em objetos base com fluxos e defina tarefas para executar transformações de dados.
Snowpark: realize transformações mais complexas usando linguagens de programação como Python, Java e Scala.
dbt: use uma ferramenta de transformação de dados de código aberto e uma estrutura para definir, testar e implantar transformações SQL.
Além disso, a SnowConvert AI pode ingerir e transformar dados, e o Snowpark Migration Accelerator pode converter código de várias plataformas no Snowflake.
Para obter mais informações, consulte Visão geral do carregamento de dados.
Análise¶
Com o Snowflake, você pode dimensionar cargas de trabalho de forma dinâmica com base na demanda, acessar tipos de dados diferentes, incluindo estruturados, semiestruturados e não estruturados, e compartilhar dados facilmente. Esses recursos permitem que você analise os dados armazenados no Snowflake para extrair insights, padrões e tendências relevantes para casos de uso analíticos, como business intelligence ou modelagem preditiva.
O Snowflake oferece várias maneiras de analisar dados, incluindo as seguintes opções:
Funções do sistema e constructos SQL: faça cálculos e análises estatísticas com as seguintes funções do sistema Snowflake e constructos SQL:
Funções de agregação: resuma os dados ao fazer cálculos de um conjunto de linhas relacionadas e retornar um único valor.
Funções de janela: faça cálculos de um conjunto de linhas relacionadas em partições para operações contínuas com subconjuntos de linhas em cada partição, como calcular totais acumulados ou médias móveis.
Expressões de tabela comuns (Common Table Expressions, CTEs): melhore a capacidade de leitura e de reutilização de consultas complexas, que podem executar várias etapas de transformação de dados.
Cortex AI Functions — Run unstructured analytics on text and images with large language models (LLMs) from OpenAI, Anthropic, Meta, Mistral AI, and DeepSeek.
Exibições semânticas: armazene conceitos semânticos de negócios diretamente no banco de dados para definir métricas de negócios e modelar entidades comerciais e seus relacionamentos.
AI e ML¶
O Snowflake simplifica o uso dos recursos de inteligência artificial (Artificial Intelligence, AI) e de machine learning (ML) para que você possa realizar engenharia, treinamento e inferência com recursos de AI e ML usando seus dados do Snowflake. Os modelos podem acessar os dados mais atualizados em um ambiente seguro. Com o Snowflake, você evita o custo e a complexidade de mover os dados para uma plataforma separada para as tarefas de AI e ML.
O Snowflake oferece as funcionalidades de AI e ML em dois conjuntos abrangentes de recursos:
Snowflake Cortex: recursos de AI que usam LLMs para compreender dados não estruturados, responder a perguntas em formato livre e oferecer assistência inteligente. A Funções de AI do Cortex pode automatizar tarefas de rotina, como resumos simples e traduções rápidas.
Snowflake ML: recursos que você pode usar para construir seus próprios modelos. As funções ML usam ML para retornar previsões e insights automatizados sobre seus dados. O Snowflake ML é um ambiente unificado para desenvolvimento de ML.
Para obter mais informações, consulte AI e ML Snowflake.
Aplicativos e colaboração¶
O Snowflake oferece várias maneiras de criar e compartilhar aplicativos com suas equipes, parceiros e clientes. Quando você usa o Snowflake para compartilhar dados, controla o acesso aos dados e evita ter que mantê-los sincronizados em lugares diferentes.
A lista a seguir mostra algumas das ferramentas e dos serviços que você pode usar para criar, implantar e gerenciar aplicativos no Snowflake:
Streamlit: use uma biblioteca Python de código aberto para criar e compartilhar apps da web personalizados com uma interface de usuário (User Interface, UI) interativa para ML e ciência de dados.
Snowpark Container Services: implante, gerencie e dimensione aplicativos em contêineres diretamente do Snowflake.
Snowflake Native App Framework: crie aplicativos que expandem as funcionalidades de outros recursos do Snowflake compartilhando os dados e a lógica de negócios relacionada com outras contas Snowflake. A lógica de negócios de um aplicativo pode incluir um app Streamlit, procedimentos armazenados e funções escritas usando a Snowpark API, o JavaScript e o SQL. Um Snowflake Native App também pode executar cargas de trabalho de contêiner com o Snowpark Container Services.
O Snowflake inclui suporte para os seguintes tipos de colaboração:
Compartilhamento de dados seguro: compartilhe objetos selecionados em um banco de dados em sua conta com outras contas Snowflake.
Listagens: forneça dados e outras informações a usuários diferentes do Snowflake, ou acesse dados e outras informações compartilhadas por provedores do Snowflake. Você pode explorar, acessar e fornecer listagens aos consumidores de forma privada e no Snowflake Marketplace.
Data Clean Rooms — Define what analyses can be run against the shared data, which allows the consumer to gather insights from the data without having unrestricted access to it.
Snowgrid¶
Snowgrid é a camada de tecnologia entre regiões e nuvens do Snowflake. Com o Snowgrid, você pode atingir as seguintes metas:
Conectar um ecossistema de dados entre regiões e provedores de nuvem diferentes, como Amazon Web Services (AWS), Microsoft Azure e Google Cloud, usando listagens e outros recursos de colaboração.
Aplicar políticas de segurança e de governança consistentes entre nuvens e regiões.
Habilitar recursos de recuperação de desastres e continuidade de negócios em todas as regiões por meio da replicação.
Para obter mais informações, consulte Snowgrid.
Conexão ao Snowflake¶
O Snowflake permite que você se conecte ao serviço de várias maneiras:
Snowsight, UI com base na web que você pode usar para acessar todos os aspectos de gerenciamento e de uso do Snowflake.
Clientes de linha de comando que você também pode usar para acessar todos os aspectos de gerenciamento e de uso do Snowflake; por exemplo, Snowflake CLI.
APIs nativas que você pode usar para criar e gerenciar recursos do Snowflake de modo programático; por exemplo, Snowflake Python APIs e:doc:
Snowflake APIs REST </developer-guide/snowflake-rest-api/snowflake-rest-api>.Drivers que outros aplicativos podem usar para conexão com o Snowflake; por exemplo, JDBC e ODBC.
Conectores nativos que você pode usar para desenvolver aplicativos para conexão com o Snowflake; por exemplo, Apache Kafka e Apache Spark.
Tecnologias de terceiros que você pode usar para conectar aplicativos ao Snowflake; por exemplo, ferramentas de extração, transformação, carregamento (Extract, Transform, Load, ETL), como Informatica, e de business intelligence (BI), como ThoughtSpot.
Para obter mais informações, consulte Fazer login no Snowflake.